
정확하지 않은 내용이 있을 수 있습니다. 잘못된 내용이 있으면 지적해주세요 🥹
학습한 내용을 기록하고, 리마인드하기 위해 쓴 글입니다.
Next.js - v14(App router),Tanstack-Query - v5를 기준으로 작성된 글입니다.
🍩 서버 컴포넌트와 서버 사이드 렌더링
먼저 시작하기에 앞서 서버 컴포넌트의 개념과 서버 사이드 렌더링을 잠깐 짧게 알아가보자.
(React에서 서버 컴포넌트에 대한 개념을 소개한 것이 벌써 2020년이다. 서버 컴포넌트가 도입된 것은 React 18버전이다.)
🍭 서버 컴포넌트에 대해서
서버 컴포넌트란 쉽게 말해서 서버에서 동작하는 컴포넌트이고, 우리가 이전에 계속해서 사용하던 컴포넌트들은 클라이언트 컴포넌트이다.
화면을 구성하는 데 있어서 RSC와 RCC를 적절히 사용하여 페이지를 구성하였다고 하자.
그러면 서버에서는 컴포넌트 트리를 보면서 직렬화 과정을 통해 json 형태로 만들어준다.
> function Component({ children }) {
return <div>{children}</div>;
}
> React.createElement(Component, { children: "**" });
{
$$typeof: Symbol(react.element),
type: Component // reference to the Component function
