Prometheus, Grafana, k6의 개념과 역할
Prometheus는 오픈 소스 모니터링 및 경보 시스템으로, 시계열(time-series) 데이터베이스를 내장하고 애플리케이션/시스템으로부터 메트릭 데이터를 수집합니다. Prometheus는 풀(Pull) 방식으로 동작하여 대상 시스템에 주기적으로 접속해 미터링 엔드포인트를 스크레이핑(scraping)함으로써 데이터를 가져옵니다.
수집한 성능 지표들은 고유한 메트릭 이름과 레이블(key-value 쌍)로 구분되어 저장되며, 사용자는 PromQL이라는 질의 언어를 통해 데이터를 분석할 수 있습니다. 또한 Prometheus는 임계값 초과 등의 조건을 감지해 Alertmanager와 연동한 경보(alert) 발송도 지원합니다.
Grafana는 다양한 데이터 소스로부터 메트릭을 불러와 시각화 대시보드를 생성하는 오픈 소스 플랫폼입니다. Grafana를 사용하면 Prometheus에 축적된 모니터링 지표나 AWS CloudWatch와 같은 외부 모니터링 시스템의 지표를 가져와 대시보드 형태로 시각화할 수 있습니다. Grafana는 다양한 시각화 패널(그래프, 게이지, 테이블 등)을 제공하고, 실시간으로 대시보드를 갱신하거나 기간을 변경하여 추이 분석을 할 수 있게 해줍니다. 또한 임계치에 따른 알람 규칙을 설정하여 이메일, Slack 등의 채널로 통보를 보낼 수도 있습니다. 결국 Grafana는 모니터링 관찰성을 높여주고 운영자가 한 눈에 시스템 상태를 파악하도록 돕는 역할을 합니다. k6는 Grafana Labs에서 개발한 오픈 소스 부하 테스트 도구입니다.
k6는 코드 기반(JavaScript 스크립트)으로 시나리오를 작성해 대량의 가상 사용자(VU)를 시뮬레이션함으로써 애플리케이션에 부하를 가합니다. HTTP, WebSocket 등 다양한 프로토콜에 대해 부하 테스트를 지원하며, 테스트 중에 요청당 응답 시간, 초당 처리량, 에러율 등의 성능 지표를 수집합니다. k6는 경량으로 설계되어 CLI 환경에서 쉽게 실행할 수 있고, 테스트 결과를 콘솔 요약뿐만 아니라 외부 시계열 DB로 출력하여 실시간 모니터링 및 사후 분석 대시보드로 활용할 수 있습니다. 즉, k6는 시스템의 한계치 파악과 성능 튜닝 인사이트 확보를 위한 도구이며, Prometheus·Grafana와 연계하여 부하 테스트 결과를 시각적으로 모니터링할 수 있습니다.
Spring Boot 애플리케이션에 Prometheus 연동하기
Java Spring(Spring Boot) 기반 서비스에서는 Micrometer 라이브러리를 통해 손쉽게 애플리케이션 내 성능 지표를 수집하고 Prometheus로 노출할 수 있습니다. Spring Boot의 Actuator 모듈과 Micrometer를 활용하면 애플리케이션의 각종 상태 값을 계측하고 표준화된 인터페이스로 제공해줍니다. 구체적으로, Spring Boot Actuator에 포함된 /actuator/prometheus 엔드포인트를 열어두면 애플리케이션의 메트릭스를 Prometheus 포맷의 텍스트로 출력해줍니다.
구성 방법: Spring Boot에 다음 의존성을 추가합니다: spring-boot-starter-actuator와 micrometer-registry-prometheus. Actuator는 앱의 상태와 metrics를 노출해주는 모듈이며, micrometer-registry-prometheus는 수집된 메트릭을 Prometheus가 이해할 수 있는 형태로 변환해주는 Micrometer의 구현체입니다. 그런 다음 application.yml 설정 파일에서 Actuator의 웹 엔드포인트 중 Prometheus를 활성화합니다. 예를 들어:
management:
endpoints:
web:
exposure:
include: prometheus이렇게 설정하면 Spring Boot 앱 실행 시 /actuator/prometheus 경로로 접근할 때 JVM 메모리/쓰레드, CPU 사용량, Spring MVC 요청수/응답시간 등의 다양한 기본 지표들이 텍스트로 노출됩니다. 아래는 해당 엔드포인트 출력의 예시 일부입니다:
# HELP jvm_threads_daemon_threads The current number of live daemon threads
# TYPE jvm_threads_daemon_threads gauge
jvm_threads_daemon_threads 19.0
# HELP system_cpu_count The number of processors available to the Java virtual machine
# TYPE system_cpu_count gauge
system_cpu_count 8.0
# HELP tomcat_sessions_expired_sessions_total
# TYPE tomcat_sessions_expired_sessions_total counter
tomcat_sessions_expired_sessions_total 0.0위와 같이 jvm_threads_daemon_threads, system_cpu_count, tomcat_sessions_expired_sessions_total 등의 지표들이 출력되며, 각 메트릭에는 설명(HELP)과 타입(TYPE) 정보도 포함됩니다. 이러한 기본 내장 메트릭 외에도, 개발자는 Micrometer API를 통해 커스텀 메트릭(예: 특정 함수 호출 시간, 도메인 이벤트 발생 건수 등)을 정의하고 기록할 수 있습니다. Actuator/Micrometer를 활용하면 코드 레벨에서 어노테이션(@Timed 등)이나 MeterRegistry를 이용하여 카운터, 게이지, 타이머 등을 등록하고, 자동으로 /actuator/prometheus에 노출시킬 수 있습니다. 최종적으로 Prometheus는 해당 엔드포인트를 주기적으로 스크레이핑하여 애플리케이션 내부 지표들을 데이터베이스에 축적하게 됩니다.
