Project 02. Analysis Seoul Crime
EDA - 프로젝트 개요 (이론)
데이터 과학의 목적?
- 가정(혹은 ‘인식’)을 검증하고 표현하는 것
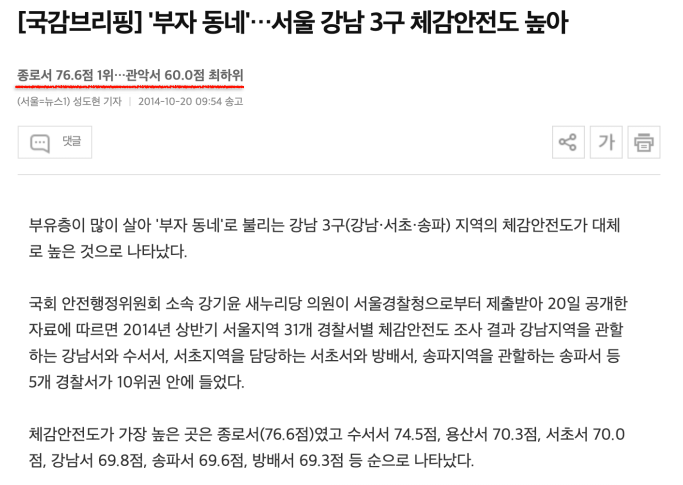
목표
- 위 기사의 인식과 가정을 확인해보는 도구로 활용
- GoogleMaps, Folium, Seaborn, Pandas의 Pivot_table 의 사용법 숙달
데이터 얻기
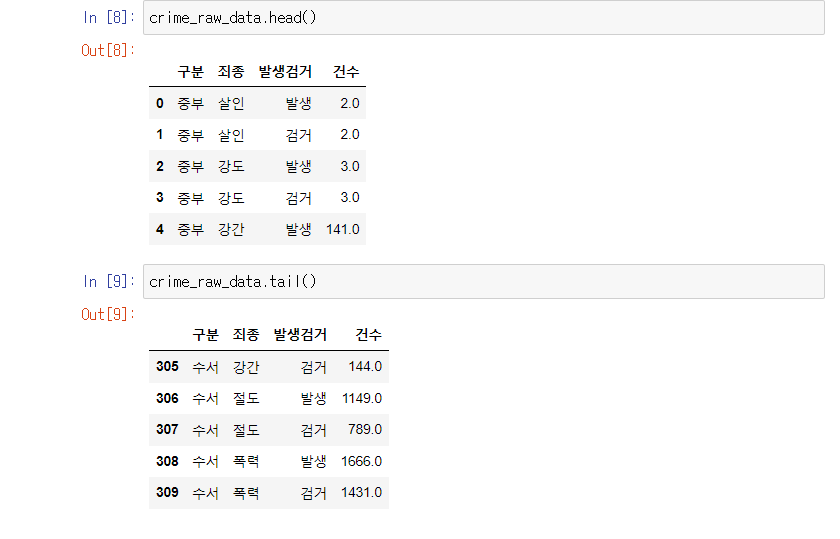
구글 검색
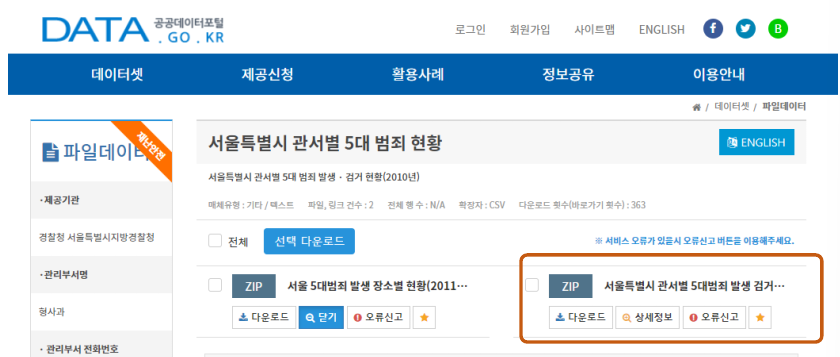
5대 범죄 발생 검거 관련 데이터 다운로드
EDA - 데이터 개요
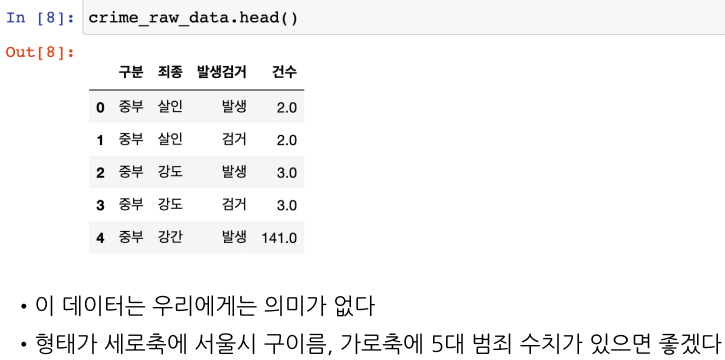
데이터 확인하고 초기 정리하기

데이터 불러오고 변수에 할당하기
read_csv() 함수 사용
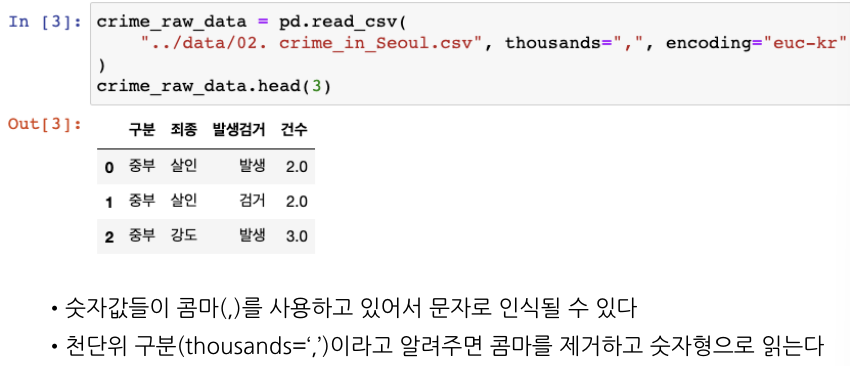
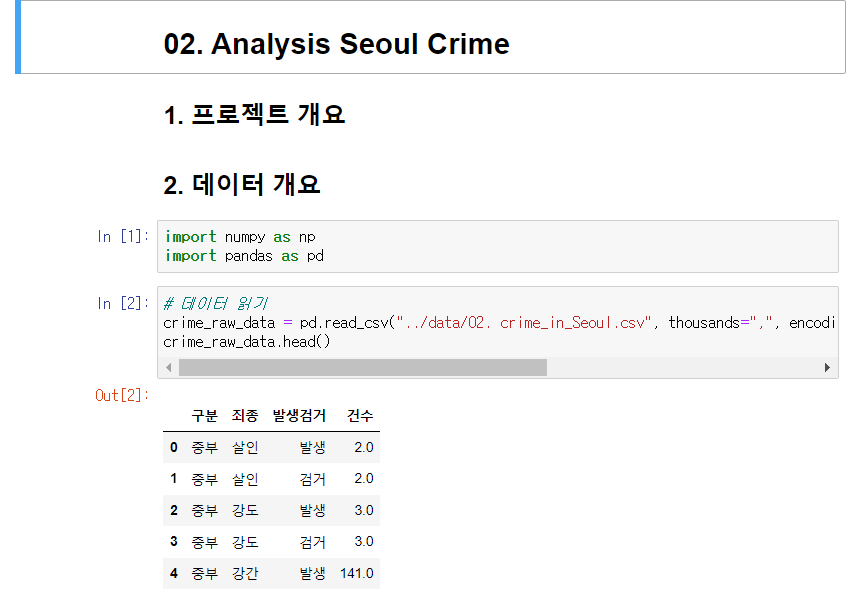
불러온 데이터 정보 확인
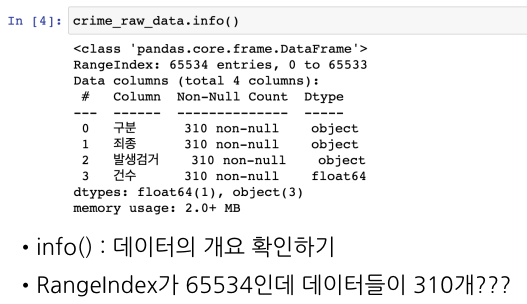
-> 인덱스 범위와 데이터의 수가 이상한 것을 확인
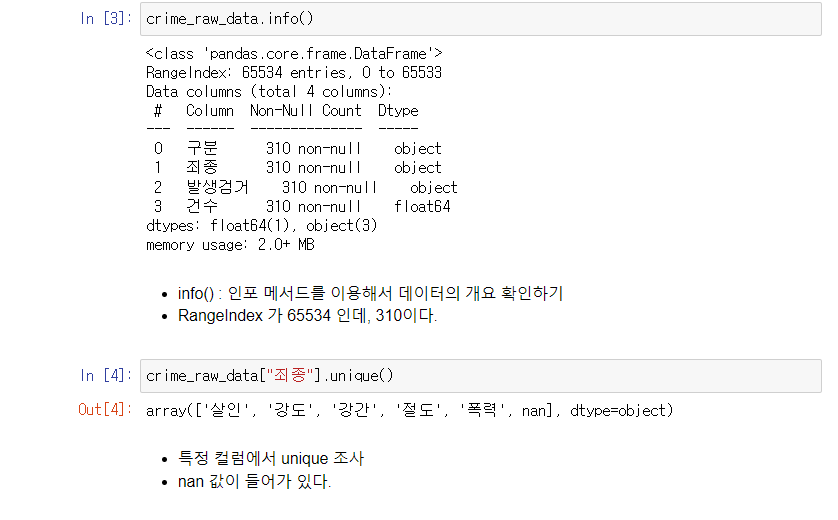
unique() 매서드로 데이터 종류 확인

