레거시 프로젝트를 이관하면서, 레디스 에서 key-value 외에 다양한 자료구조가 있다는 것을 알았다. 자료구조와 메서드 그리고 어떤 상황에 해당 자료구조가 적절한지 알아보자.
레디스는 싱글 스레드 기반으로 동작하기 때문에 명령어의 시간복잡도를 파악한 후 해당 명령어로 인한 블로킹이 얼마나 생기는지 파악 후, 작업을 진행해야 한다. 특히 N이 데이터베이스의 키 갯수일 때 실행속도가 O(N)인 KEYS * 를 운영에서 날리는 작업은 피해야 한다.
redis.io에 소개되고 있는 자료구조
Strings
Strings는 key-value 형태의 바이트 시퀀스를 저장하는 자료구조이다.
레디스 CLI 과 Spring RedisTemplate 메서드
SET
- 문자열 값을 저장하는 메서드
- 시간복잡도 O(1)
> SET key value
> SET member:coupon:1234 1
OK public void setStringValue(String key, String value) {
redisTemplate.opsForValue().set(key, value);
}GET
- 문자열 값을 검색하는 메서드로
- 시간복잡도 O(1)
> GET key
> GET member:coupon:1234
"1" public String getStringValue(String key) {
return redisTemplate.opsForValue().get(key);
}카운터로서의 문자열
INCR / DECR
- key에 저장된 숫자를 증가/감소시키는 메서드
- 시간복잡도 O(1)
> SET key 0
> SET coupon_cnt 0
OK
> INCR coupon_cnt
(integer) 1
> INCRBY coupon_cnt 10
(integer) 11 public long increment(String key) {
ValueOperations<String, String> valueOps = redisTemplate.opsForValue();
return valueOps.increment(key);
}
public long incrementBy(String key, long incrementValue) {
ValueOperations<String, String> valueOps = redisTemplate.opsForValue();
return valueOps.increment(key, incrementValue);
}INCR명령은 문자열 값을 정수로 구문 분석하고 1씩 증가시킨 후 마지막으로 얻은 값을 새 값으로 설정한다. INCRBY, DECR및 와 같은 다른 유사한 명령이 있고, 내부적으로는 약간 다른 방식으로 작동한다.
INCR이 원자적이라는 것은 동일한 키에 대해 INCR을 발행하는 여러 클라이언트라도 결코 경쟁 조건에 빠지지 않는다. 예를 들어, 클라이언트 1이 "10"을 읽고, 클라이언트 2가 "10"을 동시에 읽고, 둘 다 11로 증가하고 새 값을 11로 설정하는 일은 결코 발생하지 않는다. 최종 값은 항상 12이고 read-increment-set 작업은 다른 모든 클라이언트가 동시에 명령을 실행하지 않는 동안 수행된다.
Lists 의 다른 메서드가 필요하다면 공식문서에 찾아보자.
언제 사용하면 좋을까?
- 단일 값을 저장하고 검색하는 경우
- 세션 데이터
- 카운터
- 캐시 등
Lists
Lists는 문자열 값의 연결된 목록을 저장하는 자료구조이다.
레디스 CLI 과 Spring RedisTemplate 메서드
LPUSH / RPUSH
- 목록의 헤드/꼬리에 새 요소를 추가하는 메서드
- 시간복잡도 O(1)
> LPUSH key value
> LPUSH member:coupon:1234:read 20231107
(integer) 1
> LPUSH member:coupon:1234:read 20231108
(integer) 2 public void leftPushToList(String key, String value) {
redisTemplate.opsForList().leftPush(key, value);
}
public void rightPushToList(String key, String value) {
redisTemplate.opsForList().rightPush(key, value);
}LRANGE
- 저장된 목록의 지정된 요소를 반환 메서드
- 시간복잡도 O(S+N)
- S는 작은 목록의 경우 HEAD로부터, 큰 목록의 경우 가장 가까운 끝(HEAD 또는 TAIL)으로부터의 시작 오프셋 거리
- N은 지정된 범위의 요소 수
> LRANGE key start end
> LRANGE member:coupon:1234:read 0 10
1) "20231108"
2) "20231107" public List<String> getRangeFromList(String key, long start, long end) {
return redisTemplate.opsForList().range(key, start, end);
}
public String getListItemAtIndex(String key, long index) {
return redisTemplate.opsForList().index(key, index);
}Lists 의 다른 메서드가 필요하다면 공식문서에 찾아보자.