EC2에 Prometheus 및 Grafana 설치 및 구성 (Self-Hosted vs Managed 비교)
자가 구축(Self-Hosted) 방법: 가장 직접적인 방법은 AWS EC2 인스턴스(예: Amazon Linux 2나 Ubuntu) 위에 Prometheus와 Grafana를 수동 설치하는 것입니다. Prometheus의 경우 공식 배포본의 Linux 바이너리를 다운로드하여 실행하거나, Docker 컨테이너 이미지를 사용할 수 있습니다. 예를 들어 Ubuntu EC2에 설치한다면, tar.gz 패키지를 풀어서 /usr/local/bin에 prometheus 바이너리를 배치하고, /etc/prometheus/prometheus.yml 설정 파일을 작성한 뒤 시스템 서비스(systemd)로 등록해 구동할 수 있습니다. Prometheus 설정 파일(prometheus.yml)에는 스크레이프 설정(scrape_configs)을 넣어 어떤 대상(target)에서 얼마나 자주 메트릭을 수집할지 정의합니다. 여기에는 앞서 구성한 Spring Boot 애플리케이션의 /actuator/prometheus URL(예: http://<내부-IP>:8080/actuator/prometheus)을 대상에 추가합니다. 필요에 따라 Node Exporter와 같은 에이전트를 EC2에 설치하여 OS 수준 메트릭(CPU, 메모리, 디스크 등)을 수집하고, Prometheus 설정에 해당 Node Exporter의 주소(:9100/metrics)도 추가할 수 있습니다. 이렇게 설정 후 Prometheus 서비스를 시작하면, 주기적으로 Spring Boot 앱과 Node Exporter로부터 메트릭을 가져와 저장하게 됩니다.
Grafana는 마찬가지로 공식 웹사이트에서 리눅스용 바이너리 또는 패키지를 받아 설치하거나 Docker 이미지를 실행합니다. 예를 들어 Debian 계열 OS에서는 Grafana Labs apt 리포지토리를 추가하여 apt install grafana로 설치할 수 있습니다. 설치 후 Grafana 서버를 실행하면 기본적으로 포트 3000에서 웹 UI가 열립니다. 최초 접속하여 관리자 계정으로 로그인한 후, 데이터 소스로 Prometheus를 추가합니다. (Grafana UI에서 Configuration > Data Sources로 이동, Prometheus URL을 설정). 이렇게 하면 Grafana가 백엔드의 Prometheus로부터 질의(쿼리)를 보내 메트릭 데이터를 가져올 수 있습니다. 이제 Prometheus와 Grafana가 모두 EC2 상에서 동작하며, Spring Boot 애플리케이션의 내부 지표를 수집·시각화할 준비가 갖춰집니다.
