
프로젝트 예상 질문
Q. 해당 프로젝트 지원 동기에 대해서 소개해주세요.
A. 각자 지원 동기 읽어오기
Q. 비디오 검색 시스템 구축에서 가장 중요한 단계는 무엇이라고 생각하나요?
A. 비디오 검색 시스템 구축에서 가장 중요한 단계는 비디오 데이터의 특징 추출입니다. 이는 비디오의 내용을 효과적으로 인덱싱하고 검색할 수 있도록 하는 핵심 과정입니다. 특히, 다양한 특징(예: 시각적 특징, 텍스트 등)을 추출하고 이를 벡터화하여 데이터베이스에 저장하는 과정이 중요합니다. 이 단계의 정확성과 효율성이 전체 시스템의 성능을 좌우합니다.
Q. 비디오 특징 벡터를 생성하는 과정에서 중요한 고려 사항은 무엇인가요?
A. 비디오 특징 벡터를 생성하는 과정에서 중요한 고려 사항은 다중 모달리티(multimodality)를 반영하는 것입니다. 즉, 시각적 특징뿐만 아니라 시각적 프롬프트, 텍스트 등의 다양한 정보를 통합하여 벡터를 생성해야 합니다. 또한, 실시간 처리 요구사항을 충족하기 위해 특징 추출 알고리즘의 효율성을 최적화하는 것도 중요합니다. 마지막으로, 생성된 벡터가 검색 작업에서 효과적으로 사용될 수 있도록 데이터베이스 구조를 최적화해야 합니다.
Q. LLM을 사용하여 비디오 검색 성능을 향상시키는 방법은 무엇인가요?
A. LLM(대규모 언어 모델)을 사용하여 비디오 검색 성능을 향상시키는 방법은 텍스트 프롬프트를 통해 비디오의 내용을 더 잘 이해하고 검색 쿼리를 확장하는 것입니다. 예를 들어, 비디오의 캡션이나 설명을 분석하여 보다 풍부한 메타데이터를 생성할 수 있습니다. 또한, LLM을 사용하여 사용자 쿼리를 자연어로 입력받고 이를 비디오 특징 벡터와 매칭시켜 검색 결과의 정확도를 높일 수 있습니다.
Q. 비디오 검색 시스템의 성능을 어떻게 평가할 수 있나요?
A. 비디오 검색 시스템의 성능을 평가하는 방법으로는 검색 정확도, 정밀도, 재현율, F1 스코어 등이 있습니다. 또한, 검색 속도와 시스템의 확장성도 중요한 평가 지표입니다. 사용자 피드백을 통해 검색 결과의 품질을 평가하고, 실제 사용자 환경에서의 성능을 측정하는 것도 중요합니다. 다양한 평가 메트릭을 사용하여 시스템의 전반적인 성능을 종합적으로 평가해야 합니다.
Q. 비디오 검색 시스템에서 실시간 처리를 구현하기 위한 전략은 무엇인가요?
A. 비디오 검색 시스템에서 실시간 처리를 구현하기 위한 전략으로는 다음과 같은 것들이 있습니다:
-
효율적인 프레임 샘플링: 비디오에서 중요한 프레임만을 선택하여 처리 시간을 단축합니다.
-
경량화된 모델 사용: 실시간 추론이 가능한 경량화된 딥러닝 모델을 사용합니다.
-
분산 처리: 여러 노드를 사용하여 비디오 처리를 분산시켜 병렬로 처리합니다.
-
캐싱: 자주 사용되는 데이터와 검색 결과를 캐싱하여 응답 속도를 향상시킵니다.
Q. 비디오 데이터에서 텍스트 정보를 추출하는 방법에는 무엇이 있나요?
A. 비디오 데이터에서 텍스트 정보를 추출하는 방법으로는 이미지 캡셔닝을 사용할 수 있습니다. 캡셔닝을 통해 프레임 내의 장면을 설명하여 문장을 통해 LLM 이 잘 이해할 수 있도록 도울 수 있습니다.
Q. 비디오 검색에 필요한 작업과 데이터가 무엇일지 분석 및 연구는 무엇인가요?
A. 비디오 데이터 전처리 작업이 필요합니다. 그 후
Q. 비디오 검색 관련하여 본인 경험이 있을까요?
A. 네, 비디오 데이터를 활용한 이상치 탐지, 실시간 객체 탐지 및 segmentation, Video Processing 실습 등을 한 경험이 있습니다. 또한 2D 이미지 및 3D 모달리티의 데이터도 다수 다뤄본 경험이 있어 본 프로젝트를 수행함에 있어 부족함 없다고 생각하며 부족한 부분은 배워나가겠습니다.
