커서 페이징 쿼리에서 마지막 쿼리가 10초를 초과하는 경우, SQLInvalidAuthorizationSpecException 이 발생하고 있다. SQLInvalidAuthorizationSpecException 이 발생하는 원인과 슬로우 쿼리가 발생한 이유에 대해 정리해보자.
쿼리 실행시간이 10초를 초과하는 경우, SQLInvalidAuthorizationSpecException 가 발생해요

java.sql.SQLInvalidAuthorizationSpecException: (conn=1908142) Communications link failure with secondary host dev.ap-northeast-2.rds.amazonaws.com:3306. Connection timed out
at org.mariadb.jdbc.internal.util.exceptions.ExceptionFactory.createException(ExceptionFactory.java:66)
at org.mariadb.jdbc.internal.util.exceptions.ExceptionFactory.create(ExceptionFactory.java:158)...✔️ 사용하고 있는 데이터베이스 엔진 및 서비스의 설정은 다음과 같다.
- 8.0.mysql_aurora.3.05.2
- MariaDB Connector/J 2.7, aurora 모드
❎ (추측 1) 10초 관련된 MySQL 서버 설정 찾았는데, connect_timeout 이 원인일까
show global variables like '%timeout';| Variable Name | Value |
|---|---|
| connect_timeout | 10 |
| delayed_insert_timeout | 300 |
| innodb_flush_log_at_timeout | 1 |
| innodb_lock_wait_timeout | 50 |
| net_read_timeout | 30 |
| net_write_timeout | 60 |
| wait_timeout | 28800 |
해당 에러가 발생한 원인을 분석한 결과, 쿼리 실행 도중에 타임아웃이 발생했으며 서버가 아닌 클라이언트가 먼저 연결을 끊었다는 로그가 남아 있었다. 따라서, connect_timeout 설정이 원인이 아니었다.
✅ (추측 2) 10초 관련된 MariaDB Connector/J 설정 찾았는데, socketTimeout 이 원인일까

aurora 모드로 사용시에, 쿼리 실행 시간이 10초를 초과한 경우 드라이버는 failover가 발생한 것으로 판단한다.
fyi; MariaDB Connector/J Used Parameters
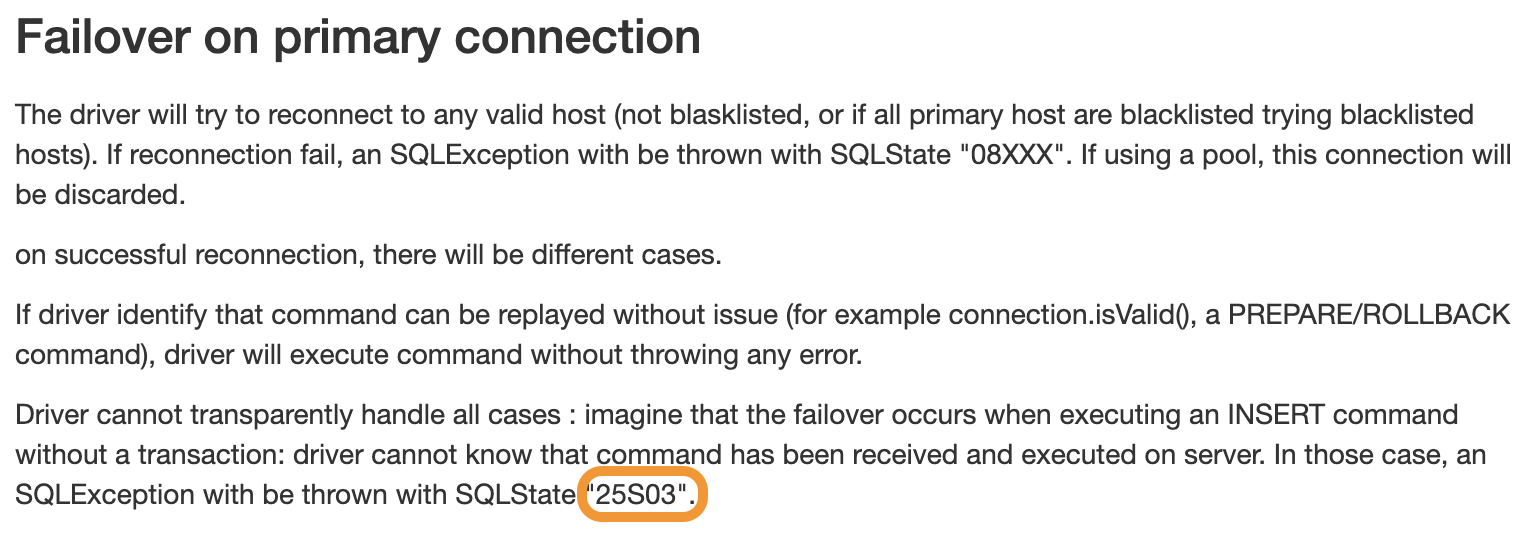
SQLInvalidAuthorizationSpecException 발생시에 SQLState 는 25S03 이었는데, Failover on connection 발생 시에 해당 SQLState 가 반환된다고 되어있다.