-> 5대 범죄 이외에 non 데이터가 들어가 있음을 알 수 있다.
-> non 데이터가 문제인 것을 유추할 수 있다.
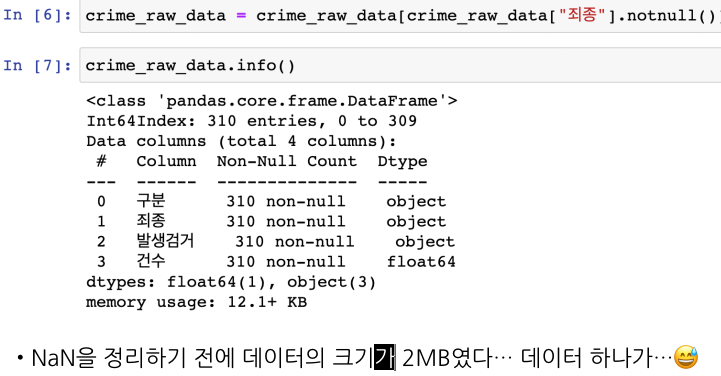
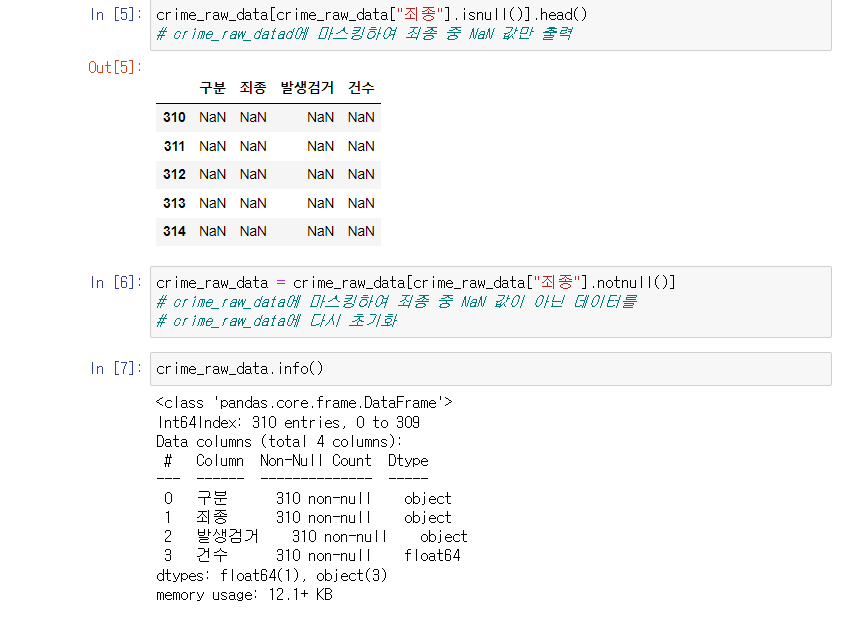
죄종 컬럼에서 non 데이터만 가져오기


NoN 데이터 제외하고 데이터 가져와서 변수로 초기화
EDA - 프로젝트 개요 (실습)
데이터 불러오기
info()매서드와 unique()매서드 이용하여 데이터의 정보 확인
마스킹하여 원하는 데이터 추출 후 확인
EDA - Pandas pivot_table (이론)
Pandas Pivot Table
- DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
- values : 집계할 데이터프레임의 열 이름
- index : 행 인덱스로 사용할 열 이름
- columns : 열 인덱스로 사용할 열 이름
- aggfunc : 집계 함수 (기본값: 'mean')
- fill_value : 결측값 대체 값
- margins : 행/열별 총합/평균 등의 요약 통계량을 추가할지 여부 (기본값: False)
- dropna : 결측값이 있는 행/열을 제외할지 여부 (기본값: True)
- margins_name : margins가 True인 경우 추가될 행/열의 이름 (기본값: 'All')
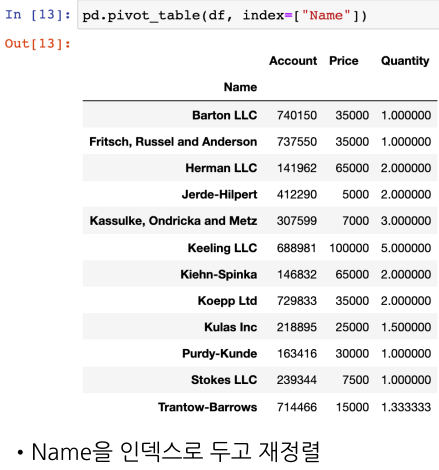
판매현황표로 Pivot Table 활용 연습

Name 컬럼을 인덱스로하여 정렬
- pivot_table(데이터프레임, index=컬럼)
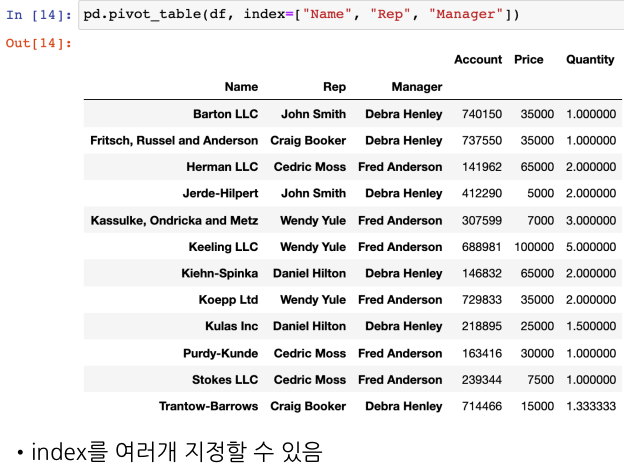
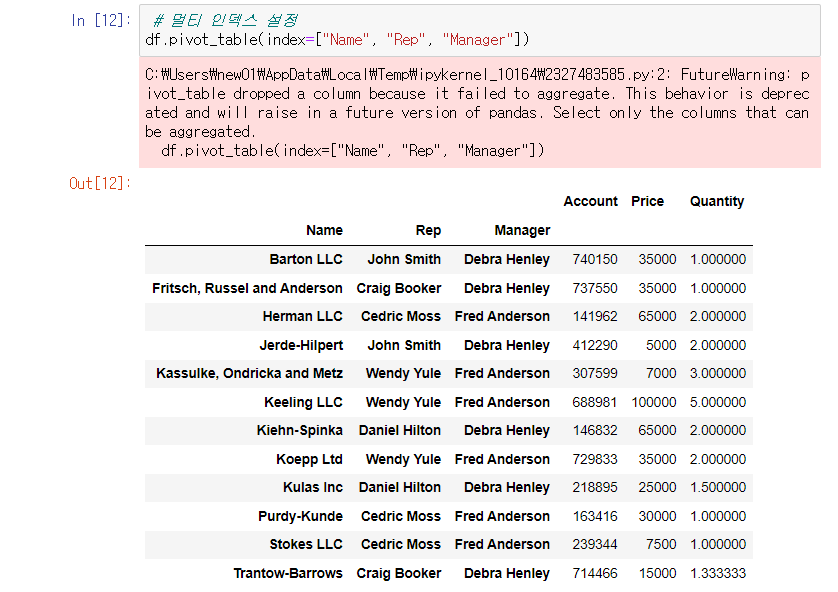
- 다수의 컬럼을 인덱스로 지정할 수 있다.
- values값을 정할 수 있다.
- aggfunc옵션으로 values값에 함수를 적용할 수 있다. 디폴트 값은 평균이다.
- aggfunc옵션은 다수 지정할 수 있다.
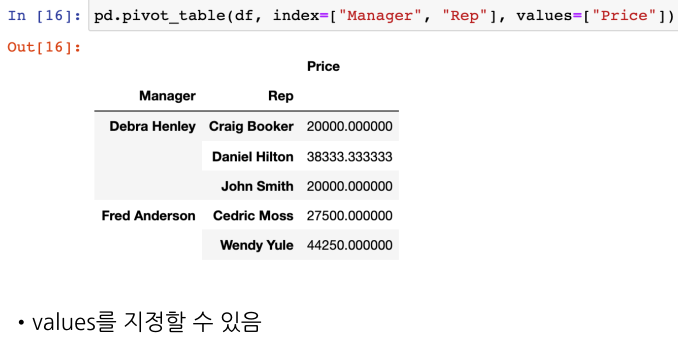
데이터 합산 값으로 출력

데이터값 평균 및 갯수 출력

구하려는 데이터의 분류(columns)를 지정
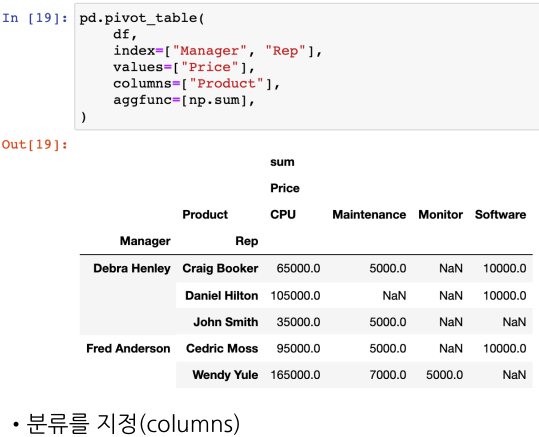
-> 데이터 중 NaN값이 확인된다.
NaN값을 0으로 처리하도록 지정
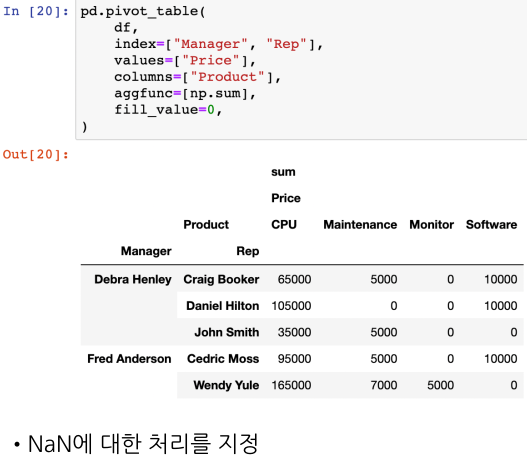
원하는 방식으로 데이터 정렬
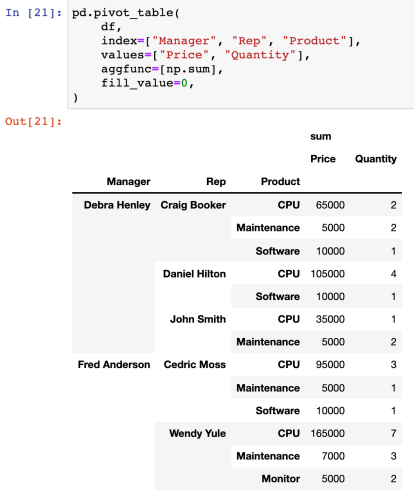
마지막 줄에 각 컬럼 합계 인덱스 추가

