초록
- 초록(Abstract) 번역
바이너리 수준 함수 매칭은 공개된 프로그램에서 1-day 취약점이 존재하는지 탐지하는 데 널리 사용되고 있습니다. 하지만 취약한 함수와 패치된 함수가 매우 유사하기 때문에, 현재 함수 매칭 솔루션에서는 높은 오탐(false positive)이 발생하는 문제가 있습니다. 본 논문에서는 Binary X-Ray(BINXRAY)라는 패치 기반 취약점 매칭 접근법을 제안하여, 대상 프로그램에서 특정 1-day 취약점을 정확하고 효과적으로 식별할 수 있도록 합니다.
준비 단계에서는, 취약한 프로그램과 패치된 프로그램을 비교하여 패치의 시그니처(특징)를 추출하는 기본 블록 매핑 알고리즘을 설계하였습니다. 이 시그니처는 기본 블록 트레이스 집합으로 표현됩니다. 탐지 단계에서는, 패치 시맨틱(의미론)을 적용하여 관련 없는 기본 블록 트레이스를 줄이고, 시그니처 탐색 속도를 높입니다. 또한, 트레이스 유사도(traces similarity)를 설계하여 대상 프로그램이 패치되었는지 여부를 식별합니다.
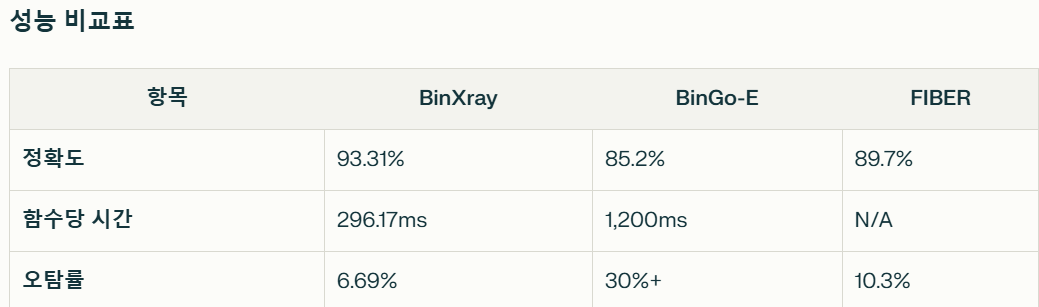
실험에서는 12개의 실제 소프트웨어 프로젝트에서 479개의 CVE를 수집해 평가를 진행했습니다. BINXRAY는 93.31%의 정확도를 달성했고, 함수당 분석 시간은 296.17ms로 기존 최신 연구들보다 뛰어난 성능을 보였습니다.
도입
- 도입(Introduction) 번역
패치가 공개된 취약점은 1-day 취약점이라고 불립니다. 이는 최신 보안 패치를 적용하지 않은 사용자를 공격하는 데 악용될 수 있으며, 가장 심각하고 흔한 보안 위협 중 하나입니다. 바이너리 수준 코드 매칭은 공개된 프로그램에서 1-day 취약점을 탐지하기 위한 좋은 솔루션으로 간주됩니다.
이는 "알려진 취약점이 있는 함수(몇가지 룰들)"와 "대상 바이너리 내 함수"의 유사도를 비교하여, 대상 함수가 취약한 함수와 유사할 경우 취약한 것으로 예측합니다.
취약점 탐지 능력을 높이기 위해, 많은 연구들이 바이너리 수준 코드 매칭 정확도를 높이기 위한 방법을 제안해왔습니다. 예를 들어, DiscovRE와 CACompare는 바이너리 명령어를 통합 중간 표현으로 변환하여 아키텍처를 넘나드는 함수 매칭을 달성합니다. BLEX는 프로그램 실행을 통해 의미론적 특징을 추출하여 매칭 정확도를 높입니다. BinGo와 BinGo-E는 구문, 구조, 의미 정보를 결합해 더 정확한 매칭 결과를 도출합니다.
