진행하고 있는 프로젝트에 아래와 같은 기능이 필요했다.
MP4 파일 업로드 -> 파일에서 음원만 분리 -> 학습시킨 모델을 이용해서 음원을 텍스트로 변환
Machine Learning을 위해 서버를 올리는 것에서 서버리스 아키텍쳐인 Lambda로 변경한 이유는 다음과 같다.
- 간단한 CICD 스크립트
- 로깅 등 모니터링 코드를 추가할 필요 없음
- AWS에 관한 설정 불필요
- 데이터 처리 속도 향상
- 기존에는 클라이언트에서 API 서버에 요청을 하면, API 서버와 Machine Learning 서버의 통신을 통해 데이터를 처리하고, 그 결과를 다시 클라이언트에 응답하는 로직으로 결과를 내려주기까지에 클라이언트와 서버, 서버와 서버간 요청이 많았다.
- 변경된 아키텍쳐에서는 AWS S3 트리거를 사용하여 별다른 API 요청 없이도 lambda에서 데이터를 처리하도록 변경하였다. 최종적으로 처리시간을 3분에서 40초로 줄일 수 있었다.(3분영상 기준)
⭐좋아! AWS Lambda를 사용해보자!⭐
Lambda 레이어에 필요한 라이브러리를 추가하자!
그냥 필요한 라이브러리 올리면 되는 줄 알았건만, 런타임 언어에 따라 정해진 디렉토리 구조를 따라야한다.
각각의 계층(Layer)들은 함수 실행 환경에서 /opt 디렉토리로 추출된다. 각 런타임은 언어에 따라 /opt 아래의 각각의 경로 하위 라이브러리를 찾는다.
Node.js : nodejs/node_modules, nodejs/node8/node_modules(NODE_PATH)
예) xray-sdk.zip
└ nodejs/node_modules/aws-xray-sdk
Python : python, python/lib/python3.7/site-packages(사이트 디렉토리)
예) pillow.zip
│ python/PIL
└ python/Pillow-5.3.0.dist-info
위와 같이 언어에 맞는 구조로 패키지를 구성하여 zip으로 압축하여 업로드 하면 된다.
예를 들어, 내가 pydub 라이브러리를 레이어에 추가하고 싶다면
📦압축해야할 폴더
┗ 📂python
┃ ┗ 📂pydub
┃ ┃ ┣ 📂__pycache__
┃ ┃ ┃ ┣ 📜audio_segment.cpython-39.pyc
┃ ┃ ┃ ┣ 📜effects.cpython-39.pyc
┃ ┃ ┃ ┣ 📜exceptions.cpython-39.pyc
┃ ┃ ┃ ┣ 📜generators.cpython-39.pyc
┃ ┃ ┃ ┣ 📜logging_utils.cpython-39.pyc
┃ ┃ ┃ ┣ 📜playback.cpython-39.pyc
┃ ┃ ┃ ┣ 📜pyaudioop.cpython-39.pyc
┃ ┃ ┃ ┣ 📜scipy_effects.cpython-39.pyc
┃ ┃ ┃ ┣ 📜silence.cpython-39.pyc
┃ ┃ ┃ ┣ 📜utils.cpython-39.pyc
┃ ┃ ┃ ┗ 📜__init__.cpython-39.pyc
┃ ┃ ┣ 📜audio_segment.py
┃ ┃ ┣ 📜effects.py
┃ ┃ ┣ 📜exceptions.py
┃ ┃ ┣ 📜generators.py
┃ ┃ ┣ 📜logging_utils.py
┃ ┃ ┣ 📜playback.py
┃ ┃ ┣ 📜pyaudioop.py
┃ ┃ ┣ 📜scipy_effects.py
┃ ┃ ┣ 📜silence.py
┃ ┃ ┣ 📜utils.py
┃ ┃ ┗ 📜__init__.py제일 상위 폴더인 압축해야할 폴더을 압축하여, 레이어에 올리면 된다. 처음에 python 폴더를 올렸다가, 라이러리 import가 안 되어서 애를 먹었다😂 python 폴더 안에 올리고 싶은 라이브러리를 넣고, 한번 더 감싸서 올린다고 생각하면 편할 것 같다.
참고로 라이브러리들은 람다 환경에서 /opt/python 아래 설치될 것이다.
별도의 경로 설정이 필요한 실행파일들은 어떻게 해야할까?
- FFmpeg 사용 예시
FFmpeg 다운
1. https://johnvansickle.com/ffmpeg/ 홈페이지로 이동
2. release: 4.4 - ffmpeg-release-amd64-static.tar.xz 다운 및 압축 해제
3. ffmpeg-release-amd64-static 폴더 위에압축해야할 폴더를 감싸서 으로 압축
📦압축해야할 폴더
┗ 📂ffmpeg
┃ ┣ 📂manpages
...
