혼공머신 4주차
- Chapter 5) 트리 알고리즘
5-1 결정트리
문제 : 화이트와인, 레드와인 구분하기
특성 : 도수, 당도, pH
1) 로지스틱 회귀로 와인 분류
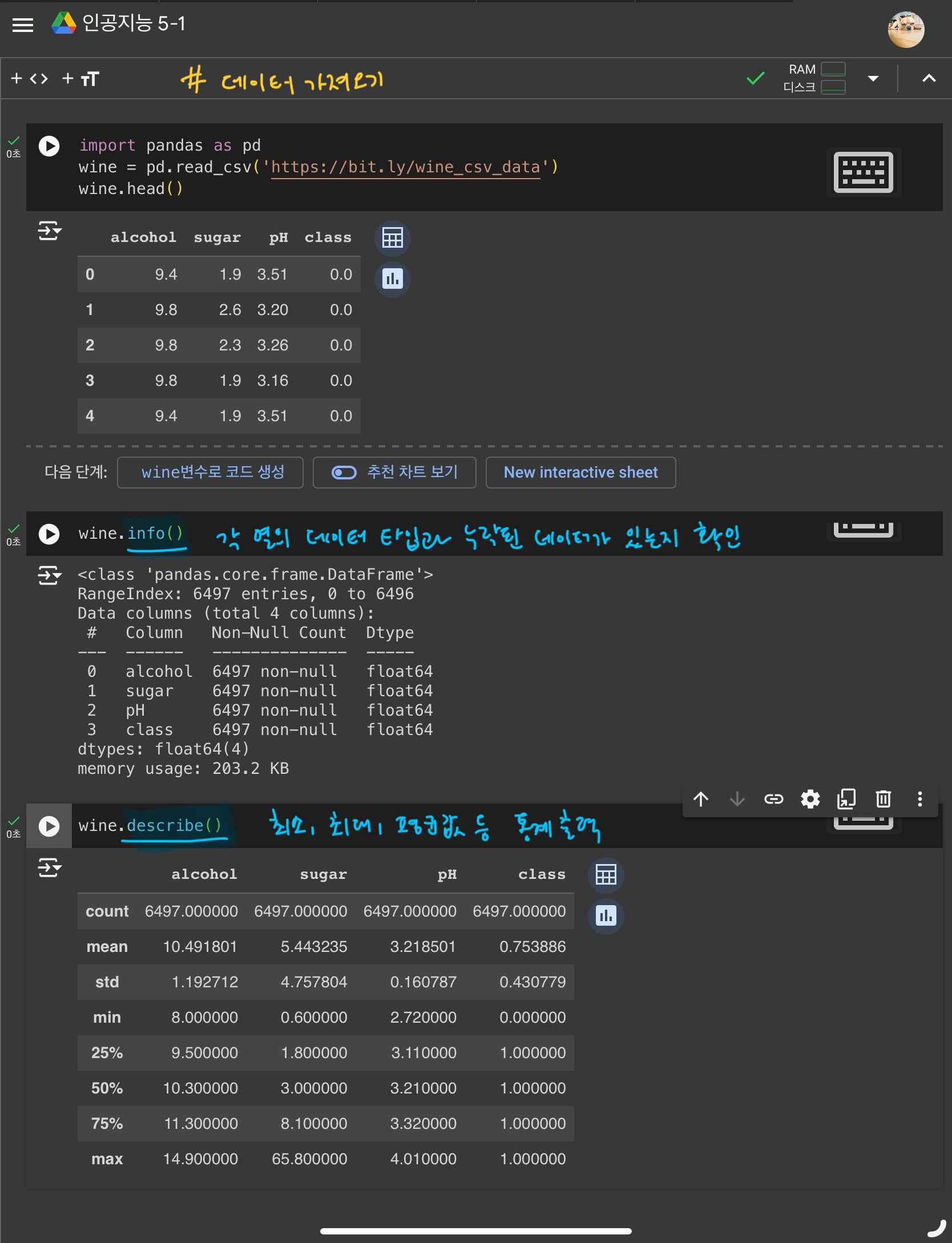

2) 결정트리
- 결정트리
예/아니오에 대한 질문을 이어나가면서 정답을 찾는 학습알고리즘
-> 비교적 예측 과정과 이유를 설명하기 쉽다.

가지치기
- 결정트리가 훈련세트에 과대적합되는 것을 억제하는 효과
-> 트리의 최대깊이를 지정한다.

- 특성값의 스케일이 결정 트리 알고리즘에 아무런 영향을 미치지 않음 -> 결정트리는 표준화 전처리 과정이 필요없다.
(전처리 전과 후 점수가 동일)- 결정트리는 어떤 특성이 가장 유용한지 특성중요도를 출력할 수 있다.

