혼공머신 1주차
- Chapter 1 ) 나의 첫 머신러닝
- Chpater 2) 데이터 다루기
1-1 인공지능과 머신러닝, 딥러닝
1단계, 인공지능, 머신러닝, 딥러닝이 무엇인지 용어부터 파악하기

1-2 코랩으로 실습하기
2단계, 구글 계정으로 머신러닝 실습을 할 수 있는 환경 만들기
코랩이란?
웹브라우저에서 무료로 파이썬 프로그램을 테이트하고 저장할 수 있는 서비스로, 머신러닝 프로그램 실습에 사용되는 프로그램
(별도의 설치없이 구글 계정만 있으면 사용 가능!)
아이패드로 실습이 가능한지 해봤는데, 아이패드에서도 코랩 접속하여 실습까지 문제없이 실행되었다.
1-3 마켓과 머신러닝
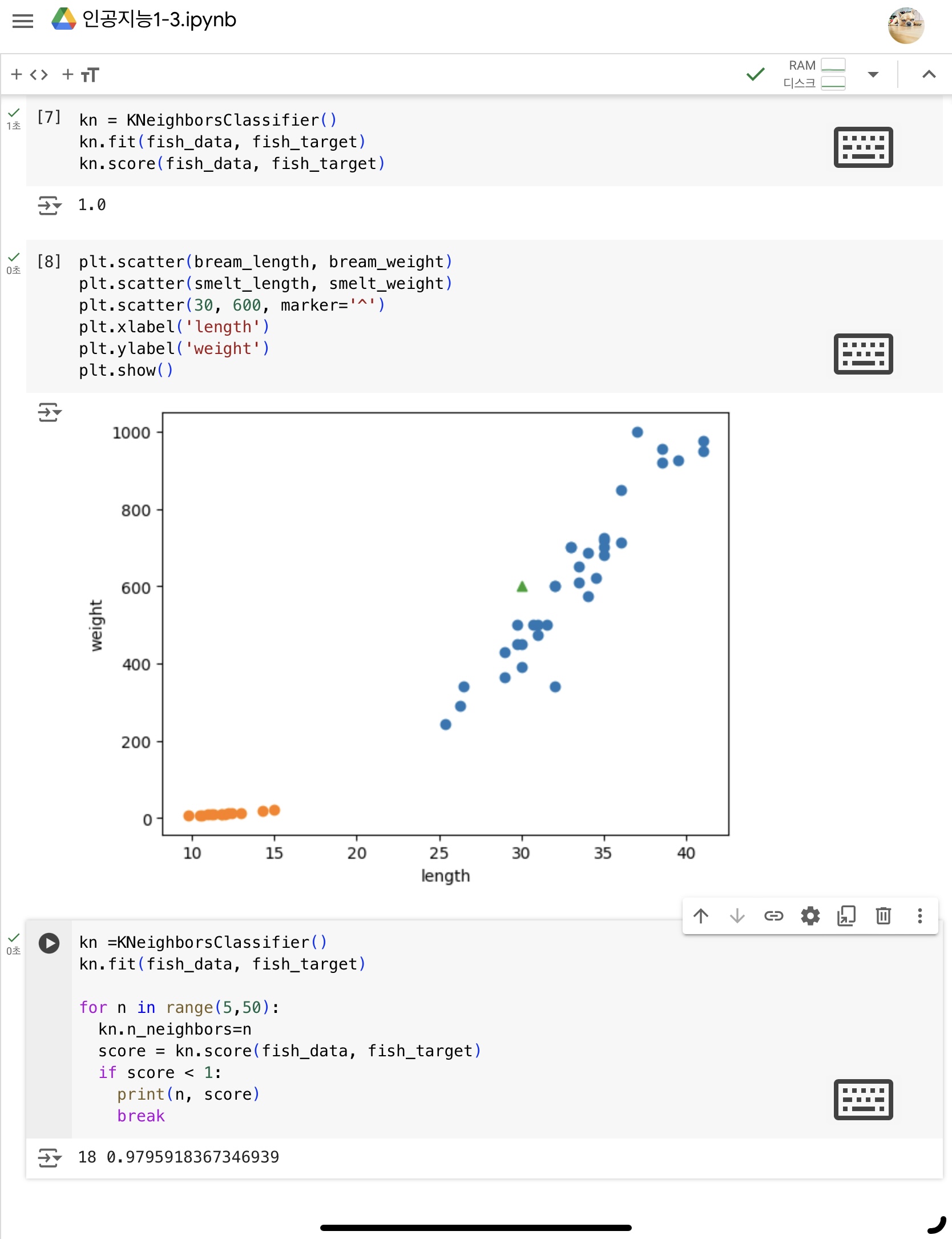
첫 번째 머신러닝 프로그램 k-최근접 이웃 모델
- k-최근접 이웃 알고리즘 : 전체 데이터를 가지고 있는 상태에서, 새로운 데이터에 대해 가장 가까운 직선거리의 데이터를 통해 예측하는 모델
