근접성 서비스의 경우 사업장 주소는 정적이지만, 주변 친구 위치는 자주 바뀔 수 있다. 주변 친구 서비스를 설계하고, 생각해보면 좋을 키워드에 대해 정리해보자.
1단계: 문제 이해 및 설계 범위 확정
- 주변에 있다의 지리적 기준을 5마일로 하고, 수치는 설정 가능하다.
- 10억명 중에 10% 정도가 주변 친구 서비스를 사용한다.
- 사용자의 이동 이력을 보관해야한다.
- 친구 관계에 있는 사용자가 10분 이상 비활성 상태이면 해당 사용자를 주변 친구 목록에서 사라지게 한다.
요구사항
| 요구사항 종류 | 요구사항 내용 |
|---|---|
| 기능 | 모바일 앱에서 주변 친구를 확인할 수 있다. |
| 기능 | 주변 친구 목록에는 해당 친구까지의 거리와, 마지막으로 갱신된 시각이 표시된다. |
| 기능 | 친구 목록은 몇 초마다 갱신된다. |
| 비기능 | 주변 친구의 이치 변화가 반영되는데 너무 오랜 시간이 걸리지 않아야 한다. |
| 비기능 | 시스템은 전반적으로 안정적이어야 하지만 몇개이 데이터가 유실되는 것 정도는 용인할 수 있다. |
| 비기능 | 위치 데이터를 저장하기 위해 강한 일관성을 지원하는 데이터 저장소를 사용할 필요는 없다. 복제본의 데이터가 원본과 동일하게 변경되기까지 몇 초 정도 걸리는 것은 용인할 수 있다. |
개략적 규모 추정
| 항목 | 추정값 |
|---|---|
| DAU (일일 활성 사용자 수) | 1억 명 |
| 동시 접속 사용자 | 천만(1억 * 10%) |
