개요
배달 앱을 구현하는 팀 프로젝트에서 메뉴, 장바구니, 주문 API를 맡게 되었다.
JPA를 사용해 구현해야 한다는 기본 요구사항이 있었는데, 쿼리문을 직접 쓰지 않고 구현해보자! 라는 것이 개인적으로 가진 추가 목표였다.
왜 굳이 쿼리를 통해 그룹핑하지 않고 비즈니스 로직에서 그룹핑을 적용해보자는 생각이 나왔는지, 생각의 흐름을 기록해보려고 한다.
1. 쿼리 사용 없이 구현을 시도한 이유?
Spring Data JPA는 정해진 규칙 내에서 메서드 명만으로 쿼리를 자동 생성할 수 있게 해준다. 하지만 필드 명이 길거나 조건이 복잡해지면 메서드 명도 따라서 엄청나게 길어질 수 밖에 없고, 결국 @Query 어노테이션을 사용해 JPQL을 직접 작성하게 된다.
이때 JPQL은 다음과 같은 문제를 갖는다.
-
컴파일 타입 안정성 부족:
JPQL은 문자열로 작성되어 문법 오류를 컴파일 시점에 잡을 수 없다. -
복잡한 쿼리 관리 어려움:
조건이 많아지면 쿼리 가독성이 떨어지고 유지보수성이 떨어진다. -
테이블 구조 변경 시 수정 필요:
DB 구조 변경 시 JPQL도 수정해야 한다.
특히 기본적인 CRUD 작업이나 복잡하지 않은 조건의 조회라면 쿼리를 직접 쓰지 않고 해결하는 게 더 깔끔하고 유지보수에 유리하다고 판단했다.
또한 도커 같은 컨테이너들이 보편화되면서, 서버의 Scale-out이 DB보다 상대적으로 쉽기 때문에, 서버 단에서 비교적 무거운 로직을 처리해보는 것도 괜찮은 경험일 거라 생각했다.
2. 그룹핑 처리가 필요했던 부분
주문과 관련된 엔티티는 두 가지였다.
각 엔티티의 구조는 아래와 같이 되어있다.
Order 엔티티
@Entity
@Table(name = "orders")
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Order extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Enumerated(EnumType.STRING)
@Column(nullable = false)
private OrderStatus status;
@Column(nullable = false)
private Integer totalPrice;
@Column(nullable = false)
private String phoneNumber;
@Column(nullable = false)
private String deliveryAddress;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id", nullable = false)
private User user;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "store_id", nullable = false)
private Store store;
public void updateOrder(OrderStatus status) {
this.status = status;
}
public void canceledOrder(OrderStatus status) {
this.status = status;
}
}OrderItem 엔티티
@Entity
@Table(name = "orderItem")
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class OrderItem {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "order_id", nullable = false)
private Order order;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "menu_id", nullable = false)
private Menu menu;
@Column(nullable = false)
private Integer quantity;
@Column(nullable = false)
private Integer price;
}내가 원하던 JSON 응답 형식
[
{
"orderId": 1,
"orderItems": [
{ "menuId": 101, "menuName": "메뉴1" },
{ "menuId": 102, "menuName": "메뉴2" },
{ "menuId": 103, "menuName": "메뉴3" }
]
},
{
"orderId": 2,
"orderItems": [
{ "menuId": 201, "menuName": "메뉴1" },
{ "menuId": 202, "menuName": "메뉴2" }
]
}
]이렇게 주문 건 하나에 포함되는 메뉴들을 묶어서 매핑하고 싶었다.
여기서 내가 스스로 정한 세부적인 요구사항은 OrderItem을 출력할 때 외래키인 주문 아이디를 중복 출력하고 싶지 않았다.
상위 Order 객체에 이미 아이디가 있기 때문에 굳이 아이템에도 가독성 떨어지게 중복해서 여러 번 찍을 이유가 없다고 생각했다.
3. 내가 구현한 방법 (메모리 연산)
스트림 + groupingBy 사용
어려운 방법이지만 실무에서도 많이 쓰이는 방법이라고 하니 익혀두는 것이 좋을 것 같다.
"쿼리를 단순화하고, 복잡한 응답 구조는 자바 코드로 조립한다"가 핵심이다.
OrderItemResponse DTO와 OrderListResponse DTO를 사용하여, 각 주문에 대한 메뉴 리스트를 포함하는 응답 형식을 만들었다.