비교: AWS 관리형 서비스(Managed Service)를 이용하는 대안도 있습니다. 대표적으로 Amazon Managed Service for Prometheus(AMP)와 Amazon Managed Grafana가 있습니다. Managed 서비스를 사용하면 인프라 설치나 업그레이드 없이 AWS가 제공하는 완전관리형 Prometheus/Grafana 인스턴스를 이용할 수 있습니다. 예를 들어 Amazon Managed Grafana는 Grafana 서버를 AWS가 운영해주며, AWS IAM이나 SSO 연동으로 접근제어를 간편하게 설정할 수 있습니다. Amazon Managed Prometheus는 AWS가 호스팅하는 높은 신뢰성의 Prometheus 호환 저장소로, 주로 EKS(Kubernetes) 환경과 연계하여 쓰이지만, CloudWatch 에이전트나 Prometheus Remote Write를 통해 EC2 워크로드의 지표도 보낼 수 있습니다. 관리형 서비스의 장점은 유지보수 편의성과 자동 확장입니다. 사용자는 패치나 스케일링을 신경 쓸 필요 없이, AWS가 고가용성으로 운영해주므로 운영 오버헤드가 줄어듭니다. 또한 AWS 서비스와의 보안 통합(IAM 권한 관리, VPC 접근 등)이 수월합니다. 반면 단점으로는 추가 비용 발생 및 커스터마이징 제약이 있습니다. 예를 들어 Managed Grafana는 플러그인 설치에 제한이 있거나, Managed Prometheus는 사용한 메트릭 데이터량에 따라 비용이 청구됩니다. 소규모/중규모(예: 하루 수백만 건 미만의 시계열 데이터) 환경에서는 EC2 위에 직접 Prometheus를 올려 사용하는 것이 비용 효율적일 수 있지만, 서비스 규모가 커져 Prometheus 서버의 부하가 높아지거나 HA 구성이 필요해지면 관리형 옵션을 검토하는 것이 좋습니다.
Tip: Grafana는 CloudWatch를 비롯한 다양한 AWS 서비스에 직접 데이터 소스로 연결할 수 있습니다. 꼭 모든 지표를 Prometheus로 수집하지 않더라도, Grafana에서 AWS 자격 증명을 설정해 CloudWatch 지표를 바로 시각화하는 것도 가능합니다.
RDS, Lambda 등 AWS 리소스의 지표 수집 방법 (CloudWatch 연동)
AWS EC2 외에도 RDS (Relational Database Service)나 Lambda와 같은 AWS 관리형 리소스의 성능 지표도 모니터링해야 합니다. 이러한 리소스들은 애플리케이션처럼 직접 Prometheus 메트릭 엔드포인트를 제공하지는 않지만, AWS의 CloudWatch 모니터링 서비스와 통합되어 기본 지표를 제공합니다. 예를 들어 RDS(MySQL/PostgreSQL)의 경우 CPUUtilization, FreeableMemory, DatabaseConnections, Read/Write IOPS 등의 지표를 CloudWatch에서 확인할 수 있고, Lambda 함수의 경우 Invocations, Duration, Errors, Throttles 등의 지표를 CloudWatch에 자동으로 보냅니다. 이 CloudWatch 지표들을 Grafana/Prometheus 생태계로 가져오는 방법은 두 가지를 고려할 수 있습니다.
1. Grafana에서 CloudWatch 데이터 소스 사용
Grafana는 AWS CloudWatch를 데이터 소스로 지원하므로, Grafana 설정에서 CloudWatch 데이터 소스를 추가하면 됩니다. 앞서 Stack Overflow 답변에서도 언급된 것처럼, AWS IAM에서 CloudWatchReadOnlyAccess 정책이 부여된 액세스 키를 가진 IAM User를 하나 생성한 뒤, Grafana의 데이터 소스 설정 화면에서 해당 액세스 키/시크릿을 입력하여 CloudWatch에 읽기 접근 권한을 부여할 수 있습니다. 연결 시 AWS Region을 지정하면 Grafana를 통해 해당 리전에 있는 RDS, Lambda 등 서비스의 지표를 쿼리할 수 있습니다. 이렇게 하면 별도의 수집기 없이 Grafana가 필요할 때마다 CloudWatch API를 호출해 최신 지표를 가져옵니다. Grafana에는 AWS 리소스별로 미리 만들어진 대시보드(Json)도 커뮤니티에 공개되어 있어, ID로 불러와 바로 시각화를 구현할 수도 있습니다. 이 접근 방식의 장점은 설정이 간편하고 AWS가 제공하는 모든 CloudWatch 지표를 그대로 활용할 수 있다는 점입니다. 다만 Grafana 대시보드에서 조회할 때마다 CloudWatch API 호출이 발생하므로 쿼리 지연이 있을 수 있고, CloudWatch API 비용이 소량 발생할 수 있습니다.
2. Prometheus CloudWatch Exporter 사용
두 번째 방법은 Prometheus exporter를 활용해 CloudWatch 지표를 주기적으로 가져와 Prometheus에 저장하는 것입니다. Prometheus에는 공식 CloudWatch Exporter(Java로 구현)와 경량 Go 구현체(YACE: Yet Another CloudWatch Exporter) 등이 있습니다. CloudWatch Exporter를 EC2 인스턴스나 컨테이너로 실행하고, AWS 접근 권한을 주면 이 Exporter가 CloudWatch로부터 지정된 지표를 수집해 자체 /metrics 엔드포인트로 노출합니다. 이후 Prometheus 설정에 이 Exporter의 엔드포인트를 추가하여 스크레이핑하면, CloudWatch 지표가 Prometheus DB에 축적되는 구조입니다.