하지만 현재 함수 매칭 솔루션들은 "취약점"과 "패치된 함수"의 구분이 어렵습니다. 왜냐하면 패치는 보통 미세한 코드 변경만으로 취약점을 수정하기 때문입니다. 그 결과, 패치된 함수도 취약한 함수로 오인되어 오탐률이 높아집니다. 따라서, 실제로 취약한 함수를 찾기 위해 보안 전문가가 수작업으로 분석해야 하며, 이는 매우 시간이 많이 소요됩니다.
이 문제를 해결하는 것은 쉽지 않습니다. 한편으로는, 함수 업그레이드나 컴파일러 최적화 등 취약점과 무관한 작은 코드 변경이 있어도 취약한 함수를 식별할 수 있을 만큼 접근법이 관대해야 합니다. 다른 한편으로는, 이미 패치된 함수는 걸러낼 수 있을 만큼 정밀해야 합니다.
기존 연구(Zhang and Qian)는 함수가 패치되었는지 여부를 판단하는 알고리즘을 제안했습니다. 이들은 소스코드에서 구문 및 의미 변화를 추출하고, "소스코드-바이너리" 매칭 모델을 구축합니다. 하지만 이는 소스코드가 필요하므로, 소스코드가 없는 경우에는 적용할 수 없습니다.
현재까지, 패치 식별이 가능한 바이너리 수준 취약점 매칭을 위한 효과적이고 효율적인 방법은 부족한 상황입니다. 실무에 적용 가능한 접근법은 다음 세 가지 특성을 가져야 합니다.
P1. 대상 함수에서 패치를 정확하게 식별할 수 있어야 한다.
P2. 대규모 실제 프로그램에도 확장 가능해야 한다.
P3. 소스코드 정보 없이, 폐쇄형 바이너리 프로그램에도 적용 가능해야 한다.
이 세 가지 특성을 충족하기 위해, 우리는 Binary X-Ray(BINXRAY)라는 패치 기반 취약점 매칭 접근법을 제안합니다. 이 방법은 바이너리 내에서 패치된 함수와 취약한 함수를 정확하게 구분할 수 있습니다. 최신 함수 매칭 도구(BinGo-E) 대비 오탐률을 30% 이상 줄이면서, 시간 소요도 더 적습니다. 또한, 소스코드 없이도 패치 식별 도구(FIBER)보다 더 높은 정확도를 보입니다.
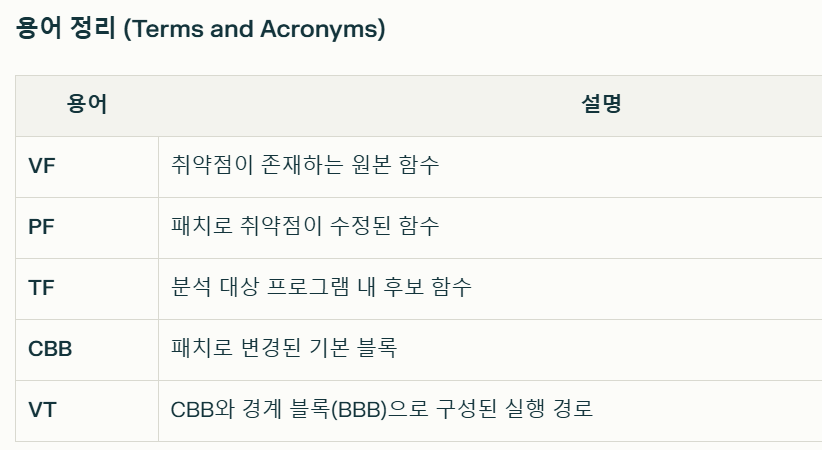
3.방법론 (Methodology)
1. 기본 블록 매핑 알고리즘 요약
- 목적: 취약 함수(VF)와 패치 함수(PF) 간 변경된 기본 블록(CBB) 정확히 식별
- 과정:
1.정규화: 컴파일러 최적화 노이즈 제거를 위한 레지스터/메모리 주소 정규화 기술로 메모리 접근을 심볼릭 값으로 치환한다.