- 특성 : 데이터를 표현하는 하나의 성질(예. 생선길이, 생선무게)
- 훈련 : 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정
- 정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)
2-1 훈련세트와 테스트 세트
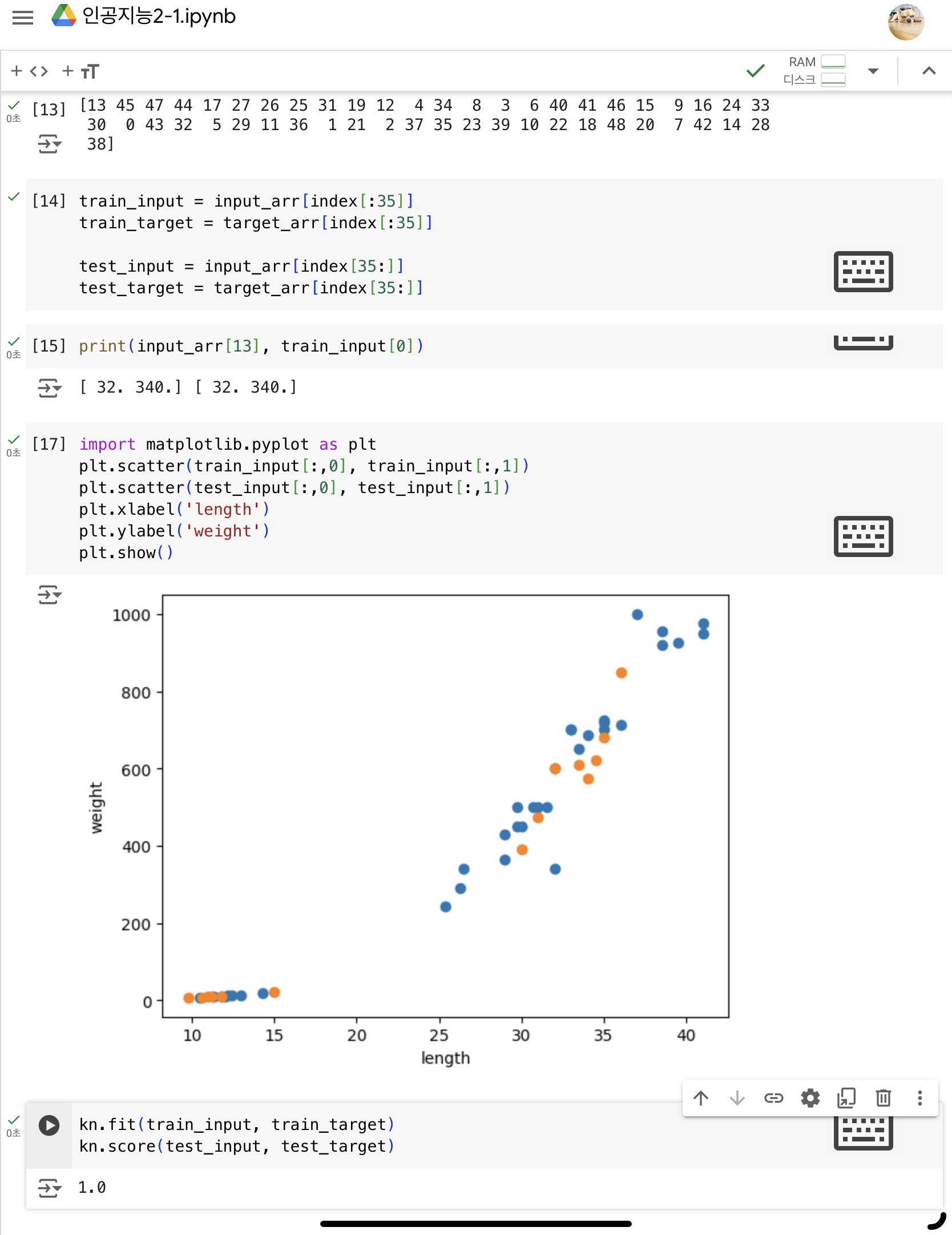
두 번째 머신러닝 프로그램 훈련/테스트 이용한 k-최근접 이웃 모델
- 지도 학습 : 입력(데이터)과 타깃(정답)으로 모델을 훈련한 후, 다음 새로운 데이터를 예측 (예. k-최근접 이웃 모델)
- 비지도 학습 : 타깃 데이터가 없이 입력 데이터에서 어떤 특징을 찾는 모델
- 훈련에 사용되는 데이터(훈련 세트)와 평가에 사용하는 데이터(테스트 세트)는 따로 준비되어야 한다.