CloudWatch Exporter 설정은 YAML 구성 파일로 이루어지며, 어떤 AWS 네임스페이스와 지표를 가져올지 명시합니다. 예를 들어 RDS 관련 주요 지표를 수집하려면 설정에 aws_namespace: AWS/RDS 아래에 DBInstanceIdentifier 차원으로 구분되는 CPUUtilization, FreeableMemory, DiskQueueDepth 등 원하는 메트릭 이름들을 열거해두면 됩니다. Exporter는 이 설정을 토대로 CloudWatch GetMetricData API를 호출하여 데이터를 가져오며, 필요한 IAM 권한은 읽기 전용에 준합니다 (예: cloudwatch:ListMetrics, cloudwatch:GetMetricStatistics, cloudwatch:GetMetricData 등이 필요 - AWS의 CloudWatchReadOnlyAccess 정책에 이 권한들이 포함되어 있습니다). Exporter 실행 시에는 이러한 AWS 자격 증명을 환경변수나 IAM Role로 전달해주어야 합니다. CloudWatch Exporter 방식의 장점은 Prometheus DB에 지표가 쌓이므로 다른 앱 지표와 함께 통합 분석이나 알람 설정을 할 수 있고, CloudWatch에 없는 세밀한 집계(예: 5초 간격 등)도 가능합니다. 반면 단점은 지속적으로 CloudWatch API를 호출하므로 약간의 비용이 추가되고, 지표 수집 주기 및 대상 설정을 관리해야 한다는 점입니다. 또한 너무 많은 지표를 짧은 주기로 가져오면 CloudWatch API Rate Limit에 걸리거나 Prometheus 성능에 부담을 줄 수 있으므로, 필요한 지표만 선별하고 적절한 간격으로 수집하는 것이 중요합니다.
어느 방식을 선택할까? 작은 규모에서는 Grafana가 CloudWatch를 직접 조회하는 것으로도 충분하며 간단합니다. 하지만 지표를 장기간 저장하며 애플리케이션 지표와 한 곳에서 관리하고 싶다면 Exporter로 가져와 Prometheus에 저장하는 편이 유리합니다. 예를 들어, RDS의 CPU 사용률과 동시에 애플리케이션의 쓰레드 수 변화를 하나의 PromQL 쿼리로 결합하여 보거나, Lambda의 에러율 증가와 동시에 애플리케이션 로그 지표를 연관 분석하려면 모든 지표가 Prometheus에 있는 편이 다루기 쉽습니다. 필요에 따라 두 방식을 병행할 수도 있습니다. Grafana에서 CloudWatch 데이터를 실시간 보면서, 핵심 지표는 Exporter로 끌어와 중요 이벤트에 대한 Alert을 Prometheus/Alertmanager로 발송하게 할 수도 있습니다.
k6를 이용한 부하 테스트 및 Grafana 연동
운영 중인 서비스에 대해 부하 테스트를 실시하면 현재 시스템의 처리 한계를 파악하고 병목 지점을 발견할 수 있습니다. 앞서 구성한 모니터링 환경에 k6를 통합하면, 부하 테스트를 실행하면서 그 결과(트래픽량, 응답시간, 에러율 등)를 실시간으로 Grafana 대시보드에서 모니터링할 수 있습니다.
k6 기본 사용
k6를 사용하려면 부하 테스트 스크립트를 JavaScript로 작성하고 CLI로 실행합니다. 예를 들어 간단히 10분 동안 VU(가상사용자) 200까지 증가시키며 특정 API 엔드포인트를 때리는 시나리오를 스크립트로 작성할 수 있습니다. k6 run script.js 명령으로 실행하면 콘솔에 실시간 진척도와 최종 요약(평균/최대 응답시간, 요청 수, 에러 수 등)이 출력됩니다. 하지만 콘솔 출력만으로는 테스트 동안의 세부 추이를 보기 어렵기 때문에, 외부 모니터링 시스템으로 결과를 내보내는 옵션을 사용하는 것이 좋습니다. k6는 실행 시 --out 옵션을 통해 여러 종류의 출력 backend로 결과 메트릭을 전송할 수 있도록 설계되어 있습니다. 예를 들어 InfluxDB, JSON, Graphite 등이 기본 지원되며, Prometheus와의 연동을 위해 Prometheus Remote Write 방식을 실험적으로 지원합니다.
