
안녕하세요,이번 글에서는 사용자가 늘어남에 따라 발생할 수 있는 잠재적 성능 문제를 예측하고, k6를 이용한 부하 테스트와 데이터베이스 인덱싱을 통해 선제적으로 해결한 경험을 공유하고자 합니다. 이 과정을 통해 1만 건의 데이터 환경에서 API의 95% 응답 시간을 148.67ms에서 31.67ms로 약 4.7배 단축시키는 성과를 거두었습니다.
1. 문제 제기
"성장하는 서비스를 위한 선제적 대응"
저희 서비스 '터닝'은 현재 1,400명의 사용자와 1만 건의 누적 스크랩 데이터를 보유하며 꾸준히 성장하고 있습니다. 특히 사용자가 스크랩한 공고의 마감일을 월별로 보여주는 캘린더 조회 기능은 사용률이 매우 높은 핵심 기능입니다.
저는 현재의 지표에 안주하지 않고, 미래의 상황을 예측해보기로 했습니다.
"만약 앞으로 공격적인 마케팅을 통해 유저가 10배, 100배로 증가하고, 스크랩 데이터가 수십만 건이 된다면 어떻게 될까?"
이 질문에 답하기 위해 코드 리뷰를 진행했고, '캘린더 조회' API가 미래에 심각한 성능 병목을 일으킬 수 있다는 위험 신호를 발견했습니다. 사용자가 캘린더를 넘길 때마다 3~5초씩 기다려야 하는 상황은 서비스의 성장에 치명적인 걸림돌이 될 것입니다. 저는 이러한 미래의 장애를 예방하고, 서비스의 확장성을 확보하기 위해 선제적인 성능 개선을 진행하기로 결정했습니다.
2. 원인 분석
조인(JOIN) 뒤에 숨어있던 'Full Table Scan'
성능 저하가 예상되는 지점은 ScrapServiceImpl의 getMonthlyScraps 메소드에서 호출하는 QueryDSL 쿼리였습니다.
ScrapRepositoryImpl.java
public List<Scrap> findScrapsByUserIdAndDeadlineBetweenOrderByDeadline(Long userId, LocalDate start, LocalDate end){
return jpaQueryFactory
.selectFrom(scrap)
.where(scrap.user.id.eq(userId) // 조건 1
.and(scrap.internshipAnnouncement.deadline.between(start, end))) // 조건 2
.orderBy(scrap.internshipAnnouncement.deadline.asc())
.fetch();
}이 쿼리는 scrap 테이블과 internship_announcement 테이블을 조인(JOIN)하여 결과를 찾습니다. 인덱스가 없던 상태에서 이 쿼리는 다음과 같이 비효율적으로 동작합니다.
- Full Table Scan:
WHERE user_id = ?조건을 만족하는 데이터를 찾기 위해, DB는scrap테이블의 1만 개 데이터를 처음부터 끝까지 모두 읽습니다. - 반복적인 JOIN: 1번에서 찾은 결과 각각에 대해,
internship_announcement테이블로 이동하여deadline이 원하는 기간에 맞는지 다시 확인합니다.
이러한 Full Table Scan 방식은 데이터가 적을 때는 문제가 되지 않지만, 데이터가 많아질수록 "1만 페이지짜리 책에서 특정 단어를 찾기 위해 첫 장부터 넘겨보는 것"과 같아져 성능이 기하급수적으로 저하됩니다.
3. 개선 전략
WHERE절을 기반으로 한 최적의 인덱스 설계
비효율적인 검색을 해결하기 위해, WHERE 절에 사용되는 핵심 컬럼들을 기준으로 "찾아보기(Index)"를 만드는 전략을 세웠습니다.
scrap (user_id)인덱스:WHERE scrap.user.id = ?조건의 성능을 높이기 위해 생성했습니다. 이를 통해 특정 사용자의 스크랩 데이터를 빠르게 찾을 수 있습니다.internship_announcement (deadline)인덱스:WHERE ...deadline.between(...)조건의 성능을 높이기 위해 생성했습니다. 특정 기간 내의 공고를 신속하게 필터링할 수 있습니다.
적용된 인덱스 생성 쿼리:
-- 1. 사용자를 기준으로 스크랩을 빠르게 찾기 위한 인덱스
CREATE INDEX idx_scrap_on_user_id ON scrap (user_id);
-- 2. 마감일을 기준으로 공고를 빠르게 찾기 위한 인덱스
CREATE INDEX idx_announcement_on_deadline ON internship_announcement (deadline);4. 검증 과정
데이터 기반의 성능 측정
'추측'이 아닌 '데이터'로 개선을 증명하기 위해 k6를 이용한 부하 테스트를 설계했습니다.