props: { children: "**" },
...
}직렬화에 대해서는 쉽게 말하면
JSON.stringifiy를 거쳐도 멀쩡하게 살아있는 애들로 보면 될 것 같다.
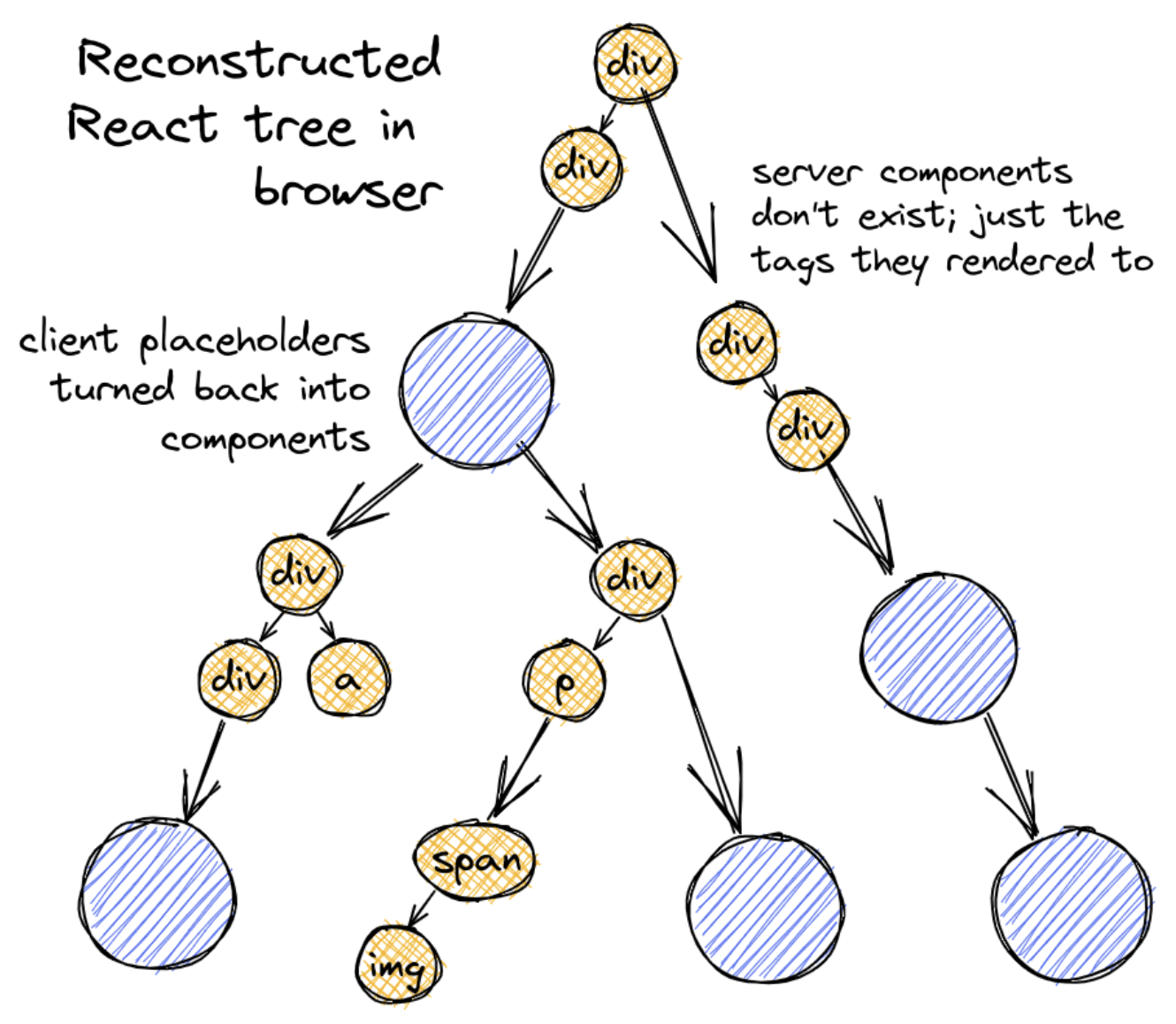
이때 컴포넌트 트리를 살펴볼 때 RCC의 경우에는 직렬화하지 않고 "여기는 RCC야"라는 딱지(placeholder)를 끊어놓고 진행된다.
이때 json형태로 만들어진 형태(RSC payload) 자체는 스트리밍하는데 쓰기에는 부적합하다. 그래서 청크 단위로 분할하여 사용하기 좋은 포멧의 데이터 전송 양식을 사용하게 된다.
그게 바로 'response format'이다. 그 형태는 다음과 같다.
M1:{"id":"./src/ClientComponent.client.js","chunks":["client1"],"name":""}
J0:["$","@1",null,{"children":["$","span",null,{"children":"Hello from server land"}]}]M은 클라이언트 컴포넌트 모듈 참조를 의미J는 실제 react 컴포넌트 트리를 정의하고 앞에서 말한 딱지(placeholder)들도 같이 있다.
🍭 RSC의 FLOW를 도식화 한 이미지
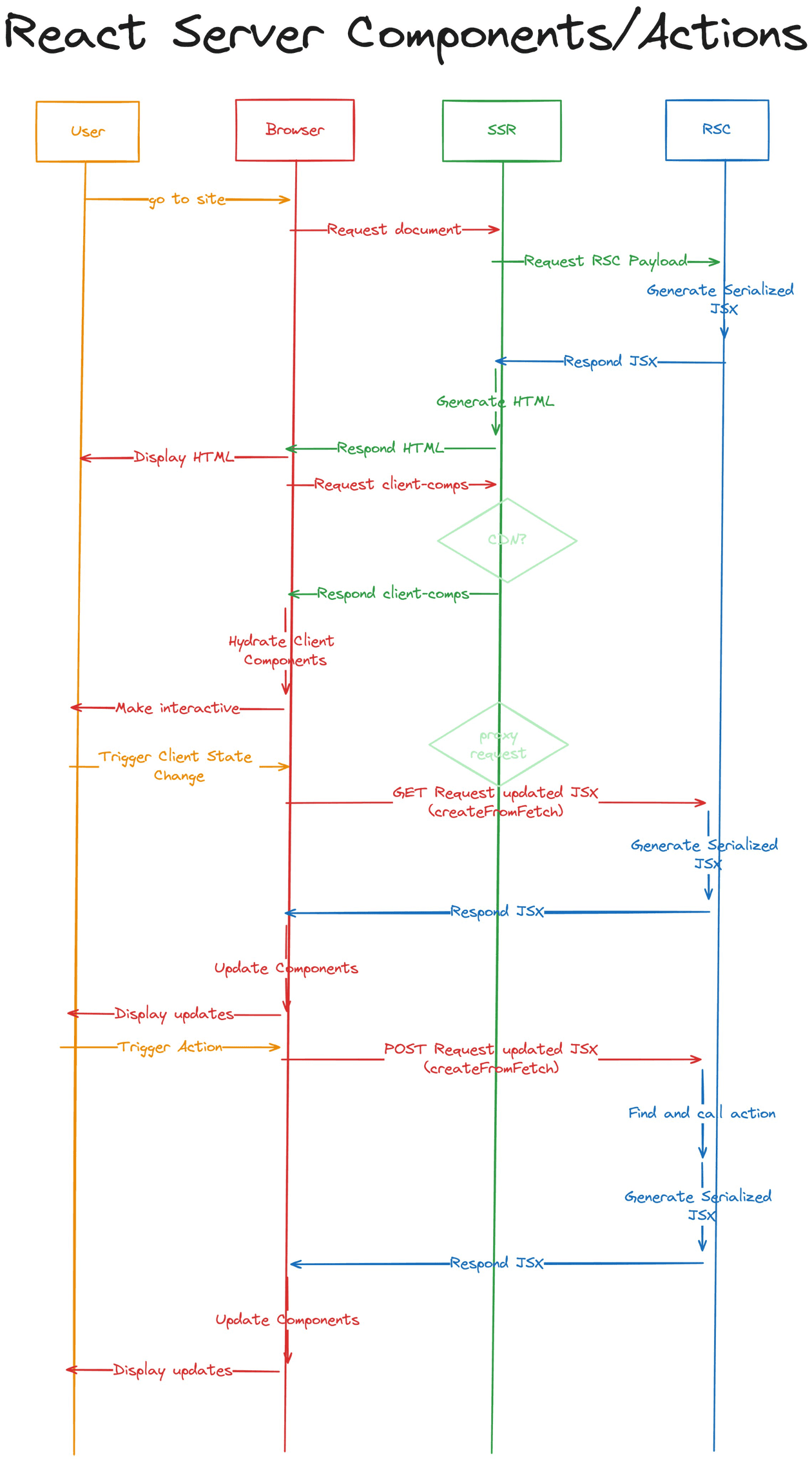