| QPS (초당 쿼리 수) | 334,000 (30초마다 자기 위치를 시스템에 전송) |
2단계: 개략적 설계안 제시 및 동의 구하기
개략적 설계 및 시스템 구성 요소
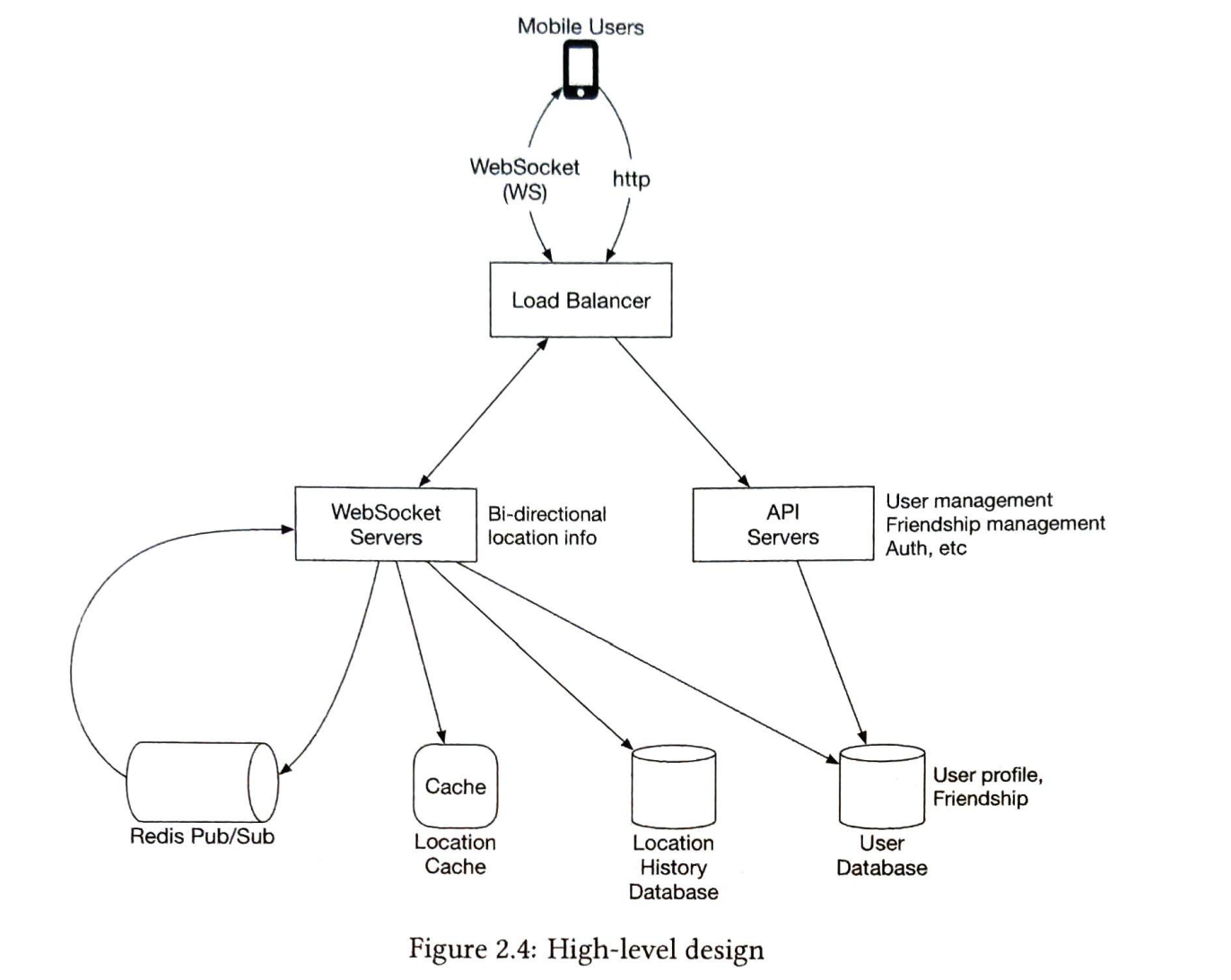
로드밸런서 (Load Balancer)
- 기능: RESTfurl API 서버 및 웹소켓 서버로 트래픽을 배분한다.
RESTfurl API 서버
- 기능: 친구를 추가/삭제하거나 사용자 정보를 갱신한다.
웹소켓 서버
- 기능:
- 검색 반경 내 친구 위치가 변경되면 해당 내역을 전송한다.
- 모바일 클라이언트가 시작되면, 모든 주변 친구 위치를 전송한다.
- 새로 계산한 거리가 검색 반경 이내면 갱신된 위치와 갱신 시각을 웹소켓 연결을 통해 클라이언트앱으로 보낸다.
- 특징: 거의 실시간에 가깝게 처리하는 유상태 서버 클러스터다.
레디스 위치 정보 캐시
- 기능: 활성 상태 사용자의 가장 최근 위치 정보를 캐싱한다.
사용자 데이터베이스
- 기능: 사용자의 데이터 및 사용자의 친구 관계 정보를 저장한다.
- 특징: 관계형 데이터베이스나 NoSQL 둘다 사용가능한다.
위치 이동 이력 데이터베이스
- 기능: 사용자의 위치 이동 변동 이력을 보관한다.
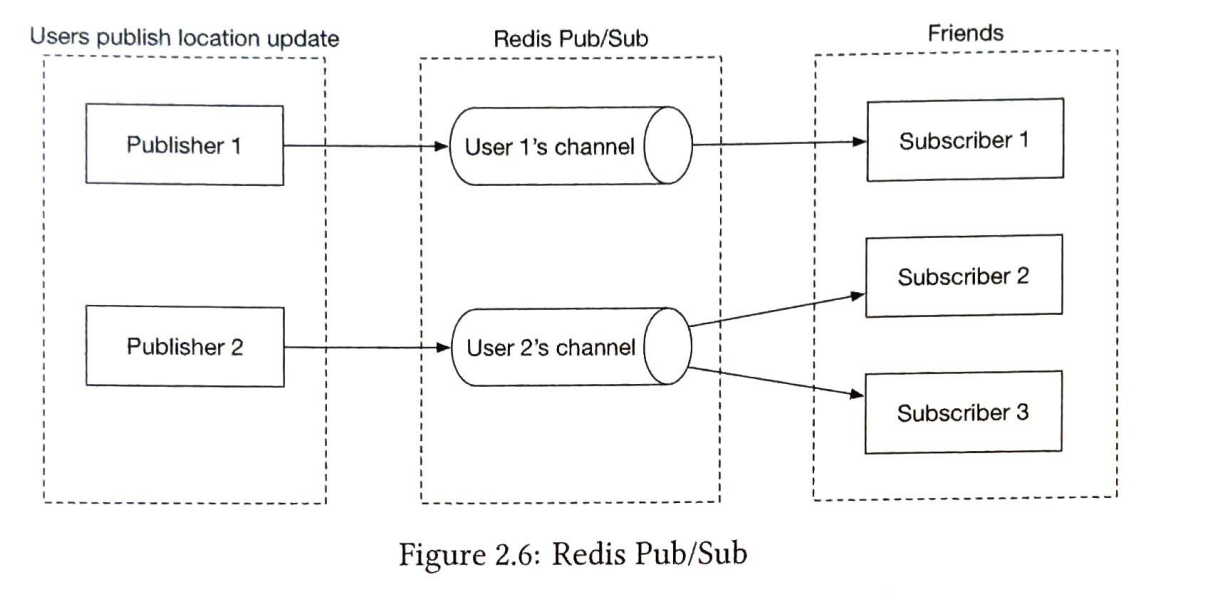
레디스 펍/섭 서버
- 기능:
- 특정 사용자의 위치 정보 변경 이벤트는 해당 사용자에게 배정된 펍/섭 채널에 발행한다.