언제 사용하면 좋을까?
- 사용자가 소셜 네트워크에 게시한 최신 업데이트 내역에 빠르게 엑세스가 필요한 경우
- 사용자가 새 사진을 게시할 때마다 해당 ID를 목록에 추가합니다 LPUSH
- 사용자가 홈페이지를 방문하면 LRANGE 0 9최근 게시된 10개의 항목을 가져오기 위해 사용합니다.
- 생산자가 항목을 목록에 푸시하고 소비자가 해당 항목을 소비하고 작업을 실행하는 소비자-생산자 패턴을 사용하는 프로세스 간 통신이 필요한 경우
Hashes
Hashes는 필드-값 쌍의 컬렉션으로 구성된 자료구조이다.
레디스 CLI 과 Spring RedisTemplate 메서드
HSET
- 지정된 필드를 에 저장된 해시의 해당 값으로 설정하는 메서드
- 시간복잡도 O(1)
> HSET key field value
(integer) 1
> HSET member:coupon:1234:read:20231108 1123 1
(integer) 1
> HSET member:coupon:1234:read:20231108 4123 1
(integer) 1 public void hset(String key, String field, String value) {
redisTemplate.opsForHash().put(key, subKey, value);
}HGET
- field에 저장된 해시에 연결된 값을 반환하는 메서드
- 시간복잡도 O(1)
- N은 해시 크기
> HGET key field
> HGET member:coupon:1234:read:20231108 1123
"1" public Boolean hGet(String key, String field) {
return redisTemplate.opsForHash().get(key, field);
}Hashes 의 다른 메서드가 필요하다면 공식문서에 찾아보자.
언제 사용하면 좋을까?
- 데이터를 저장할때 Key값에 대해서 Overehead가 발생하기 때문에, 레디스 상에서 관리되는 Key의 갯수를 줄여 메모리를 절약이 필요한 상황
그외 자료구조
TTL 설정하기
EXPIRE
- TTL 을 설정하는 메서드
- 시간복잡도 O(1)
> EXPIRE key value
> EXPIRE member:coupon:1234 100
(integer) 1 public void setExpiryForRedisKey(String key, long ttl) {
redisTemplate.expire(key, ttl, TimeUnit.SECONDS);
}TTL
- TTL 의 남은 시간을 반환하는 메서드(단위는 초)
- 시간복잡도 O(1)
> TTL key
> TTL member:coupon:1234
(integer) 100 public Long getExpiryForRedisKey(String key) {
return redisTemplate.getExpire(key, TimeUnit.SECONDS);
}- 레디스 2.6 이하에서 키가 존재하지 않거나 키가 존재하지만 TTL 이 걸려있지 않은 경우 -1이 반환된다.
- 레디스 2.8 부터 오류 발생 시 반환 값이 다음과 같이 변경되었다.
- 키가 존재하지 않는 경우 -2 반환된다.
- 키가 존재하지만 TTL 이 걸려있지 않은 경우 -1 이 반환된다.
- String 외에도 Lists, Hashes 의 키도 TTL 설정이 가능하다! 물론 키에 TTL 을 걸면 하위에 있는 목록이나 해시값들도 모두 삭제된다.
DEL 과 UNLINK
- 키를 삭제하는 메서드
- DEL 과 UNLINK 모두 문자열로 된 key를 하나만 삭제하면 O(1)이 걸린다.