EDA - Pandas pivot_table (실습)
- index
- values - aggfunc
- columns
데이터 불러오기
데이터 프레임 생성
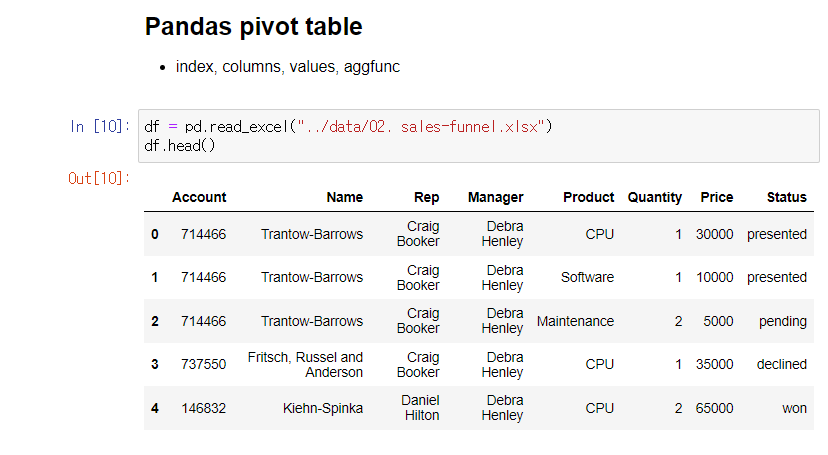
index 설정
컬럼 중 Name을 인덱스로 설정

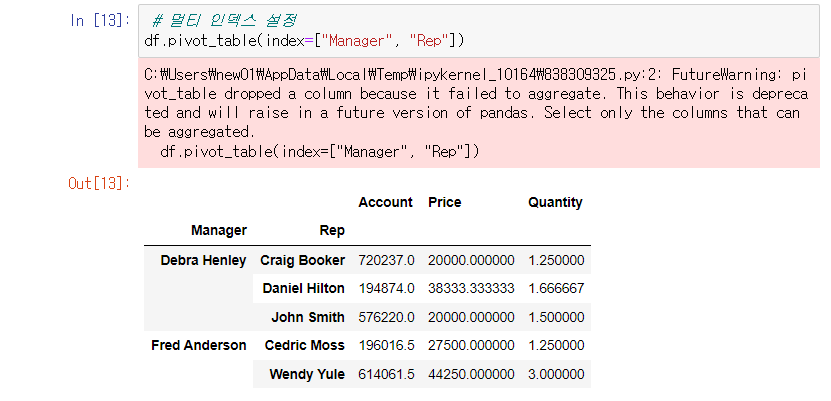
다수의 인덱스 설정
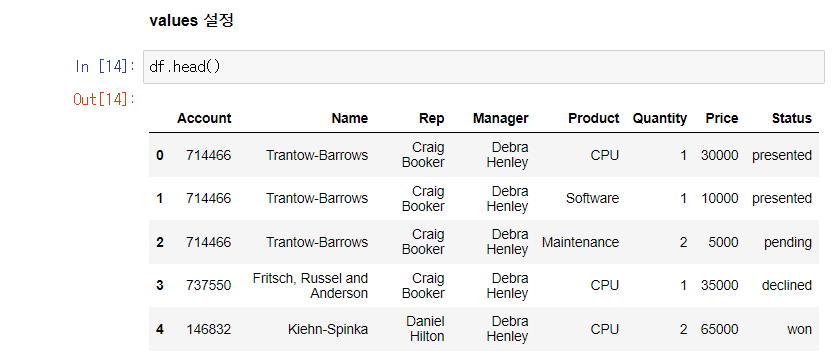
values 설정
- values 은 디폴트값으로 평균 값이 표기된다.
데이터 확인
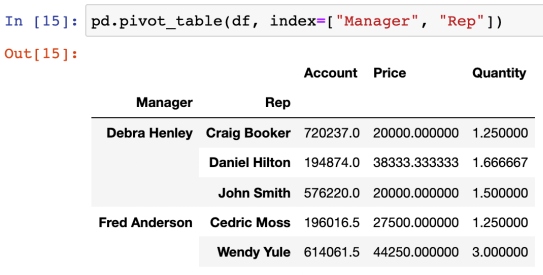
다수의 index에 대한 values 설정
values 은 기본적으로 평균 값으로 표기된다.
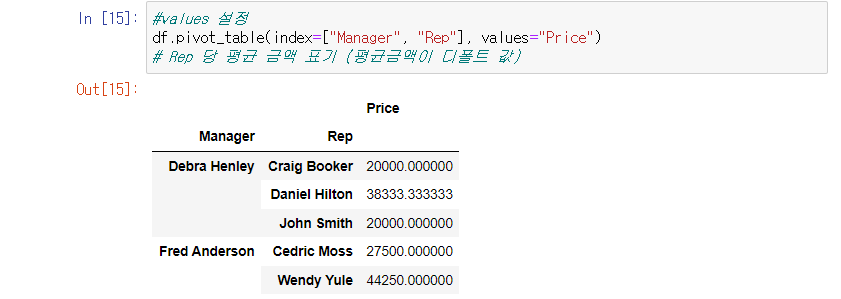
values 의 합으로 표기
기능 aggfunc=np.sum 사용
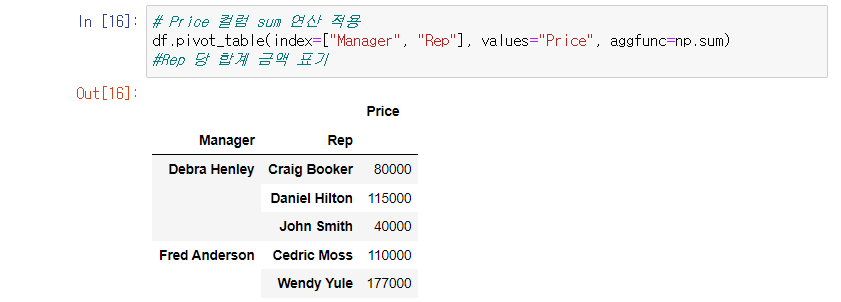
다수의 기능 사용 aggfunc=np.sum, len
Price에 대한 sum 값과 len 값이 각각 표기된다.
columns 설정
데이터 확인
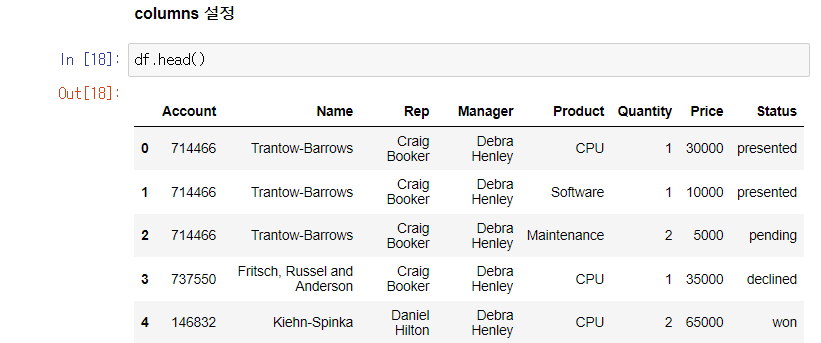
columns 지정하기
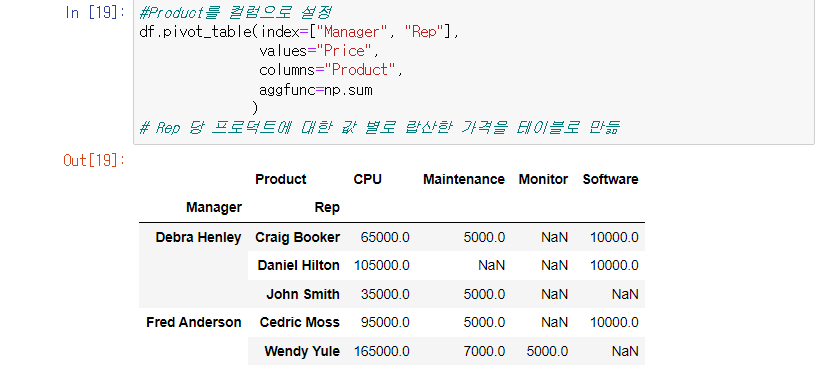
-> 데이터 중에 NaN값이 발생
-> 해당하는 곳에 입력한 값이 없기 때문이다.
NaN 데이터에 값 주기
fill_value=0 키워드로 NaN에 0을 초기화
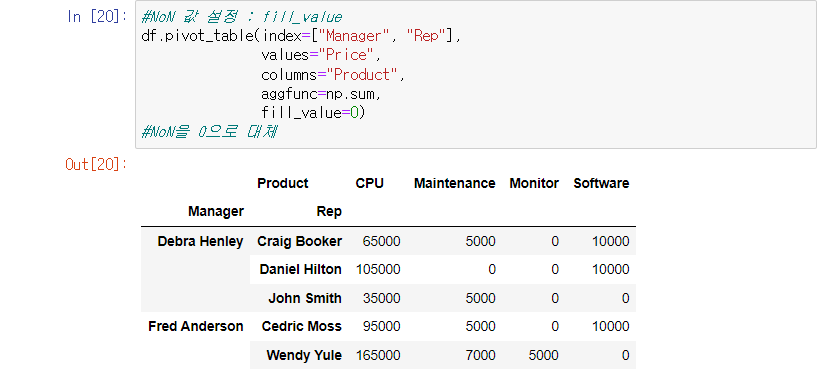
의미 있는 데이터 정리
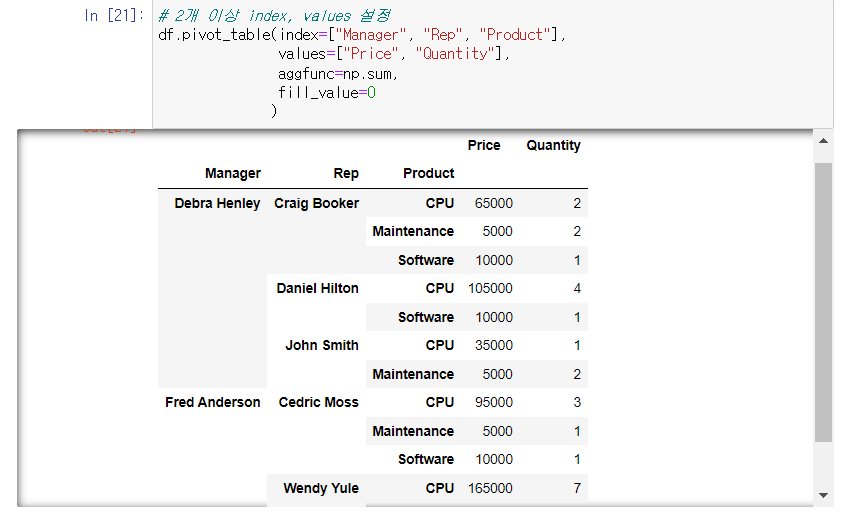
2개 이상 index, values 설정
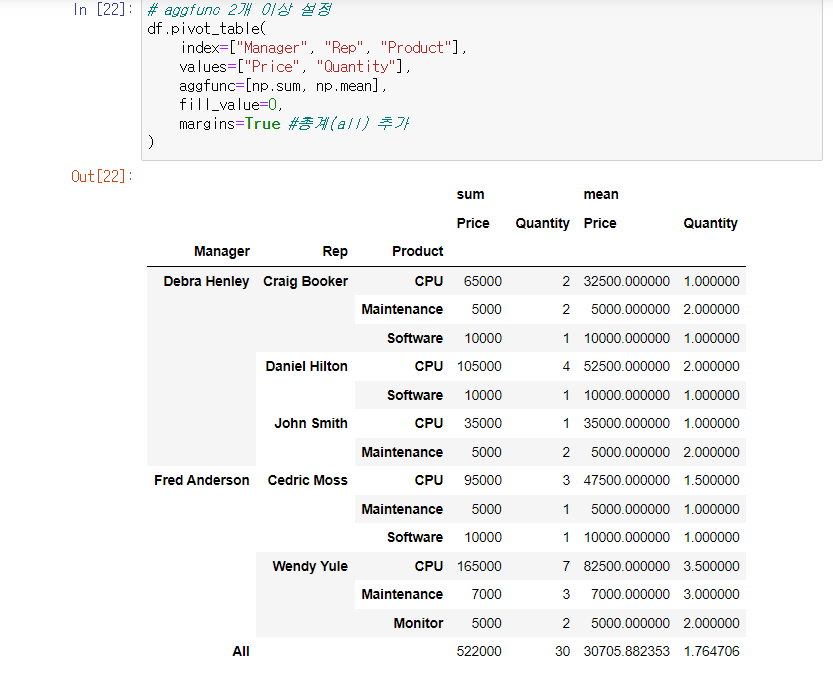
aggfunc 2개 이상 설정
margins=True은 총계를 추가하는 키워드
EDA - 서울시 범죄 현황 데이터 정리 (이론)
Pandas Pivot Table 적용
원본 데이터
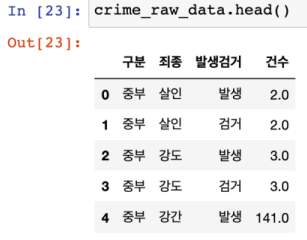
pivot_table을 적용한 원본 데이터를 매서드
pivot_table을 적용한 원본 데이터를 변수에 초기화 (crime_station)