YoloV5 실습
Object Detection in 10 minutes with YOLOv5 & Python!
Video Processing 실습
Video Data Processing with Python and OpenCV
Working with Video in Python [Youtube Tutorial]
본인 계정 실습 코드
Q. RAG 를 활용해본 경험이 있나요?
A. 네, Langchain의 chroma db를 통해 사용해보았습니다. 이번에는 Pinecone을 활용해볼 생각입니다.
Vector DB 모두를 비교한 sheet
해당 sheet 를 모두 같이 보면 좋을거 같음
Vector DB Comparison
Pinecone 에서 설명한 유사도 측정 방법 Docs
Pinecone Algo
Q. 실시간 영상 분석 방법과 전통적인 바운딩 박스와 클래스외에도 비디오에서 추출할 수 있는 유용한 데이터로는 무엇이 있을까요? 다양한 메타 데이터 정보를 어떻게 구할 것인가요?
A. 영상을 30초, 1분, 5분, 30분, 1시간 등의 간격으로 영상을 청크로 나누어 시간에 따른 객체의 다양한 통계 및 분석에 대해 생각해보았습니다. 이를 통해 지역적 및 전역적 이벤트에 대한 분석이 가능할 것으로 판단되고 영상의 구분 시간은 실험적으로 최적화하여 결정할 것입니다.
추가적인 메타 정보는 LLM을 통한 Caption 정보도 메타 정보로 활용될 수 있습니다. 예를 들어, 사람의 행동 패턴 인식을 한다면, 단순히 'person' 이라고 분류하는 것을 넘어 'runing person'을 분석하는 LLM을 기대하고 있습니다.
또한, 장면 분리 기법을 활용하여 하이라이트 인덱스를 추가하여 특이 사항이 있는 장면에 대해서 저장할 수도 있습니다.
Q. Scene 분리를 어떻게 할 것인가요?
A. 영상을 분석할 때 모든 프레임을 처리하여 저장하는 것은 자원이 한정된 상황에서는 불가능할 것 같습니다. 이를 보완하기 위해 영상을 일정한 초 단위로 나누어 각 청크를 분석하는 방법을 고려했지만, 이 경우 특정 이벤트가 설정한 초 범위를 벗어날 때 문제가 발생할 수 있습니다. 따라서, 하이라이트 요약에서 소개된 세그먼트 포인트를 학습하여 특정 초를 동적으로 조정함으로써 장면을 분리하면 보다 적절한 분석이 가능할 것 같습니다.
Q. 어떤 종류의 추론 모델을 사용할 건가요?
A. 영상 내 분석에는 이미지 인코더로 swin transformer를 사용하고 (기존의 vit는 고정된 패치로 인해 OD에서 아쉬운 성능을 내는 것이 밝혀짐) 텍스트 인코더로는 clip에서 사용된 text encoder를 사용할 것입니다. 이후, bidirection cross attention을 통해 early fusion을 진행하고 MaskDINO 디코더를 사용하여 OD 및 객체 중요 정보를 추출할 계획입니다.
Q. 프로젝트를 진행하면서 예상되는 어려움과 도전 과제는 무엇인가요? 그리고 어떻게 극복할 계획인가요?
A. 네, 아마 예상되는 어려움은 대규모 데이터 처리와 서비스 배포 및 기획일 것 같습니다. 이 부분은 저희팀 자체적으로 주말마다 모여 FastAPI, Docker를 활용한 AI 모델 배포 스터디 및 비디오 데이터를 활용한 모델링 스터디를 하고 있으며, 프로젝트 기간동안 부족한 부분은 팀원들과 같이 스터디를 통해 극복할 계획입니다.
Q. "Open world object detection"과 "Closed world object detection"의 차이점은 무엇일까요?
A. closed world object detection은 훈련 과정에서 GT로 예측할 클래스를 제한합니다. 반면에, Open world object detection은 훈련과정에서 관찰되지 않은 새로운 클래스를 감지하는 것입니다.
