해당 자료는 바킹독의 실전 알고리즘을 참고하여 작성하였습니다 !
배열
배열 -> 메모리 상에 원소를 연속하게 배치한 자료구조
원래 C++에서는 int arr[10];으로 배열을 선언한 뒤에는 arr의 길이를 변경하는 것 x
하지만 자료구조로써의 배열에서는 길이를 마음대로 늘리거나 줄일 수 있다고 가정하겠음.
성질로는
1. O(1)에 k번째 원소를 확인/변경 가능
-> 메모리 상에 연속하게 배치한 자료구조이기 때문에 k번째 원소의 위치를 바로 계산할 수 있음. 시작 주소에서 k칸 만큼 오른쪽으로 가면 되기 때문.
2. 추가적으로 소모되는 overhead가 거의 없음
-> 메모리 상 데이터들이 붙어있어 spatial locality가 높다고 말할 수 있음.
3. Cache hit rate가 높음
4. 메모리 상에 연속한 구간을 잡아야 해서 할당에 제약이 걸림
기능으론
**- 임의의 위치에 있는 원소를 확인/변경 -> O(1)
-
원소를 끝에 추가 -> O(1)
-
마지막 원소를 제거 -> O(1)
-
임의의 위치에 원소를 추가 -> O(N)**
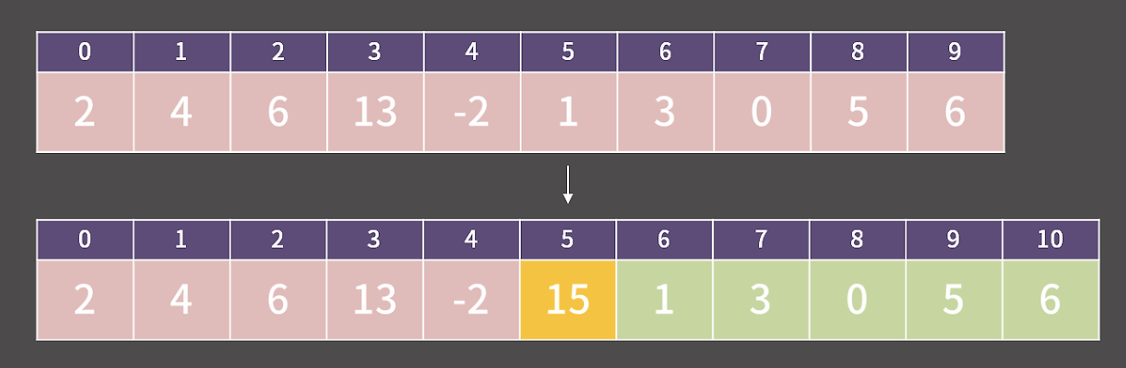 5번에 15를 추가하는데, 5번 이후의 원소들은 전부 한 칸씩 밀어야하기 떄문에 O(N)이 필요하게 됨. 추가하는 위치가 끝에 가까울수록 시간을 줄어들고, 앞에 가까울수록 시간을 늘어날테지만 평균적으로 N/2개를 밀어야하므로, O(N)이라 해도 무방 !
5번에 15를 추가하는데, 5번 이후의 원소들은 전부 한 칸씩 밀어야하기 떄문에 O(N)이 필요하게 됨. 추가하는 위치가 끝에 가까울수록 시간을 줄어들고, 앞에 가까울수록 시간을 늘어날테지만 평균적으로 N/2개를 밀어야하므로, O(N)이라 해도 무방 ! -
임의의 위치에 있는 원소를 제거 -> O(N)
마찬가지로 만약 2번 원소를 제거했다고 가정하면, 그 이후에 있던 모든 원소들을 한 칸씩 땡겨와야하기 때문에 O(N)이라 할 수 있음.
물론 그냥 다 내버려두고 2번 원소만 비워두면 안되냐고 생각할 수 있으나, 더 이상 메모리 상에 원소가 연속해서 존재한다는 배열의 정의에 위배되고, k번째 원소를 O(1)에 찾는 것도 불가능해지기 때문.
