8.빅데이터의 조직&인력
-
조직의 구조
-
집중 구조 - 부서 별로 분석
- 전사 분석 업무를 별도의 분석 전담 조직에서 담당
- 전략적 중요도에 따라 분석 조직이 우선 순위를 정해서 진행 가능
- 현업 업무 부서의 분석 업무와 이중화/이원화 가능성 높음
-
기능 구조 - 부서 별로 분석
- 일반적인 분석 수행 구조
- 별도 분석 조직이 없고 해당 업무 부서에서 분석 수행
- 전사적 핵심 분석이 어려우며, 부서 현황 및 실적 통계 등 과거 실적에 국한된 분석 수행 가능성 높음
-
분산 구조
- 분석 조직 인력들을 현업 부서로 배치하여 분석 업무 수행
- 분석 결과에 따른 신속한 action 가능
- 전사 차원의 우선 순위 수행
- 부서 분석 업무와 역할 분담 명확히 해야 함 (→ 업무 과다 이원화 가능성)
-
DSCoE(Data Science Center of Excellence): 데이터 사이언스 전문가 조직
- 조직 평가를 위한 성숙도 단계
- 기업의 분석 수준은 성숙도 수준에 따라 달라진다.
- 도입 단계
- 활용 단계
- 확산 단계
- 최적화 단계
9.클라우드 컴퓨팅
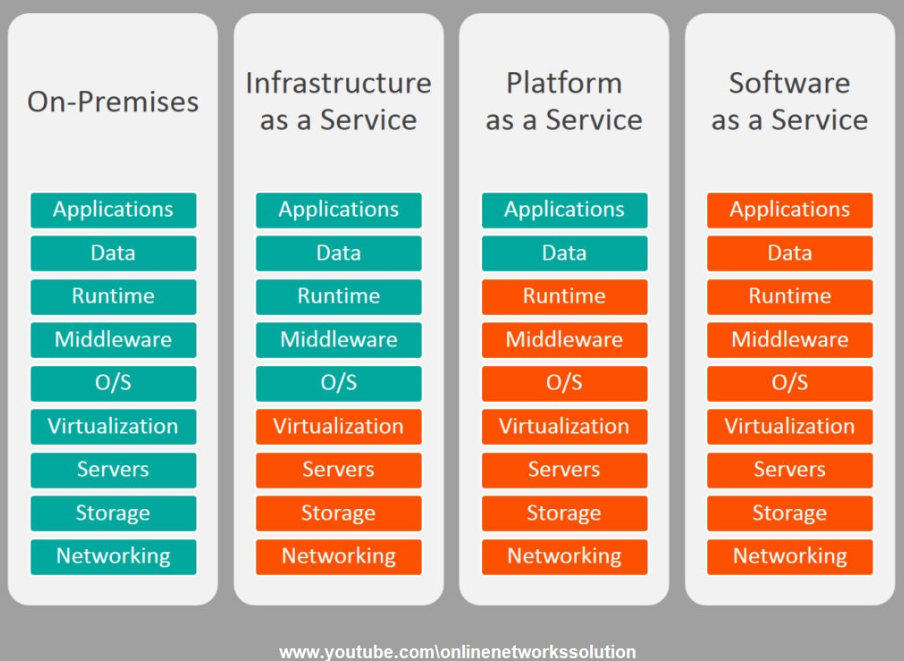
- IaaS (Infrastructure as a Service)
- 서버, 네트워크, 스토리지를 가상화 환경으로 만들어 필요에 따라 인프라 자원을 사용할 수 있게 제공하는 서비스
- PaaS
- SaaS 개념을 개발 플랫폼으로 확장한 것으로, 웹에서 개발 플랫폼을 쉽게 빌려 쓸 수 있는 서비스
- SaaS
- IaaS와 PaaS 위에 올라가는 소프트웨어를 말하며, 온디맨드 소프트웨어라고 얘기함
- 중앙에서 호스팅되는 소프트웨어를 웹 브라우저 등 클라이언트로 이용하는 서비스
10.빅데이터 플랫폼
-
다양한 데이터 소스로부터 수집한 데이터를 처리하고, 분석하여 지식을 추출하고 이를 기반으로 지능화된 서비스를 제공하는데 필요한 IT 환경을 의미