쿼리 수행시간이 10초를 초과하는 경우, SQLInvalidAuthorizationSpecException 가 발생하는지 테스트해보자
class ConnectionTest {
// Connection parameters
private static final String URL = "jdbc:mysql:aurora://dev-...:3306/coupon";
private static final String USER = "user";
private static final String PASSWORD = "password";
// Method to establish and return a connection
public static Connection getConnection() throws SQLException {
try {
// Load the MariaDB driver
Class.forName("org.mariadb.jdbc.Driver");
} catch (ClassNotFoundException e) {
throw new SQLException("MariaDB Driver not found", e);
}
// Establish and return the connection
return DriverManager.getConnection(URL, USER, PASSWORD);
}
@Test
public void test() {
try (Connection connection = getConnection()) {
if (connection != null) {
System.out.println("Connection established successfully.");
PreparedStatement pstmt = connection.prepareStatement("select sleep(15)");
boolean res = pstmt.execute();
System.out.println("query res? " + res);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}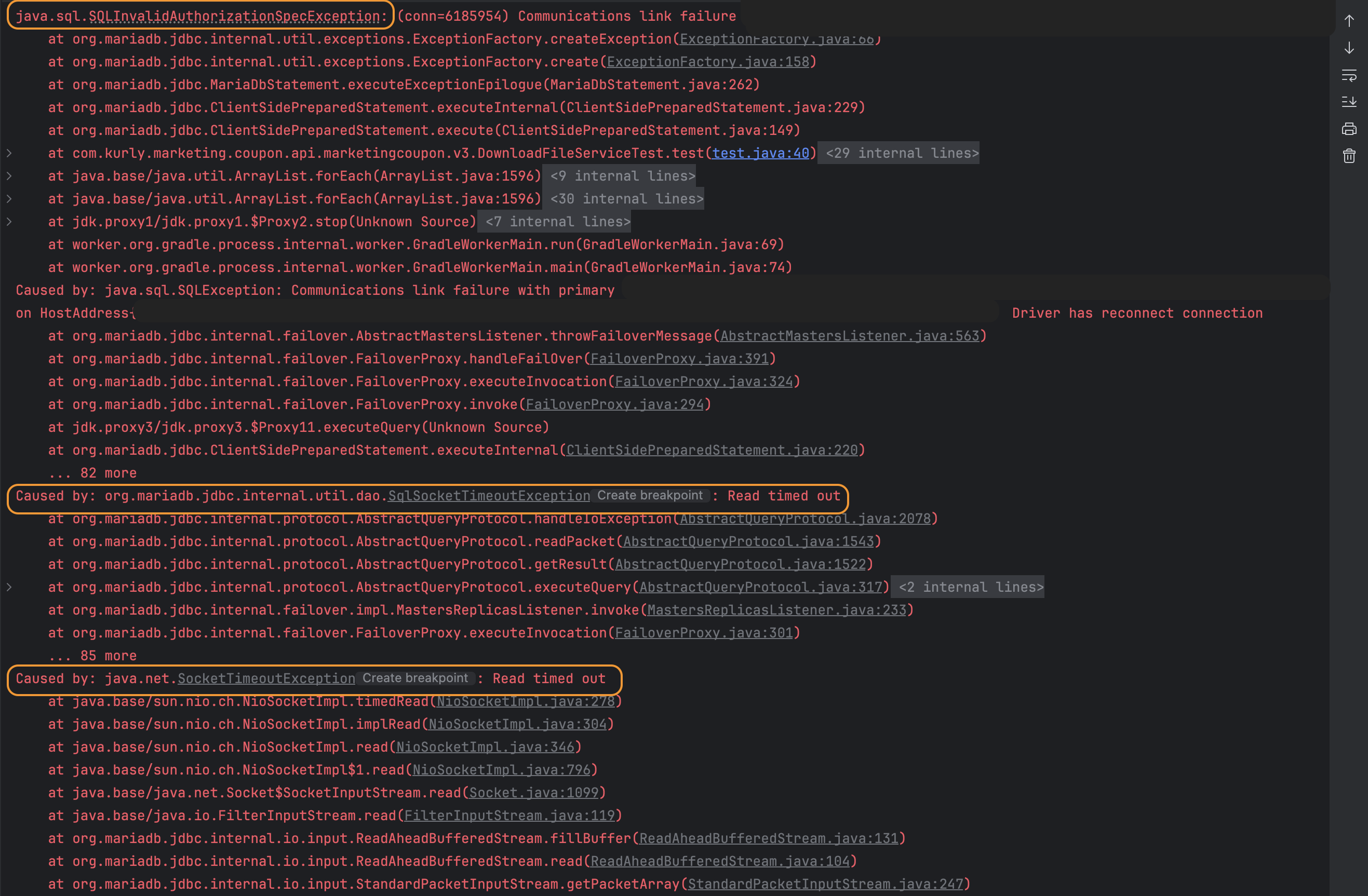
10초가 넘는 쿼리가 발생하면 SQLInvalidAuthorizationSpecException 가 발생하고 있다! 하위 스택트레이스를 살펴보면 SqlSocketTimeoutException 예외가 발생한 것도 알 수 있다.(왜 사람 헷갈리게 SQLInvalidAuthorizationSpecException 로 변환되는거야)
해결방법
만약 10초가 넘는 쿼리 실행시에도 에러를 발생시키고 싶지 않다면, socketTimeout 설정을 늘려주자.
jdbc:mysql:aurora://dev-...:3306/coupon?socketTimeout=30000위 이슈는 10초가 넘는 슬로우쿼리가 발생하는 것이 문제였기때문에, socketTimeout 은 기본값인 10초로 유지했다.
페이징 쿼리에서 마지막 쿼리 수행시간이 10초를 초과해요
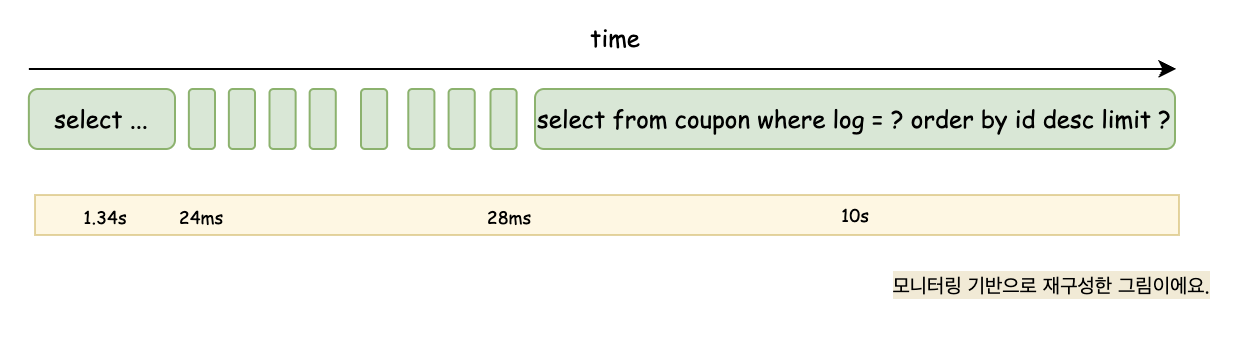
마지막 쿼리에서 슬로우 쿼리가 발생하는 이유
- 전체 범위 검색
- 조건을 만족하는 데이터가 부족할 때, 데이터베이스는 인덱스 범위 스캔을 통해 모든 가능성을 검색하는데, 이 과정에서 많은 양의 데이터를 읽고 필터링해야 하므로 시간이 많이 소요된다.