┃ ┣ 📂model
┃ ┃ ┣ 📂other_models
...
┃ ┣ 📜ffmpeg
┃ ┣ 📜ffprobe
┃ ┣ 📜GPLv3.txt
┃ ┣ 📜qt-faststart
┃ ┗ 📜readme.txtffmpeg=/opt/ffmpeg/ffmpeg
mp.ffmpeg_tools.ffmpeg_extract_audio(...)이렇게 호출해서 사용하면 된다.
lambda에서 레이어로 바로 올릴 수 있는 파일의 크기에 제한이 있다고?

그렇다. 하지만 s3에 올려서 url을 첨부만 하면 된다.

lambda에서 사용할 수 있는 크기에 제한이 있다고?
람다 패키지는 압축 기준 50MB, 압축 해제 기준으로는 250MB를 지원하고 있다.
프로젝트에서 필요한 라이브러리만 이만큼...
tensorflow==2.7.0
tensorflow_io==0.23.1
ffmpeg-python==0.2.0
boto3==1.21.23
pydub==0.25.1
urllib3==1.26.9
imageio-ffmpeg==0.4.5
llvmlite==0.38.0tensorflow만해도 턱없이 부족했다.
Lambda 스크립트 대신 컨테이너 이미지를 이용해보자!
AWS ECR에 이미지를 푸시하면, 그 이미지를 lambda에 배포하는 방식이다.
도커 이미지 빌드만 잘 되면 되는거다!! 이미지 크기는 크게 제한이 없는 것 같다.
이미지는 public.ecr.aws/lambda/python:3.7을 이용했다.
이미지 빌드도 잘 되고, 배포도 잘 된 것 같은데 왜 3초만에 끝나버리지?

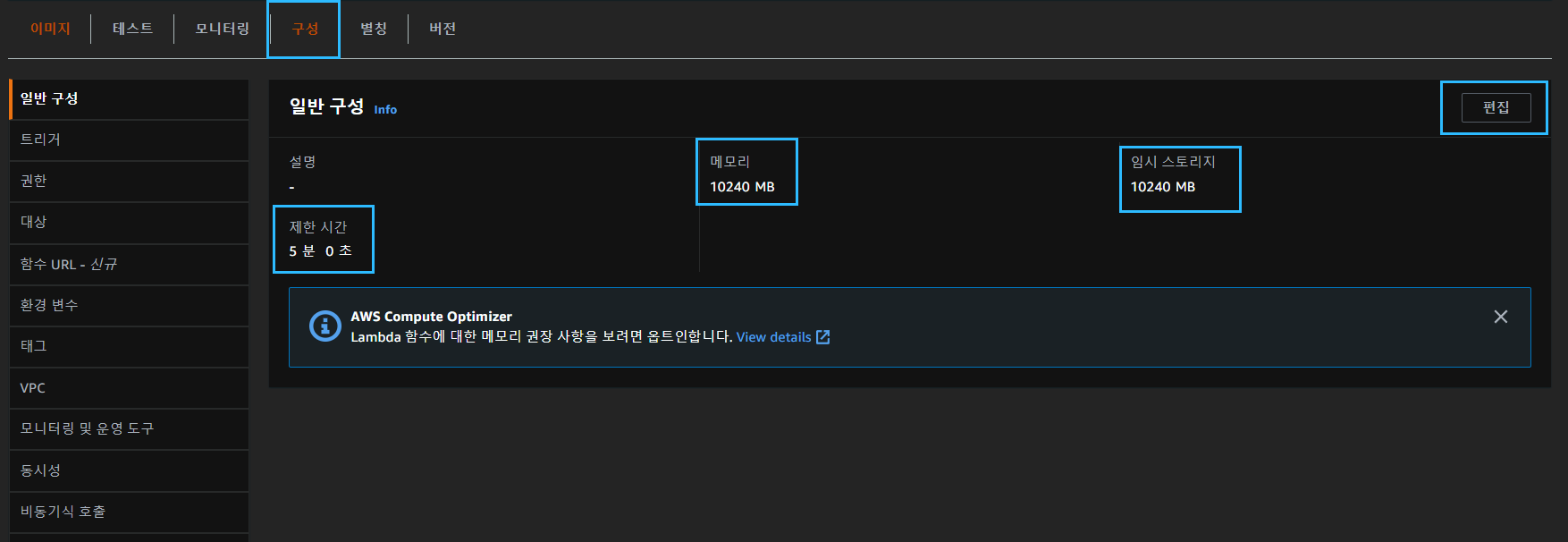
이렇게 아무런 에러 없이 끝나버리는 경우에는, 구성에서 제한시간을 원하는 만큼 변경하자.