해당 프로젝트에서는 모든 클래스에 대해 사전훈련을 진행하기 어려우므로 Open world object detection 모델을 사용하여 OD의 제로샷 성능을 높이고자 합니다.
Q. 기존의 Early Fusion과 뭐가 다른 건지 말해주세요.
A. 해당 프로젝트에서는 Late Fusion과 Early Fusion 중에 Early Fusion을 선택했습니다. 이는 각 모달리티 인코더의 출력을 디코더에 들어가기 전에 결합하여 전달하는 것을 의미합니다. 이때, 단순한 행 단위로 concat하는 것이 아니라 각 모달리티 인코더의 출력을 크로스 어텐션을 통해 결합하고 이를 정해진 레이어에 대해 반복합니다. 마지막으로, 이러한 결합된 각 인코더의 출력을 concat하여 디코더의 입력으로 전달합니다.
Q. 객체 추적의 방식에 대해 설명해주세요.
A. 객체 추적은 먼저 텍스트 쿼리를 통해 추적하고자 하는 객체를 식별합니다. 이후 Object Foundation 모델을 통해 영상 내 객체의 바운딩 박스 좌표 정보를 추출하고 이를 데이터베이스에 저장합니다. 추가로, 추적된 객체의 중심점을 기준으로 해당 클래스의 객체가 움직인 거리를 5초나 설정된 n초 간격으로 클래스 마다 다른 색으로 표시하며 영상에서 추적하는 작업을 수행할 것입니다.
Q. 왜 GLEE 모델을 사용하나요? YoloV9 같은 모델과의 차이점이 있을까요?
A. GLEE의 경우 open world 모델이기 때문에 어떠한 상황이 입력되어도 대응할 수 있다는 장점이 있습니다. 그리고 텍스트 모달리티와 비주얼 프롬프트가 같이 학습되었기 때문에, 검색시 텍스트 쿼리를 잘 이해할 수 있다는 장점이 존재합니다. 또한, 하나의 Unified Foundation model 을 통해 여러 메타 정보와 특징 벡터를 얻을 수 있다는 강력한 장점이 존재하기 때문에 GLEE 모델을 선택하였습니다.
Q. 관련 multimodal 경험이 있을까요?
A. 저는 석사 연구 분야로서 Vision Language Model을 활용해 VQA관련 연구를 진행 중입니다. VQA에서는 다양한 문제점이 존재하는데 그 중에서도 텍스트 쿼리로 영어와 한국어를 동시에 받더라도 단일 언어와 유사한 성능을 보이도록 모델을 고도화 중에 있습니다. 이 연구를 수행할 때 비디오 텍스트 retrieval 관련 논문들이 많아 이를 리뷰하여 비디오 검색에 필요한 선행 연구를 따라갔습니다.
영상 간 검색 질문
Q. Frame Encoder 와 Temporal Encoder 에서 출력값이 나오는데 해당 출력값은 무엇을 의미하는지?, 그리고 적절한 stride를 통한 overlapping chunks는 어느정도인지?
A. 먼저 1초당 1프레임으로(1FPS) 샘플링합니다. Frame Encoder 는 12 layer 의 ViT를 사용하고, Temporal Encoder 는 public CLIP의 가중치를 사용할 것이며 Frame Encoder의 출력값에 Position 을 더해 입력값으로 주어 최종 출력 feature vector 는 ViT 구조와 동일하게 [CLS] Token 을 사용할 예정입니다. 해당 Token 은 비디오를 대표하는 feature vector 로 Vector database 에 저장되고 텍스트 검색시 유사도 측정을 기반하여 연관된 비디오를 검색할 수 있도록 구현할 예정입니다. 또한 참고한 논문은 X-CLIP 논문입니다.
Q. 비디오 영상 검색 시 top K 를 뽑는데, 유사도 측정은 어떻게 할 예정인가요?
A. 코사인 유사도를 통해 측정할 예정입니다. ViT와 CLIP 등 사용할 논문에서 특징 벡터를 만들 때 내적을 통한 유사도를 측정하기 때문에 코사인 유사도를 통해 측정하는 것이 벡터 데이터 베이스에 저장된 벡터와의 유사도 측정에 적합하다고 생각합니다.
