클러스터드 인덱스(Clustered Index)와 세컨더리 인덱스(Secondary Index)는 MySQL과 같은 데이터베이스 시스템에서 성능을 최적화하기 위한 인덱스 유형이다. 두 인덱스는 데이터의 저장 방식과 동작 방식에서 차이가 있으며, 각기 다른 목적을 가지고 있다. 이제 이 둘의 차이점과 역할을 살펴보자.
인덱스의 종류
클러스터드 인덱스 (Clustered Index)
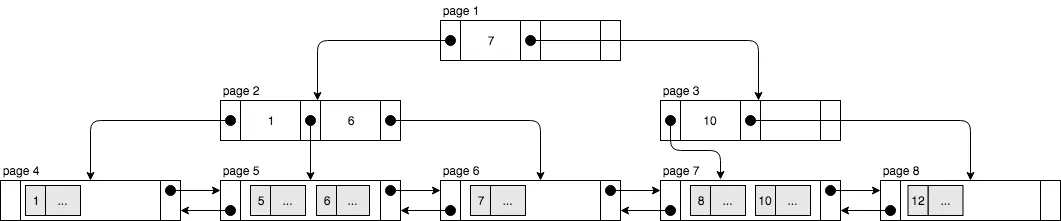
클러스터드 인덱스는 프라이머리 키를 기준으로 데이터가 물리적으로 정렬되어 저장된다. 즉, 테이블의 데이터가 프라이머리 키 값에 따라 정렬되며, 데이터는 이 인덱스를 기준으로 저장된다. B+트리 구조를 사용하며, 비리프 노드에는 프라이머리 키가, 리프 노드에는 실제 데이터가 저장된다.
세컨더리 인덱스 (Secondary Index)
세컨더리 인덱스는 논클러스터드 인덱스 또는 보조 인덱스라고도 불리며, 프라이머리 키가 아닌 컬럼에 대해 생성되는 인덱스다. 세컨더리 인덱스 역시 B+트리 구조를 사용하지만, 리프 노드에는 해당 컬럼 값과 함께 프라이머리 키가 저장된다. 세컨더리 인덱스를 검색해 프라이머리 키를 찾고, 이를 통해 다시 클러스터드 인덱스에서 실제 데이터를 조회하는 방식이다.
인덱스의 구조 및 탐색 방식
클러스터드 인덱스 (Clustered Index)
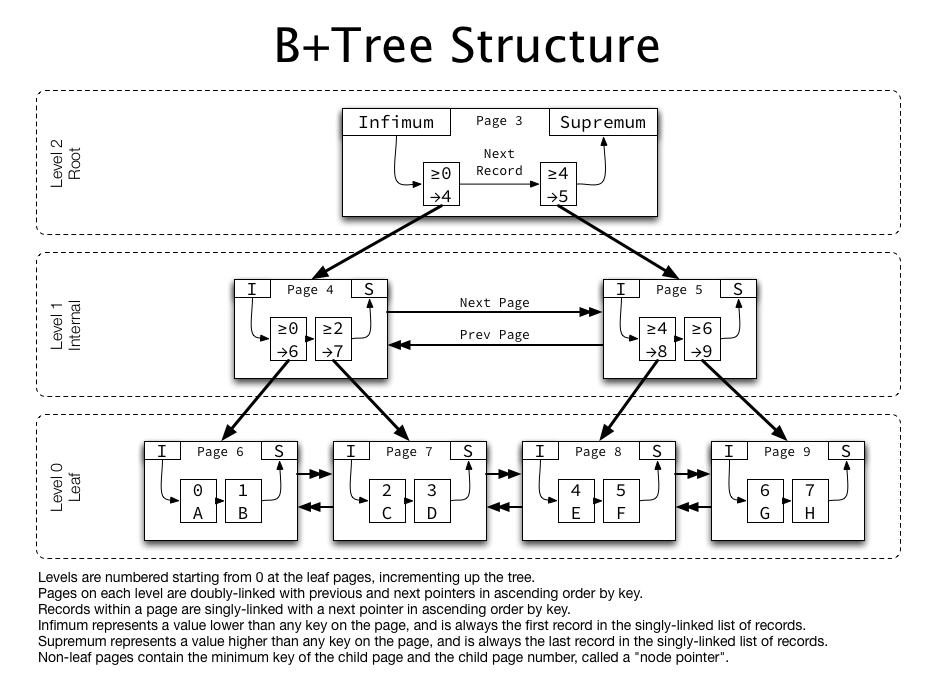
Jeremy Cole, B+Tree index structures in InnoDB
클러스터드 인덱스의 탐색 방식
- 비리프 노드 탐색: 상위 페이지들은 비리프 노드로, 인덱스 키 값만 저장하며 리프 노드로의 탐색 경로를 제공한다.
