안녕하세요🤗 ~!
SKT AI Fellowship 6기 '대규모 Multimodal AI모델을 이용한 영상 검색 시스템 개발' 연구를 수행한 📺텔레토비전 팀📺 입니다 ~!
이번 글에서는 지금까지 연구한 내용을 정리하여 말씀드리고자 합니다.
1. 연구 주제 및 목표
💡 연구 배경 및 필요성
기존의 AI를 활용한 지능형 관제 시스템은 사전에 정의된 이벤트만을 탐지하고 분석할 수 있기 때문에 다양한 사용자의 요구를 충족하기 어렵습니다.
또한, 관제 시스템 UI는 현재 대부분의 업체가 거의 동일한 형식을 사용하고 있으며, 이는 Open Set 검색 및 분석이 불가능한 한계점을 가집니다.
따라서, 본 연구는 대규모 Multimodal AI 기술을 이용한 영상 검색 및 분석 시스템의 도입을 통해 기존의 지능형 관제 시스템을 개선시키고자 하였습니다.
Smaller Large Language Model, Retrieval-Augmented Generation 등 최신 AI 기술을 활용하여 실시간 관제 시스템을 고도화 하고자 합니다.
이를 통해, 관제 시스템 UI에 정의되지 않은 데이터를 검색하고 영상에 대한 설명문 생성, 통계 분석 시각화 등의 지식 기반 서비스를 개발하고자 합니다.
Multimodal AI 모델은 다양한 정보를 활용하여 단일 모달로는 해석하기 어려운 복합적인 상황을 이해하는 능력이 지속적으로 향상되고 있습니다.
Large Language Model의 발전으로 자연어 이해를 통해 인간과 소통하며 복잡한 문제를 효과적으로 처리할 수 있습니다.
AI 기술은 무어의 법칙보다 빠른 속도로 발전하고 있는 추세로 우수한 성능의 AI 모델을 적극적으로 활용하여 실제 서비스에 적용할 필요가 있습니다.
1) 연구 목표
사용자에게 중요한 영상을 검색하고 영상의 상세한 설명을 제공하는 영상 검색 서비스 개발을 목표로 서비스 관점과 기술적 관점 2가지로 접근하였습니다.
1. 기존 실시간 관제 시스템에 추가하고자 하는 서비스
- 텍스트 검색 기반의 영상 간 검색 시스템 (e.g. “비가 오는 밤에 촬영된 영상을 찾아줘)
- 전체 영상에서 중요한 영상을 추출하는 영상 내 검색 시스템 (e.g. “이 영상에서 주황색 상의를 입은 남성이 지나간 장면을 추적해줘”)
- 요약문 및 시각화 그래프를 제공하는 영상 분석 시스템 (e.g. “이 영상에서 3:00 ~ 5:00 분 사이에 지나간 사람들의 성비 분포는 어떻게 돼?”)
2. 추가하고자 하는 서비스를 위한 기술 및 연구적 접근
- 영상으로부터 유용하고 다양한 데이터를 저장 및 추출하여 데이터베이스를 구축.
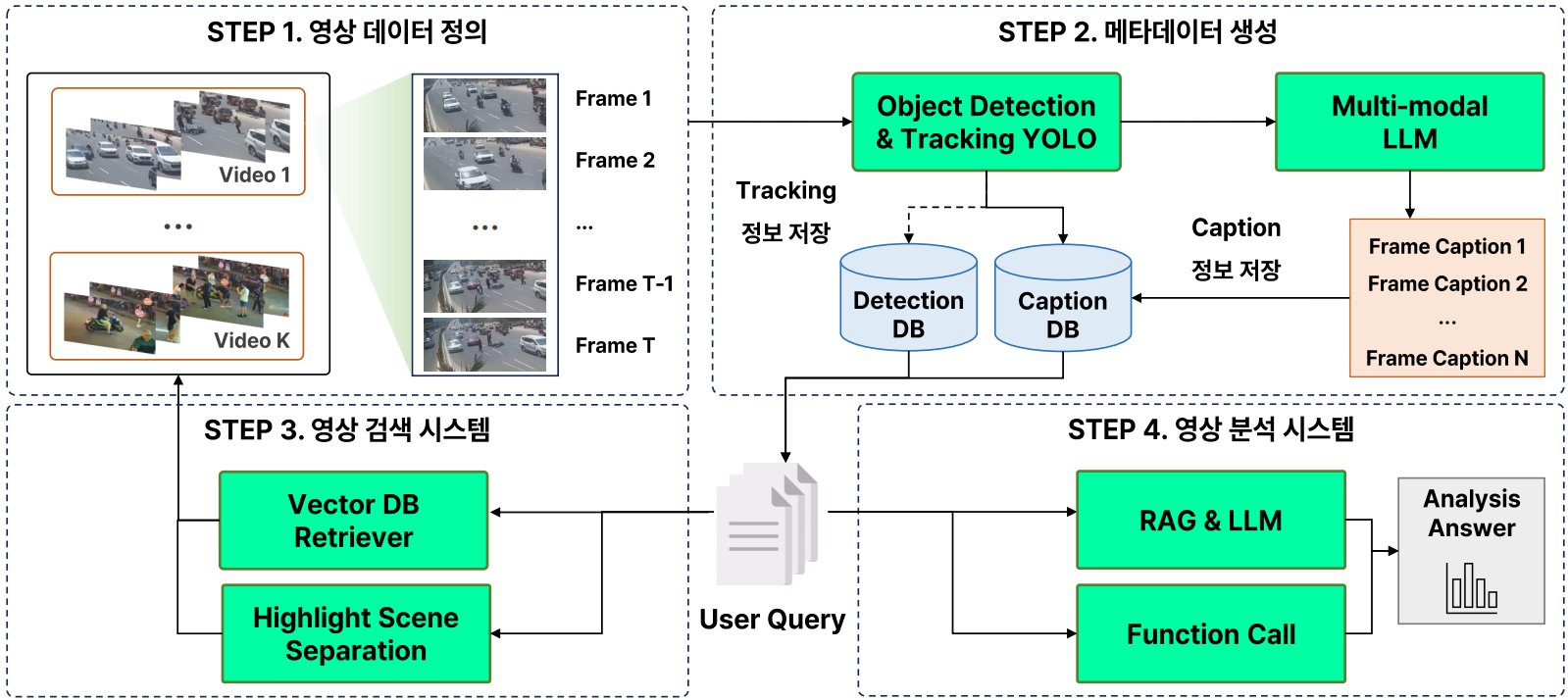
