Cilium 은 IPVLAN 에 기반한 Routing Datapath 기법을 제공하고 있다. IPVLAN 은 VXLAN 과 마찬가지로 리눅스 커널이 제공하는 기능이므로 IPVLAN 에 대한 자세한 설명은 생략하고, Cilium 의 동작 과정을 설명하면서 필요한 부분에 대해서만 간단히 부연설명하겠다. (Routing Datapath 기법은 모든 노드가 같은 서브넷 안에 있을 때만 사용 가능하다. Calico 는 같은 서브넷에서는 라우팅 기법을, 다른 서브넷에서는 터널링 기법을 사용하는 CrossSubnet 기능도 제공하지만, Cilium 에는 아직 이러한 기능은 없다.)
아래 그림은 Cilium 에서 IPVLAN 을 사용할 경우 Pod-To-Pod 통신이 이루어지는 과정이다. Node0 의 Pod0 에서 Node1 의 Pod3 으로 패킷을 보내는 과정을 살펴보도록 하자.
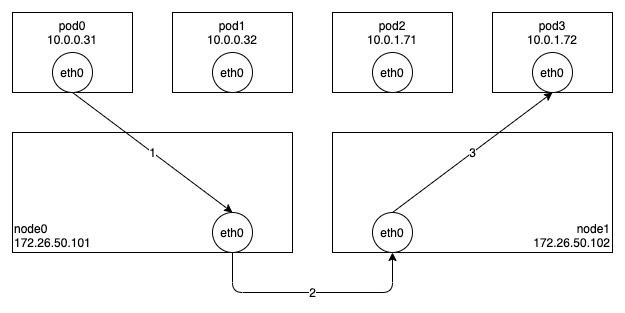
기본적으로 VETH/VXLAN 에 비해 구조가 단순한데, 그 이유는 Pod 의 eth0 은 IPVLAN 슬레이브로, Node 의 eth0 은 IPVLAN 마스터로 동작하기 때문이다. IPVLAN 슬레이브에서 패킷을 전송하면 IP 헤더를 확인하여 동일한 노드에 해당 목적지 주소를 사용하는 IPVLAN 슬레이브가 있으면 바로 전달하고, 아니면 IPVLAN 마스터로 패킷을 전달한다.
IPVLAN 은 MACLAN 과 달리 모든 슬레이브가 마스터의 맥 주소를 공유한다. 즉, MACLAN 처럼 마스터 네트워크 장치를 Promiscuous 모드로 사용하거나, 스위치의 물리적인 제한에 걸리는 문제가 없다는 말이다. 아래는 IPVLAN 기반의 Cilium 을 사용할 경우 Pod 과 노드의 네트워크 정보이다.
pod0 $ ip addr show
9: eth0@if2: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether a4:ae:11:18:c4:2d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.0.71/32 scope global eth0
valid_lft forever preferred_lft forever
...
node0 $ ip addr show
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether a4:ae:11:18:c4:2d brd ff:ff:ff:ff:ff:ff
altname enp2s0
inet 172.26.50.170/24 brd 172.26.50.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::a6ae:11ff:fe18:c42d/64 scope link
valid_lft forever preferred_lft foreverIPVLAN 을 사용하는 경우, LXC BPF 프로그램(cilium/bpf/bpf_lxc.c)을 연결하는 것이 애매하다. VXLAN 을 사용하는 경우에는 Pod 의 veth 가 호스트 네트워크 네임스페이스에 존재하기 때문에 veth 에 LXC BPF 프로그램을 연결해서 사용하지만, IPVLAN 은 호스트 네트워크 네임스페이스에 추가적인 가상 네트워크 장치가 없기 때문에 Pod 의 eth0 에 LXC BPF 프로그램을 연결할 수 밖에 없다. (Kubelet 과 Cilium 이 호스트 네트워크 네임스페이스에서 동작하기 때문에 LXC BPF 프로그램을 연결할 가상 네트워크 장치가 같은 호스트 네트워크 네임스페이스에 있는 것이 편리하다.) 이 문제를 해결하기 위해 Cilium 은 호스트 네임스페이스에 각각의 Pod 을 위한 BPF 프로그램 어레이 맵을 하나씩 만들고, Pod 의 eth0 의 egress 에는 해당 BPF 프로그램 어레이 맵의 첫 번째 프로그램을 tailcall 하는 프로그램을 연결하는 방식을 사용하고 있다.