- 리프 노드 탐색: 리프 노드에는 실제 데이터가 프라이머리 키 순서로 정렬되어 있으며, 이 노드들은 서로 연결되어 있어 범위 검색 시 효율적이다.
예를 들어, 프라이머리 키 값이 7인 데이터를 찾을 때, 먼저 상위 노드에서 프라이머리 키 값에 따른 탐색 경로를 찾고, 리프 노드에 도달한 후 실제 데이터를 조회한다.
프라이머리 키 삽입 방식
- 리프 노드에 공간이 충분할 경우: 새 데이터를 추가하고 정렬 상태를 유지하면서 삽입이 완료된다.
- 리프 노드에 공간이 부족할 경우: B+트리의 노드 분할(Page Split)이 발생하며, 새로운 페이지를 생성하고 일부 데이터를 새 노드로 이동시킨다. 이 과정에서 비리프 노드에도 변화가 생긴다.
Auto Increment Key 의 성능 이점
Auto Increment Key는 순차적인 값으로 데이터를 가장 끝에 삽입하기 때문에, B+트리에서 노드 분할이나 트리 재정렬이 거의 발생하지 않아 성능이 좋다. 반면, UUID나 이메일 필드 같은 값은 랜덤하게 생성되어 중간에 삽입되므로, 노드 분할과 트리 재정렬이 자주 발생해 성능이 저하될 수 있다.
세컨더리 인덱스 (Secondary Index)
[Page 3 (Root): ≥ 0 -> Page 4, ≥ 4 -> Page 5]
/ \
[Page 4: ≥ 0 -> Page 6, ≥ 2 -> Page 7, ≥ 6 -> Page 8] [Page 5: ≥ 4 -> Page 8, ≥ 8 -> Page 9]
/ | \ / | \
[Page 6: 0 -> PK1, PK2, 1 -> PK3] [Page 7: 2 -> PK4, PK5, 3 -> PK6] [Page 8: 4 -> PK7, 5 -> PK8] [Page 9: 6 -> PK9, PK10, 7 -> PK11, PK12](B+트리 구조를 사용하지만 리프 노드에 프라이머리 키 또는 Row ID가 저장된다는 차이가 있다)
세컨더리 인덱스의 탐색 방식
- 비리프 노드 탐색: 세컨더리 인덱스는 특정 컬럼 값이 저장된 비리프 노드를 탐색한다.
- 리프 노드에서 프라이머리 키 조회: 리프 노드에는 검색 컬럼 값과 해당 프라이머리 키가 함께 저장되어 있다.
- 클러스터드 인덱스를 통해 실제 데이터 조회: 조회된 프라이머리 키를 이용해 클러스터드 인덱스에서 실제 데이터를 가져온다.
세컨더리 인덱스 삽입 방식
리프 노드에 공간이 없으면 역시 B+트리의 노드 분할이 발생하며, 새로운 리프 노드가 생성되고 상위 비리프 노드가 이에 맞춰 조정된다.
TEXT 타입 컬럼에 인덱스를 사용하는 경우의 비효율성
TEXT와 같이 크기가 큰 컬럼에 인덱스를 사용하면, 페이지 하나에 저장할 수 있는 인덱스 항목이 줄어들며, 그 결과로 페이지가 빠르게 가득 차고, Page Split이 자주 발생해 성능이 저하된다. 프리픽스 인덱스(일부만 인덱싱)와 같은 최적화 기법을 사용하는 것이 바람직하다.
세컨더리 인덱스가 필요한 경우
- WHERE 절에서 자주 검색되는 컬럼: 특정 값을 기준으로 데이터를 검색하는 경우, 해당 컬럼에 세컨더리 인덱스를 추가하면 검색 속도를 높일 수 있다.
- JOIN 절에서 자주 사용되는 컬럼: 조인에 자주 사용되는 컬럼에 세컨더리 인덱스를 추가하면 JOIN 성능이 향상된다.