Prometheus로 k6 결과 전송
k6의 Prometheus Remote Write output을 사용하면 k6가 생성하는 시계열 데이터를 직접 지정한 Prometheus 서버의 원격 쓰기 엔드포인트로 전송할 수 있습니다. 이 방식은 k6 실행 시 -o experimental-prometheus-rw 플래그를 사용하고, 환경변수 K6_PROMETHEUS_RW_SERVER_URL에 Prometheus Remote Write 수신 경로(예: http://<Prometheus서버>:9090/api/v1/write)를 지정하면 활성화됩니다. 단, 기본적으로 Prometheus는 원격 쓰기 수신 기능이 비활성화되어 있으므로, Prometheus 실행 시 --web.enable-remote-write-receiver 플래그를 주어 remote write 리시버를 켜야 합니다. (Prometheus 2.41+ 버전부터 이 기능이 실험적으로 제공됩니다.) 이렇게 설정한 후 k6 스크립트를 실행하면, k6 내부적으로 매 초 수집하는 메트릭들을 Prometheus에 푸시합니다. k6가 전송하는 주요 메트릭으로는 http_req_duration(HTTP 요청 응답시간 분포), http_reqs(요청 횟수), vus(현재 가상사용자 수), iterations(완료된 테스트 케이스 수) 등이 있습니다. 이 데이터는 Prometheus DB에 일반 애플리케이션 메트릭과 동일하게 저장되고, Grafana에서 Prometheus를 조회하여 k6 테스트 상황을 실시간 그래프로 볼 수 있게 됩니다. Grafana Labs에서는 k6용 공식 대시보드 템플릿도 제공하고 있어서, Grafana 대시보드 목록에서 "k6 Prometheus" 대시보드를 가져오면 주요 부하 테스트 지표를 보기 좋게 시각화할 수 있습니다.
한 가지 유의할 점은, k6 → Prometheus 직접 전송은 아직 실험적 기능이므로 환경에 따라 세부 조정이 필요할 수 있습니다. 예를 들어 트렌드(Trend) 메트릭을 히스토그램으로 보관하려면 Prometheus와 k6 양측에서 실험적 히스토그램 기능을 활성화해야 합니다. 만약 이러한 구성이 부담스럽다면, 차선책으로 k6 결과를 InfluxDB로 보내고 Grafana에서 InfluxDB를 데이터 소스로 추가하는 방법도 사용됩니다. (k6의 --out influxdb=http://... 옵션 활용). InfluxDB는 설정이 비교적 간단하고 Grafana에서도 지원이 완성되어 있어 많이 쓰이는 방식입니다. 하지만 InfluxDB를 새로 도입하기보다 기존 Prometheus 환경에 통합하고 싶다면 앞서 언급한 Remote Write 구성이 더 직접적입니다. 부하 테스트를 실행하면 곧바로 Grafana 대시보드에서 응답 시간 추이, 에러 발생률, 시스템 자원 사용량(CPU/RDS지표) 등을 한눈에 모니터링할 수 있습니다. 이를 통해 특정 TPS(초당 트랜잭션) 수준에서 응답 시간이 급격히 증가하거나 에러가 발생하는 지점을 포착할 수 있고, 해당 시점의 인프라 자원 지표를 함께 분석하여 병목 원인을 유추할 수 있습니다.
도식
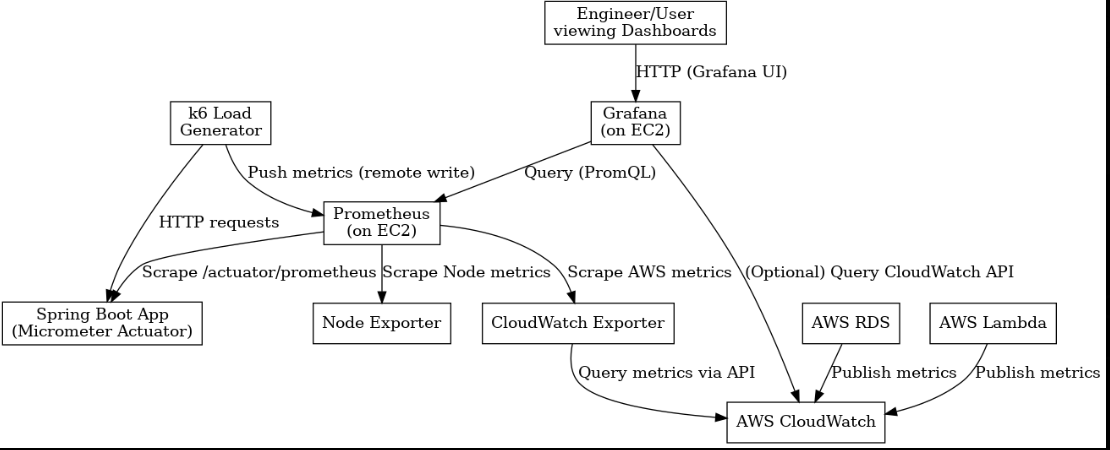