서버-클라이언트 간 실시간 데이터 통신을 고려할 때, 어떤 프로토콜이 있을까?
-
HTTP (Long Polling):
- 클라이언트에서 서버로 요청 클라이언트는 HTTP 요청을 서버에 보낸다.
- 장점 HTTP 프로토콜을 사용하기 때문에 서버와 클라이언트 간의 통신이 단순하고, 네트워크 방화벽에서 많은 경우 허용된다.
- 단점 실시간성이 낮고, 서버에 부하가 많이 걸릴 수 있다. 클라이언트가 주기적으로 요청을 보내야 하므로 오버헤드가 발생할 수 있다.
-
WebSocket
- 클라이언트에서 서버로 요청 클라이언트는 WebSocket을 통해 서버에 연결을 요청한다.
- 서버에서 클라이언트로 데이터 전송 서버와 클라이언트는 양방향 연결을 유지하며, 서버나 클라이언트가 원할 때 데이터를 보낼 수 잇다.
- 장점 양방향 실시간 통신을 지원하며, 연결을 유지하므로 HTTP Long Polling보다 더 낮은 지연 시간과 더 높은 실시간성을 제공한다.
- 단점 WebSocket 프로토콜을 지원하는 모든 네트워크 환경에서 사용할 수 없을 수 있고, 추가적인 서버 및 클라이언트 구현이 필요할 수 있다.
-
Server-Sent Events (SSE)
- 서버에서 클라이언트로 데이터 전송 서버는 연결을 열어두고, 이벤트를 스트림 형식으로 클라이언트로 보낸다.
- 장점 단방향 실시간 통신을 제공하며, 특히 서버에서 클라이언트로의 데이터 푸시가 필요한 경우 유용합니다. HTTP 기반으로 동작하므로 기존 인프라와 호환성이 좋다.
- 단점 양방향 통신이 필요한 경우에는 적합하지 않으며, 모바일 네이티브 애플리케이션에서 지원이 부족할 수 있다.
데이터 모델
위치 정보 캐시

사용자의 현재 위치만을 이용하기 때문에 읽기 및 쓰기 연산 속도가 빠른 레디스를 사용한다. TTL 을 사용하여 활성 상태가 아닌 사용자 정보를 자동으로 제거할 수 있다.
위치 이동 이력 데이터베이스
막대한 쓰기 연산 부하를 감당할 수 있고, 수평적 규모 확장이 가능해야한다. 이러한 요구사항에서 카산드라를 사용할 수 있다.
카산드라 Eventually Consistency (최종 일관성)
데이터베이스 시스템에서 모든 복제본이 언젠가는 일관된 상태에 도달할 것임을 보장하는 일관성 모델이다. 카산드라에서 이는 다음과 같은 특성을 가진다.
-
비동기 복제
- 카산드라는 쓰기 작업을 수행한 후, 모든 복제본에 대해 즉시 일관성을 보장하지 않는다. 대신, 비동기적으로 복제가 이루어진다. 이는 쓰기 작업이 클러스터 전체에 전파되는 시간을 의미한다.
- 이는 쓰기 작업의 응답 시간을 줄이는 데 기여한다. 따라서 클라이언트는 쓰기 작업이 성공한 즉시 응답을 받고 다음 작업을 진행할 수 있다.
-
읽기 작업의 일관성 보장
- 쓰기 작업 후 모든 복제본이 동일한 데이터를 가지게 될 때까지 시간이 걸릴 수 있지만, 읽기 작업에 대해서는 일관성을 보장한다. 즉, 최근에 쓰여진 데이터가 아니더라도 이전에 쓰인 데이터는 정확하게 읽을 수 있다.