Similarity Search
Choosing Indexes for Similarity Search (Faiss in Python)
영상 하이라이트 요약 질문
Q. 비디오 영상 하이라이트 요약에 대해 자세히 설명해주시겠어요? (이건 내꺼임 :) )
A. 영상 하이라이트 요약 과정에 대해 설명 드리겠습니다. 훈련 과정에서 영상 분석을 기반으로 이벤트 발생 시점을 예측하는 하이라이트 인덱스를 학습하고 이를 활용해 영상 요약 보고서를 생성합니다. 구체적인 예시를 소개해드리자면 24시간 동안 이벤트가 총 10번이 일어났다고 가정하면 관제사는 인수인계 시 직접 영상을 찾지 않고 LLM에게 요약 프롬프트를 전달하면 해당 이벤트에 대한 요약 정보를 영상과 함께 텍스트로 받을 수 있습니다.
Faiss
위의 Similarity Search 강의를 듣고 간단히 정리해보았다.
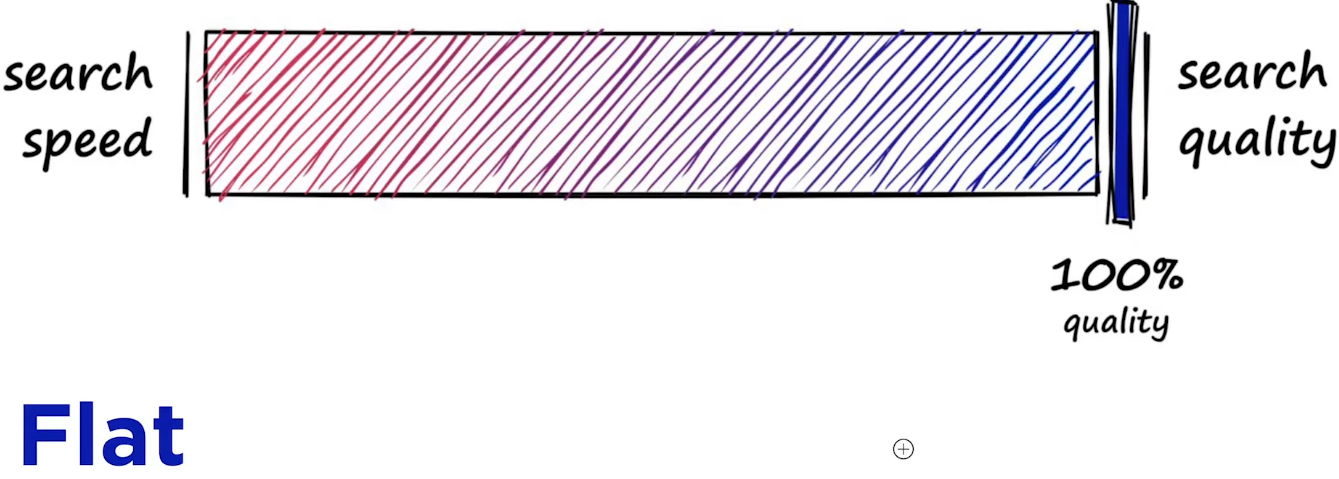
IndexFlateL2 인덱싱 방식
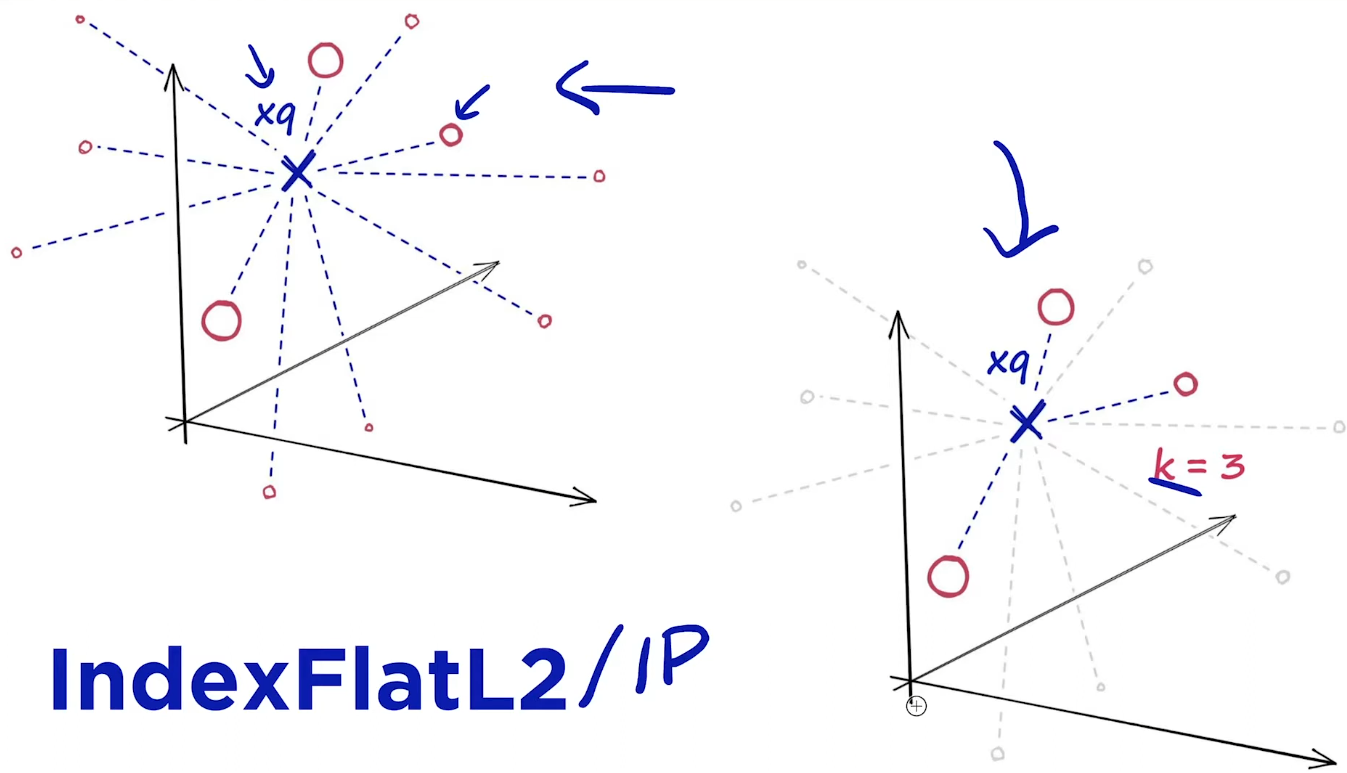
모든 벡터를 메모리에 직접 저장하고 유클리드 거리(L2 거리)를 사용하여 검색을 수행한다.
- 직접 저장(Brute Force Search)