[cilium/pkg/datapath/connector/ipvlan.go]
func getEntryProgInstructions(fd int) asm.Instructions {
return asm.Instructions{
asm.LoadMapPtr(asm.R2, fd),
asm.Mov.Imm(asm.R3, 0),
asm.FnTailCall.Call(),
asm.Mov.Imm(asm.R0, 0),
asm.Return(),
}
}위 함수는 Kubelet 에서 새로운 Pod 을 생성할 때 호출하는 cilium-cni 에서 Pod 을 위한 IPVLAN 슬레이브(eth0)를 만들고 해당 슬레이브의 egress 에 실제로 연결할 프로그램을 생성하는 함수이다. fd 인자가 바로 앞에서 언급한 호스트 네임스페이스에서 생성한 BPF 프로그램 어레이 맵에 접근할 수 있는 파일디스크립터이고, fd 와 0 을 인자로 tailcall 명령어를 호출하는 간단한 프로그램을 반환한다. 이런 준비과정을 거쳐 Cilium 은 Pod 의 LXC BPF 프로그램을 변경하고 싶을 때 네임스페이스 변경없이 앞에서 생성한 BPF 프로그램 어레이 맵의 첫 번째 프로그램을 변경만 하면 되는 것이다. 그리고 ingress 는 가상 네트워크 장치에 LXC BPF 프로그램을 직접 연결하는 방식이 아니기 때문에 VXLAN 과 동일한 방식을 사용한다. (cilium_call_policy 맵에 목적지(Pod)의 엔드포인트 아이디를 인덱스로 사용해서 저장된 프로그램(cilium/bpf/bpf_lxc.c#handle_policy)을 tailcall 로 직접 호출한다.)
참고로, 동일한 LXC BPF 프로그램(cilium/bpf/bpf_lxc.c#from-container)이 IPVLAN 에서는 Pod 의 eth0 의 egress 에 연결되지만, VXLAN 에서는 veth 의 ingress 에 연결된다. 이는 VXLAN 에서는 Pod 의 eth0 의 TX 가 veth 의 RX 로 바로 전달되기 때문에 호스트 네임스페이스에 있는 veth 의 ingress 에 연결하는 것이다.
IPVLAN 슬레이브에 연결된 BPF 프로그램이 호스트 네임스페이스에서 동작하지 않기 때문에 호스트 네임스페이스에 있는 IPVLAN 마스터로 패킷을 직접 전달(redirect)하는 것은 불가능하다. BPF 프로그램에서 패킷을 전달(redirect)할때 네트워크 장치 인덱스를 같이 전달하는데, 기본적으로 동일한 네임스페이스에 있는 장치 목록에서만 검색을 하기 때문에 다른 네임스페이스에 있는 장치로 패킷을 전달(redirect)하는 것은 불가능하다. 하지만 IPVLAN 은 슬레이브에서 패킷을 내보내면(xmit) IPVLAN 드라이버에서 마스터로 직접 전달해주기 때문에 슬레이브에 연결된 BPF 프로그램에서는 패킷을 전달(redirect)하는 대신, 전송(xmit)만하면 된다. 동일한 노드에 있는 다른 슬레이브로 패킷을 전달할 때도 IPVLAN 드라이버에서 목적지 주소를 확인해서 해당 슬레이브로 패킷을 바로 전달해준다. (반대로, IPVLAN 마스터에서 슬레이브로 패킷을 전달할 때도 전달(redirect)하는 대신, 전송(xmit)하면 IPVLAN 드라이버에서 목적지 주소를 확인해서 해당 슬레이브로 패킷을 바로 전달해준다.)
그럼 이제 패킷이 전달되는 과정을 좀 더 상세히 살펴보도록 하자.
Node0 의 Pod0 에서 생성된 패킷은 eth0 의 ingress BPF 프로그램(cilium/bpf/bpf_lxc.c#from-container)에 의해 목적지 주소가 동일한 노드이면 해당 목적지(Pod1)의 eth0 으로 바로 전송(xmit)하고, 다른 노드이면 노드의 eth0 으로 전송(xmit)한다. 노드에서는 일반적인 패킷과 동일한 방식으로 라우팅 테이블을 참고하여 패킷을 전달하는데, 이는 새로운 노드가 추가될때 해당 노드의 PodCIDR 과 주소를 이용해서 아래와 같이 라우팅 정보를 미리 추가해놓기 때문에 가능하다. (이처럼 Routing Datapath 기법은 모든 노드가 같은 서브넷에 있으면 각 노드의 주소를 게이트웨이 주소로 사용해서 터널링 없이 라우팅이 가능하다.)
node0 $ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.26.50.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 10.0.0.196 255.255.255.0 UG 0 0 0 cilium_host
10.0.0.196 0.0.0.0 255.255.255.255 UH 0 0 0 cilium_host
10.0.1.0 172.26.50.102 255.255.255.0 UG 0 0 0 eth0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
172.26.50.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Node1 의 물리 네트워크 장치(eth0)로 수신된 패킷은 ingress BPF 프로그램(cilium/bpf/bpf_host.c#from-netdev)에서 처리된다. 여기서는 목적지 주소가 해당 노드에 있으므로 cilium_call_policy 맵에 목적지(Pod3)의 엔드포인트 아이디를 인덱스로 사용해서 저장된 프로그램(cilium/bpf/bpf_lxc.c#handle_policy)을 tailcall 로 호출하여 필요한 처리를 한 뒤, 목적지(Pod3)의 eth0 으로 패킷을 전송(xmit)한다.
여기까지 IPVLAN 을 통해 Pod-To-Pod 통신이 이루어지는 과정을 살펴보았다.
"Node0 의 Pod0 에서 생성된 패킷은 eth0 의 ingress BPF 프로그램(cilium/bpf/bpf_lxc.c#from-container)에 의해 "에서 ingress -> egress 로 수정이 필요해보입니다.