AWS 환경에서 Prometheus, Grafana, k6를 활용한 모니터링 아키텍처 예시. Spring Boot 애플리케이션이 Actuator/Micrometer로 내부 메트릭을 /actuator/prometheus로 노출하고, Prometheus 서버가 주기적으로 해당 엔드포인트를 스크레이핑하여 시계열 데이터를 수집합니다. 동시에 Node Exporter를 통해 EC2 인스턴스 OS 지표(CPU, Memory 등)를 가져오고, CloudWatch Exporter를 통해 RDS, Lambda 등의 AWS 관리형 서비스 지표도 가져옵니다. k6 부하 테스트를 실행하면 애플리케이션에 HTTP 요청 부하를 발생시키며, 발생한 테스트 결과 지표를 Prometheus의 Remote Write 엔드포인트로 푸시합니다. Grafana는 주요 데이터 소스로 Prometheus를 연결해 애플리케이션/인프라/부하테스트 메트릭을 모두 조회하고 대시보드로 시각화합니다. (또한 필요 시 Grafana가 CloudWatch API를 직접 조회하여 추가 지표를 가져올 수도 있습니다.) 마지막으로 운영 담당자는 Grafana 웹 UI에 접속해 대시보드를 보며 성능 지표를 모니터링합니다.
성능 지표 시각화를 통해 얻을 수 있는 인사이트
모니터링 환경을 구축하고 나면, 수집된 다양한 성능 지표들을 한 곳에서 시각화함으로써 얻을 수 있는 통찰력이 크게 향상됩니다. 다음은 이러한 지표들을 통해 얻을 수 있는 대표적인 인사이트들입니다:
시스템 병목 확인
대시보드를 통해 애플리케이션 레이어 지표(예: 요청 처리속도, 에러율)와 인프라 지표(EC2 CPU, RDS IOPS 등)를 함께 살펴볼 수 있습니다. 만약 부하 테스트 중 특정 시점에 응답 시간이 급증한다면, 같은 시각에 EC2의 CPU가 100%에 도달했는지, RDS의 커넥션 수가 한계치에 다다랐는지 등을 교차 확인하여 병목 지점을 특정할 수 있습니다. 예를 들어, TPS가 높아질 때 애플리케이션 스레드 풀 사용률은 낮은데 RDS의 CPU 사용률이 급상승한다면 DB가 병목임을 시사합니다.
성능 한계 및 용량 계획
k6로 부하를 점진적으로 늘려가며 임계 점을 찾고, Grafana 그래프에서 해당 임계점의 지표 패턴을 분석할 수 있습니다. 이를 통해 현재 시스템이 견딜 수 있는 최대 사용자 수나 트래픽량을 산정하고, 여유 자원 대비 얼마나 남았는지 파악할 수 있습니다. 이러한 정보는 추후 사용자 증가에 대비한 용량 산정(capacity planning)과 인스턴스 스펙 업그레이드 여부 판단에 근거를 제공합니다. 예를 들어 CPU 여유는 많지만 메모리 사용률이 지속적으로 80%를 넘는다면 메모리 증설이 필요하고, 반대로 CPU가 한계라면 스케일 아웃을 고려해야 할 것입니다.
성능 튜닝 및 최적화 효과 검증
모니터링을 통해 성능상의 약한 부분을 발견하면, 코드 최적화나 DB 인덱스 추가 등의 튜닝 작업을 수행하게 됩니다. 이때 튜닝 전후의 지표 변화를 Grafana에서 비교하여 개선 효과를 검증할 수 있습니다. 예를 들어, 특정 API의 캐싱 전략을 변경한 후 평균 응답시간이 얼마나 감소했고 DB 쿼리 수가 얼마나 줄었는지 한눈에 볼 수 있습니다. 숫자로 확인된 개선 효과는 향후에도 성능 개선 작업의 ROI를 설명하는 근거가 됩니다.
장기 추세 분석 및 이상 탐지
Prometheus에 누적된 지표 데이터를 Grafana로 장기간 추세를 살펴보면, 일별/주별 패턴이나 비정상적 추이를 파악할 수 있습니다. 예를 들어 메모리 누수가 있다면 JVM 메모리 사용량이 배포 후 시간에 따라 서서히 상승하는 추세를 보일 수 있고, 트래픽 피크가 특정 시간대에 몰린다면 해당 시간대 지표들이 반복적으로 치솟는 패턴이 관찰될 것입니다. 이러한 추세 파악은 문제를 사전에 발견하고 조치하는 프리엠프티브 모니터링을 가능케 합니다. Grafana의 알람 기능 또는 Prometheus의 Alertmanager를 활용하면 임계치 뿐만 아니라 평소 패턴에서의 이탈 여부까지 감지하여 알림을 받는 것도 가능합니다.