-
다양한 소스 (컴퓨터, 모바일 등) 로부터 생성되는 대량의 데이터를 처리하기 위하여 데이터의 수집, 저장 , 처리, 분석, 시각화를 제공
-
빅데이터 분석 프로세스
- 데이터 수집 → 데이터 저장&관리 (전처리/후처리) → 데이터 처리 (가공) → 데이터 분석 (계획 수립/시스템 구축) → 시각화 및 활용 → 데이터 폐기
-
하둡 에코 시스템
- 프레임워크를 이루고 있는 다양한 서브 프로젝트들의 집합으로 수집, 저장, 처리 기술과 분석, 실시간 SQL 질의 기술로 구분
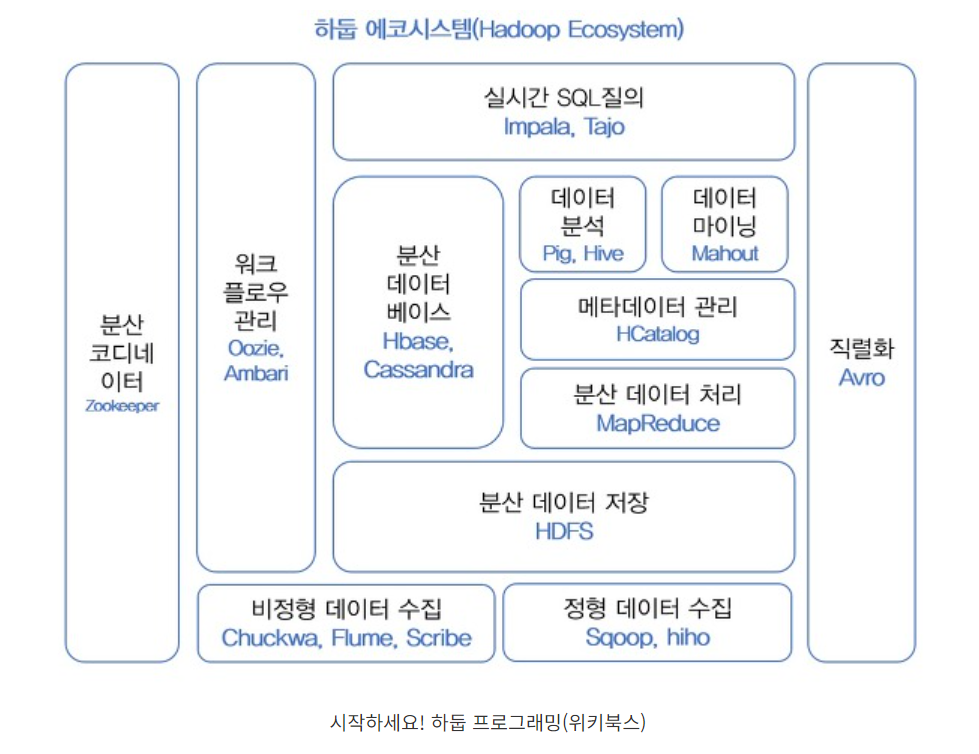
-
비정형 데이터 수집
- 척와 (Chuckwa)
- 에이전트와 컬렉터로 구성됨
- 분산된 각 서버에서 에이전트를 실행하고, 컬렉터는 에이전트로부터 데이터를 받아 HDFS에 저장
- 데이터 수집, 하둡 파일 시스템에 저장, 실시간 분석기능 제공
- 플럼 (Flume)
- 많은 양의 로그 데이터를 효율적으로 수집, 집계, 이동하기 위해 이벤트와 에이전트를 활용하는 기술
- 스크라이브 (Scribe)
- 다수의 서버로부터 실시간으로 스트리밍되는 로그 데이터를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실시간 로그 수집 기술, 최종 데이터는 HDFS 외에 다양한 저장소를 사용
- HDFS에 저장하기 위해서는 JNI(Java Native Interface) 이용해야함
- 척와 (Chuckwa)
- 정형 데이터 수집
- 스쿱 (Sqoop)
- 대용량 데이터 전송 솔루션
- 커넥터를 이용해 RDBMS에서 HDFS로 데이터를 수집
- HDFS에서 RDBMS로 데이터를 전송
- 히호 (Hiho)
- 스쿱과 같은 대용량 데이터 전송 솔루션
- 하둡에서 데이터를 가져오기 위한 SQL 지정 가능하며, JDBC 인터페이스를 지원한다.