훈련 세트와 테스트 세트가 나눠져 있지 않으면, 정답을 알려주고 평가하는 것과 같음- 데이터는 특정 종류의 샘플이 과도하게 많지 않도록 골고루 뽑아야한다.
샘플링 편향은 제대로된 훈련과 평가가 될 수 없다.
2-2 데이터 전처리
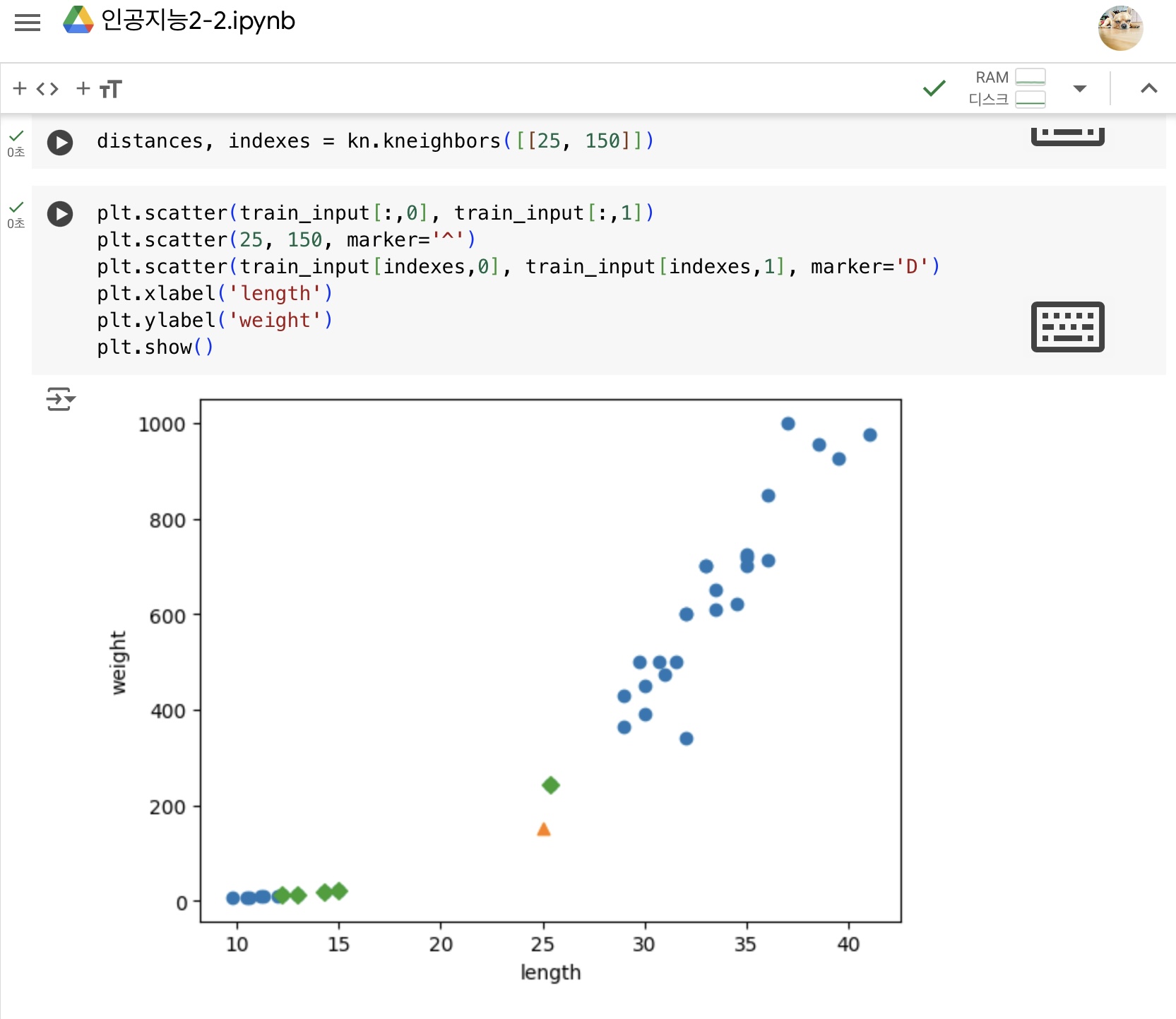