원하는 데이터 프레임 형태로 출력
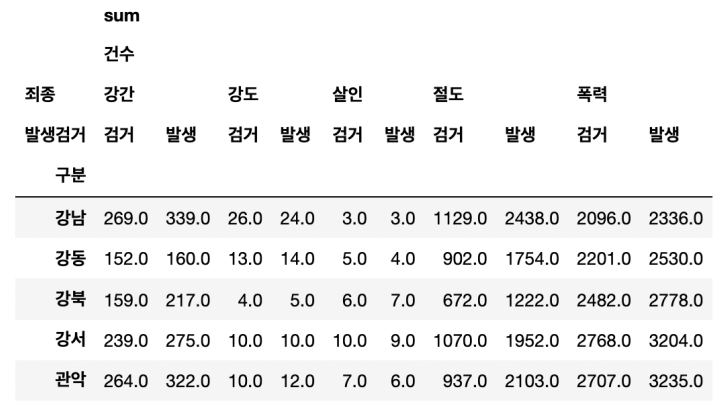
-> 이때 컬럼이 여러 행으로 되어 있다.
여러행의 컬럼 정리

-> 컬럼의 인덱스(0=sum, 1=건수, 2=강도, 3=검거)를 확인할 수 있다.

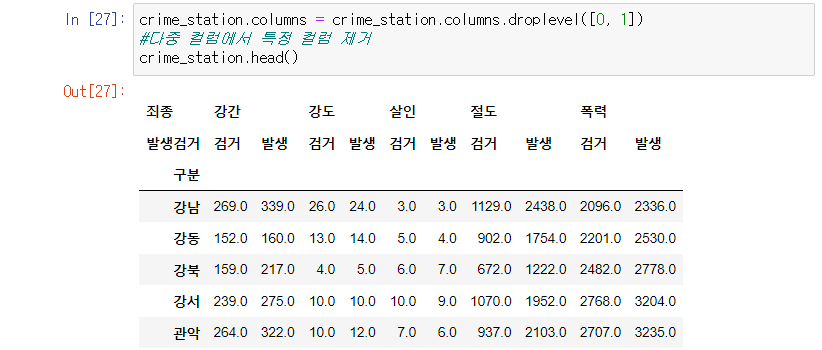
특정 컬럼 제거
- sum과 건수는 필요한 정보가 아니다.
- droplevel() 함수를 이용하여 컬럼의 특정 행 제거


정리된 데이터프레임의 인덱스를 확인

-> 경찰서 이름 인덱스의 데이터 프레임이 필요
EDA - 서울시 범죄 현황 데이터 정리 (실습)
데이터 확인
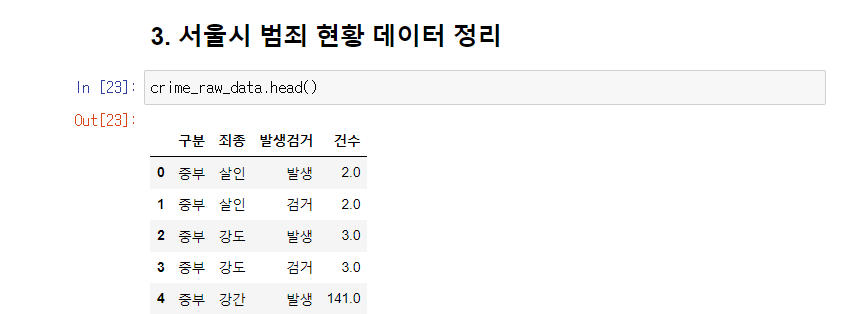
데이터 불러오기
데이터 프레임 초기화

데이터 프레임 가공
컬럼 확인
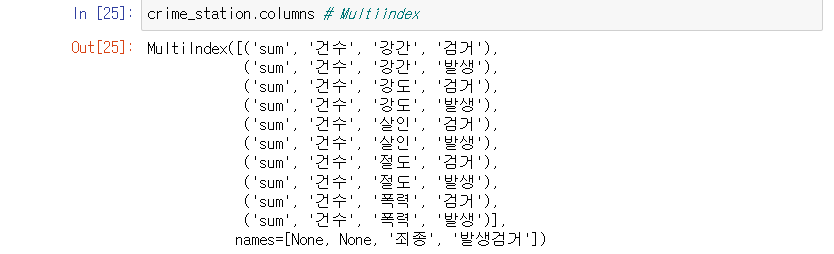

-> 컬럼의 인덱스가 0~4 인것을 알 수 있다.
특정 컬럼 제거
droplevel([]) 매서드로 원하는 컬럼 제거
정리 후 알 수 있는 사실


EDA - Python 모듈 설치 (이론)
- 파이썬 언어는 사용할 모듈을 직접 설치해야한다.
- anaconda는 많은 모듈을 포함하기에 따로 설치하지 않아도 된다.
- 그럼에도 모듈을 설치하는 방법을 알아야한다.
pip 명령

conda 명령


EDA - Python 모듈 설치 (실습)