2.해시 기반 매칭:
동일한 해시값을 가진 블록들을 그룹화.
한 그룹 내에서 구조적 유사도(인접 블록의 명령어 시퀀스 편집 거리) 계산.
탐욕적 알고리즘(Greedy Algorithm)으로 최적 매핑 도출.
3.변경 블록(CBB) 식별: 매핑 후 남은 블록을 CBB로 분류.
3.1 대상 함수 매칭
- VF의 구문 정보(명령어 연산자, 함수 호출) + 구조 정보(기본 블록 수, CFG 구조) 결합해 함수 시그니처를 생성한다.
- VF의 시그니처와 TF내 함수들의 시그니처를 비교해, VF와 유사한 함수 후보를 추출한다.
3.2 패치 시그니처 생성
3.2.1 Basic Block Mapping (기본 블록 매핑)
- 목적: VF와 PF 간 변경된 기본 블록(CBB)을 정확하게 식별한다.
- 정규화:
주소 정규화: 구체적 주소를 address로 치환한다.
call 0x80488094 → call address
메모리 정규화: 간접 메모리 접근을 mem으로 치환한다.
mov [ebp], edx → mov mem, edx
레지스터 정규화: 구체적 레지스터를 reg로 치환한다.
mov ebp, esp → mov reg, reg - 해시 기반 그룹화
정규화된 명령어 시퀀스의 해시값 계산해 동일한 해시값의 블록들을 그룹으로 묶는다. - 구조적 유사도 계산
그룹 내 블록 쌍의 인접 블록 명령어 시퀀스 편집 거리 계산해 가중치를 적용 - 탐욕적 매핑(Greedy Algorithm)
유사도 점수 행렬에서 가장 높은 점수의 블록 쌍을 순차적으로 매칭하고, 남은 블록을 변경된 기본 블록(CBB)로 분류한다.
예시:
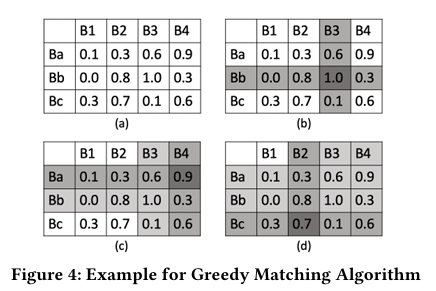
VF 블록: Ba, Bb, Bc
PF 블록: B1, B2, B3, B4
- 기존 도구 Bindiff는 오류: Bb ↔ B3 매칭 실패 (구조적 유사도 무시).
- BinXray는 성공: 문맥 정보(인접 블록 명령어)로 정확한 Bb ↔ B3 매칭.
3.2.2 Valid Trace Generation (유효 트레이스 VT 생성)
- VT 정의: CBB와 경계 블록(BBB)으로 구성된 순차적 실행 경로.
생성 규칙
1.시작/종료 노드:
BBB(경계 블록) 또는 CFG의 루트/리프 노드.
2.루프 처리:
루프는 1회 순회로 평탄화(Flatten) → 구문 정보 보존.
3.경로 추출:
CBB와 BBB로 구성된 연결된 그래프에서 모든 가능한 경로 탐색. - 패치 시그니처: VF의 트레이스 집합(T₁)과 PF의 트레이스 집합(T₂)을 결합.
예시 (HeartBleed):
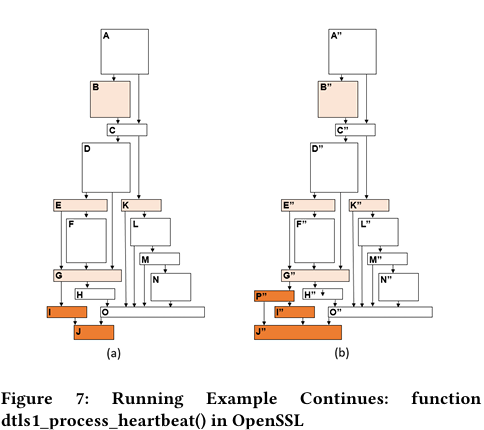
VF(OpenSSL 1.0.1f):
트레이스: A→B, A→C→D→E 등 8개.