머신러닝 모델에 데이터를 주입하기 전에 데이터를 가공하는 단계
- 특성값을 일정한 기준으로 맞춰야 한다. (예. 표준점수)
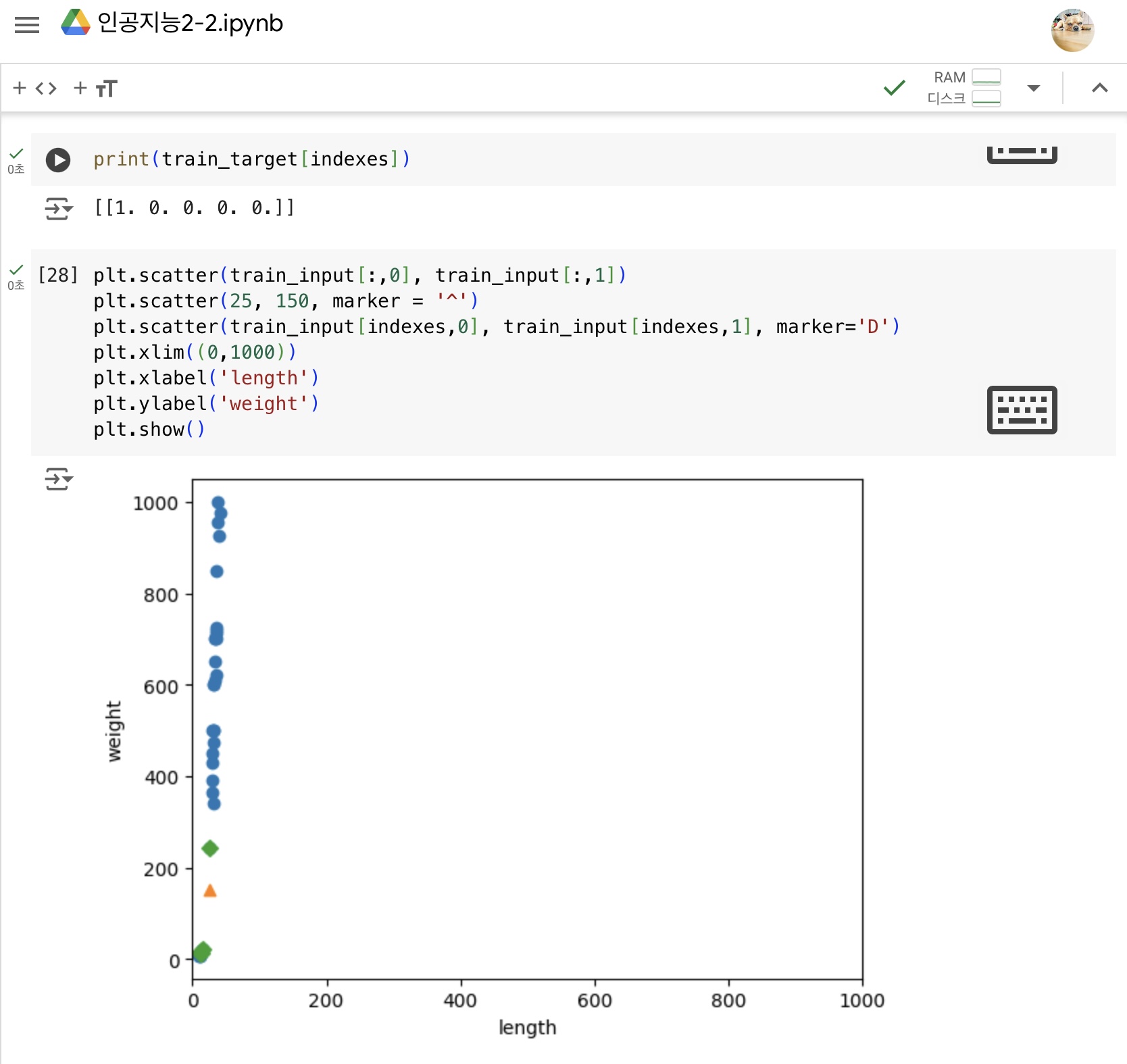
거리 기반으로 하는 알고리즘은 특성의 스케일이 다르면 올바르게 예측할 수 없다- 훈련 세트를 변환한 방식 그대로 테스트 세트를 변환해야 한다.