- 유클리드 거리(L2 Distance)
대신 이렇게 모든 항목에 대해서 검색하다 보니 시간이 오래 걸릴 수 있다. Search quality와 search speed는 반비례하는 관계를 가지고 있다.
import numpy as np
import faiss
# 데이터셋과 쿼리 벡터 생성
d = 128 # 벡터의 차원
nb = 10000 # 데이터셋 내 벡터의 수
nq = 5 # 쿼리 벡터의 수
# 랜덤 데이터 생성
np.random.seed(1234)
xb = np.random.random((nb, d)).astype('float32')
xq = np.random.random((nq, d)).astype('float32')
# 인덱스 생성 및 데이터셋 추가
index = faiss.IndexFlatL2(d)
index.add(xb)
# 쿼리 수행
k = 4 # 검색할 이웃의 수
D, I = index.search(xq, k) # 쿼리 벡터 xq에 대해 k개의 최근접 이웃 검색
# 결과 출력
print(I) # 인덱스
print(D) # 거리LSH 인덱싱 방식
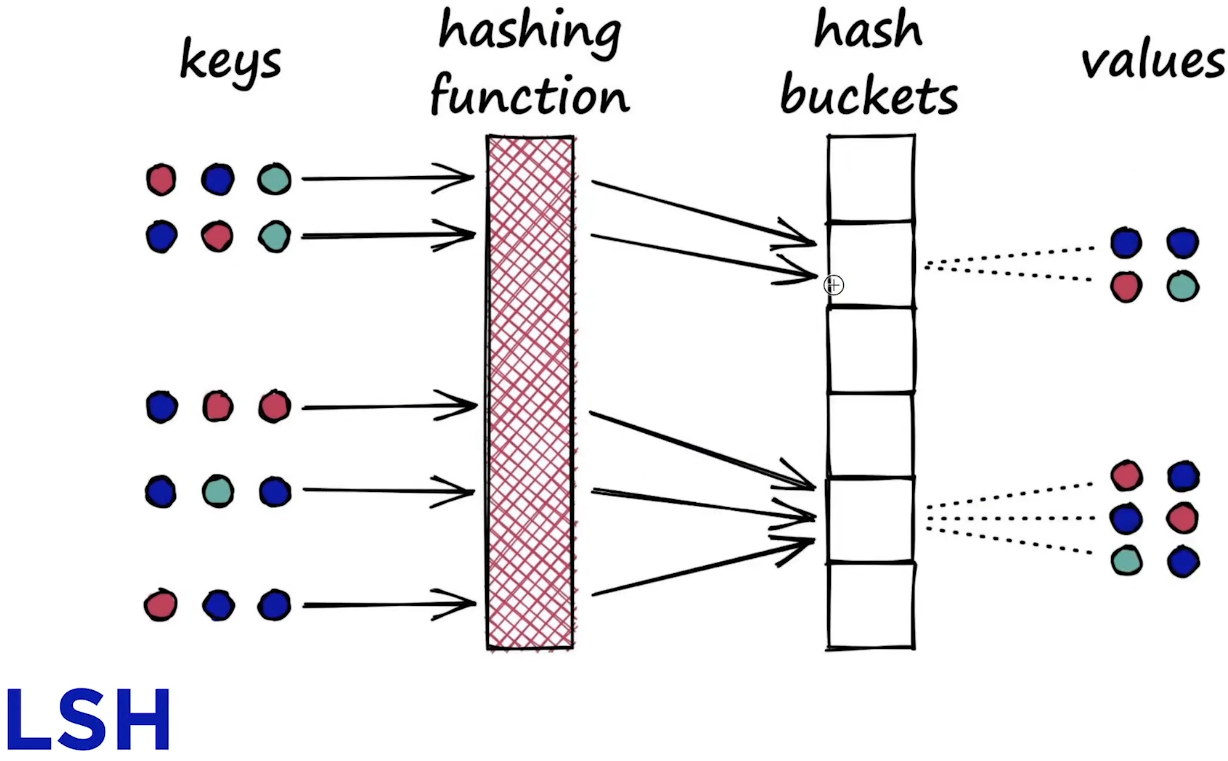