PF(OpenSSL 1.0.1g):
트레이스: A’→B’, A’→C’→D’→M’→U’ 등 14개.
3.3 Patch Presence Identification (패치 적용 여부 식별)
3.3.1 Trace Generation (트레이스 생성)
입력: TF(대상 함수), VF 시그니처(T₁), PF 시그니처(T₂).
과정:
1. TF ↔ VF 매핑: CBB 추출 → BBB와 결합하여 트레이스 집합(T₃, T₄)생성.
2. TF ↔ PF 매핑: 동일한 방법으로 트레이스 집합(T₅, T₆)생성.
3.3.2 Trace Reduction (트레이스 축소)
목적: 관련 없는 트레이스 제거 → 노이즈 감소.
방법:
T₄에서 T₁과 공통 CBB가 없는 트레이스 제거 → T₄¹ 생성.
T₆에서 T₂와 공통 CBB가 없는 트레이스 제거 → T₆² 생성.
3.3.3 Similarity Comparison (유사도 비교)
트레이스 유사도 계산:
두 트레이스(t₁, t₂)의 Levenshtein 거리 기반 유사도 점수:
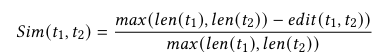
전체 트레이스 집합 유사도: 각 트레이스 쌍의 가중 평균.
3.3.4 Decision Algorithm (결정 알고리즘)
판정 기준:
TF가 VF(T₁)와 더 유사 → 취약 함수.
PF(T₂)와 더 유사 → 패치된 함수.
4.실험 (Evaluation)
4.1 실험 설계
- 데이터셋: 12개 오픈소스 프로젝트(Linux Kernel, OpenSSL 등)의 479개 CVE.
- 비교 대상:
함수 매칭 도구: BinGo-E(함수 전체의 유사도를 비교한다.)
패치 식별 도구: FIBER (소스코드 의존적.) - 평가 지표:
정확도(Accuracy), 함수당 분석 시간, 오탐률(False Positive Rate).
주요 사례:
CVE-2014-0160 (HeartBleed): BinXray가 패치된 함수를 100% 정확도로 식별.
CVE-2015-1790 (OpenSSL): 노이즈 변경(Area 1)을 무시하고 실제 패치(Area 2)만 탐지[그림 5].
4.3 논의 (Discussion)
4.3.1 기존 연구와의 차별점
- 기존 도구 한계
BinGo-E는 전체 함수 유사도만 비교 → 패치 전후 유사해서 오탐률 높음.
FIBER는 소스코드 의존적 → 폐쇄형 바이너리 분석 불가.
-BinXray의 혁신
패치 시그니처 집중 비교 → 정적 분석의 정밀도 향상(오탐률 30% 이상 감소)
바이너리 레벨 독립적 분석 가능 → 소스코드 의존성 제거, 실무 적용성 확보
4.3.2 한계 및 향후 과제 - 컴파일러 최적화: 높은 최적화 수준(O2, O3)에서 정확도 약간 하락하는 문제.
- 난독화 바이너리: 코드 난독화 시 패치 시그니처 추출 어려운 한계.
- 확장성: 대규모 펌웨어(100MB+) 분석 시 메모리 사용량 급증 문제.
결론
BinXray는 낮은 오탐률과 소스코드 독립성으로 기존 도구 대비 실용성 우수.
향후 컴파일러 최적화 내성 강화 및 대규모 분석 최적화가 필요.
결론
- 결론(Conclusion) 번역
본 논문에서는 바이너리 수준에서 패치 기반 취약점 매칭을 위한 접근법인 BINXRAY를 제안하였다.
BINXRAY는 패치 전/후 함수의 차이를 분석하여 패치 시그니처를 추출하고, 이를 통해 대상 바이너리 내에서 패치가 적용되지 않은 취약한 함수를 정확하게 식별할 수 있다.