- DEL은 list, set과 같은 다른 타입을 사용하면 element 개수(M)에 따른 O(M)의 시간 복잡도를 가지지만, UNLINK는 O(1) 이다.
> DEL key
> UNLINK key public void deleteKey(String key) {
redisTemplate.delete(key);
}
public void unlink(String key) {
redisTemplate.unlink(key);
}- UNLINK는 4.0.0 버전부터 추가되었고, 몇 개의 키를 삭제하든 O(1) 의 시간 밖에 필요하지 않다. DEL 보다 빠르다. 커맨드를 실행할 때는 삭제할 키를 keyspace에서만 삭제하고 실제로 데이터를 지우는 것은 비동기 형태로 다른 스레드에서 진행하게 되어, 데이터 삭제가 UNLINK 명령을 블로킹하지 않는다. 데이터를 삭제하는 스레드는 O(N)의 시간복잡도를 갖는다.
- DEL은 블로킹 형태로 동작하며, 명령을 실행하면 바로 키를 찾아서 삭제한다.
벌크로 저장이 필요한 경우, RedisTemplate에서 어떻게 할 수 있을까?
저장이 필요할 때마다 커넥션을 맺을 필요없이 한번 커넥션에서 많은 양의 데이터를 저장하여 RTT 및 부하를 줄일 수 있다.
public void bulk(Map<String, Long> keyTtlMap, String value) {
redisTemplate.executePipelined(
(RedisCallback<Object>) connection -> {
StringRedisConnection stringRedisConn = (StringRedisConnection) connection;
keyTtlMap.forEach((key, ttl) -> {
stringRedisConn.set(key, value, Expiration.from(ttl, TimeUnit.SECONDS), RedisStringCommands.SetOption.UPSERT);
});
return null;
});
}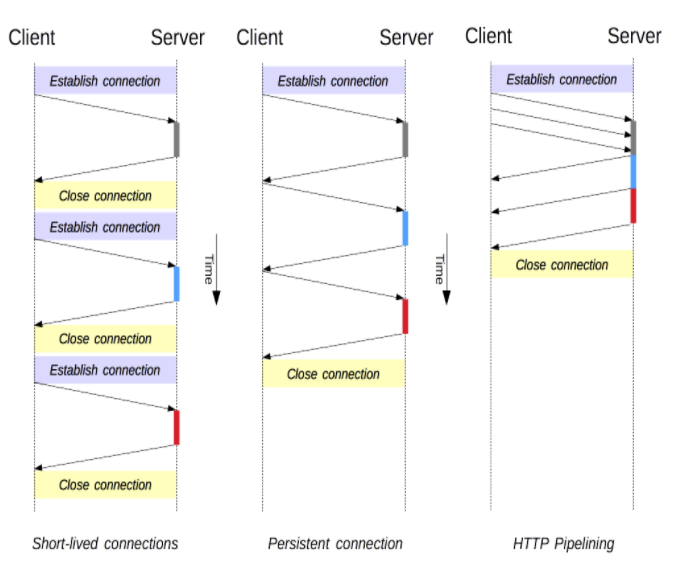
첫번째 그림은 이는 TCP연결을 매번해야 하는 오버헤드가 있어 Keep Alive속성이 생겼다.
두번째 그림은 Http의 Keep Alive속성때문에 연결이 지속되어 리퀘스트를 보내고 리스폰스를 받는다.
세번째 그림은 한번에 수많은 리퀘스트를 보내고 리스폰스를 기다리지 않고 보낼 수 있다.
출처
정리
- 레디스에는 key-value 외에도 다양한 자료구조가 존재한다.
- 각 서비스에 맞는 자료구조를 선택하면 메모리를 절약할 수 있다.
- TTL 을 설정하여 사용하지 않는 데이터에 대한 메모리를 절약하자.
References