- 필터링 비용 증가
- 모든 데이터를 읽은 후, coupon_log_id = 8 조건을 적용하여 필터링해야 한다.
- 이로 인해 CPU 사용량이 증가하고 쿼리 시간이 길어진다.
- LIMIT 조건을 채우지 못함
- LIMIT 10000 조건을 사용하여 최대 10000개의 행을 반환하려 하지만, 조건을 만족하는 데이터가 10000개 미만인 경우 전체 데이터를 검색하고 필터링해야 한다.
- 예를 들어, 조건을 만족하는 데이터가 2641개라면, 나머지 7359개를 채우기 위해 전체 범위를 검색한다.
위 쿼리에서 사용할 수 있는 인덱스는 PRIMARY, idx_coupon 으로 2개였다.
쿼리 옵티마이저는 가능한 여러 인덱스를 분석하여 각 실행 계획의 코스트를 계산한 후, 인덱스 범위 스캔의 효율성, 인덱스 커버리지, 최신 통계 정보, 인덱스 유지보수 비용, 옵티마이저 힌트 및 설정 등 다양한 요인을 고려하여 최적의 실행 계획을 선택하는데요!
결과적으로 위 쿼리에서 옵티마이저가 실제로 선택한 인덱스는 PRIMARY 였다.
해결방법
✅ (해결방법 1) boundary 설정
select min(id),max(id) from coupon c1_0
where log_id = 1267;
select c1_0.id,
...
from coupon c1_0
where c1_0.id between 20122129 and 20674866 ## 🔥🔥🔥 min, max 값으로 바운더리를 잡기
...
order by c1_0.id desc
limit 10000;
select c1_0.id,
...
from coupon c1_0
where c1_0.id between 20122129 and 20664865 ## 🔥🔥🔥 첫번째 쿼리의 제일 마지막 값에서 -1 한 값을 상한값으로 지정
...
order by c1_0.id desc
limit 10000;between 은 이상/이하로 경계값을 포함하기 때문에 이전 페이지의 마지막 값에서 -1 한 값을 상한으로 지정한다.
Keyset 페이징 이란?
seek 메서드는 이전 페이지의 값을 구분자로 사용하기 때문에 두 가지 문제를 모두 피할 수 있다. 이는 이전 페이지의 마지막 항목 뒤에 와야 하는 값을 검색한다는 것을 의미한다. 이를 간단한 where 절로 표현할 수 있다. 다른 말로 하자면, seek 메서드는 이미 표시된 값을 선택하지 않는다.