5-2 교차 검증과 그리드 서치
먼저, 일반화 성능을 올바르게 예측하기 위해 훈련세트, 검증세트, 테스트 세트로 나누기
1) 훈련세트로 훈련하고, 검증세트로 모델평가
2) 최적의 매개변수 선택하여, 전체 훈련세트(훈련+검증)로 다시 훈련
3) 테스트 세트로 최종 점수 평가
- 검증세트로 인한 훈련세트 감소 -> 교차검증 이용

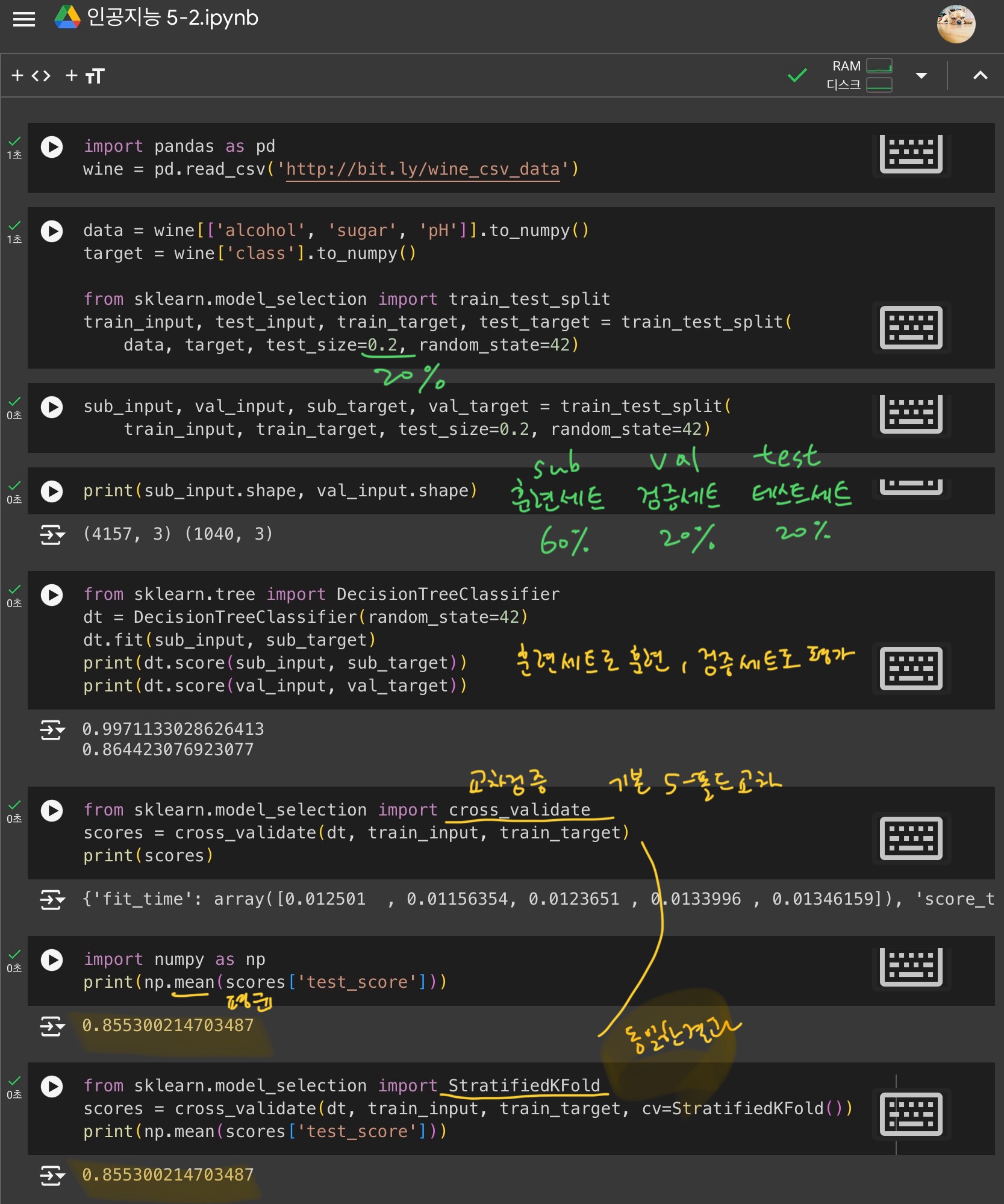
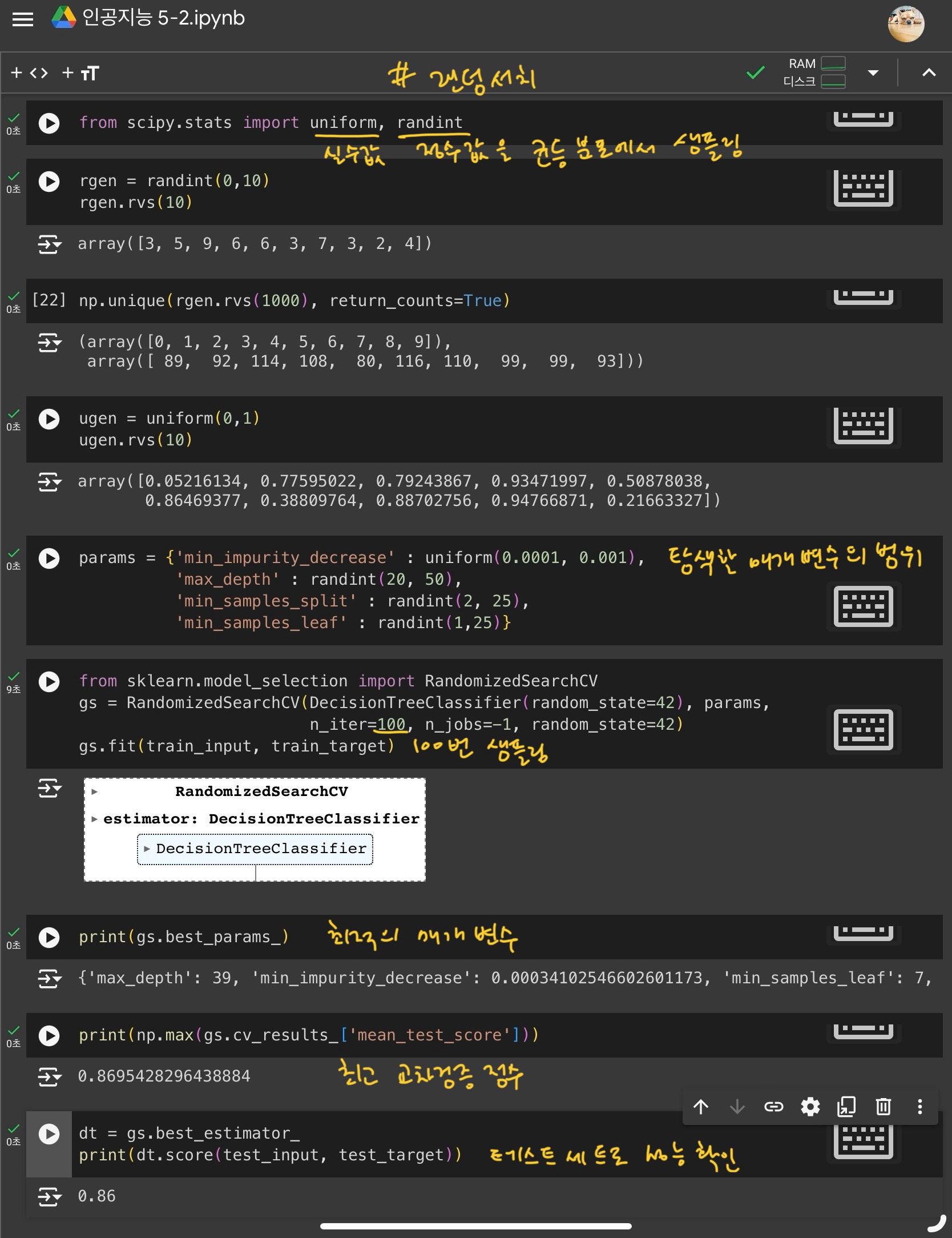
교차검증 도구 1) 그리드 서치
- 하이퍼파라미터 탐색 자동화도구