EDA - Google Maps API 설치 (이론)
Python 모듈 설치

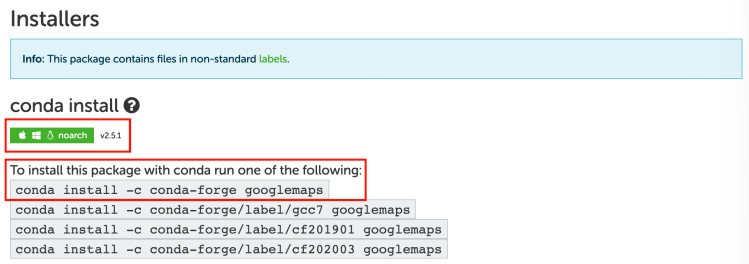
Google Map API
구글맵 활용

Google Map API Key 발급
구글 클라우드 결제 계정 만들기


Key 발급
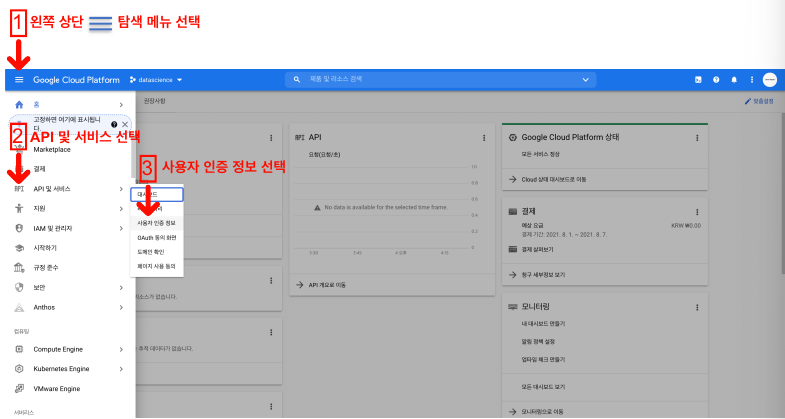
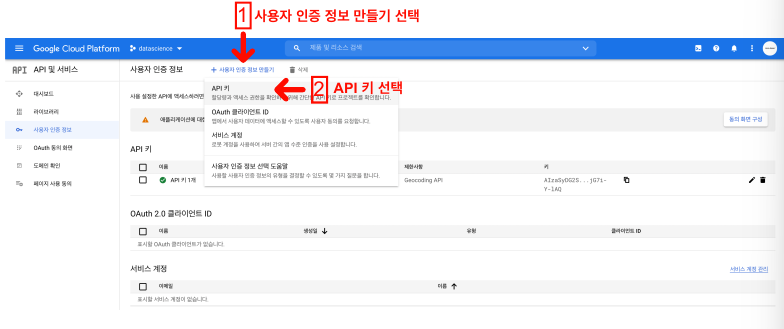
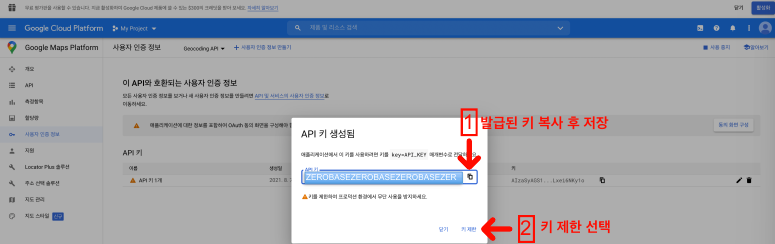
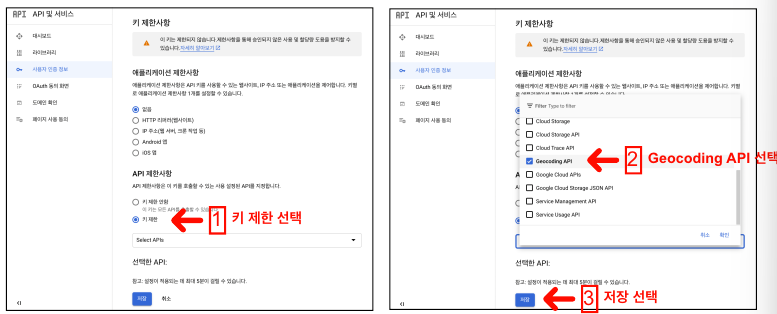
Google Map을 이용해서 주소와 위치 정보 얻기
구글맵 설치
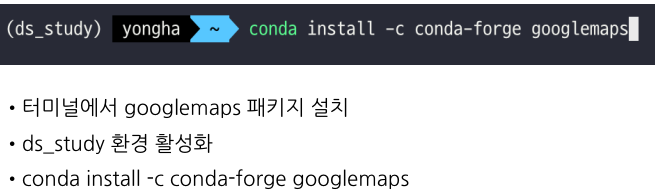
EDA - Google Maps API 설치 (실습)

구글맵 사용하기
- 구글맵에서 서울영등포경찰서에 대한 위치정보를 코드로 볼 수 있다.
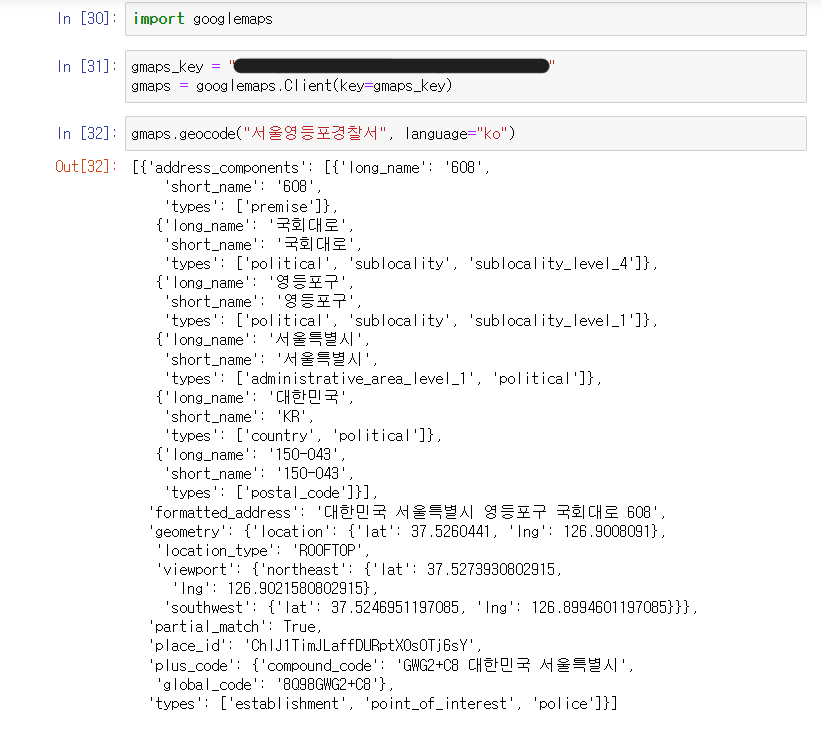
EDA - Python의 반복문(이론)
For - loop
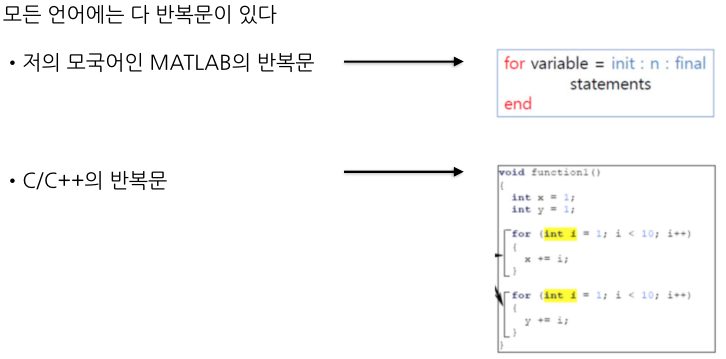
Python의 반복문은?


예제
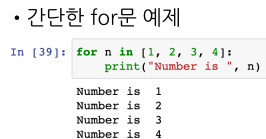


iterrows()

EDA - Python의 반복문(실습)
예시
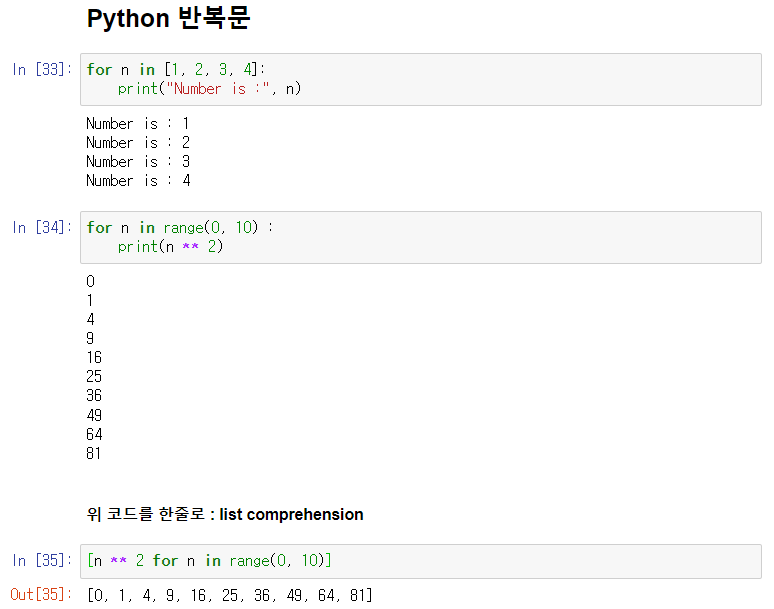
Pandas 에 잘 맞춰진 반복문용 명령 : iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴 떄 for문을 사용하면, n 번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들 때 iterrows() 옵션을 사용하면 편함
- 받을 때, 인덱스와 내용으로 나누어 받는 것만 주의할 것.
EDA - Google Maps를 이용한 데이터 정리(이론)
Google Map을 이용해서 주소와 위치 정보 얻기
데이터 확인
- 리스트형안에 dict형으로 이워진 것을 확인할 수 있다.
- 딕셔너리형에서 데이터 얻을 때는 get 사용한다.
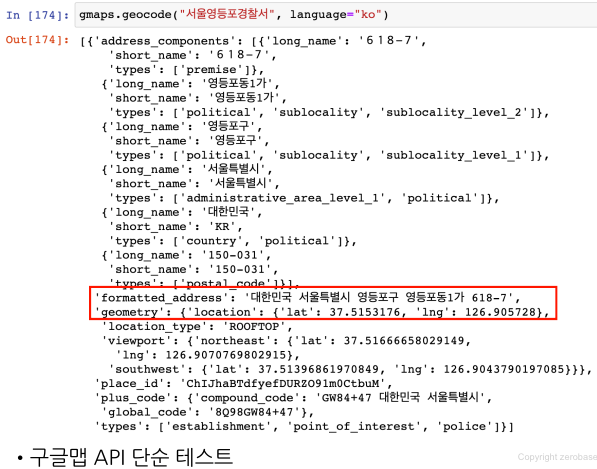
특정 데이터 값 확인
- 위도 값 데이터 찾기
- 경도 값 데이터 찾기
- 주소 값 데이터 찾기

-> 주소 값 중 '구'의 데이터만 필요하다
문자열 분리
- split() 매서드

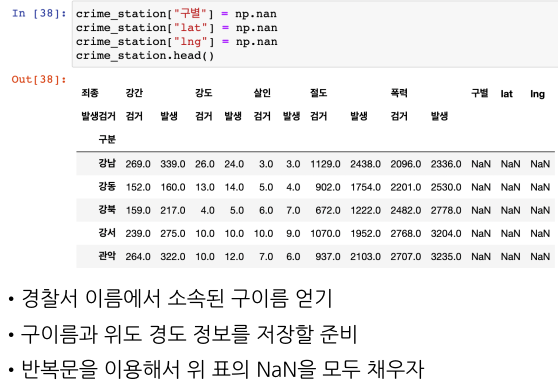
구, 위도, 경도 컬럼에 추가
- 기존 데이터 프레임에 없다면 신규로 추가한다.
for - iterrows() 사용하여 데이터 추가
- iterrows() 함수는 Pandas DataFrame 객체에서 각 행의 인덱스와 해당 행의 데이터를 Series 형태로 반환하는 함수이다.
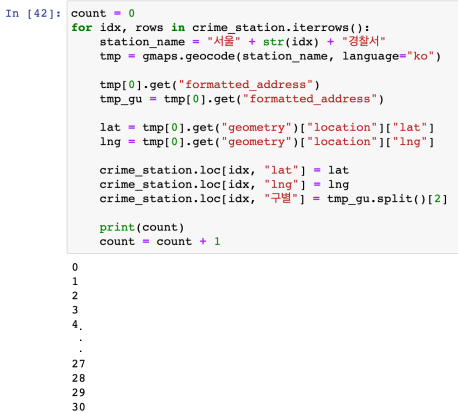
인덱스를 받아 특정 구의 경찰서 이름을 변수에 초기화