출처: https://saengmotmi.netlify.app/react/what-is-rsc/
🍭 서버 사이드 렌더링에 대해서
1. 서버 사이드 렌더링은 서버 컴포넌트와 다른 개념일까? -> ✅ 맞다 다른 개념이다.
서버 사이드 렌더링은 서버에서 컴포넌트를 해석하고, html을 최종적으로 내려주게 된다. 그래서 초기 렌더링은 매우 빠르지만 매 페이지 이동에 새로운 html을 요청해 받아야 했고 인터렉션에도 약한 단점이 있(었)다.
그러나 지금 우리가 흔히 말하는 SSR은 위의 단점이 없어졌다. Next.js에서는 기존 SSR의 단점을 보완하기 위해서 js도 같이 가져와 hydration하는 과정을 하게 된다.(여기서 hydration에 대해서는 설명하지 않겠다.) 그렇기 때문에 페이지 이동마다 새로운 html을 받아올 필요도 없어지고, 필요한 js만 받아와 CSR의 장점도 같이 취할 수 있게 되었다.
2. 클라이언트 컴포넌트는 그럼 서버에서 렌더링이 될까? -> ✅ (How are Client Components Rendered?)

클라이언트 컴포넌트도 서버에서 렌더링된다. 다만 클라이언트 쪽에서도 렌더링이 된 후에 hydration이 이뤄지게 되는 과정이 있는 것이다. ('use client'를 'use hydration'으로 생각하면 이해가 조금 더 잘된다.)
서버 컴포넌트와 서버 사이드 렌더링을 같이 사용할 때 더 빛나는 장점을 발휘할 수 있게 된다.

