어플리케이션 트래픽을 받기 전, 특정 테이블의 데이터를 모두 로드하여 메모리에 적재해야 하는 요구사항이 있었다. 이는 시작 시 데이터를 빠르게 제공하기 위해 설계된 로직이었다. 로컬 환경에서는 문제없이 동작했지만, Heap Size가 제한된 개발 환경에서 실행할 때 OutOfMemoryError(OOM)가 발생하며 어플리케이션이 시작되지 않는 문제가 발생했다.
대량 데이터를 처리하는 어플리케이션에서는 데이터베이스에서 가져온 결과를 효율적으로 처리하는 방식이 중요한데, Connector/J 가 ResultSet을 사용하여 데이터를 처리하는 방식과 JPA 에서는 어떻게 동작하는지 살펴보자.
ResultSet이란?
ResultSet은 서버와 클라이언트 모두에서 동작하는 중요한 데이터베이스 객체이다. 데이터베이스와 클라이언트 간의 데이터 전송 및 처리를 책임지며, 서버와 클라이언트의 역할에 따라 그 동작 방식이 달라진다.
클라이언트 측 cursor
- ResultSet은 데이터베이스 서버에 저장된 결과 집합을 참조한다.
- 클라이언트가 요청할 때마다 행 단위로 데이터베이스와 통신하여 필요한 데이터를 가져온다.
- 따라서, 모든 데이터를 한꺼번에 가져오지 않고도 클라이언트 커서를 활용해 스트리밍 방식으로 처리할 수 있다.
코드 예제
@Test
public void testClientCursorMemoryUsage() throws SQLException {
String url = "jdbc:mysql://localhost:3306/mydb"; // 기본 JDBC 설정
String user = "username";
String password = "password";
try (Connection connection = DriverManager.getConnection(url, user, password)) {
Statement stmt = connection.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
// 클라이언트 커서를 사용해 데이터 한 행씩 처리
ResultSet rs = stmt.executeQuery("SELECT * FROM large_table");
while (rs.next()) {
System.out.println("ID: " + rs.getInt("id") + ", Data: " + rs.getString("data"));
}
rs.close();
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}Heap 사용량 패턴
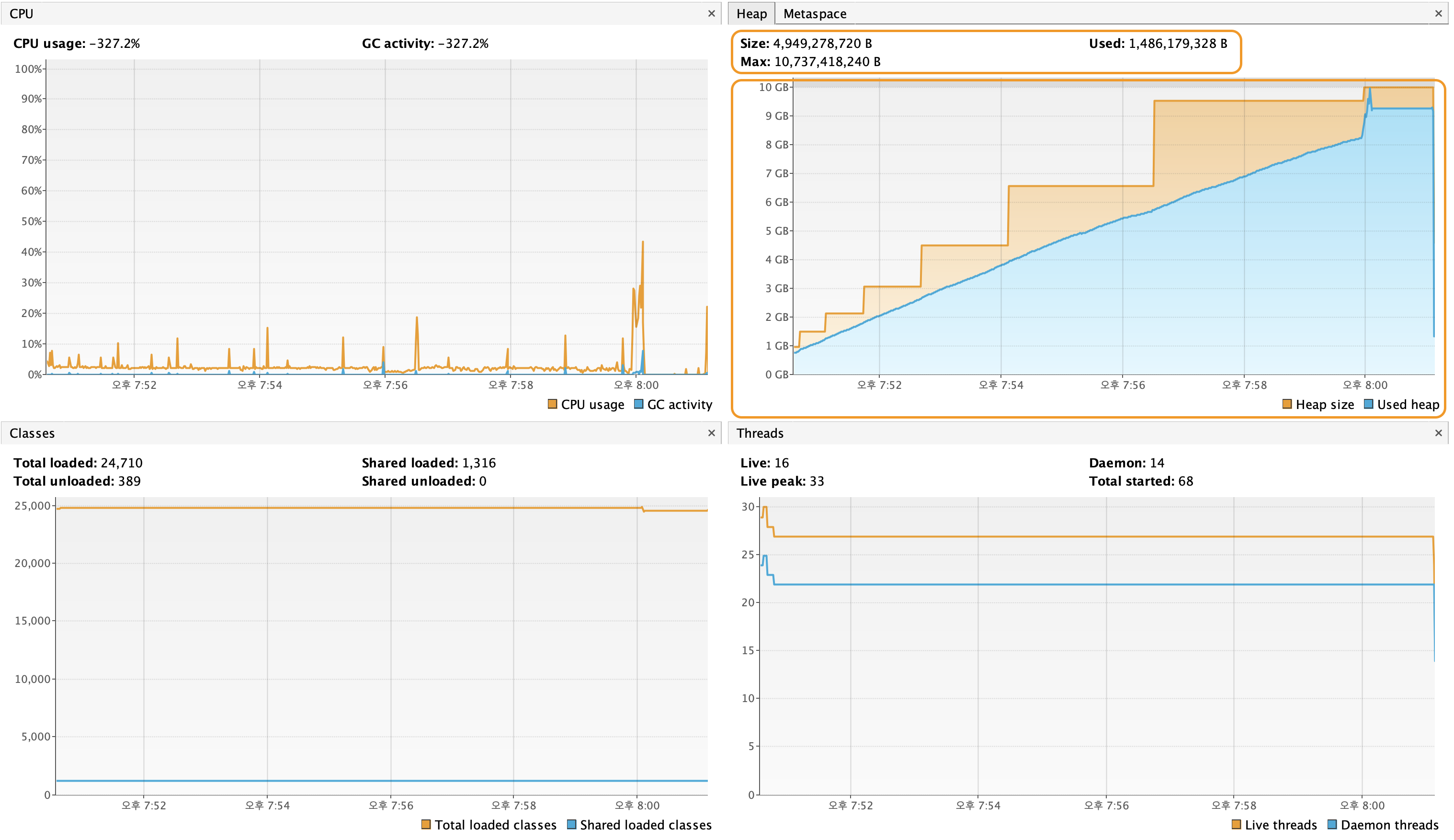
- 사용된 Heap 메모리(Used heap)가 점진적으로 증가하며, 계단식으로 올라가는 모습을 볼 수 있다.