구 경찰서 이름으로 주소를 초기화

구 경찰서 이름으로 위도와 경도초기화 및 모든 데이터 값 non 초기화
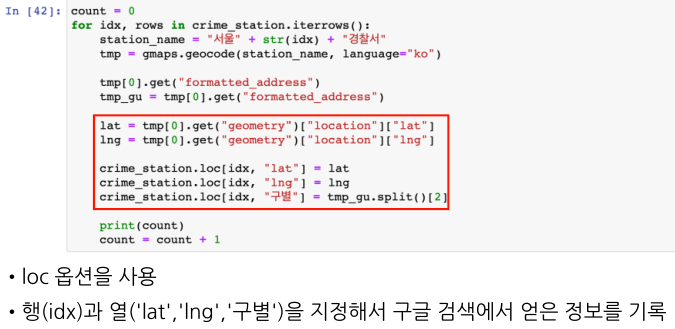
결과
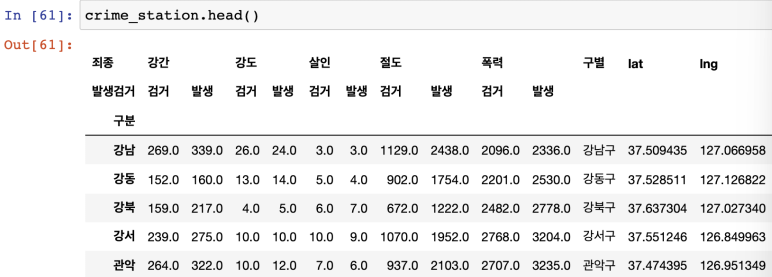
컬럼 합치기 for문
- 여러 레벨의 컬럼을 서로 합친다.
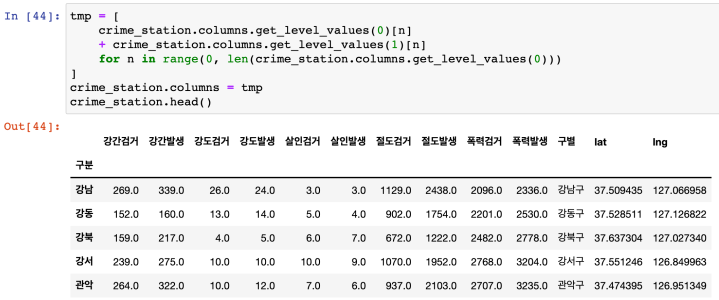
저장

Google Maps를 이용한 데이터 정리(실습)
구글 맵을 이용한 좌표 얻기
키값을 입력하여 데이터 불러오기
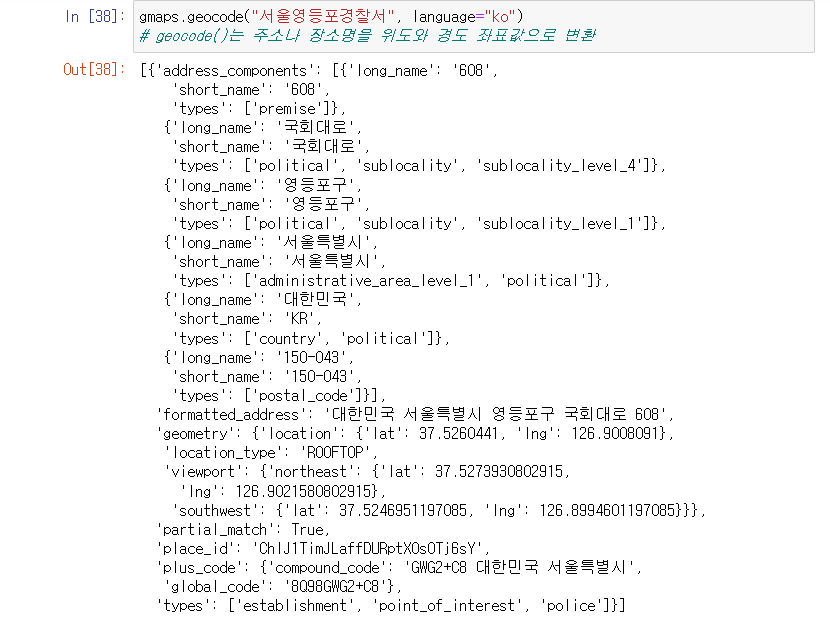
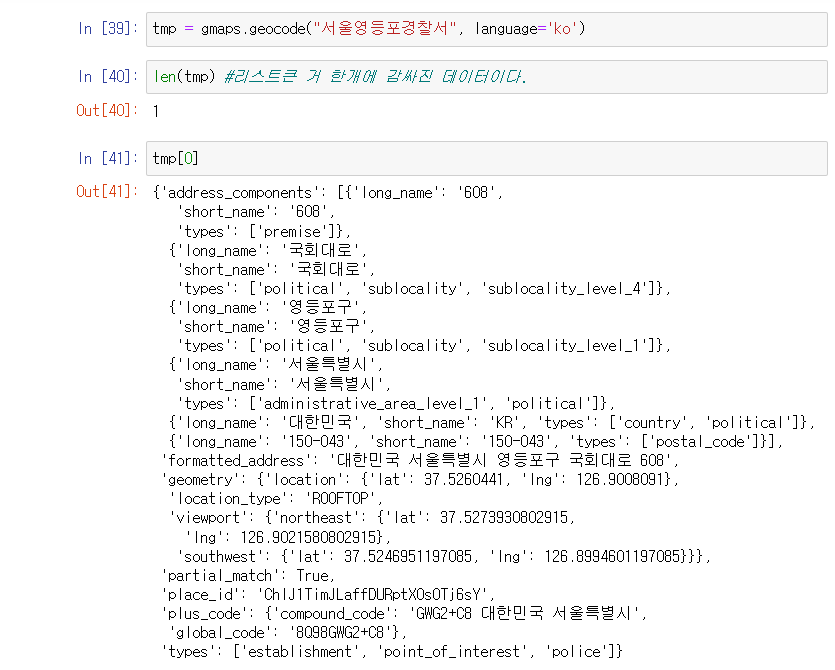
서울 영등포 경찰서 정보 조회
- 각종 많은 정보 중 위도, 경도, 주소 데이터 조회해본다.
- 주소에서 '구'만 조회해본다.

원본 데이터 가공
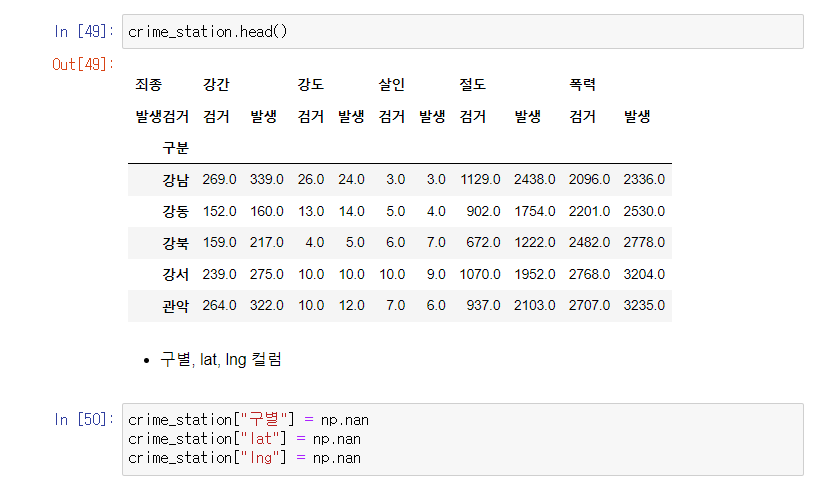
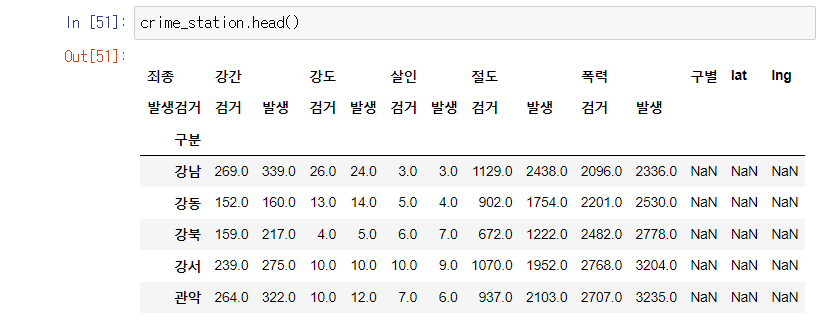
경찰서의 구, 위도, 경도 컬럼 추가 준비
iterrow() 를 이용하여 NaN 데이터 채우기
- 코드 진행이 잘 작동되는지 가시적으로 확인을 위한 count +1 문장