서버 컴포넌트를 사용하게 되면 JS 번들이 필요 없어지게 된다. SSR만 사용한다면 CSR을 사용할 때 처럼 동일한 JS 번들을 모두 다운받아야 하기 때문에 로딩속도에 있어서는 장점을 가져갈 수 없다. 그러나 서버 사이드 렌더링에 서버 컴포넌트까지 사용하게 된다면 번들 사이즈를 줄이게 되어 초기 로딩 속도에서 이점을 가져갈 수 있게 해준다.
참고하면/했던 진~짜 좋은 블로그 글 👍 :
🍩 Next.js에서 React-Query 사용하기
서버 컴포넌트와 서버 사이드 렌더링을 알아보았으니 이제 Next.js에서 react-query를 쓰는 법에 대해 알아보자
https://tanstack.com/query/latest/docs/framework/react/guides/advanced-ssr 의 글을 기반으로 작성되었습니다.
🍭 서버에서 사용하기 위한 QueryClient를 세팅하기
'use client'
import {
isServer,
QueryClient,
QueryClientProvider,
} from '@tanstack/react-query'
function makeQueryClient() {
return new QueryClient({
defaultOptions: {
queries: {
// SSR을 사용할 때는 일반적으로 staleTime의 기본값을
// 0보다 크게 설정하여 클라이언트에서 즉시 리페칭하는 것을 피합니다.
staleTime: 60 * 1000,
},
},
})
}
let browserQueryClient: QueryClient | undefined = undefined
function getQueryClient() {
if (isServer) {
// Server: 항상 새 쿼리 클라이언트를 만듭니다.
return makeQueryClient()
} else {
// Browser: 아직 쿼리 클라이언트가 없다면 새로 만듭니다.
// 이는 매우 중요한데, 초기 렌더링 중 React가 suspend되더라도
// 새로운 클라이언트를 다시 만들지 않기 때문입니다.
// 쿼리 클라이언트 생성 아래에 서스펜스 바운더리가 있는 경우에는
// 이 작업이 필요하지 않을 수도 있습니다.
if (!browserQueryClient) browserQueryClient = makeQueryClient()
return browserQueryClient
}
}
export default function Providers({ children }) {
const queryClient = getQueryClient()
return (
<QueryClientProvider client={queryClient}>{children}</QueryClientProvider>
)
}공식 문서에는 거의 완성된 보일러 플레이트를 제공한다. 여기서 눈에 띄는 점은 getQueryClient()인데 서버 환경과 브라우저 환경에서 서로 다르게 생성한다.
클라이언트 환경에서는 싱글톤을 유지해도 되지만 서버 환경에서는 싱글톤을 유지하면 안 된다. 같은 서버에서 모든 유저가 하나의 queryClient를 사용한다면 매우 큰일이 나기 때문에 매번 새로 생성하고, 클라이언트 환경에서 각 유저들은 매번 queryClient를 만들 필요가 없기 때문에 다음과 같이 작성되어 있다.
import {
dehydrate,
HydrationBoundary,
QueryClient,
} from '@tanstack/react-query'
export default async function PostsPage() {
const queryClient = new QueryClient()
await queryClient.prefetchQuery({
queryKey: ['posts'],
queryFn: getPosts,
})
return (
// Neat! Serialization is now as easy as passing props.
// HydrationBoundary is a Client Component, so hydration will happen there.
<HydrationBoundary state={dehydrate(queryClient)}>
<Posts />
</HydrationBoundary>
)
}서버 컴포넌트에서 미리 query 요청을 한 후에 dehydrate처리를 하여 상태를 넘겨준다. 그러면 클라이언트 컴포넌트에서는 미리 받아온 데이터를 즉시 꺼내와 사용할 수 있게 된 것이다.
이렇게 서버에서 prefetch를 진행 한 후에 클라이언트 측에서는 이와 같이 사용한다.
// app/posts/posts.jsx
'use client'
export default function Posts() {
// 이 useQuery는 <Posts>의 더 깊은 자식에서 발생할 수도 있습니다.