- 데이터가 클수록 더 많은 메모리를 점유하며, 결국 JVM 힙 메모리를 초과(OOM)할 가능성이 있다.
- Heap Size: 약 10GB로 증가(Gradle 설정이나 기본 JVM 설정에 따라 증가)한다.
- Used Heap: 계단식으로 증가하며 최대 약 10GB 사용한다.
ㅑ
서버 측 cursor
- 서버 측에서 쿼리 실행 결과를 관리하며, 이를 임시 테이블 또는 메모리에 저장한다.
- 서버는 커서(Cursor)를 사용해 결과를 순차적으로 클라이언트로 전송한다.
- 서버 커서의 동작은 다음과 같다.
- 클라이언트가 데이터를 요청할 때마다 결과 집합에서 필요한 데이터를 제공한다.
- 쿼리 결과를 임시로 저장하고, 클라이언트가 데이터를 소비하는 동안에도 쿼리 실행을 완료한 상태로 유지한다.
코드 예제
@Test
public void testServerCursorMemoryUsage() throws SQLException {
String url = "jdbc:mysql://localhost:3306/mydb?useCursorFetch=true"; // 서버 커서 활성화
Properties props = new Properties();
props.setProperty("user", "username");
props.setProperty("password", "password");
props.setProperty("defaultFetchSize", "100");
try (Connection connection = DriverManager.getConnection(url, props)) {
Statement stmt = connection.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(100); // 서버 커서로 배치 단위 데이터 처리
ResultSet rs = stmt.executeQuery("SELECT * FROM large_table");
while (rs.next()) {
System.out.println("ID: " + rs.getInt("id") + ", Data: " + rs.getString("data"));
}
rs.close();
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}MySQL 현재 실행 중인 커서 관련 정보
SELECT SQL_TEXT, ROWS_SENT FROM performance_schema.events_statements_current where sql_text = 'SELECT * FROM large_table'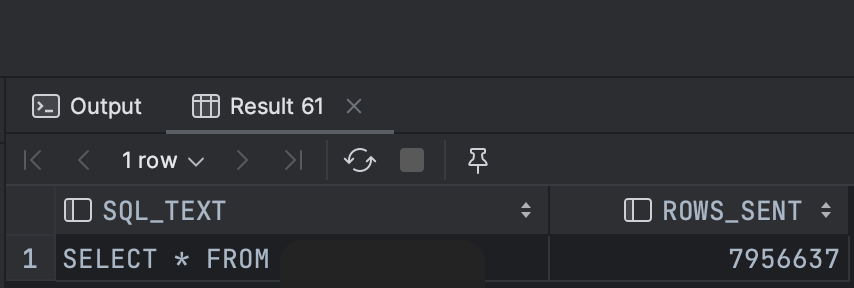
서버 커서 방식일 경우, ROWS_SENT 값이 일정한 패턴으로 증가하는 것을 볼 수 있다.