OrderItemResponse
@Builder
@Schema(description = "주문 아이템 응답 DTO")
public record OrderItemResponse (
@Schema(description = "주문 아이템 ID")
Long id,
@Schema(description = "메뉴 이름")
String name,
@Schema(description = "주문 수량")
Integer quantity,
@Schema(description = "메뉴 가격")
Integer price
) {
public static OrderItemResponse from(OrderItem orderItem) {
return OrderItemResponse.builder()
.id(orderItem.getId())
.name(orderItem.getMenu().getName())
.quantity(orderItem.getQuantity())
.price(orderItem.getPrice())
.build();
}
}
OrderListResponse
@JsonInclude(JsonInclude.Include.NON_NULL)
@Getter
@Schema(description = "주문 목록 응답 DTO")
public class OrderListResponse {
@Schema(description = "주문 ID")
private final Long orderId;
@Schema(description = "가게 ID")
private final Long storeId;
@Schema(description = "가게 이름")
private final String storeName;
@Schema(description = "주문자 이름")
private final String userName;
@Schema(description = "전화번호")
private final String phoneNumber;
@Schema(description = "배달 주소")
private final String deliveryAddress;
@Schema(description = "총 가격")
private final Integer totalPrice;
@Schema(description = "주문 상태")
private final String orderStatus;
@Schema(description = "주문 아이템 리스트")
private final List<OrderItemResponse> orderItems;
public OrderListResponse(Order order, List<OrderItem> orderItems) {
this.orderId = order.getId();
this.storeId = order.getStore().getId();
this.storeName = order.getStore().getName();
this.userName = order.getUser().getName();
this.phoneNumber = order.getPhoneNumber();
this.deliveryAddress = order.getDeliveryAddress();
this.totalPrice = order.getTotalPrice();
this.orderStatus = order.getStatus().getDescription();
this.orderItems = orderItems.stream()
.map(OrderItemResponse::from)
.toList();
}
}OrderService
@Transactional(readOnly = true)
public List<OrderListResponse> getStoreOrders(Long userId, Long storeId) {
Store store = storeRepository.findById(storeId)
.orElseThrow(() -> new StoreException(StoreExceptionCode.STORE_NOT_FOUND));
if (!store.isOwner(userId)) {
throw new OrderException(OrderExceptionCode.OWN_STORE_ONLY);
}
List<Order> orders = orderRepository.findAllByStore(store);
return orderItemService.getOrderItemList(orders);
}OrderItemService
public List<OrderListResponse> getOrderItemList(List<Order> orders) {
return orderItemRepository.findAllByOrderIn(orders).stream()
.collect(Collectors.groupingBy(OrderItem::getOrder))
.entrySet()
.stream()
.map(entry -> new OrderListResponse(entry.getKey(), entry.getValue()))
.toList();
}주문과 관련된 아이템들을 가져온 후, 스트림을 사용하여 Order 별로 그룹핑을 한다. 이때 Collectors.groupingBy()를 사용해 Order 객체를 키로 하고 OrderItem 리스트를 값으로 갖는 맵을 생성한다.
결과
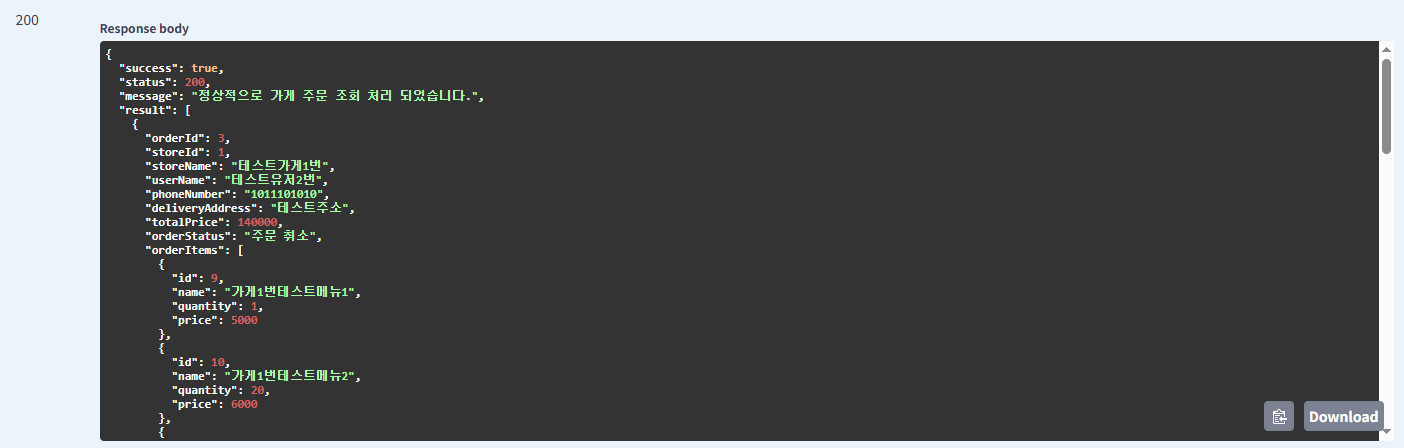
장점
-
단일 책임 원칙(SRP):
각 클래스와 메서드가 하나의 책임만을 가진다.OrderItemService는 OrderItem을 그룹핑해서 Order 별로 묶어주는 역할만 하고,OrderService는 인증, 권한 검증 후 필요한 주문 목록을 가져오는 역할만 맡는다.