컬럼 레벨 합치기

컬럼 레벨 당 데이터 조회
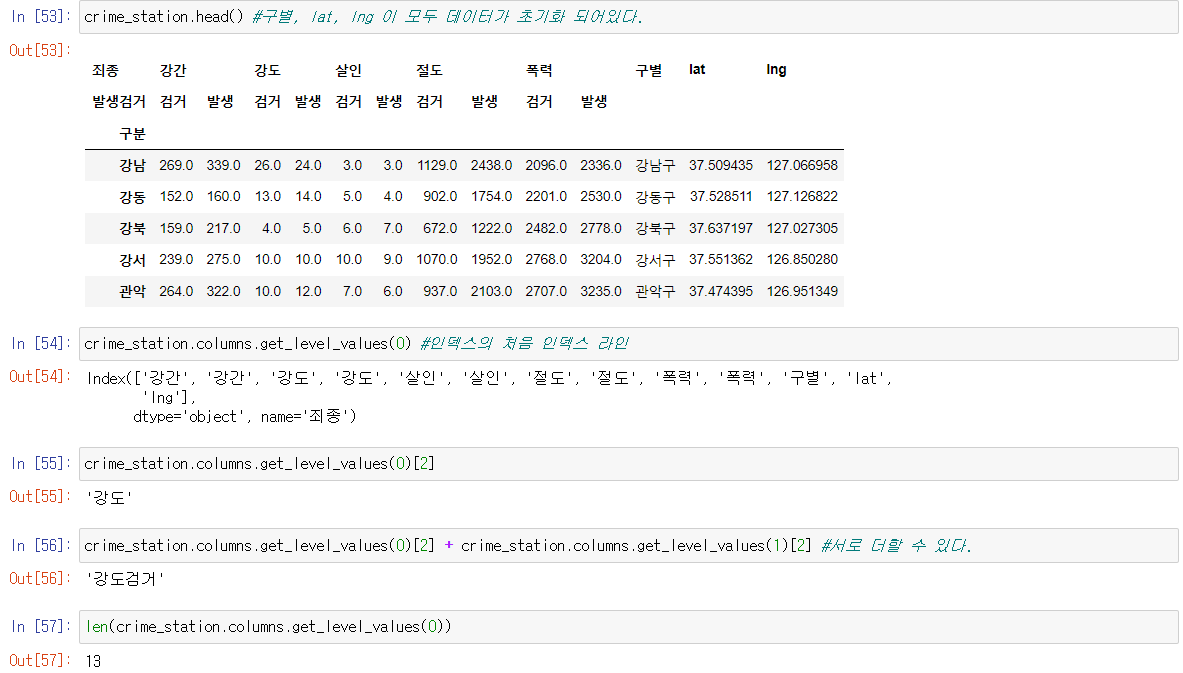
컬럼 레벨 합치기
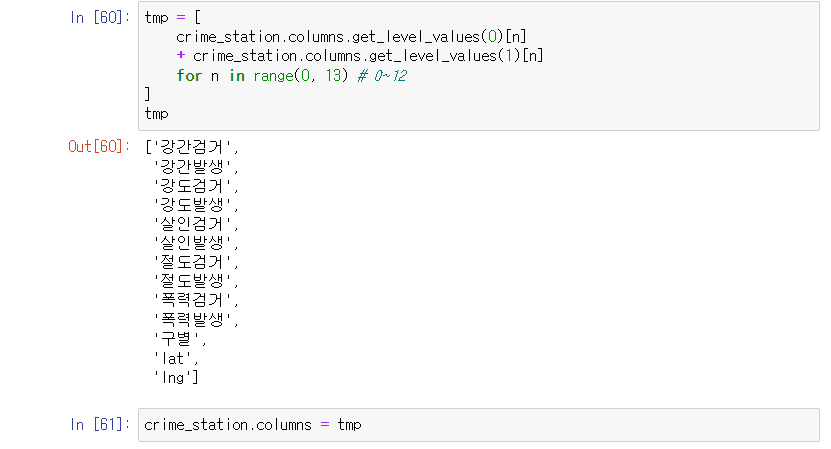
결과

저장 및 조회

EDA - 구별 데이터로 정리(이론)
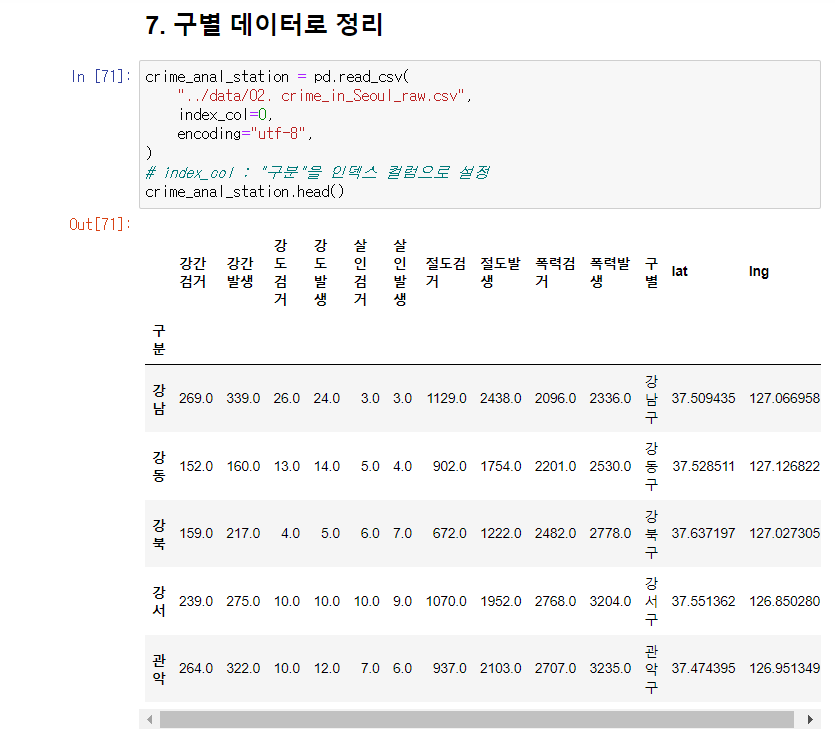
구별 데이터 생성
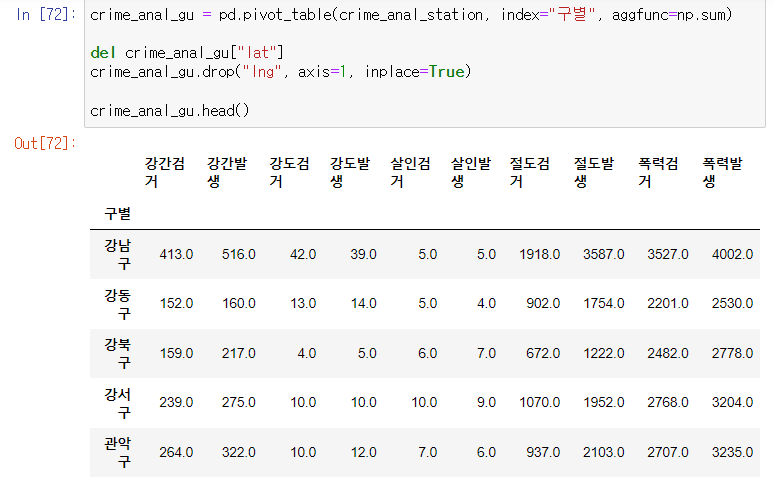
구별 데이터 얻기(pivot_table)


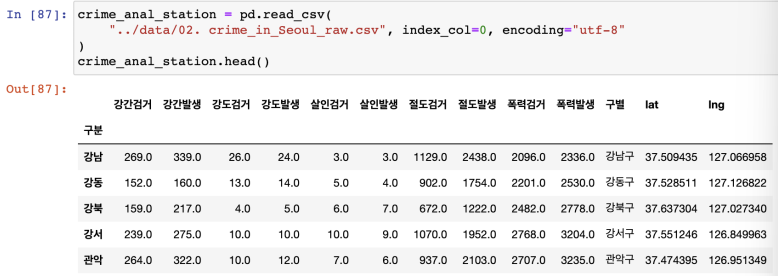
필요한 데이터로 가공

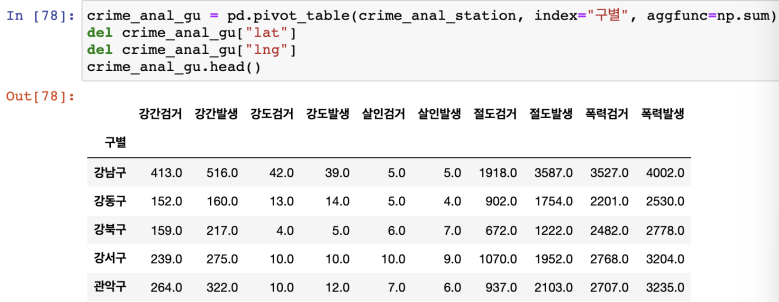
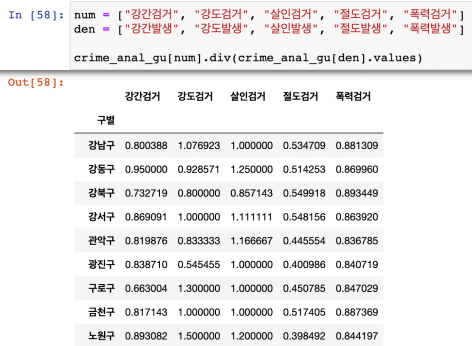
div() 활용하여 데이터프레임 생성
조회