교차검증 도구 2) 랜덤서치
- 주어진 범위에서 고르게 샘플링하여 매개변수 탐색
5-3 트리의 앙상블
정형데이터에 뛰어난 성과를 내는 알고리즘 “앙상블 학습”
1) 랜덤 포레스트
- 데이터 세트에서 중복을 허용하여 데이터를 샘플링하는 부트스트랩 방식을 사용
- 부트스트랩 샘플에 포함되지 않는 OOB샘플을 검증 세트로 활용

2) 엑스트라 트리
- 랜덤 포리스트와 비슷하나, 부트스트랩 샘플을 사용하지 않고 전체 훈련 세트를 사용한다.
- 결정 트리의 노드를 랜덤하게 분할하여 훈련속도가 빠르다.
3) 그레이디언트 부스팅
- 깊이가 얕은 결정트리를 사용하여 높은 일반화 성능을 기대할 수 있는 방법으로, 과대적합에 매우 강하다.

4) 히스토그램 기반 그레이디언트 부스팅
- 그레이디언트 부스팅의 속도를 개선한 것으로, 훈련 데이터를 256개 정수 구간으로 나누어 빠르고 높은 성능을 낸다.
(가장 뛰어난 앙상블 학습으로 평가 받는 알고리즘)

4주차 학습 일기
이번 주차에는 많은 알고리즘이 등장해서, 많이 혼란스러웠다.
간단한 특징이나 차이점 정도 이해한 것 같은 느낌...ㅎㅎ
그보다 현재 맡은 업무에서도 학습데이터가 줄어든다는 부분을 교차 검증으로 보완해볼 수 있는지 고민해봐야겠다.
(이미 그렇게 하고 있는데 잘 몰랐던 걸지도... 검토해봐야지...)
알면 알수록 복잡하고 어려운 인공지능의 세계... @_@

공부기록