-
튜너블한 일관성 수준
- 카산드라는 개발자가 일관성 수준을 조절할 수 있는 옵션을 제공한다. 일관성 수준을 "ONE" (한 노드에만 쓰기를 완료하면 성공)에서부터 "QUORUM" (다수결 일관성, 노드의 과반수 이상에 쓰기가 완료되어야 함) 등 다양하게 설정할 수 있다.
-
분산 환경에서의 적용
- 다중 데이터 센터 환경에서도 최종 일관성 모델을 유지하며, 데이터의 지역적 복제와 장애 복구 기능을 통해 데이터의 가용성과 일관성을 동시에 유지할 수 있다.
3단계: 상세 설계
클라이언트 초기화
웹소켓 연결이 초기화되면 서버에서는 사용자의 모든 친구 정보를 가져온 후, 위치 정보 캐시에 일괄 요청을 보내어 모든 친구의 위치를 한번에 가져온다.
레디스 클러스터 모드인 경우 데이터가 각각 다른 해시 슬롯에 분산되어 있을텐데 조회 시 부하는 없을까? 위치 캐시만 동일 슬롯에 저장하도록 하는게 좋을까?
lettuce 가 슬롯이 분산되어있으면 100개를 단건으로 조회하는 future 를 만들어서 반환한다. 그래서, 전체적으로 네트워크 오버헤드가 발생할 수 있다.
하지만 단일 노드에 비해 클러스터에서는 조회 요청이 여러 노드로 분산되기 때문에 개별 노드의 부하는 줄어들 수 있다.
레디스 펍/섭 서버와 메시지 버스(카프카/MQ)의 작동 방식을 비교
기본 작동 방식
- 레디스 펍/섭 서버:
- 레디스는 Pub/Sub 방식으로 메시지를 전송함.
- 발행자가 메시지를 채널에 발행하면, 구독자가 그 채널을 통해 메시지를 받음.
- 브로드캐스트를 하지 않으면 특정 채널을 구독 중인 구독자에게만 메시지가 전달됨.
- 메시지 버스(카프카/MQ
- 카프카와 MQ는 메시지를 토픽 기반으로 전송함.
- 생산자가 메시지를 토픽에 전송하면, 소비자가 그 토픽을 구독하고 메시지를 받음.
- 브로드캐스트 없이도 특정 토픽을 구독 중인 소비자에게만 메시지가 전달됨.
메시지 되감기
- 레디스 펍/섭
- 메시지를 일단 발행하면 되감기가 불가능함.
- 구독자가 메시지를 놓치면 다시 받을 수 없음.
- 카프카
- 메시지를 되감기할 수 있음.
- 소비자는 특정 오프셋으로 되돌아가 이전 메시지를 다시 읽을 수 있음.
확장성
- 레디스 펍/섭
- 확장할 때 신경을 많이 써야 함.
- 다수의 구독자가 있을 경우, 성능 저하와 같은 문제가 발생할 수 있음.
- 카프카
- 브로커와 소비자만 늘리면 확장이 용이함.
- 리밸런싱이나 메시지가 소비되지 않는 경우 장애가 발생할 수 있지만, 이런 문제를 관리하는 도구와 기능이 제공됨.
생각해보면 좋을 질문
레디스 클러스터 모드인 경우 데이터가 각각 다른 해시 슬롯에 분산되어 있을텐데 조회 시 부하는 없을까? 위치 캐시만 동일 슬롯에 저장하도록 하는게 좋을까?
lettuce 가 슬롯이 분산되어있으면 100개를 단건으로 조회하는 future 를 만들어서 반환한다. 그래서, 전체적으로 네트워크 오버헤드가 발생할 수 있다.
하지만 단일 노드에 비해 클러스터에서는 조회 요청이 여러 노드로 분산되기 때문에 개별 노드의 부하는 줄어들 수 있다.
데이터 샤딩 시에 샤딩 키가 변경되는 경우에 데이터 리밸런싱을 최소화하기 위해 어떤 전략을 취할 수 있을까?
-> 리밸런싱 해야하는 대상만 추출 -> 리밸런싱 -> 구현 난이도가 어려울 수 있음
-> 모든 데이터를 리밸런싱 하는 방식 -> 구현 난이도가 쉬움 -> 우아한 형제들 주문 MSA 에서는 샤드를 사용하는 데이터는 최근 날짜 기준 2달치만 저장함 -> 모든 데이터를 리밸런싱 하는 방식