- 스쿱 (Sqoop)
- HDFS
- 대용량 파일을 분산된 서버에 저장하고 , 그 저장된 데이터를 빠르게 처리할 수 있게하는 하둡 분산 파일 시스템
- 구성 요소
- 네임 노드 → 마스터 역할 + 모든 메타데이터 관리
- 보조 네임 노드 → 상태 모니터링을 보조
- 데이터 노드 → 슬레이브 역할 + 데이터 입출력 요청
- 분산 데이터베이스
- HBase
- HDFS 를 기반으로 구현된 컬럼 기반의 데이터베이스
- 실시간 랜덤 조회 및 업데이트 가능
- 구글의 BigTable 논문을 기반으로 개발된 것으로 각각의 프로세스는 개인의 데이터를 비동기적으로 업데이트 할 수 있다.
- HBase
- 분산 데이터 처리
- 맵리듀스 (Mapreduce)
- 구글 검색을 위해 개발된 분산환경 병렬 데이터 처리 기법
- 대용량 데이터 세트를 분산 병렬 컴퓨팅에서 처리하거나 생성하기 위한 목적으로 만들어진 소프트웨어 프레임워크
- 모든 데이터를 키 - 값 쌍으로 구성
- 구성요소
- Map → key - value 형태로 데이터를 취합
- 셔플 → 데이터를 통합하여 처리
- 리듀스 → 맵 처리된 데이터를 정리
- 맵리듀스 (Mapreduce)
- 리소스 관리
- 얀 (YARN)
- 하둡의 맵리듀스 처리 부분을 새롭게 만든 자원 관리 플랫폼
- 구성요소
- 리소스 매니저
- 스케줄러 역할을 수행하고, 클러스터 이용률 최적화를 수행
- 노드 매니저
- 노드 내의 자원을 관리하고, 리소스 매니저에게 전달 수행 및 컨테이너를 관리
- 리소스 매니저
- 얀 (YARN)
- 인메모리 처리
- 아파치 스파크
- 하둡 기반 대규모 데이터 분산 처리 시스템으로 스트리밍 데이터, 온라인 머신러닝 등 실시간으로 데이터를 처리
- 필요한 데이터를 메모리에 캐시로 저장하는 인-메모리 방식 채택
- OLTP 보다 OLAP 에 더 적합
- 특징 : 불변성, 복원성, 분산성
- 아파치 스파크
- 데이터 가공
- 피그 (Pig)
- 복잡한 맵리듀스 프로그래밍을 대체할 Pig Latin이라는 자체 언어를 제공
- Mapreduce API를 매우 단순화시키고, SQL과 유사한 형태로 설계
- Hive
- 하둡 기반 DW (Data Warehouse) 솔루션으로 SQL과 유사한 HiveQL이라는 쿼리 제공 → 페이스북 제작
- 피그 (Pig)
- 데이터 마이닝
- Mahout (머하웃)
- 하둡 기반으로 데이터 마이닝 알고리즘을 구현한 오픈소스로 분류
- Mahout (머하웃)
- 실시간 SQL 질의
- 임팔라 (Impala)
- 하둡 기반의 실시간 SQL 질의 시스템