서비스 수준 지표(SLI/SLO) 관리
수집된 메트릭을 가공하여 서비스 수준 지표를 정의할 수 있습니다. 예를 들어, "요청 99th 퍼센타일 응답시간 2초 이내"와 같은 SLI(Service Level Indicator)를 설정하고 Grafana에서 현재 수치를 표시하거나, SLO(Service Level Objective) 달성률을 계산하는 것입니다. 이를 통해 서비스 신뢰도나 SLA 준수 여부를 모니터링하고 경영/사업 측면의 보고에도 활용할 수 있습니다.
요약하면, 한 눈에 들어오는 대시보드를 통해 시스템의 상태를 가시화하면, 문제를 발견->분석->개선하는 선순환 사이클을 빠르게 돌릴 수 있습니다. 이는 곧 서비스 운영의 안정성과 개발 생산성 향상으로 이어집니다.
운영 환경에서 고려해야 할 요소들 (보안, 비용, 확장성, 알림 설정 등)
마지막으로, 실제 프로덕션 환경에 모니터링 시스템을 구축·운영할 때 염두에 두어야 할 몇 가지 추가 요소들을 정리합니다:
보안
모니터링 구성 요소들은 민감한 내부 정보를 다루므로 접근 제어와 통신 보안이 중요합니다. 우선 Prometheus 서버와 Grafana 대시보드는 가능하면 사설망(VPC) 내부에서만 접근되도록 두고, 필요 시 VPN이나 SSH 터널 등을 통해 내부 사용자만 접속하게 설정합니다. Grafana의 경우 기본적으로 로그인 기능이 있으며, 조직에 SSO(싱글사인온)나 OAuth 연동을 활성화하여 접근 통제를 강화할 수 있습니다. Prometheus는 기본 인증 기능이 없으므로, Nginx 등의 리버스 프록시를 앞단에 두어 Basic Auth나 TLS 적용을 고려합니다. 또한 /actuator/prometheus와 같은 애플리케이션 메트릭 엔드포인트도 외부에 노출되지 않도록 하고, Kubernetes나 서비스 메ESH 사용 시에는 서비스 디스커버리와 RBAC를 통해 특정 네임스페이스에서만 스크레이핑하도록 제한하는 방법도 있습니다. AWS Managed 서비스를 쓴다면, IAM 정책과 VPC 엔드포인트 등을 활용해 지정된 IAM 사용자/역할만 데이터에 접근하고 인터넷을 경유하지 않도록 설정할 수 있습니다. 마지막으로, 메트릭 데이터 자체에 고객 식별자 등의 민감정보가 포함되지 않도록 주의해야 합니다 (예: 계정 ID 등을 레이블로 노출하지 않기).
비용 관리
오픈 소스 도구를 자체 운영한다고 해도 숨은 비용이 발생할 수 있습니다. 예를 들어 Prometheus가 저장하는 시계열 데이터의 양이 많아지면 EC2 인스턴스의 디스크 용량과 I/O 비용이 증가합니다. 기본적으로 Prometheus는 메모리 및 로컬 디스크에 데이터를 보관하므로, 보존기간(retention)을 적절히 설정하여 불필요하게 오래 데이터를 보관하지 않도록 해야 합니다. (예: 1300명 사용자 규모라면 15일 또는 30일 정도 데이터 보존 등 정책 수립). CloudWatch Exporter를 사용할 경우 CloudWatch API 호출 비용이 발생하는데, 호출 주기와 Metric 개수를 조정하여 비용을 최적화해야 합니다. Grafana 자체는 오픈소스 버전 비용이 들지 않지만, Managed Grafana를 쓰면 활성 사용자 수나 데이터 쿼리량에 따라 과금이 될 수 있으므로 미리 산정해야 합니다. k6의 경우 OSS 버전은 무료지만, 부하 테스트를 클라우드에서 분산 실행하고 싶을 때 Grafana의 k6 Cloud(유료)를 고려할 수 있습니다. 요약하면, 모니터링 솔루션 도입으로 인한 인프라 비용(EC2, EBS, 트래픽 등)과 AWS API 비용을 모니터링하면서, 효용에 맞게 규모를 조절하는 것이 필요합니다.