div 활용
강도검거/강도발생, 살인검거/강도발생 데이터프레임 생성

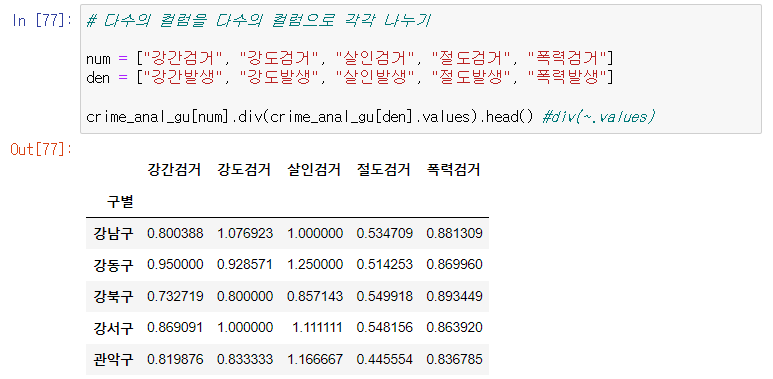
다수의 컬럼 / 다수의 컬럼

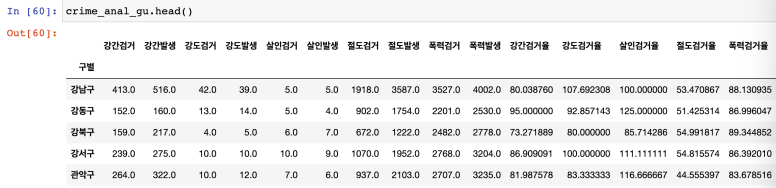
데이터 가공
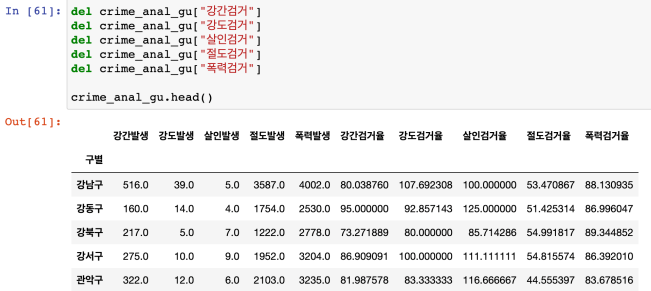
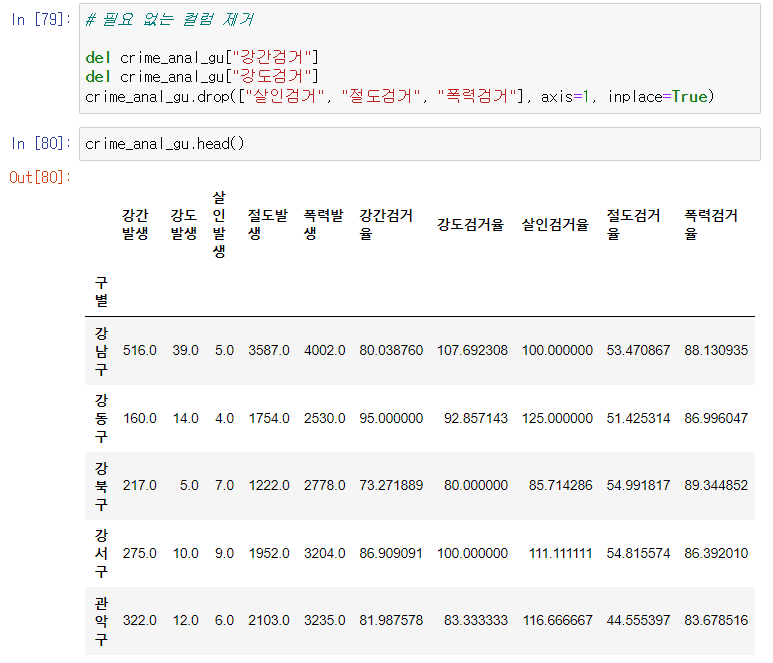
필요없는 데이터 삭제
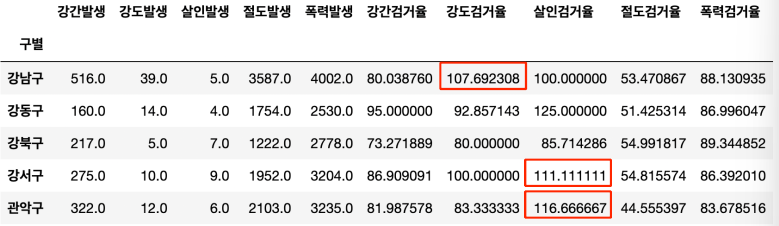
100퍼센트 초과 데이터 변경

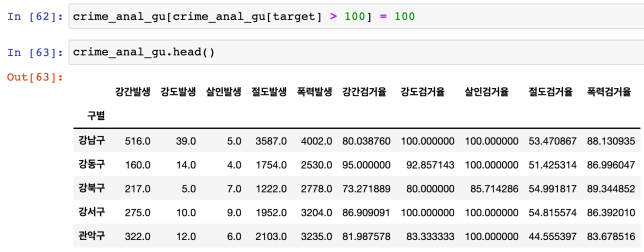
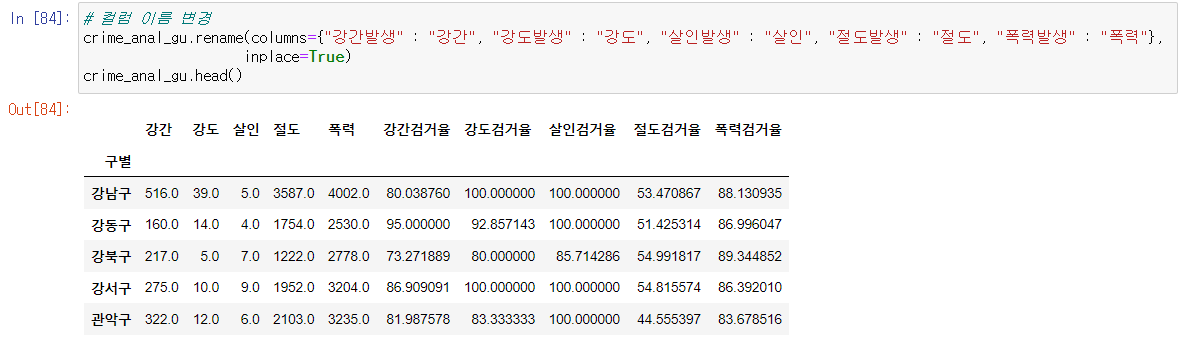
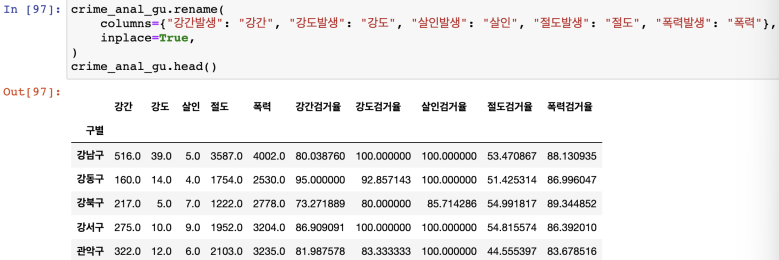
컬럼이름변경
- rename(columns={},inplace=True)
EDA - 구별 데이터로 정리(실습)
데이터 가공
pibot_table 이용하여 가공
- 구별을 인덱스로 변경
- 데이터 값 합산으로 변경
- 경도 및 위도 삭제( drop() 및 del )
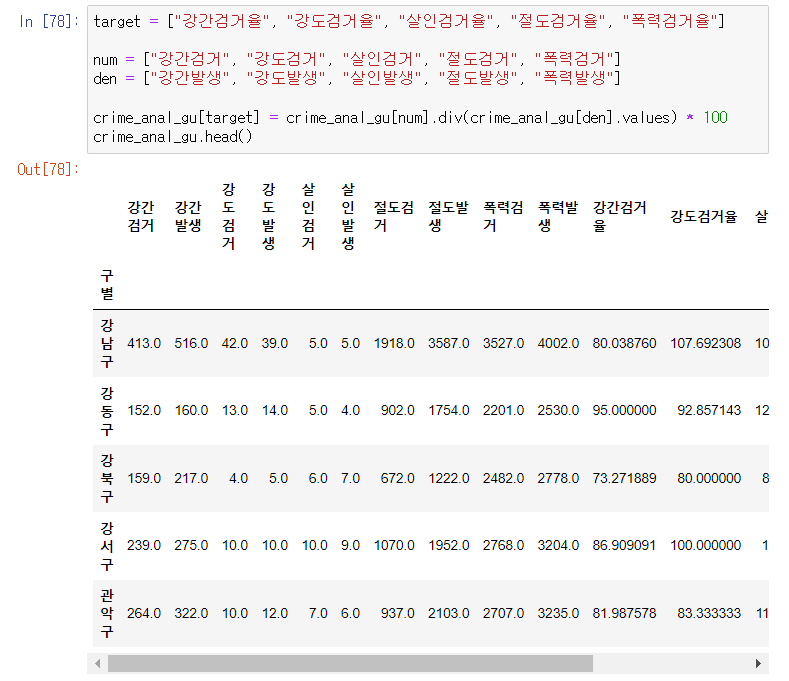
검거율
여러 예시

다수 컬럼 나누기
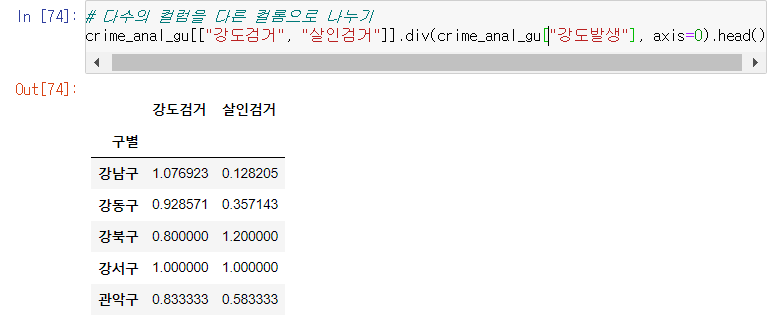
다수 컬럼 / 다수 컬럼
검거율 데이터프레임 생성
데이터 프레임 가공
100 이상 데이터 100으로 변경
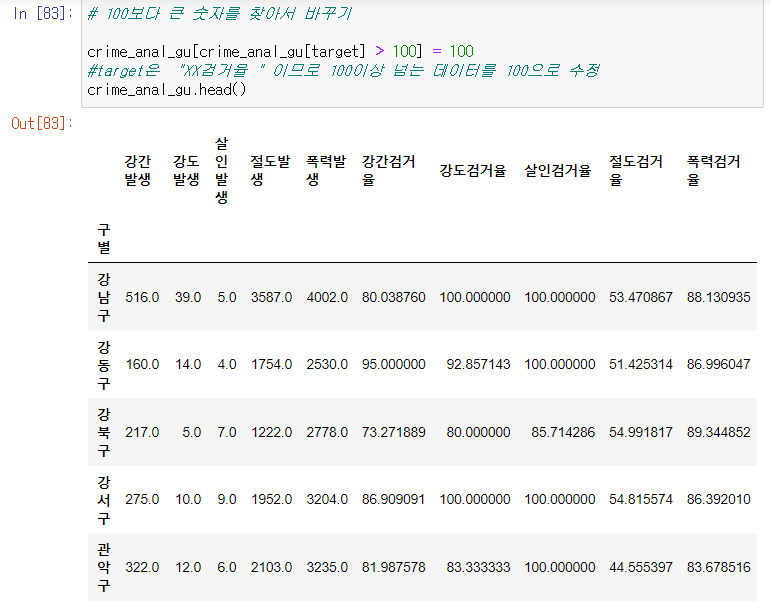
컬럼 이름 변경