- 데이터 조회를 위한 인터페이스로 HiveQL을 사용
- 수초 내에 SQL 질의 결과를 확인할 수 있으며, Hbase에 연동 가능
- Tajo (타조)
- 다양한 데이터 소스를 위한 하둡 기반의 ETL 기술을 이용해서 데이터 웨어하우스에 적재하는 시스템
- 임팔라 (Impala)
- 워크플로우 관리
- 우지 (Oozie)
- 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템
- 자바 서블릿 컨테이너에서 실행되는 자바 웹 어플리케이션 서버
- 맵리듀스, 피그와 같은 특화된 액션들로 구성된 워크플로우 제어
- 우지 (Oozie)
- 분산 코디네이션
- 주키퍼 (Zookeeper)
- 분산 환경에서 서버들 간에 상호 조정이 필요한 다양한 서비스를 제공하는 기술
- 하나의 서버에만 서비스가 집중되지 않도록 서비스를 알맞게 분산하여 동시에 처리
- 주키퍼 (Zookeeper)
11.빅데이터 & 인공지능
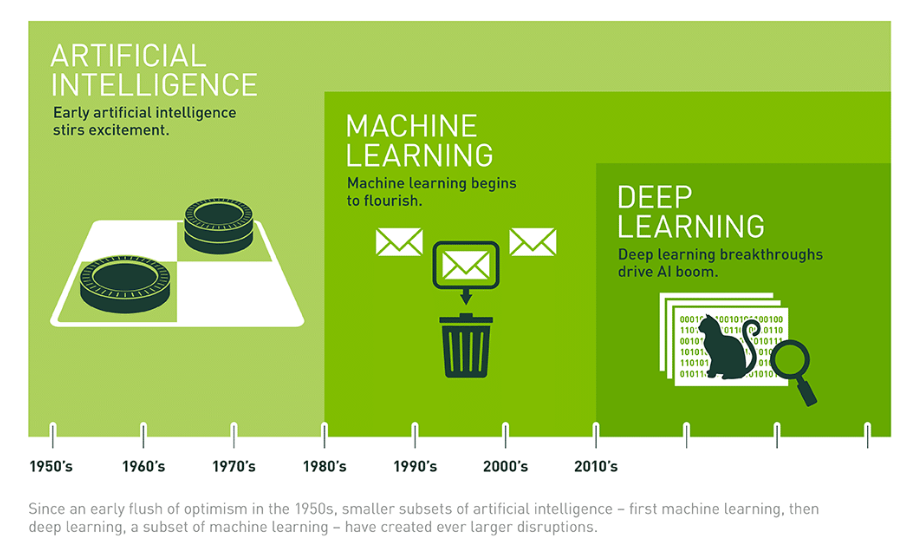
출처: https://blogs.nvidia.com/blog/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
-
인공지능
- 인간의 지적능력을 인공적으로 구현한 기술
- 약인공지능 → 특정한 작업에 특화된 인공지능
- 강인공지능 → 인간과 동등한 지능 수준을 가지는 인공지능
-
머신러닝
- 사람이 수행하기에 복잡하거나 어려운 작업을 사람의 프로그래밍 없이 대량의 데이터를 접했을 때 스스로 수정하여 원하는 결과를 얻기 위한 기술
- 데이터 마이닝 ⇒ 현재의 특징 분석 / 머신러닝 ⇒ 데이터 예측
-
딥러닝
- 인간의 뇌와 흡사하게 구현한 신경망 알고리즘을 적용하여 보다 빠르고 효율적으로 학습하는 인공지능 → 사람의 개입 없이 인공 신경망 방식으로 스스로 학습하는 기술
- 딥러닝은 은닉층을 사용한 결과에 대한 해석이 어렵다
- 지도학습
- 정답인 레이블이 포함되어 있는 훈련 데이터를 통해 학습시키는 방법
- 비지도 학습
- 입력 데이터에 대한 정답인 레이블이 없는 상태에서 훈련 데이터를 통해 학습 시키는 방법
- 준지도 학습
- 정답인 레이블이 포함되어 있는 훈련 데이터와 레이블이 없는 훈련 데이터를 통해 모두 훈련에 사용하는 학습 방법
- 강화 학습
- 어떤 환경 안에서 정의된 에이전트의 현재의 상태를 인식하여, 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하는 방법
-