- ORDER BY, GROUP BY에 사용되는 컬럼: 정렬이나 그룹화가 자주 발생하는 컬럼에 인덱스를 추가하면, 데이터 조회 성능이 개선된다.
- 카디널리티가 높은 컬럼: 고유한 값이 많은 컬럼에 세컨더리 인덱스를 추가하면 검색 성능이 크게 향상된다.
카디널리티가 낮은 컬럼에 인덱스를 추가하는 것은 그리 효율적이지 않을 수 있으며, 테이블 풀 스캔이 더 나을 수 있다.
세컨더리 인덱스를 사용하지 않는 경우
- 함수나 연산자를 사용하는 경우
SELECT * FROM employees WHERE LOWER(name) = 'john';- 인덱스는 컬럼 값 그대로 사용할 때만 효율적이다. 함수가 적용되면 인덱스를 사용할 수 없어 테이블 풀 스캔이 발생한다.
- LIKE문에서 와일드카드가 앞에 있는 경우
SELECT * FROM users WHERE email LIKE '%example.com';- 와일드카드가 앞 또는 중간에 있으면 인덱스를 탈 수 없고, 풀 스캔이 발생한다.
- OR절을 사용하는 경우
SELECT * FROM orders WHERE order_id = 123 OR customer_id = 456;- OR 조건에서는 인덱스를 효율적으로 사용하지 못할 수 있다.
- NULL 값을 비교하는 경우:
SELECT * FROM orders WHERE order_id = 123 OR customer_id = 456;- NULL 값은 인덱스에서 관리되지 않기 때문에 풀 스캔이 발생할 수 있다.
- 부정 조건 사용 시:
ELECT * FROM users WHERE age != 30;!=와 같은 부정 조건에서는 인덱스 사용이 어려워 풀 스캔이 발생할 가능성이 크다.
번외
커버링 인덱스(Covering Index)
커버링 인덱스는 인덱스의 자료구조 자체가 다른 인덱스와 다른 것이 아니라, WHERE 절 뿐만 아니라 SELECT 절에서 필요한 모든 컬럼이 인덱스에 포함된 경우를 말한다. 즉, 쿼리를 실행할 때 인덱스만으로 필요한 데이터를 모두 처리할 수 있는 상황을 지칭한다.
예를 들어, SELECT 쿼리가 특정 컬럼들에 대한 데이터를 반환하는데, 그 컬럼들이 모두 하나의 인덱스에 포함되어 있다면 테이블에 접근하지 않고 인덱스만으로 데이터를 반환할 수 있는 것이다.
커버링 인덱스는 특정 쿼리가 필요로 하는 모든 데이터를 인덱스에 포함시켜, 테이블을 다시 접근하지 않고 인덱스만으로 데이터를 조회할 수 있는 인덱스이다. 이를 통해 성능을 최적화할 수 있지만, 인덱스 크기와 삽입/업데이트 성능에 주의해야 한다. 잘 설계된 커버링 인덱스는 읽기 성능을 크게 향상시킬 수 있다.
MySQL 인덱스 구조인 B트리 파악하기에 좋은 사이트
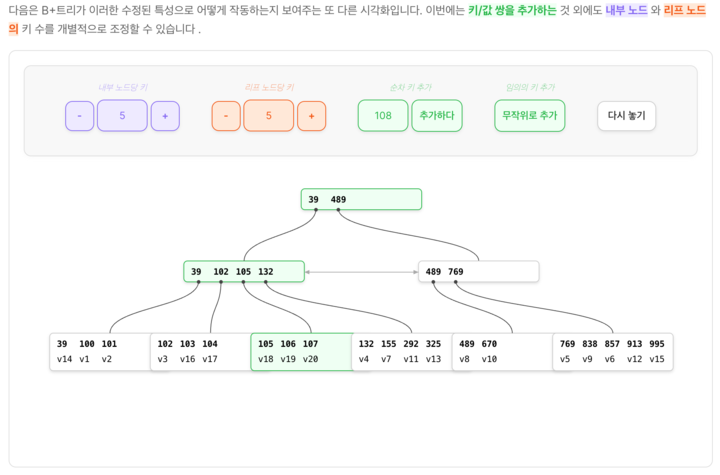
B-트리, B+트리에 데이터가 추가 / 조회되는 것을 시각화하여 보여주고, 장단점을 알 수 있는 사이트이다.
https://planetscale.com/blog/btrees-and-database-indexes
References