훈련 세트의 평균과 표준편차로 테스트 세트를 변환해야 같은 스케일로 산점도를 그릴 수 있음
특성의 스케일이 다름
기준 맞추기
전처리 데이터로 모델 훈련하기
1) 훈련세트와 동일한 기준으로 테스트세트를 변환하지 않아서 발생한 문제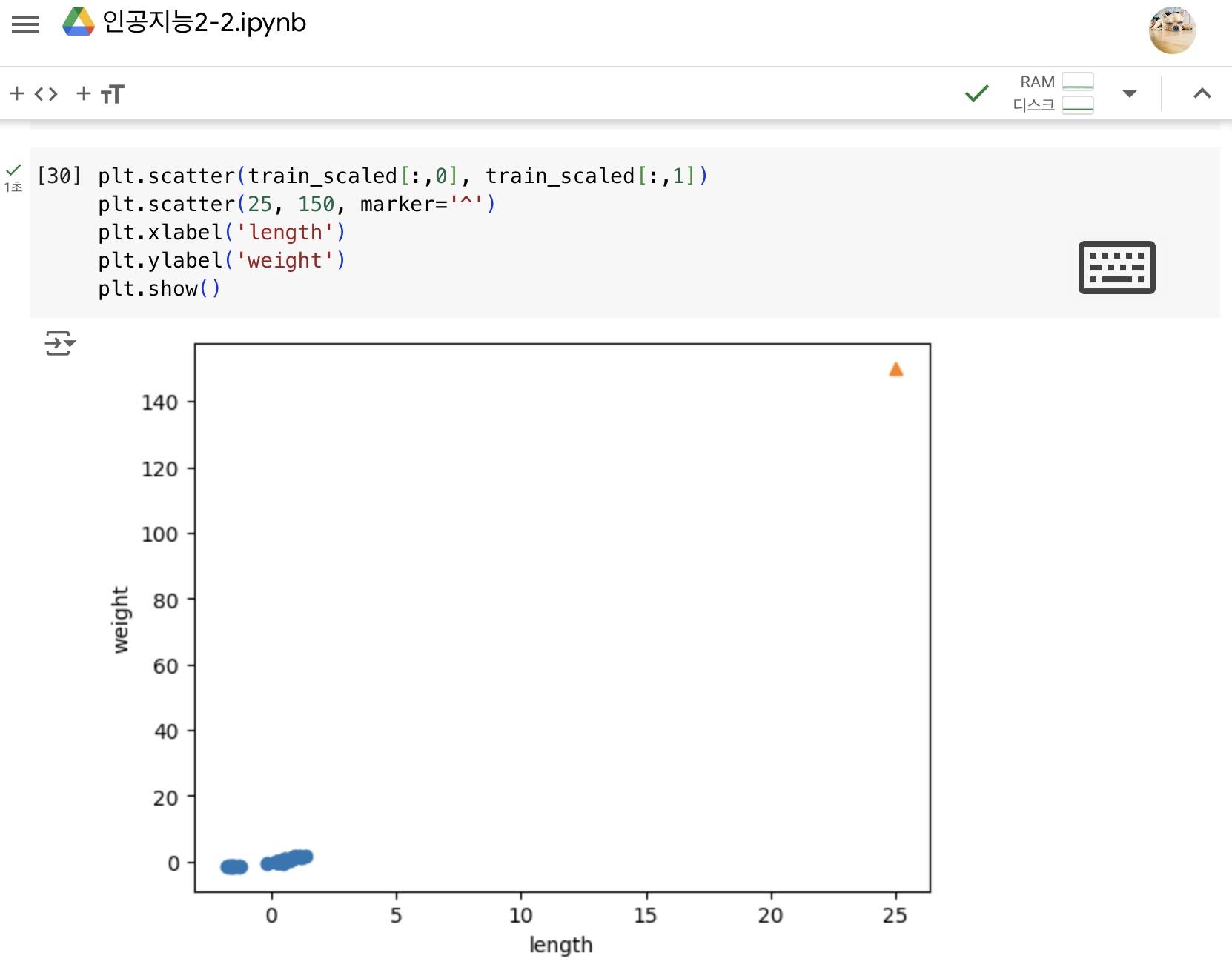