따라서, 저희는 크게 (1) 영상 데이터 정의 및 메타데이터 생성, (2) 영상 검색시스템, (3) 영상 분석 시스템 개발을 통해 VMS에 효과적인 시스템을 개발하고자 합니다.
2) 전체 파이프라인 설계
텔레토비전의 전체 파이프라인 설계는 다음과 같습니다.
2. 영상 데이터 정의 및 메타데이터 생성
1) 실시간 관제 시스템의 영상 데이터 특성
영상 데이터는 다음과 같이 정의하였습니다.
VMS 상에 수집되는 데이터는 긴 영상 특성으로 이벤트 발생 시점을 탐지하기 어렵우며, 실시간 영상임으로 즉시 분석이 요구되며 지연 없이 빠르게 처리하는 것이 중요합니다.
따라서 "실시간 긴 영상 데이터를 저장된 짧은 영상 데이터로 변환하여 검색 및 분석에 활용" 하고자 하였습니다.
2) 메타데이터 정의 및 처리
메타데이터 생성의 목표는 "영상으로부터 유용하고 다양한 메타데이터 추출 및 생성" 입니다.
비디오 영상 원시 데이터를 저장하고 활용하는 방법은 현실적으로 제약이 많기 때문에 이미지 프레임 단위의 데이터를 활용하였습니다.
실시간 영상 데이터를 가치 있는 데이터로 가공하기 위해 영상으로부터 객체 식별, 객체 추적, 객체 간 관계에 대한 정보를 추출해야 합니다.
-
객체 식별 특징: Class ID, Bbox를 통해 영상으로부터 나타나는 중요한 객체에 대해 정확한 위치와 크기를 식별합니다.
-
객체 추적 특징: Class Num, Track ID를 통해 시간의 변화에 따른 객체의 동적 특성을 분석하여 시공간적 변화를 파악합니다.
-
객체 간 관계 특징: 객체 식별 및 추적 특징을 통해 객체 간 상호작용을 반영하는 Caption을 생성하여 영상을 대표하는 데이터를 생성합니다.
3) 메타데이터 데이터베이스 구축
"메타데이터 Detection 및 Caption 데이터베이스 구축 및 저장" 하고자 하였습니다.
Detection DB는 사용자가 특정 영역을 마킹(e.g. Line, Polygon)하고 지정 영역을 분석(e.g. Region Counting)에 활용됩니다.
- ByteTrack YOLOv8 모델을 통해 K개의 실시간 영상을 병렬 처리하여 30 FPS 기준으로 Car, Person, Bike의 Bbox와 Track ID를 추출합니다.
Caption DB는 Multi-modal LLM을 통해 생성된 프레임 캡션의 모음으로 영상 검색 및 분석에 활용됩니다.
- Vip-LLaVA-7b 모델을 통해 1 FPS 기준으로 영상을 설명하는 Caption을 생성합니다.
4) Caption 생성 아이디어
" Verbalization 및 Temporal Prompt 방법론 채택"
프레임 단위의 caption 생성 시 발생하는 문제를 해결하기 위해 Verbalization 및 Temporal Prompt 방법론을 제안하였습니다.