즉 정리하자면,
임의의 위치에 있는 원소를 확인/변경 -> O(1)
원소를 끝에 추가 -> O(1)
마지막 원소를 제거 -> O(1)
임의의 위치에 원소를 추가/제거 -> O(N)
연결리스트
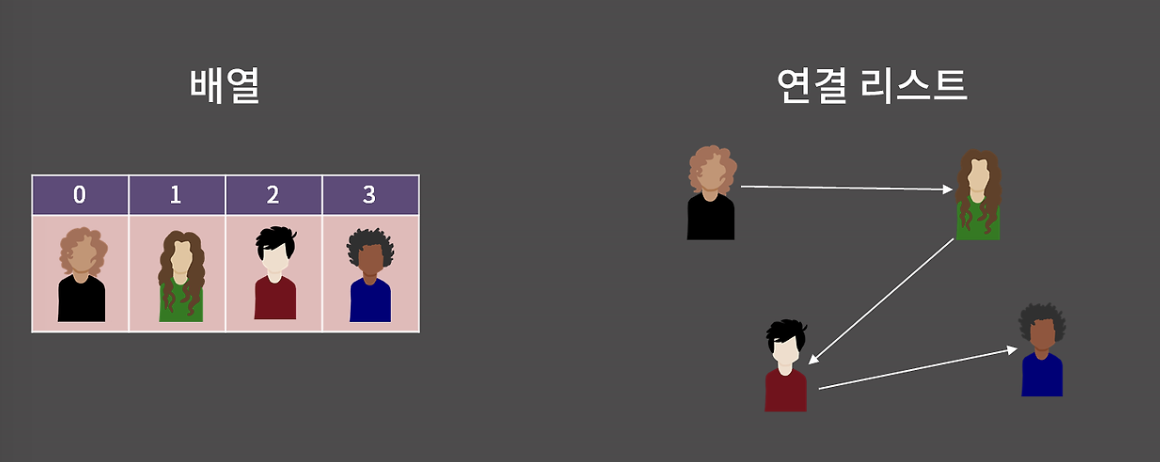
연결리스트: 원소들을 저장할 때 그 다음 원소가 있는 위치를 포함시키는 방식으로 저장하는 자료구조
실생활의 예시를 들어본다고 할 때, 학생 4명을 저장한다고 하면,
배열: 4칸짜리 배열을 만들고 4명을 저장하면 됨
그러나 연결리스트의 경우,
1번 학생은 2번 학생을 기억하고, 2번을 3번을, 3번을 4번을 기억하는 것이다.
성질로는
1. k번째 원소를 확인/변경하기 위해서 O(k)가 필요
뭔가 의아할 수 있으나, 연결리스트의 구조 상 어쩔 수 없음 !
 해당 사진의 3번째 원소인 72를 찾고 있다면 3을 거쳐 13, 13을 거쳐 72로 가야하기 때문.
해당 사진의 3번째 원소인 72를 찾고 있다면 3을 거쳐 13, 13을 거쳐 72로 가야하기 때문.
이렇게 가지 않고서야 어디 있는지 알 수 있는 방법이 없음. 배열과 달리 원소가 물리적으로 연속해서 존재하고 있지 않기 때문.
2. 임의의 위치에 원소를 추가/임의 위치의 원소 제거는 O(1)
3. 원소들이 메모리 상에 연속해 있지 않아 cache hit rate가 낮지만 할당이 다소 쉬움
배열 vs 연결리스트
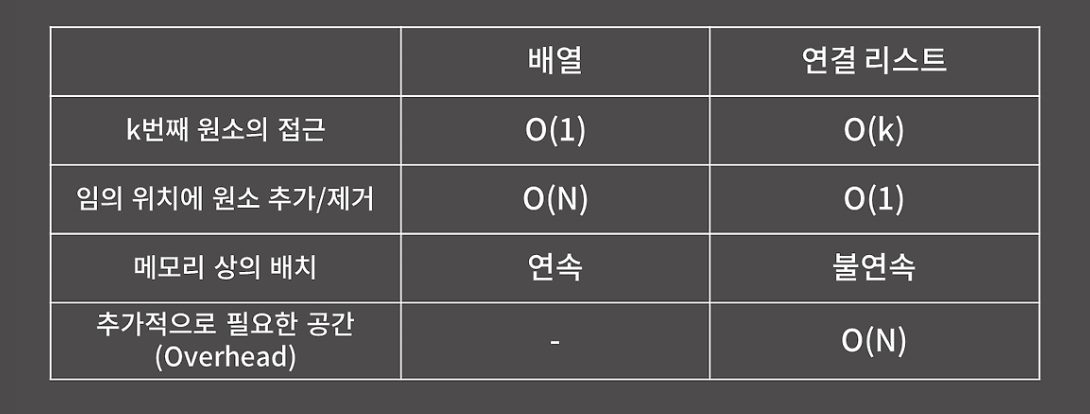
두 자료구조 모두 메모리 상에 원소를 놓는 방법을 다르더라도 원소들 사이의 선후 관계가 일대일로 정의됨. -> 선형 자료구조
참고로 비선형 자료구조로는 트리, 그래프, 해쉬 등이 있음
암튼 둘 다 선형 자료구조이기 때문에 자주 비교되는데 크게 저 4가지를 말할 수 있음
1. k번째 원소의 접근은 배열의 경우 O(1)이고, 연결리스트의 경우 O(N).