인공지능 경쟁력의 3요소 (중요)
- 알고리즘 → 기존 신경망 한계 극복
- HW 발달 → GPU 능력 향상
- Big Data → 풍부한 학습데이터
12. 개인정보법&제도
- 위기 요인
- 사생활 침해
- 통제 방안 → 동의에서 책임으로
- 책임 원칙 훼손
- 통제 방안 → 결과 기반 책임 원칙 고수
- 분석대상이 되는 사람들은 예측 알고리즘의 희생양이 될 가능성 증가
- 데이터 오용
- 통제 방안 → 알고리즘 접근 허용 (알고리즈미스트)
- 언제나 맞을 수는 없다
- 사생활 침해
- 알고리즈미스트
- 데이터 오용의 대응책으로 알고리즘에 대한 접근권을 제공하여 예측 알고리즘에 불이익을 당한 사람들을 대변할 전문가가 필요하게 됨
- 알고리즘 코딩 해석을 통해 빅데이터 알고리즘에 의해 부당하게 피해를 입은 사람을 구제하는 전문인력
- 개인 정보 보호법 (중요)
- 개인 정보 수집 시 동의를 얻지 않아도 되는 경우
- 법률에 특별한 규정이 있거나 법령상 의무 준수를 위해 불가피한 경우
- 공공 기관이 법령 등에서 정하는 소관 업무 수행을 위해 불가피한 경우
- 정보 주체와의 계약의 체결 및 이행을 위해 불가피하게 필요한 경우
- 사전 동의를 받을 수 없는 경우로 명백히 정보 주체 또는 제 3자의 급박한 생명, 신체, 재산의 이익을 위하여 필요하다고 인정되는 경우
- 개인 정보 수집 시 동의를 얻지 않아도 되는 경우
- 빅데이터 3법
추가 정보의 결합 없이는 개인을 식별할 수 없도록 안전하게 처리된 가명 정보의 개념을 도입하는 것이 핵심
- 개인정보보호법
- 정보통신망법
- 신용정보법
- 프라이버시모델 추론 방지 기술
- K-익명성
- 일정 확률 수준 이상 비식별 조치
- I-다양성
- 민감한 정보의 다양성을 높임
- t-근접성
- 민감한 정보의 분포를 낮춤
- m-유일성
- 재식별 가능성 위험을 낮춤
- K-익명성
- 가명 처리
- 개인 정보를 안전하게 활용하기 위해 특정 개인에 대한 정보들이 노출되지 않도록 가명처리를 수행
- 가명 처리의 절차
- 1단계 (사전 준비)
- 2단계 (가명 처리)
- 대상 선정
- 목적 달성에 필요한 최소 항목을 처리하는 것이 원칙
- 위험도 측정
- 처리 환경 검토
- 내부 활용
- 내부 제공
- 제 3자 제공
- 항목 별 위험도 분석
- 식별 정보 + 식별 가능 정보
- 처리 환경과 정보의 규모, 구체성 등을 고려한 다음 판단
- 처리 환경 검토
- 가명 처리 수준 정의
- 가명 처리
- 대상 선정
- 3단계 (검토 및 추가 처리)
- 4단계 (활용 및 사후 관리)

쿵!!