기본 제한 시간이 3초인가 5초로 설정되어있다. 메모리도 원하는 만큼 늘려서 사용하자. 메모리때문에 중간에 멈춰버리는 경우도 있었다.
파일 다운로드가 왜 안 될까?
lambda에서는 다운로드하거나, 파일을 write할 수 있는 폴더를 /tmp로 제한하고 있다.
다른 곳에 다운로드 하려고 하면 에러를 뱉어낸다.

s3.download_file(bucket, key, '/tmp/' + userFile)이렇게 다운받으려는 파일 앞에 /tmp를 붙이자.
filepath = '/tmp/' + key
환경변수 설정은 어떻게 하지?
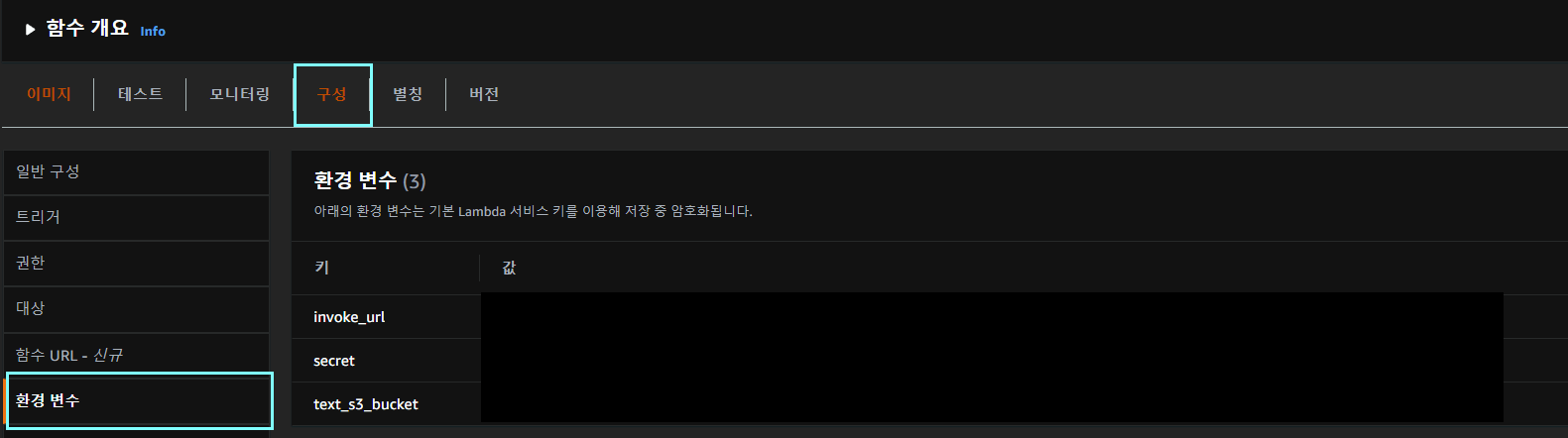
aws에서 환경변수 설정 후에, 파이썬 기준으로 os.environ로 설정해주면 된다.
`invoke_url = os.environ['invoke_url']` 라이브러리에서는 Multiprocessing이 필요한데, lambda에서는 Multiprocessing을 지원하지 않네?
mp4영상에서 음원분리를 위해서 spleeter를 사용중인데, 해당 라이브러리는 Multiprocessing이 필요했다. Python 2.7 and Python 3.6버전에서만 Multiprocessing을 지원하다고 하는데, 우리는 Python 3.7을 사용하고 있었고, 버전을 낮추니 다른 라이브러리 버전과 충돌이 생겼다.
결국 이 라이브러리를 통채로 다운받아서, 해당 Multiprocessing이 필요한 파이썬 스크립트만 바꿔서 도커에 통채로 얹어놓았다. 이것이 맞는 방식인지는 아직도 모르겠다😱
덕분에 우리의 도커 이미지 크기는 6GB가 되었다.
람다를 공부했더니, 도커도 공부가 되었네👍 도커 내부 구조에 대해 알 수 있는 경험이었다. 조금 더 공부해서 포스팅도 해보자
고생고생한 코드는 여기
전체 프로젝트
https://github.com/So-Woo-Ju/sowooju-ml-lambda
정말 간단한 Github Action을 이용한 lambda 배포 스크립트
https://github.com/So-Woo-Ju/sowooju-ml-lambda/blob/develop/.github/workflows/aws.yml