// 어느 쪽이든 데이터는 즉시 사용 가능합니다.
const { data } = useQuery({
queryKey: ['posts'],
queryFn: () => getPosts(),
})
// 이 쿼리는 서버에서 프리페치되지 않았으며,
// 클라이언트에서 가져오기 시작할 때까지 시작되지 않습니다.
// 두 패턴 모두 함께 사용해도 괜찮습니다.
const { data: commentsData } = useQuery({
queryKey: ['posts-comments'],
queryFn: getComments,
})
// ...
}🍭 서버 컴포넌트에서 데이터를 다룰때 주의할 점
서버 컴포넌트에서 화면을 그려주는 케이스에서 주의해야 할 점이 존재한다.
// app/posts/page.jsx
import {
dehydrate,
HydrationBoundary,
QueryClient,
} from '@tanstack/react-query'
import Posts from './posts'
export default async function PostsPage() {
const queryClient = new QueryClient()
// 이제 fetchQuery()를 사용하고 있다는 점에 유의하세요.
const posts = await queryClient.fetchQuery({
queryKey: ['posts'],
queryFn: getPosts,
})
return (
<HydrationBoundary state={dehydrate(queryClient)}>
{/* 이 부분이 새로 추가되었습니다. */}
<div>Nr of posts: {posts.length}</div>
<Posts />
</HydrationBoundary>
)
}위에서 staleTime을 60 * 1000(1분)으로 설정하였는데, 어떤 이유에서 staleTime이 지나서 클라이언트에서 revalidates(재검증)이 필요할 때는 어떻게 해야 할까?
이미 서버 컴포넌트에서 발생한 query를 재검증할 방법은 없다. 그래서 클라이언트에서 데이터를 새로 가져와 렌더링하게 되면 서버 컴포넌트에서 그리는 post.length와 실제 데이터 간의 불일치가 발생하게 되는 것이다.
🍭 tanstack은 여기서 더 나아가
위의 코드를 보면 알겠지만, async/await이 계속해서 들어갔다. 이는 다른 말로 서버에서 요청을 기다리는 게 포함되어 있다.
🤔 그러나 기다릴 필요가 없다면? 그러면 기다리지 않고 어떻게 dehydrate해서 전달해주지?
아까 위에서 작성한 코드에서 옵션을 추가하면 된다.
function makeQueryClient() {
return new QueryClient({
defaultOptions: {
queries: {
staleTime: 60 * 1000,
},
dehydrate: {
// 디하이드레이션에 보류 중인 쿼리 포함
shouldDehydrateQuery: (query) =>
defaultShouldDehydrateQuery(query) ||
query.state.status === 'pending',
},
},
})
}pending상태인 query까지 함께 dehyrdrate처리를 해버릴 수 있는 것이다.
이게 가능한 이유는 React에서 Promise를 직렬화 할 수 있기 때문이다. (아까 위에서 말한 직렬화가 가능한 것만 사용할 수 있다는게 여기에 한번 더 나온다.)
이렇게 되면 이제 prefetchQuery를 기다릴 필요 없이 제공만 하면 되는 것이다.
// async/await을 제거할 수 있게 되었다.
export default function PostsPage() {
const queryClient = getQueryClient()
queryClient.prefetchQuery({
queryKey: ['posts'],
queryFn: getPosts,
})
return (
<HydrationBoundary state={dehydrate(queryClient)}>
<Posts />
</HydrationBoundary>
)
}
// app/posts/posts.tsx
'use client'
export default function Posts() {
const { data } = useSuspenseQuery({ queryKey: ['posts'], queryFn: getPosts })
// ...
}Promise를 리턴하기 때문에 우리는 이제 useSuspenseQuery를 호출할 수 있다!
🍭 보일러 플레이트가 너무 많아
여기까지 오면 느낀게 있을 것이다.
그것은 바로 HydrationBoundary 매번 감싸고, dehydrate하는 작업이 반복되는 느낌이 들 것이다. 이 과정을 한번에 해주는 컴포넌트를 만들고 싶을 것이다.