Heap 사용량 패턴
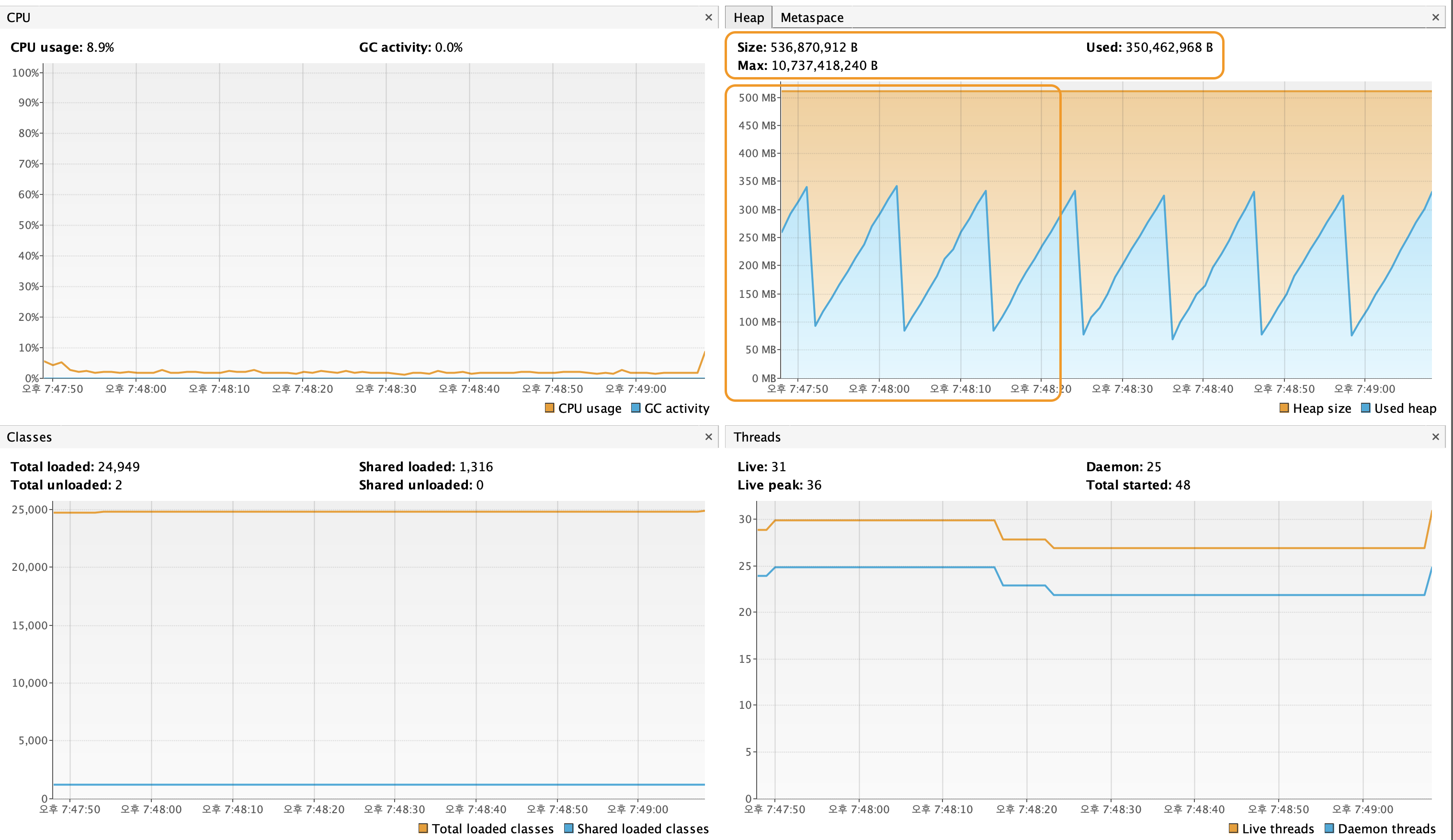
- 그래프에서 사용된 Heap 메모리가 주기적으로 상승한 후, GC(가비지 컬렉션)가 작동하여 다시 낮아지는 것을 볼 수 있다.
- 데이터를 배치 단위(fetchSize)로 처리하고, 처리 완료된 데이터는 더 이상 참조되지 않으므로 GC에 의해 메모리가 회수되는 것을 보여준다.
- 사용된 Heap 메모리(Used heap)가 안정적으로 유지된다.
- Heap Size: 약 500MB로 고정되어 있으며, JVM 힙 메모리 설정에 따라 일정하게 유지한다.
- Used Heap: 최대 약 350MB까지 사용되며, GC 실행 시 약 50MB로 감소한다.