확장성과 유지보수
처음에는 작은 규모로 시작하더라도, 추후 모니터링 대상이 늘고 데이터량이 증가하면 시스템을 확장해야 합니다. Prometheus 단일 인스턴스는 일정 수준의 QPS와 시계열 수를 버틸 수 있지만, 그 한계를 넘어서면 수평 확장이 필요합니다. 이를 위해 CNCF Sandbox 프로젝트인 Thanos나 Grafana Labs의 Mimir 등을 도입하여 Prometheus 데이터를 장기 저장하고 여러 Prometheus 인스턴스를 통합 조회하는 아키텍처로 발전시킬 수 있습니다. 또는 AWS Amp 같은 관리형 서비스를 도입하여 거의 무제한에 가까운 확장성을 확보하는 방법도 있습니다. Grafana도 사용자 대시보드 증가와 동시에 메모리 사용량이 늘 수 있으므로, 필요하면 인스턴스 스펙을 올리거나 Grafana를 HA 구성을 고려해야 합니다 (세션 스토리지 공유 등을 통해 다중 서버 운용). 업그레이드와 플러그인 관리도 유지보수의 일부인데, 정기적으로 Prometheus와 Grafana의 버전을 업데이트하여 최신 보안 패치와 기능을 반영해야 합니다. 특히 Grafana 플러그인을 사용하는 경우 호환성 이슈를 사전에 테스트하고 업그레이드해야 합니다. 마지막으로, 모니터링 시스템 자체에 대한 모니터링도 간과하지 말아야 합니다. 예를 들어 Prometheus의 스토리지 잔여 공간이나 Grafana 서버의 CPU 사용률 등을 점검하고 경고를 설정해두면 모니터링 시스템이 중단되는 상황을 예방할 수 있습니다.
알림 설정 및 자동화
모니터링의 가치 중 하나는 이상 징후에 대한 선제적 알림입니다. Prometheus를 구축했다면 Alertmanager를 함께 설정하여 중요한 지표 임계치 도달 시 자동으로 경보를 보내도록 해야 합니다. 예를 들어, CPU 사용률이 일정 시간 90%를 초과하거나, HTTP 5xx 에러율이 급증하면 Alertmanager가 미리 등록된 수신자(슬랙 채널, 이메일, PagerDuty 등)에게 통지하게 할 수 있습니다. Grafana 역시 8.x 버전 이후부터 統합 Alerting 기능을 제공하여, 대시보드 패널의 임계치 기반 알람을 정의하고 수신 채널을 지정할 수 있습니다. 단, 두 시스템의 알림을 중복으로 운영하면 혼란이 있을 수 있으니, 조직 내 표준을 정해 어느 쪽에서 알람을 관리할지 결정하는 것이 좋습니다. 일반적으로 애플리케이션/인프라 지표는 Prometheus+Alertmanager로, 비즈니스 지표나 UX 지표는 Grafana Alert로 관리하는 등 역할을 구분하기도 합니다.
또한 자동화 측면에서는, 인프라 코드(IaC)를 활용해 모니터링 스택 배포를 코드화할 것을 권장합니다. 예를 들어 Terraform 모듈을 사용하여 Prometheus와 Grafana 설정을 관리하거나, Kubernetes 환경이라면 Helm 차트(예: kube-prometheus-stack)를 사용해 모니터링 네임스페이스를 통째로 배포/업데이트할 수 있습니다. 이를 통해 환경 간 설정 불일치를 줄이고 신속한 재구성을 할 수 있습니다. 마지막으로, 모니터링 지표를 기반으로 한 자동 조치(Auto Scaling)도 고려해볼 수 있습니다. AWS의 오토스케일링 그룹이나 Kubernetes HPA와 연계하여, 수집된 메트릭으로 트리거하여 인스턴스 증설 또는 축소를 자동화하면 자율적인 인프라 운영에 한 걸음 다가갈 수 있습니다.
참고
Prometheus
- https://prometheus.io/
- https://prometheus.io/docs/introduction/first_steps/
- https://prometheus.io/docs/prometheus/latest/configuration/configuration/
- https://micrometer.io/docs/registry/prometheus
- https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html#actuator.metrics
Grafana
- https://grafana.com/
- https://grafana.com/docs/grafana/latest/getting-started/getting-started-prometheus/
- https://grafana.com/docs/grafana/latest/datasources/prometheus/
- https://grafana.com/docs/grafana/latest/datasources/cloudwatch/
- https://grafana.com/docs/grafana/latest/alerting/
Exporters
- https://github.com/prometheus/node_exporter
- https://github.com/prometheus/cloudwatch_exporter
- https://github.com/nerdswords/yet-another-cloudwatch-exporter
k6 (Load Testing)
- https://k6.io/
- https://k6.io/docs/
- https://k6.io/docs/results-output/real-time/prometheus-remote-write/
- https://grafana.com/grafana/dashboards/2587
AWS 관련 문서