Locality-Sensitive Hashing(LSH) 은 고차원 데이터에서 근사 최근접 이웃(Approximate Nearest Neighbor, ANN)을 효율적으로 찾기 위한 기법 중 하나이다. LSH는 유사한 항목들이 같은 해시 버킷에 들어갈 확률이 높은 해시 함수를 사용하여, 검색 공간을 축소하고 검색 속도를 높인다.
LSH 방식은 search quality를 조금 줄이는 대신에 search speed를 빠르게 하였다.
HNSW 인덱싱 방식
Hierarchical Navigable Small World(HNSW) 방식이다.
Navigable Small World(NSW) 가 무엇인지 간단히 살펴보자. Small world network 특성을 활용하는데, 이는 노드 간의 평균 경로 길이가 짧고, 클러스터링 계수가 높은 특성을 가진다. 클러스터링 계수가 높다는 의미는 네트워크 내에서 노드들이 밀집된 그룹을 형성하고 있다는 것을 의미한다. (수식은 Local/Global Clustering Coefficient를 찾아보면 된다.)
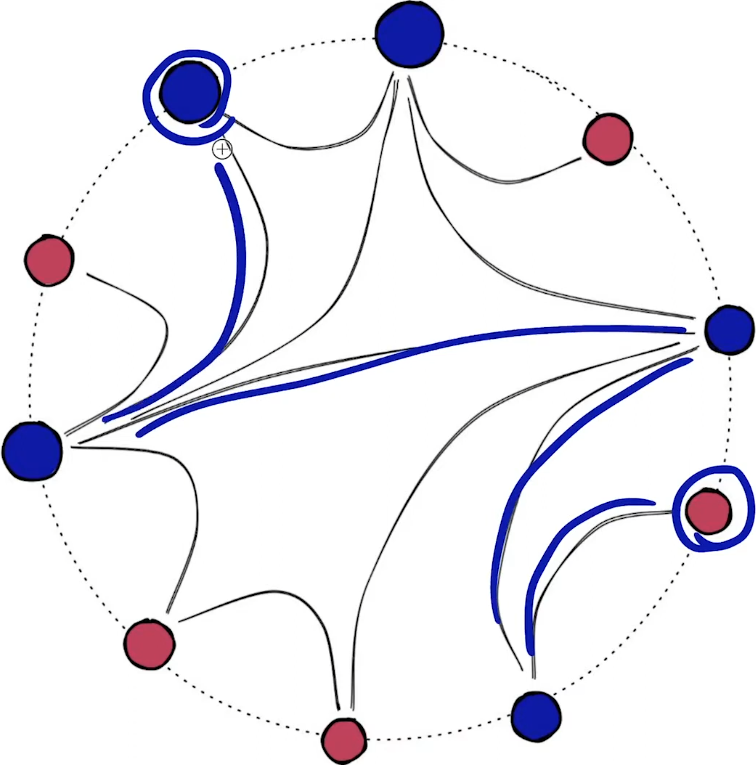
HNSW 는 NSW가 계층적으로 구성된 것을 의미한다.