ResultSet 처리 방식 비교
| 특징 | 서버 측 ResultSet | 클라이언트 측 ResultSet |
|---|---|---|
| 역할 | 쿼리 실행 및 결과 유지 | 쿼리 결과 소비 |
| 데이터 저장 위치 | 서버 메모리 또는 임시 테이블 | 클라이언트 메모리 |
| 데이터 요청 방식 | 클라이언트 요청 시 필요한 데이터만 전송 | 클라이언트가 데이터 소비를 제어 |
| 메모리 효율성 | 서버에서 결과를 관리하므로 클라이언트 메모리 부담 감소 | 클라이언트가 모든 데이터를 로드할 경우 메모리 부담 증가 |
| 커서 관리 주체 | 서버가 커서를 제어 | 클라이언트가 커서를 직접 제어 |
| 동시성 처리 | 동일 커넥션에서 다중 쿼리 실행 가능 | 동일 커넥션에서 다중 쿼리 실행 불가 |
커서 이동 방식
| 옵션 | 설명 | 특징 | 사용 사례 |
|---|---|---|---|
| TYPE_FORWARD_ONLY | 단방향 커서로, 데이터는 순차적으로만 읽을 수 있음ResultSet.next()로만 전진 이동 가능 | 이전 데이터를 다시 읽거나 특정 위치로 이동 불가 메모리와 성능이 가장 효율적 배치 처리 및 스트리밍 처리에 적합 | 대량 데이터 배치 처리, 메모리 효율이 중요한 경우 |
| TYPE_SCROLL_INSENSITIVE | 양방향 커서로, 이전/다음 데이터를 자유롭게 읽을 수 있음 데이터가 메모리에 캐시됨 | ResultSet.next(), ResultSet.previous() 등으로 특정 행으로 이동 가능데이터베이스 변경 사항은 반영되지 않음 | 변경되지 않는 정적 데이터를 탐색하는 경우 |
| TYPE_SCROLL_SENSITIVE | 양방향 커서로, 데이터베이스 변경 사항이 실시간으로 반영됨 | 데이터베이스 변경 사항이 반영됨 메모리와 성능 비용이 높음 다른 트랜잭션에서의 변경 사항을 감지 가능 | 실시간으로 데이터가 변경되는 동적 데이터를 처리해야 하는 경우 |
Gradle에서 테스트 실행 시 JVM 힙 메모리 제한 설정하기
tasks.named('test') {
useJUnitPlatform()
jvmArgs '-Xms512m', '-Xmx2g' // 최소 힙 메모리 512MB, 최대 힙 메모리 2GB로 설정
}JPA Stream Methods
JPA 2.2부터 getResultStream 메서드를 통해 JDBC ResultSet을 사용하여 결과를 스트리밍 방식으로 처리할 수 있다. 대량 데이터를 점진적으로 가져와 처리하며, 한꺼번에 모든 데이터를 메모리에 적재하는 부담을 줄일 수 있다.
코드 예제
@Repository
public interface LargeTableRepository extends JpaRepository<LargeTable, Long> {
@Query("""
SELECT l
FROM LargeTable l
WHERE l.createdOn >= :sinceDate
""")
@QueryHints(@QueryHint(name = "javax.persistence.fetchsize", value = "50")) // FETCH_SIZE 설정
Stream<LargeTable> streamByCreatedOnSince(LocalDate sinceDate);
}
@Service
public class LargeTableService {
...
@Transactional(readOnly = true)
public void processLargeTableData() {
LocalDate yesterday = LocalDate.now().minusDays(1);
try (Stream<LargeTable> stream = largeTableRepository.streamByCreatedOnSince(yesterday)) {
stream.forEach(largeTable -> {
System.out.println("Processing ID: " + largeTable.getId() + ", Data: " + largeTable.getData());
});
entityManager.detach();
}
}
}JPA Stream 특징
- JPA의 스트리밍 방식은 기본적으로 Hibernate의 ScrollableResults를 통해 구현된다.
- ScrollableResults는 JDBC의 ResultSet을 래핑하여 작업하며, 이를 Stream API로 변환한다.
- 기본적으로 TYPE_FORWARD_ONLY와 CONCUR_READ_ONLY로 동작하며, fetchSize가 설정되지 않으면 JDBC 드라이버에 따라 기본 동작이 달라질 수 있다.
- 트랜잭션 유지와 Stream 종료 후 리소스 해제에 유의해야한다.
- 스트리밍 도중 영속성 컨텍스트에 많은 엔티티가 쌓이지 않도록 주기적으로 entityManager.clear() 또는 entityManager.detach()를 호출이 필요할 수 있다.
서버 cursor로 동작할까? 클라이언트 cursor 로 동작할까?
당연히 서버 사이드 cursor 로 동작해야할 것 같지만, 구현체에 따라서 달라질 수 있다고 한다. 내가 사용하는 MariaDB Connecor J 는 클라이언트 사이드 커서 방식으로 동작한다.

fetchSize 를 설정하지 않으면, 1,215,487 개를 한번에 가져온다.

fetchSize를 10,000 으로 설정해주면 JDBC 드라이버가 해당 크기만큼 데이터를 배치 단위로 서버에서 가져오는 것을 알 수 있다.
References


커서에 대해서 잘 몰랏는데 호카론 님 덕분에 쉽게 (오늘도) 배워갑니닷 🙇