테스트 데이터 설계의 핵심 원칙은 '실제와 같은 병목 현상 재현'이었습니다. 현재 저희 운영 DB에는 약 1,400명의 사용자와 1,000개 이상의 공고, 그리고 10,000건의 스크랩 데이터가 있습니다.
개선하려는 API 성능에 가장 큰 영향을 미치는 것은 WHERE 절에서 가장 먼저 스캔하는, 그리고 가장 큰 테이블인 scrap 테이블의 전체 크기였습니다. 따라서 테스트의 정확도를 높이기 위해 scrap 데이터는 운영 환경과 동일한 10,000건으로 설정했습니다.
users나 internship_announcement 테이블의 전체 row 수는 특정 user_id로 필터링되는 개별 쿼리의 실행 속도에 미치는 영향이 미미하므로, 테스트 환경의 복잡도를 관리하고 핵심 변수에 집중하기 위해 각각 100명과 500건으로 설정하여 테스트를 진행했습니다.
- 테스트 시나리오: 10명의 동시 접속자(VU)가 30초 동안 지속적으로 "월별 스크랩 조회" API를 호출하는 상황을 시뮬레이션했습니다.
- 측정 방식: 인덱스를 적용하기 전과 적용한 후에 각각 k6 테스트를 실행하여, API의 응답 시간과 처리량을 정량적으로 비교했습니다.
5. 결과
인덱싱, 4.7배의 성능 향상
가설을 증명하기 위해, 인덱스를 적용하기 전과 후에 동일한 조건으로 부하 테스트를 각각 실행했습니다.
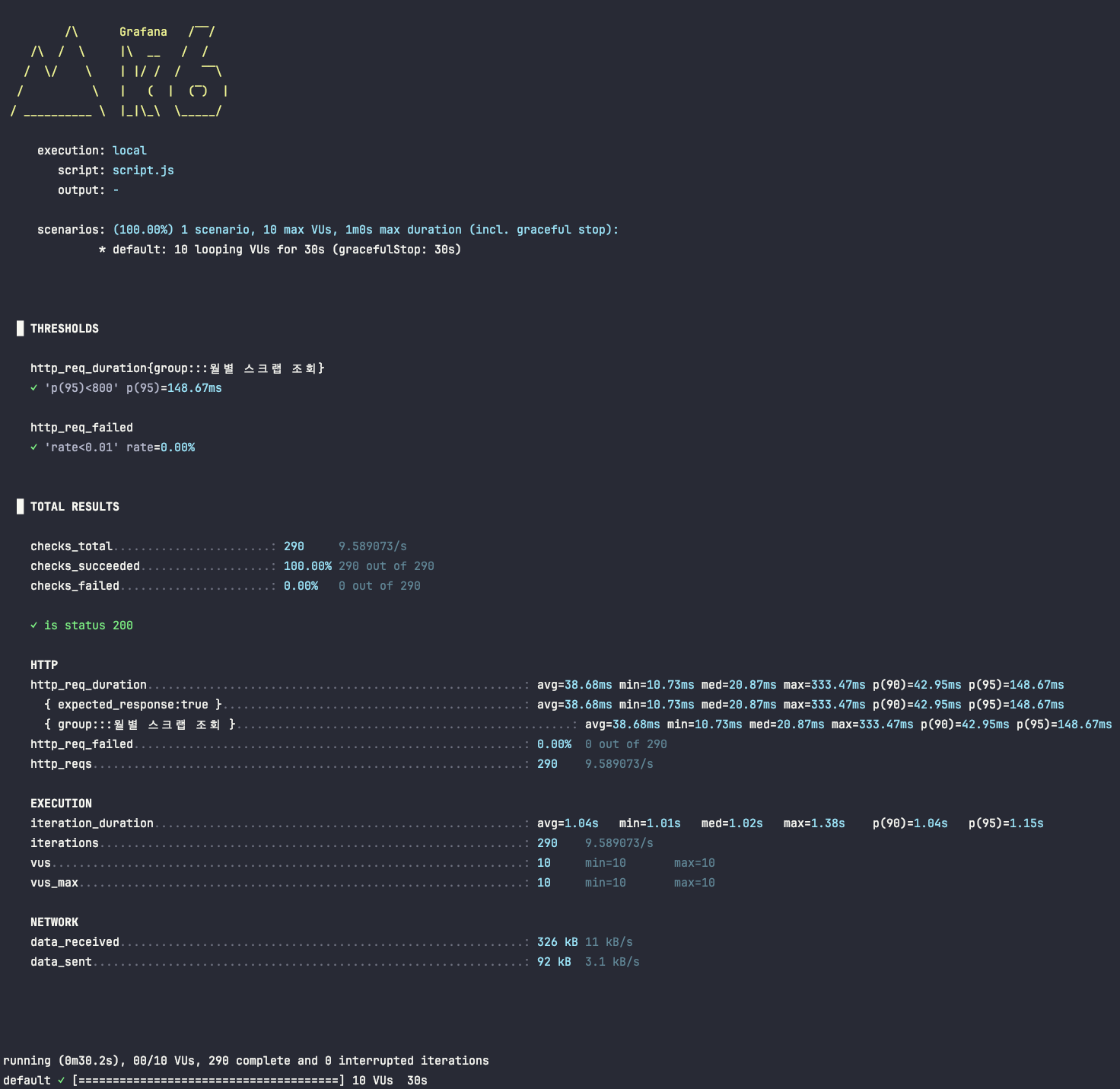
Before: 인덱스가 없는 상태