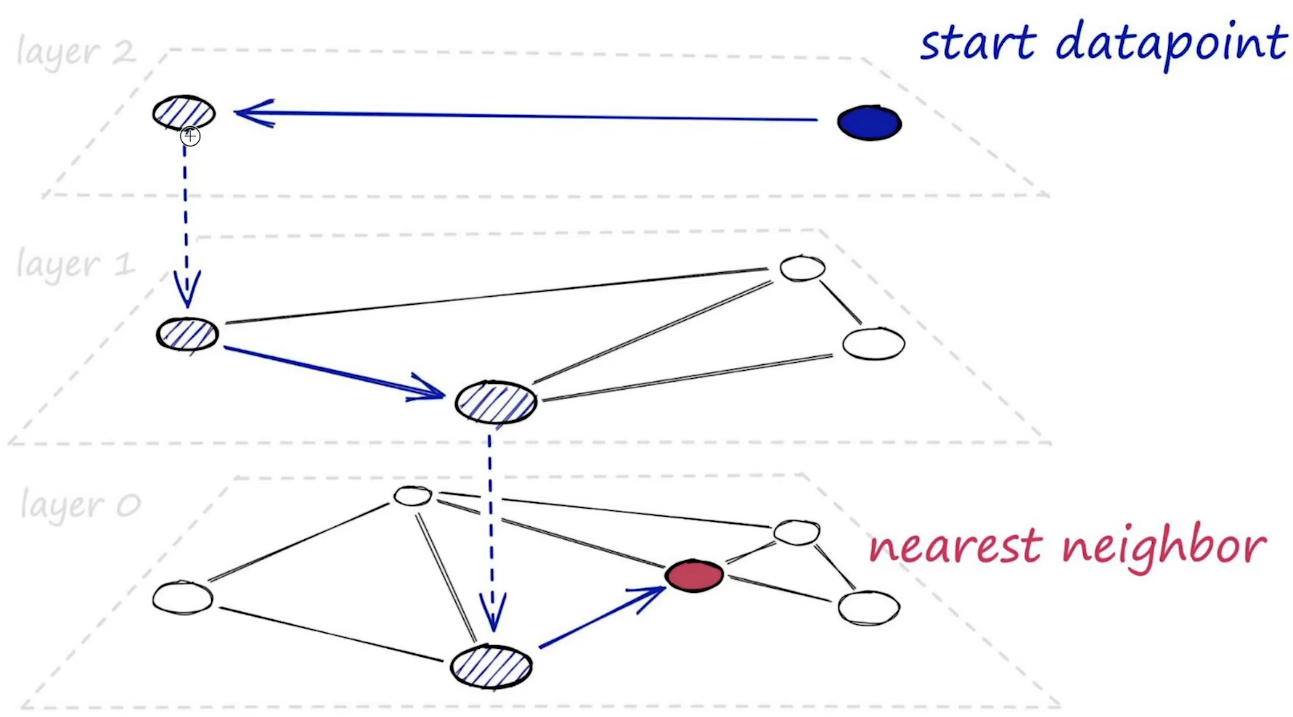
IVF 인덱싱 방식
Inverted File Index(IVF)는 데이터 포인트를 여러 클러스터로 나누고, 각 클러스터를 개별적으로 검색하는 구조를 가지고 있다. 클러스터를 나눌 때, 공간 분할 기법으로 Dirichlet Tessllation을 활용하여 클러스터링 작업을 수행한다.(해당 기법은 따로 찾아보길 권한다.)