우리는 실제 12개의 소프트웨어 프로젝트와 479개의 CVE를 대상으로 실험을 수행하였고,
BINXRAY가 기존 최신 연구들보다 더 높은 정확도(93.31%)와 빠른 분석 속도(함수당 296.17ms)를 달성함을 보였다.
BINXRAY의 주요 기여는 다음과 같다.
새로운 기본 블록 매핑 알고리즘을 통해 패치 시그니처를 정확하게 추출할 수 있다.
패치된 함수와 취약한 함수를 효과적으로 구분하여, 오탐률(false positive rate)을 크게 줄였다.
소스코드 없이도 동작하며, 실제 대규모 바이너리 프로그램에도 적용 가능하다.
향후 연구로는, 더욱 다양한 컴파일러 최적화 환경이나, 난독화(obfuscation)된 바이너리 환경에서도 BINXRAY의 성능을 개선하는 방향을 제시한다.
- 대상 바이너리내 미패치 취약 함수(TF): 검사할 타깃 프로그램(패치 여부를 확인할 바이너리)
- 취약한 함수(VF): 취약점이 존재하는 패치 적용 전의 함수
- 패치된 함수(PF): 취약점이 수정된 함수(코드가 변경되어, 더이상 취약점이 발생하지 않는 함수)
- 패치 시그니처: 패치 전 함수(VF)와 패치 후 함수(PF)를 비교해서 패치를 통해 바뀐 블록들의 경로 집합
=> binxray: 대상 바이너리(TF)에서 VF와 비슷한 함수(후보)를 찾고, 이 함수에 패치 시그니처가 적용되어 있으면, PF으로 아니면, VF로 분류한다.
팀 프로젝트 연관성
1. 차별화 포인트
통합 워크플로우: 함수 선별 → Diffing → 디컴파일을 단일 툴 체인으로 통합 (기존 연구는 단계별 도구 분리).
LLM 활용: BinXray의 트레이스 유사도 계산을 LLM 기반 시맨틱 분석으로 확장 가능[검색결과 6].
- 주의 사항
컴파일러 영향 최소화: 정규화 규칙 추가 개발 필요 (예: ARM 아키텍처 대응).
실시간 분석: 대용량 바이너리 처리 시 병렬화 기법 도입.
이 내용을 바탕으로 팀원들에게 방법론의 기술적 혁신성과 실험 결과의 실용성을 강조하며 발표할 계획입니다. 특히, BinXray가 기존 도구보다 오탐률을 크게 낮춘 점과 소스코드 없이 동작하는 장점을 부각시킬 예정입니다.
발표
1. 연구 배경 및 문제의식(왜 이 논문을 골랐는지, 이 논문이 다루는 문제는 무엇인지)
최근 소프트웨어의 보안 취약점이 공개되고 패치가 배포되더라도, 실제로 많은 시스템은 즉시 패치를 적용하지 않아 1-day 취약점이 남아있게 됩니다. 이런 1-day 취약점은 공격자에게 실질적인 위협이 되며, 신속한 탐지가 매우 중요합니다.
하지만 기존의 바이너리 취약점 탐지 방법은 오탐률이 높거나, 소스코드에 의존하는 한계가 있어 실무 적용에 어려움이 많았습니다.
이 논문은 패치 기반 바이너리 분석을 통해, 소스코드 없이도 빠르고 정확하게 미패치 취약점을 탐지하는 방법을 제안한다는 점에서 주목할 만합니다.
2. 기존 연구의 한계와 이 논문의 차별점(기존 방법으로는 무엇이 부족했는지)
기존의 대표적인 바이너리 함수 매칭 도구인 BinGo-E는 전체 함수의 유사도만을 비교하기 때문에, 패치 전후 함수가 매우 유사할 때 오탐률이 30% 이상으로 높게 나타나는 문제가 있었습니다.
또 다른 도구인 FIBER는 패치 식별 정확도는 높지만, 소스코드가 반드시 필요하다는 한계가 있어, 실제로 소스코드가 없는 상용 소프트웨어나 폐쇄형 바이너리에는 적용이 불가능했습니다.