-
프레임 단위의 분석으로 인해 전체 영상의 시간적 흐름에 따른 문맥을 파악하여 정밀한 분석을 진행하는데 한계가 존재하였습니다.
-
프레임 이미지만을 LLM의 입력으로 사용할 경우, 객체에 대한 인식 성능과 객체 간 상호작용을 정확히 파악하는데 한계가 존재하였습니다.
Verbalization은 이미지 프레임으로부터 실시간 다중 객체 탐지 및 추적 정보를 추출하여 텍스트 프롬프트로 변환 후 LLM의 입력 값으로 사용하는 기법입니다.
Temporal Prompt는 시간적 문맥에 따른 답변을 생성하기 위한 System Prompt 및 User Prompt를 설계하고 최적화하는 작업입니다.
5) Verbalization 캡션 생성
ByteTrack YOLOv8 모델을 사용하여 프레임에 대한 Class ID, Bbox, Class Num, Track ID를 추출합니다.
추출된 정보를 언어화 하여 보조 프롬프트를 생성한 후 거대 언어 모델의 입력 값으로 사용합니다.
E.g. "Can you please describe this image? The image includes bounding box and their objects: [0.64, 0.12, 0.78, 0.17] person, and [0.61, 0.11, 0.63, 0.30] car, and [0.42, 0.16, 0.46, 0.23] bike.“
Bbox 값은 이미지 크기를 기반으로 최대-최소 정규화와 소수점 둘째자리 반올림 처리를 진행합니다.
Verbalization 방법론을 적용하면 객체에 대한 인식 성능과 상황에 대한 답변의 정확성이 향상되었습니다.
-
최대-최소 정규화를 하지 않으면, Bbox를 인식하지 못하고 위치가 맞지 않다는 답변을 생성하게 되었습니다.
-
소수점 반올림을 하지 않으면, 입력 토큰 개수 길이가 너무 증가하여 답변의 품질이 떨어지는 문제가 발생하였습니다.
따라서, 텔레토비전팀이 최종적으로 사용한 프롬프트는 다음과 같습니다.
6) 메타데이터 생성 결과
"객체 개수에 대한 답변 생성 및 상황에 대한 답변 정확성 향상"
메타데이터를 생성한 결과는 아래와 같습니다.
이제 영상 검색 시스템을 어떻게 구축하였는지 말씀드리겠습니다.
3. 영상 검색 시스템
1) Vector DB를 활용한 영상 검색
"Vector DB와 LangChain을 활용한 영상 검색 시스템 개발"
영상 데이터로부터 생성된 caption 데이터를 활용하여 Text to Video Retrieval 문제를 Text to Text Retrieval 문제로 환원하였습니다.
각 영상의 프레임 캡션을 병합하여 영상을 대표하는 비디오 캡션을 생성하고 비디오 캡션의 모음을 하나의 DB로 구축한 후 영상 간 검색을 진행하였습니다.
2) 하이라이트 영상 추출 아이디어
"긴 영상 데이터를 짧은 영상 데이터로 변환하는 프레임 유사도 기반 영상 분할 방법론 제안"
VMS 시스템의 Live Cam은 긴 영상 데이터로 프레임 기반 영상 간 검색 시 중요한 이벤트 탐지에 문제가 발생할 수 있습니다.
-
하나의 긴 영상에서는 다양한 이벤트 프레임이 나타날 수 있기 때문에 특정 이벤트 탐지 성능이 떨어질 수 있습니다.
-
하나의 긴 영상은 대부분 이벤트가 없는 일상적인 프레임으로 구성되어 있으며 중요한 이벤트 프레임의 개수는 매우 희소합니다.
-
이벤트 탐지를 위해 긴 영상을 검색하고 분석하는 경우, 추론 시간이 길어지고 자원 소모가 크게 증가하는 문제점이 발생하였습니다.
3) 긴 영상 분할 방법론 (OVerlapping Chunks)
"특정 이벤트를 탐지하여 긴 영상의 구간을 의미론적으로 분할하는 방법론이 필요"
긴 영상을 분할하는 가장 단순한 방법 중 하나는 Overlapping Chunks로 시간 간격을 기준으로 고정된 크기의 프레임을 구성하는 방법입니다.
Overlapping Chunks는 자원 효율성 측면에서 비용을 줄이는데 효과적이지만 이벤트 누락 문제가 발생할 수 있는 한계점을 가짐.
따라서, 긴 영상 내에서 중요한 이벤트가 누락되지 않는 동적 이벤트 탐지 기반 영상 분할 방식이 필요합니다.
4) 긴 영상 분할 방법론 (Sentence BERT)
프레임 캡션의 문맥을 반영하기 위해 Sentence BERT를 활용한 문장 기반의 의미론적 분할 방법을 제안하였습니다.