이렇게 책임을 분리하면 코드를 이해하기 쉬워지고, 변경이 필요할 때 수정 범위가 좁아져 유지보수가 훨씬 쉬워진다. -
응집도 높은 코드:
응답 형식(OrderListResponse,OrderItemResponse)을 별도의 DTO로 분리해 잘 캡슐화했기 때문에, 추후에 새로운 요구사항이 생기더라도 기존 로직을 크게 수정하지 않고 대응할 수 있다.
예를 들어, 주문 상세 화면에서는 OrderListResponse를 그대로 가져다가 사용하고, 관리자 화면에서는 새로운 DTO에 추가 필드를 붙여 확장하는 것도 자연스럽게 가능하다.
특히 실무에서는 변경 요구가 빈번하기 때문에, 이런 설계를 익히는 것은 좋은 경험이라고 생각한다.
단점
-
성능 저하 가능성:
데이터셋이 작을 때는 문제되지 않지만, 수천~수만 건 이상의 데이터를 처리할 경우, 자바 스트림을 이용한 그룹핑 과정에서 성능이 저하될 수 있다. -
메모리 사용량 증가:
그룹핑 과정은 가져온 모든 데이터를 메모리에 올려놓고 연산을 수행한다. 따라서 데이터량이 많을수록 메모리 점유율이 급격히 증가할 수 있다.
메모리 한계를 초과하면 GC 지연이나 OutOfMemoryError 같은 문제가 발생할 위험도 생긴다. -
복잡성 증가:
스트림과 그룹핑 로직이 여러 번 중첩되거나, 변환 과정이 많아질 경우 코드가 길어지고 복잡해진다.
특히 다양한 조건에 따라 그룹핑하거나, 중첩 구조를 만들 때 가독성이 떨어지고 유지보수가 어려워질 수 있다.
쿼리에서 복잡한 조인이나 변환 로직을 수행하는 대신, 필요한 데이터만 단순하게 가져오고, 그 이후의 구조화 작업은 전부 자바 코드로 처리하는 흐름이다.
쿼리 복잡도를 낮추고 코드로 데이터를 자유롭게 다룰 수 있지만, 연산 횟수가 많을수록 메모리 사용량이 늘어날 수 있다는 점을 주의해야 한다.
마무리
이번 프로젝트에서는 쿼리를 직접 작성하기보다는 서비스 레이어에서 그룹핑하는 방식이 더 적합하다고 판단했다.
그 이유는 다음과 같다.
- 요구하는 응답 구조가 명확했고, 복잡한 쿼리를 작성할 필요가 없었다.
- 더미 데이터가 몇십 건 수준이라, 메모리 기반 그룹핑으로 충분히 감당할 수 있었다.
- 쿼리 작성 없이 깔끔하게 책임 분리된 코드를 유지할 수 있었다.
- 유지보수성과 확장성을 고려할 때, 자바 코드로 조립하는 방식이 오히려 더 유리했다.
단, 이 접근 방식이 항상 좋은 것은 아니다.
- 데이터 양이 많아지면 오히려 DB 쿼리로 그룹핑해서 가져오는 편이 성능상 유리할 수 있다.
- 서비스 규모가 커질수록 메모리 사용량과 트랜잭션 시간 등을 반드시 고려해야 한다.
요약하면, 작은 데이터셋 → 자바 그룹핑, 큰 데이터셋 → 쿼리 그룹핑을 기본으로 생각하고, 특성과 상황에 맞게 융통성 있게 선택하는 것이 중요하다고 느꼈다.
이번 경험을 통해 "쿼리는 최소한으로, 복잡한 조립은 코드로" 라는 하나의 방법을 직접 적용해 볼 수 있었다.
또한 JPA의 기본 철학인 "엔티티 중심 데이터 관리"를 제대로 활용하는 좋은 기회가 되었다고 생각한다.
다음에는 데이터 양이 훨씬 많을 때,
- DB에서
GROUP BY로 직접 묶어오는 경우 - 메모리로 묶는 경우
두 방식의 성능 차이도 벤치마킹해보고 싶다.