먼저 인덱스가 없는 상태에서 1만 건의 데이터를 대상으로 테스트를 진행했습니다. p(95) 응답 시간이 148.67ms로 측정되었습니다. 현재 데이터 양으로는 아직 사용성에 문제가 없지만, 데이터가 더 증가할 경우를 대비해야 하는 성능이었습니다.
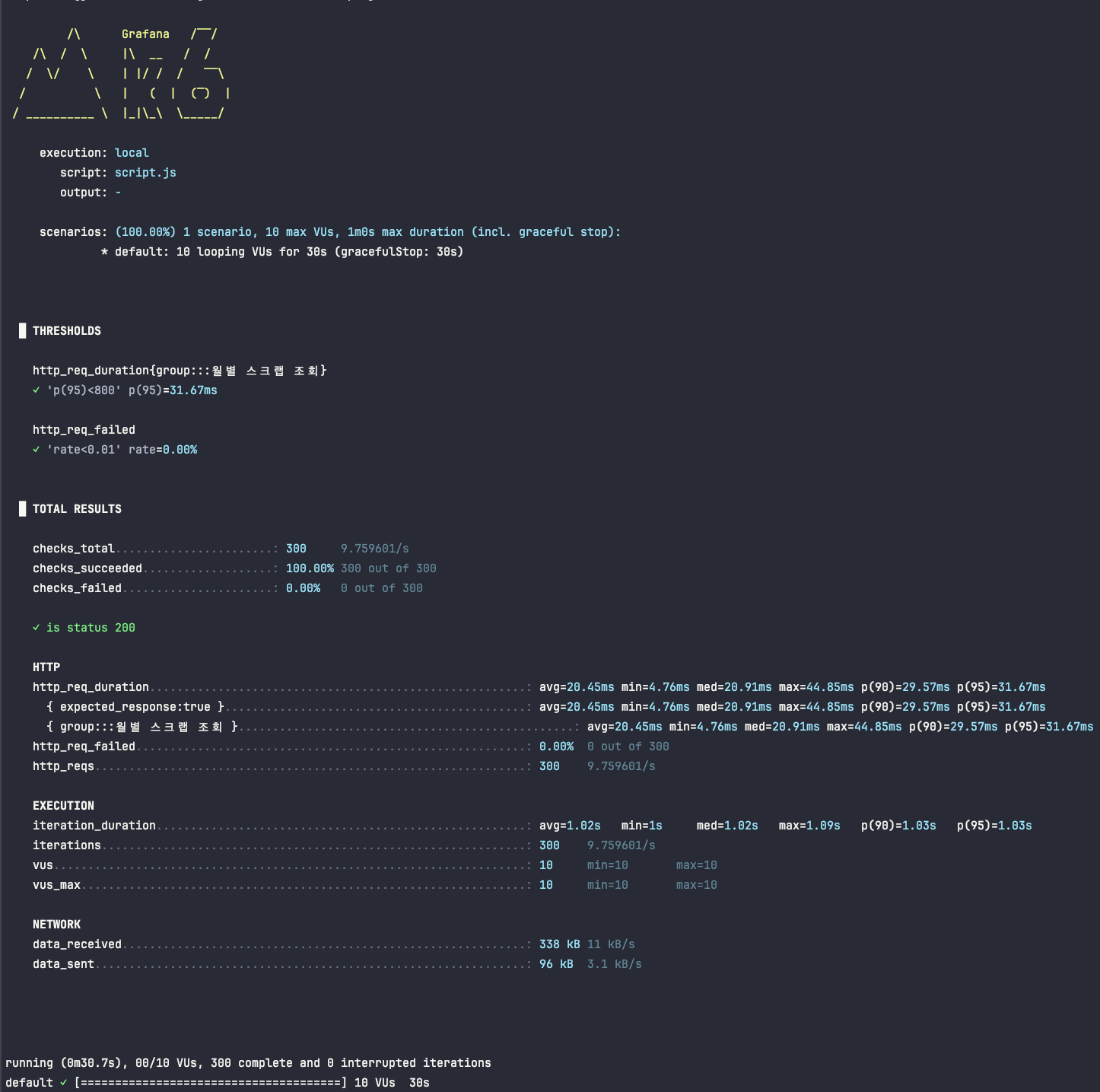
After: 인덱스 적용 후
다음으로 user_id와 deadline 컬럼에 인덱스를 생성한 후, 동일한 테스트를 다시 실행했습니다. p(95) 응답 시간이 31.67ms로 크게 단축된 것을 확인할 수 있었습니다.
결과 비교 분석
두 테스트 결과를 나란히 비교했을 때, 인덱싱의 효과는 명확하게 드러났습니다.
| 지표 (Metric) | 인덱싱 전 (1만 건) | 인덱싱 후 (1만 건) | 개선 효과 |
|---|---|---|---|
응답 시간 p(95) | 148.67 ms | 31.67 ms | 78.7% 단축 (4.7배 개선) |
평균 응답 시간 avg | 38.68 ms | 20.45 ms | 47.1% 단축 (1.9배 개선) |
최대 응답 시간 max | 333.47 ms | 44.85 ms | 86.6% 단축 (7.4배 개선) |
- 응답 속도의 극적인 개선: 인덱스 적용 후, 사용자가 체감하는 실질적인 성능 지표인 p(95) 응답 시간이 148.67ms에서 31.67ms로 4.7배나 빨라졌습니다.