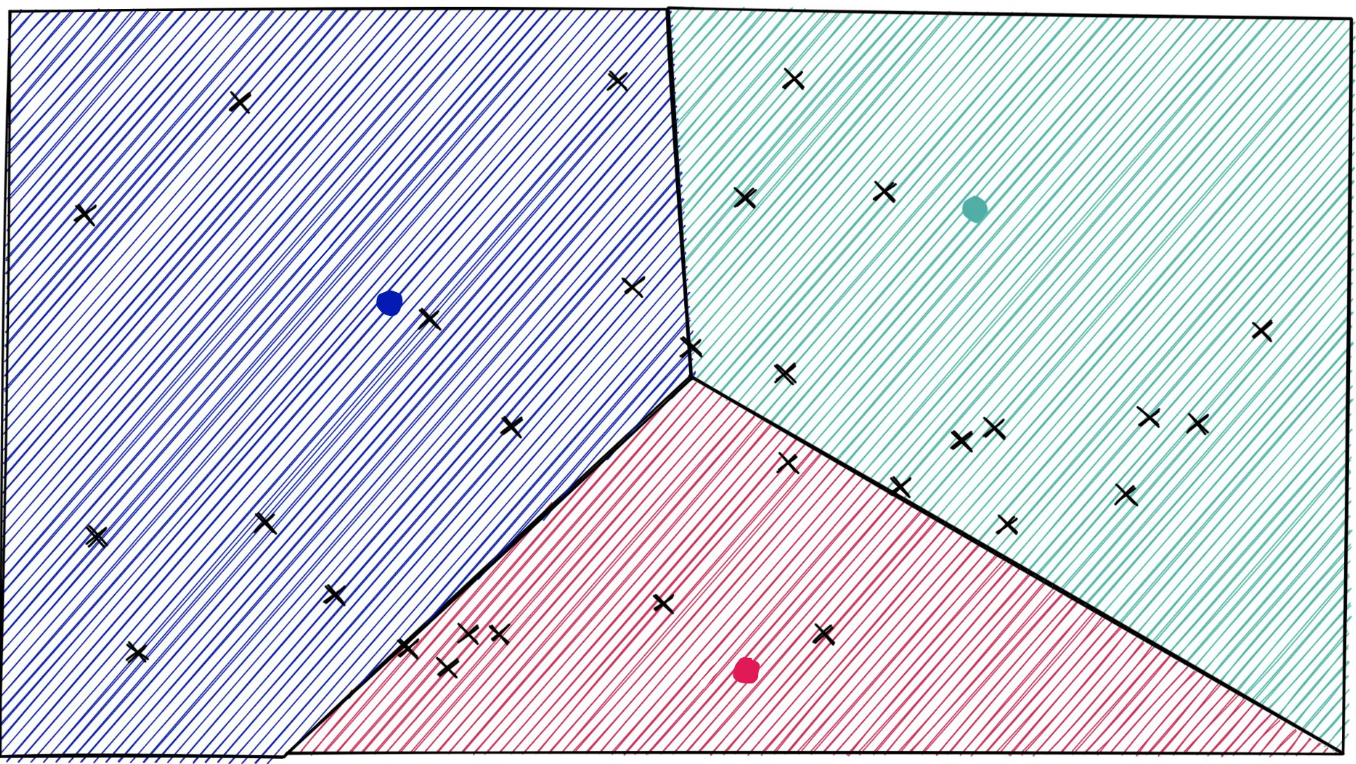
공간 분할이 끝나면 query에 대해 해당 클러스터 내에서만 검색을 수행하는 방식이다.

면접이 끝났다!!!
Q. Rag 경험 있는지?
Q. 그러면 추가로 DB 구축 하면서 어렵움은 없었는지?
Q. Prompt Tuning한 경험이 있는지
Q. 다 할 수 있을까?
Q. 백엔드 프론트 엔드 경험은 없는지
Q. 같이 프로젝트를 한 경험이 있는지?
Q. 팀워크는 괜찮은지?
대략 위 7가지 질문을 받았고 우리 팀은 정말 모든 질문에 대해 잘 답변하였다. 이제는 진인사대천명이다... 후... 제발ㅠㅠ
최종 합격하였습니다!!