사전 훈련된 Sentence BERT 모델을 활용하여 이전 프레임과 현재 프레임의 문장 간 유사도를 계산합니다.
전체 프레임에 대한 문장 간 유사도 행렬을 계산한 후 유사도가 급격하게 낮아지는 지점을 이벤트 프레임 구간으로 정의하였습니다.
각 영상마다 프레임 유사도의 분포는 다르기 때문에 유사도 임계 값이나 구간 수를 임의로 설정하는 것은 새로운 영상을 분할 시 한계점을 가졌습니다.
영상을 자동 분할하기 위해 Z-Score를 활용한 동적 임계 값 설정 방법론을 제안하였습니다.
또한, 너무 짧은 영상으로 분할되는 문제를 해결하기 위해 설정된 프레임 수보다 적게 할당된 구간은 다음 구간과 자동으로 병합하는 후처리를 진행하였습니다.
5) 프레임 유사도 기반 영상 분할 실험 결과
"프레임 캡션의 유사도를 기반으로 이벤트를 탐지하여 긴 영상 데이터를 짧은 영상 데이터로 분리"
4 영상 분석 시스템
1) 영상 분석 RAG & LLM 파이프라인
"Function Calling을 활용한 RAG 기반 영상 검색 및 분석 파이프라인 구축"
사용자 질문에 맞는 프레임을 검색하고 LLM의 입력으로 활용하기 위해 RAG 파이프라인을 구축하고 중요한 영상을 검색합니다.
ROI 기반 영상 분석 및 시각화를 위해 Function Calling 방법론을 제안하고 영상의 상세한 설명을 제공합니다.
2) Line & Polygon Function Calling
사용자가 UI에 Line 또는 Polygon 형태의 Visual Prompt를 입력하면 세 가지 단계를 통해 함수를 호출합니다.
-
실시간으로 추출되어 Detection DB에 저장된 객체의 Bounding Box와 사용자가 입력한 Visual Prompt 간의 중첩 여부를 파악합니다.
-
겹치는 객체에 대해 IoU(Intersection over Union)를 계산하고 설정된 특정 임계 값을 초과하는 경우에만 객체 정보를 저장합니다.
-
최종적으로, 지정된 출력 포맷을 적용하여 지정 영역을 통과하는 Object Counting과 Tracking Interval을 반환하고 실시간 그래프도 함께 출력합니다.
3) 영상 분석 시스템 결과
"사용자와 상호작용하는 ROI 객체 침입 탐지 및 분석 서비스 개발"
5 결과 및 시연
1) 영상 검색 시스템 정량적 평가
"MSR-VTT 벤치마크 데이터셋을 통한 영상 검색 시스템 정량적 평가"
MSR-VTT는 20개 도메인에서 10,000개의 비디오 클립으로 구성된 데이터셋으로 1k-A 분할은 성능 비교를 위한 가장 일반적인 방법으로 사용됩니다.
MST-VTT는 총 20개의 도메인의 영상들이 존재하고, 각 비디오에 대해서 총 20개의 캡션들이 존재합니다.
평가 지표는 Recall@K로 주어진 텍스트 쿼리에 대해 상위 K개의 검색 결과 중에서 정답 비디오가 얼마나 많이 포함되는지를 나타냅니다.
원시 비디오 영상 데이터를 활용하는 Text to Video Retrieval SOTA 모델과의 비교 시 본 연구에서 제안하는 방법론은 우수한 성능을 도출하였습니다.
2) 시연 영상
시연 영상은 다음 링크에서 보실 수 있습니다!! 해당 링크에는 텔레토비전팀의 연구 결과물이 잘 정리 되어 있답니다!!
https://github.com/TeletoVision/TeletoVision_AI
6. 연구 성과 및 향후 발전 가능성
1) 연구 성과
2) 연구 계획 일정 완료
3) SKT AI Fellowship 운영진께 감사의 인사 및 마무리
5개월간의 SKT AI Fellowship 프로그램을 통해 정말 많은 것을 배우고 성장할 수 있었습니다.
프로그램 기간 동안, AI 연구와 개발에 대한 깊이 있는 통찰을 얻었을 뿐만 아니라, 각 분야에서 활약하시는 뛰어난 멘토님들과 동료 연구자들과 소중한 인연도 맺을 수 있었습니다.
이번 기회를 빌려 프로그램을 준비하고 세심하게 운영해 주신 SKT AI Fellowship 운영진 여러분께 진심으로 감사드립니다.
앞으로도 Fellowship에서 배운 지식과 경험을 바탕으로, AI 분야에서 의미 있는 기여를 할 수 있도록 끊임없이 노력하겠습니다.
SKT AI Fellowship의 지속적인 발전과 성공을 진심으로 기원하며, 다시 한 번 깊은 감사의 마음을 전합니다.