- 서비스 안정성 확보: 무엇보다 중요한 것은, 인덱스가 없을 때 간헐적으로 333.47ms까지 치솟았던 최대 응답 시간이 44.85ms로 크게 감소하며 매우 안정적인 성능을 확보했다는 점입니다. 이는 어떤 사용자도 갑자기 느린 화면을 보지 않게 되었음을 의미합니다.
결과 분석
- 응답 속도의 극적인 개선: 인덱스 적용 후, 사용자가 체감하는 실질적인 성능 지표인 p(95) 응답 시간이 148.67ms에서 31.67ms로 4.7배나 빨라졌습니다.
- 서비스 안정성 확보: 무엇보다 중요한 것은, 인덱스가 없을 때 간헐적으로 333.47ms까지 치솟았던 최대 응답 시간이 44.85ms로 크게 감소하며 매우 안정적인 성능을 확보했다는 점입니다. 이는 어떤 사용자도 갑자기 느린 화면을 보지 않게 되었음을 의미합니다.
6. 회고 및 배운 점
이번 성능 개선 프로젝트는 저에게 몇 가지 중요한 교훈을 남겼습니다.
- 보이지 않는 병목을 예측하는 통찰력: 당장의 지표에 만족하지 않고, 비즈니스의 성장을 고려하여 미래에 발생할 수 있는 기술적 부채와 장애 포인트를 예측하고 선제적으로 대응하는 것이 개발자의 중요한 역량임을 깨달았습니다.
- 데이터 기반의 문제 해결 능력: '느릴 것이다'라는 막연한 추측이 아닌, k6와 같은 도구로 문제를 정량적으로 분석하고, 개선의 효과를 명확한 수치로 증명하는 체계적인 접근법을 체득했습니다.
- 데이터베이스 내부 동작에 대한 깊은 이해: 인덱스의 원리를 이해하고
WHERE절과JOIN의 관계를 고려하여 최적의 인덱스를 설계하는 과정에서 데이터베이스에 대한 깊은 이해를 갖게 되었습니다.
긴 글 읽어주셔서 감사합니다.