- BinXray의 가장 큰 차별점은
소스코드 없이도 패치 전후 바이너리의 변경된 부분(패치 시그니처)만을 집중적으로 비교해 오탐률을 6.69%까지 낮추고 대규모 바이너리에도 적용 가능하다는 점입니다.
3. 주요 방법론(이 논문에서 제안한 핵심 기술/알고리즘)
BinXray는 크게 세 단계로 동작합니다.
첫째, 대상 함수 매칭:
취약점이 있는 함수(VF)와 패치된 함수(PF)의 시그니처를 만들어, 분석 대상 바이너리에서 유사한 함수 후보를 빠르게 선별합니다.
이때 구문 정보(명령어, 함수 호출)와 구조 정보(기본 블록 수, 제어 흐름 그래프)를 모두 활용합니다.
둘째, 패치 시그니처 생성:
패치 전후 함수의 기본 블록을 정규화한 뒤, 해시 기반으로 그룹화하고,
인접 블록의 명령어 시퀀스 편집 거리까지 고려해 탐욕적 알고리즘으로 매핑합니다.
이 과정을 통해 패치로 인해 실제로 변경된 블록(CBB)만을 정확히 추출하고,
이 변경 블록과 경계 블록(BBB)으로 구성된 유효 트레이스(Valid Trace) 집합을 패치 시그니처로 만듭니다.
셋째, 패치 적용 여부 판정:
대상 바이너리에서 추출한 함수의 트레이스와 패치 시그니처를 비교해,
패치가 적용되지 않은 취약 함수인지, 패치된 함수인지를 자동으로 판별합니다.
이때 Levenshtein 거리 기반 유사도 계산을 사용합니다.
4. 실험 결과(어떤 데이터셋/실험에서 얼마나 성능이 좋았는지)
BinXray는 Linux Kernel, OpenSSL 등 12개 오픈소스 프로젝트에서
총 479개의 실제 CVE를 대상으로 평가되었습니다.
정확도는 93.31%로, 기존 BinGo-E(85.2%)와 FIBER(89.7%)보다 높았습니다.
함수당 분석 시간도 296ms로 BinGo-E(1,200ms)보다 훨씬 빨랐습니다.
대표적인 HeartBleed(CVE-2014-0160) 취약점의 경우, 패치된 함수를 100% 정확도로 식별했습니다.
또, 불필요한 코드 변경(노이즈)은 무시하고, 실제로 취약점이 수정된 부분만을 정확히 탐지하는 것이 실험적으로 입증되었습니다.
5. 결론 및 한계, 향후 연구 방향
BinXray는 패치 기반 시그니처 분석을 통해 소스코드가 없는 환경에서도 효율적이고 정확한 1-day 취약점 탐지가 가능함을 보여줍니다.
- 다만, 컴파일러 최적화(O2, O3)나 코드 난독화가 심한 바이너리에서는 정확도가 다소 하락하는 한계가 있습니다.
- 향후에는 다양한 아키텍처와 난독화 환경에서의 내성을 강화하고, 대규모 바이너리 분석의 효율을 높이는 방향으로 연구가 필요합니다.
6. 내 생각/우리 팀 프로젝트와의 연관성, 토론거리 등
우리 팀이 진행하는 1-day 취약점 자동 분석 도구 개발에 있어, BinXray의 패치 시그니처 추출 및 비교 방법은 함수 diffing, 자동 패턴화, 웹 기반 시각화 등 다양한 모듈에 바로 적용할 수 있습니다.
특히, 소스코드 없이 바이너리만으로 신속하게 취약점 존재 여부를 판별하는 과정은
실제 보안 실무에서도 매우 유용할 것입니다.
토론거리로는 LLM 등 최신 인공지능 기술을 결합해
패치 시그니처의 의미론적 분석을 자동화할 수 있을지,
그리고 우리 도구만의 차별화된 사용자 경험(UX)을 어떻게 설계할지
함께 고민해보고 싶습니다.