2) 동일한 기준으로 테스트 세트 변환 후 다시 예측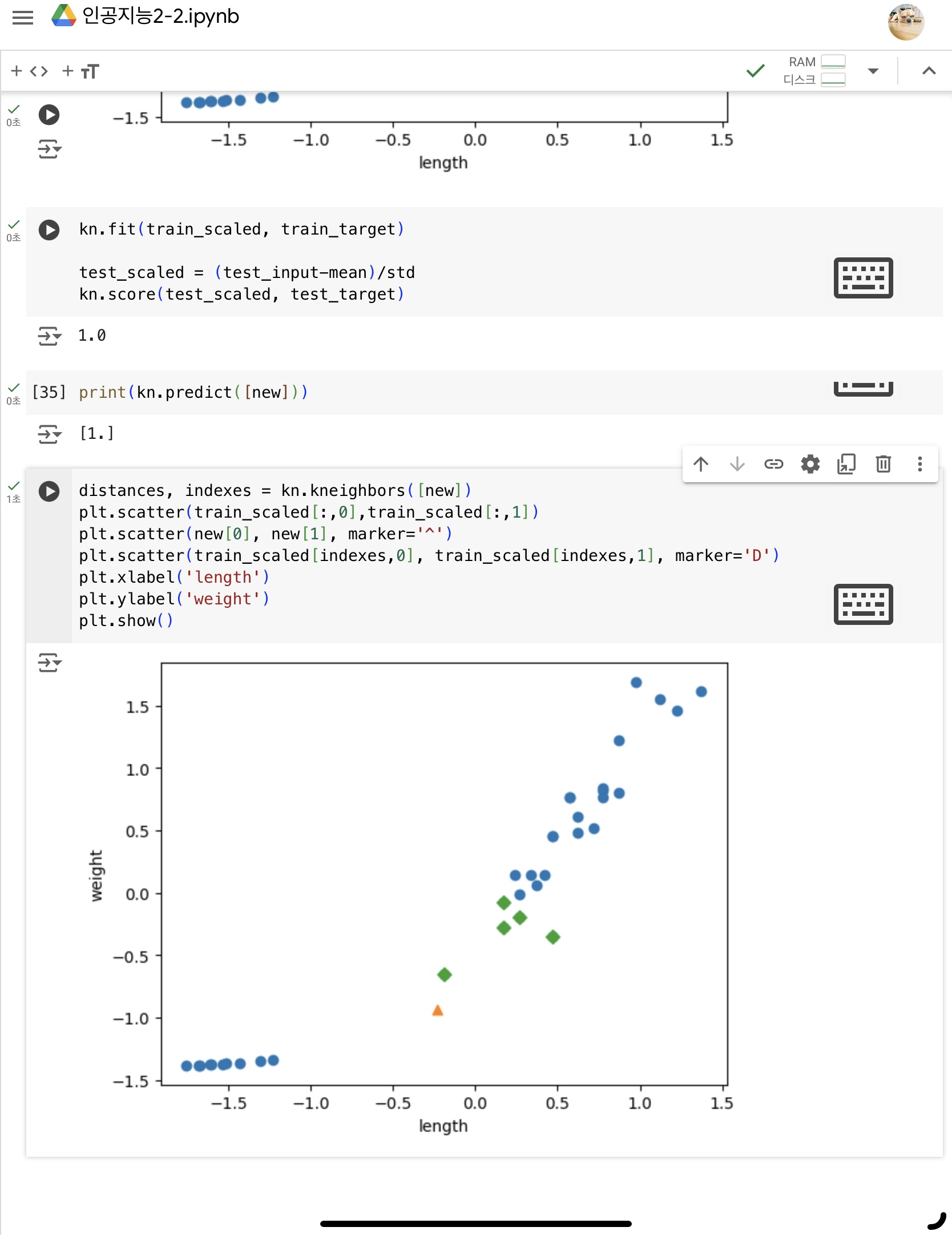
1주차 학습 일기
일주일이 정신없이 지나갔다.
해야지해야지하면서 미루다가 1주차부터 실패하는줄...
주말에 겨우 마무리했지만, 그래도 성공!!
퇴근하면 너무 피곤하지만, 조금씩 공부하는 습관을 길러보자..

공부기록