공통화하는 방법엔 정말 여러가지가 있을 것 같은데 이 부분은 직접 구현할 때 해보는 것을 추천한다. (queryOption만 받아서 넘겨받는 컴포넌트 만들기, dehydrate하는 query와 hydrate하는 컴포넌트 제공하는 유틸 만들기 등등)
역시나 이 고민을 tanstack에서도 당연히 했다.
ReactQueryStreamedHydration라는 컴포넌트를 실험적으로 제공하고 있다. 이 컴포넌트를 사용하게 되면 앞서 열심히 제작한 보일러 플레이트를 사용할 필요 없이 useSuspensQuery를 사용하는 것만으로 해결이 가능하다.
import { ReactQueryStreamedHydration } from '@tanstack/react-query-next-experimental'
// ...
export function Providers(props: { children: React.ReactNode }) {
const queryClient = getQueryClient()
return (
<QueryClientProvider client={queryClient}>
{/** 여기에 해당 컴포넌트를 넣어주면 된다. **/}
<ReactQueryStreamedHydration>
{props.children}
</ReactQueryStreamedHydration>
</QueryClientProvider>
)
}이렇게 사용하면 장점만 있는 것은 아니다.
기존에는 워터폴 요청을 효과적으로 제거할 수 있었다. 그러나 이 방식은 초기 페이지 로딩에서만 병렬적으로 요청이 가고 페이지를 요청할 때는 더 깊은 워터폴로 이뤄지게 된다.
1. |> <Feed>의 JS
2. |> getFeed()
3. |> <GraphFeedItem>의 JS
4. |> getGraphDataById()왜 그럴까 이유를 생각해보면 처음에 수동으로 직접 prefetch하는 방식은 페이지 요청마다 새롭게 할 필요가 없었지만, 이 방식은 prefetch를 실행하지 않기 때문에 매 페이지 이동마다 워터폴 형태로 요청하게 되는 것이다.
그래도 두 방법의 절충안을 시도하기를 원하는 것 같다.

tanstack에서도 서버 컴포넌트와 스트리밍에 대해서 여전히 새로운 concept로 보고 있어 열심히 개발하고 있는 과정 중에 하나라고 쓰여있다 🥹

잠깐✋ dehydrateNew()?!
dehydrateNew() - https://github.com/TanStack/query/discussions/8195
dehydrate() - https://github.com/TanStack/query/blob/f04dd199eacde5ecb9e50c51c7a894d65aaf35cd/packages/query-core/src/hydration.ts#L105
문서 중간에 보면 dehydrateNew를 개선 사항으로 남겨두었는데 이는 매번 쿼리를 dehyrdrate하는 것이 아닌 마지막 호출 이후에 새로운 쿼리만 dehydrate하는 것을 만든다고 써놓았다.
🍬 마지막으로
Next.js를 쓸 때 서버 컴포넌트에서 react-query를 쓰는 것에 대한 막연한 거부감😭을 가지고 있었다. 그러나 직접 사용하고 학습하면서 그 점이 사라지게 되었다.
클라이언트 컴포넌트에서 react-query를 사용하여 복잡한 비지니스 로직들을 관리하는데 용이하다면, 서버 컴포넌트에서 Next에서 제공하는 fetch함수를 따로 가져갔을 때 오히려 코드의 복잡도가 올라가고 효율적이지 못할 수 있다.
즉, 서버 컴포넌트에서도 react-query를 사용하여 클라이언트에서 데이터를 다루는게 더 효율적인 개발 환경이 마련되는 것이다.
또, Next.js에서 제공하는 fetch함수의 캐싱 전략과 react-query의 캐싱 전략이 서로 다른 방향성을 가지고 있는 것도 알게 되었다. 이에 대해서는 위 글에서 다루지 않았는데, 추후의 다른 글로 정리해보도록 하겠다.

21개의 댓글




저도 Next.js에서 React Query를 도입하면서 비슷한 고민을 했었는데 ReactQueryStreamedHydration 옵션도 있었군요:) 좋은 글 감사합니다!


제가 하나 팁 드리죠. RSC에서

fetch쓴다 는 말이죠.디지고 싶어 환장했다는 뜻입니다.