Keyset Pagination, SQL Seek Method, Cursor Pagination 이라고도 불린다.
https://use-the-index-luke.com/sql/partial-results/fetch-next-page
❎ (해결방법 2) index hint 적용
select c1_0.id,
...
from coupon c1_0 use index (idx_coupon)
where c1_0.id < 20124770
...
order by c1_0.id desc
limit 10000;explain analyze 결과
패치 적용전(슬로우 쿼리 발생 버전)
-> Limit: 10000 row(s) (cost=142921.12 rows=10000) (actual time=0.029..29032.838 rows=2641 loops=1)
-> Filter: ((c1_0.log_id = 1267) and (c1_0.id < 20124770) and (c1_0.created_at between '2024-07-01 00:00:00' and '2024-08-31 23:59:59')) (cost=142921.12 rows=39604) (actual time=0.028..29032.651 rows=2641 loops=1)
-> Index range scan on c1_0 using PRIMARY over (id < 20124770) (reverse) (cost=142921.12 rows=10390244) (actual time=0.025..26598.070 rows=20124760 loops=1)- Index Range Scan: PRIMARY 인덱스를 사용하여 id < 20124770 범위의 모든 레코드를 검색
- Filter: 그 후 log_id = 1267 조건을 만족하는 레코드로 필터링
- Limit: 마지막으로 10000개의 레코드를 제한
- 실제 시간: 전체 실행 시간이 매우 길며, 대부분의 시간이 필터링 단계에서 소요 (29032.809ms)
- 코스트: 높음 (142921.12)
1. boundary 설정
-> Limit: 10000 row(s) (cost=978.97 rows=19) (actual time=0.033..6.040 rows=2641 loops=1)
-> Filter: ((c1_0.log_id = 1267) and (c1_0.id between 20122129 and 20674866) and (c1_0.id < 20124770) and (c1_0.created_at between '2024-07-01 00:00:00' and '2024-08-31 23:59:59')) (cost=978.97 rows=19) (actual time=0.032..5.852 rows=2641 loops=1)
-> Index range scan on c1_0 using PRIMARY over (20122129 <= id <= 20124770 AND '2024-07-01 00:00:00' <= created_at) (reverse) (cost=978.97 rows=4874) (actual time=0.029..3.786 rows=2641 loops=1)- Boundary 조건 추가: id 범위를 5402861 <= id < 5402911로 제한하여 검색 범위를 줄임
- 실제 시간: 쿼리 실행 시간이 매우 감소 (6.040ms)
- 코스트: 매우 낮음 (978.97)
2. index hint 적용
-> Limit: 10000 row(s) (cost=142672.77 rows=10000) (actual time=163.910..164.522 rows=2641 loops=1)
-> Sort: c1_0.id DESC, limit input to 10000 row(s) per chunk (cost=142672.77 rows=1002446) (actual time=163.908..164.341 rows=2641 loops=1)
-> Index lookup on c1_0 using idx_coupon (log_id=1267), with index condition: ((c1_0.id < 20124770) and (c1_0.created_at between '2024-07-01 00:00:00' and '2024-08-31 23:59:59')) (cost=142672.77 rows=1002446) (actual time=0.460..163.219 rows=2641 loops=1)- Index Lookup: idx_coupon 인덱스를 사용하여 log_id=1267 조건을 먼저 적용
- Sort: 결과를 id DESC로 정렬
- Limit: 10000개의 레코드로 제한
- 실제 시간: 쿼리 실행 시간이 감소 (163.910ms)
- 코스트: 높음 (142672.77)
정리
- limit 쿼리 실행할 때, 데이터 결과값이 limit 보다 작은 경우 주어진 범위에 대한 풀스캔이 발생할 수 있다. 바운더리를 추가해서 범위를 줄여보자.
- 무조건 인덱스로 PK 를 사용하는 것은 아니다. 범위가 너무 큰 경우에는(25000만건) 쿼리 옵티마이저가 생성하 인덱스를 사용한다.
- MySQL 8.0.18 부터 지원하는
explain analyze를 적극 사용해보자.
부록
Spring Data JPA 3.3.2 에서도 KeySet Pagination 을 편하게 사용할 수 있도록 편의메서드를 제공하고 있다.
interface UserRepository extends Repository<User, Long> {
Window<User> findFirst10ByLastnameOrderByFirstname(String lastname, KeysetScrollPosition position);
}fyi; Spring Data JPA 공식문서
References
- 존경하는 도, 이, 조, 김 개발자님
- use-the-index-luke.com/sql/partial-results/fetch-next-page