배열과 다르게 연결 리스트는 임의의 위치에 있는 원소로 가기 위해서는 그 위치에 도달할 때까지 첫번째부터 순차적으로 방문해야함. 분명 모든 원소들은 메모리 어딘가에 있을테지만, 우리는 그 중에서 첫번째 원소의 주소만 알고 있기 때문. 따라서 k번째 원소를 보기 위해서는 O(k)만큼의 시간이 필요하지만 전체 N개의 원소가 있다고 가정하면 평균적으로 N/2의 시간이 걸리므로 O(N)이라고 생각하면 됨.
2. 임의 위치에 원소를 추가/제거의 경우, 배열은 O(N), 연결리스트는 O(1).
사실 엄밀히 말하면 만일 3번째 원소 뒤에 20이라는 원소를 추가하고 싶다고 하면, 일단 3번째 원소까지는 찾아간 뒤에야 추가가능한 것이긴 함. 즉, 3번째 원소를 탐색하는 시간이 제외됨.
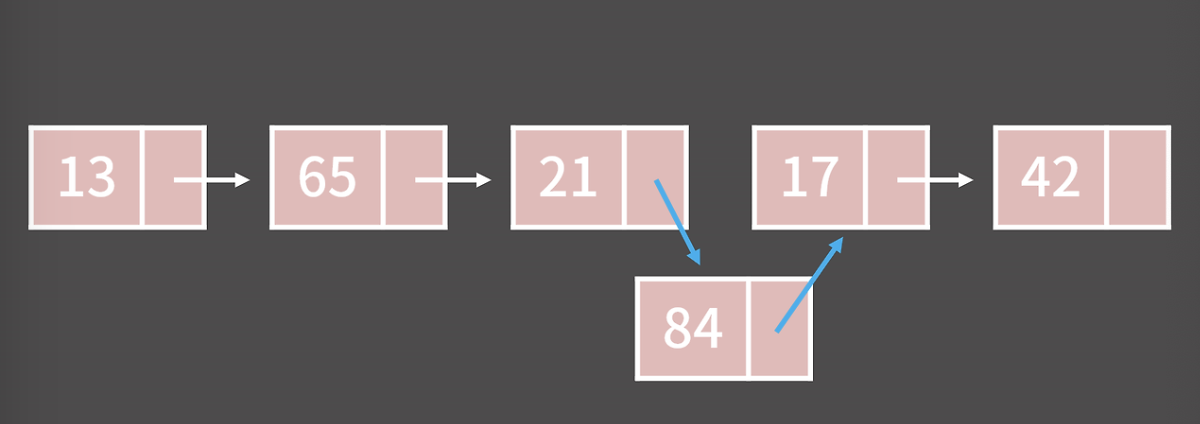 예를 들어 21 뒤에 84를 추가하고 싶다고 할 때, 배열처럼 그 뒤의 원소들을 전부 옮기는 작업을 할 필요가 없고 그냥 21과 84에서 다음 원소의 주소만 변경해주면 되기 때문.
예를 들어 21 뒤에 84를 추가하고 싶다고 할 때, 배열처럼 그 뒤의 원소들을 전부 옮기는 작업을 할 필요가 없고 그냥 21과 84에서 다음 원소의 주소만 변경해주면 되기 때문.
단, 착각하면 안되는 건, 추가하고 싶은 주소를 알고 있을 경우에만 O(1)이란 것이지, 만일 모른다면 탐색 시간이 추가로 발생함.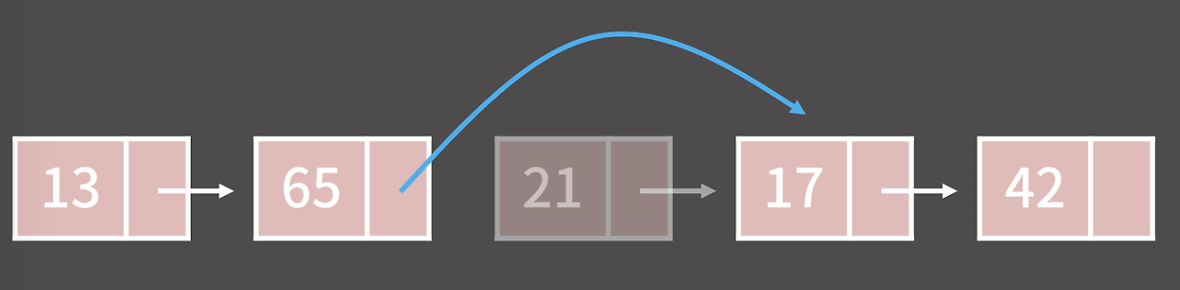 제거하는 것도 비슷하게 21을 지워본다고 하면 그냥 65에 너의 다음 원소를 21이 아닌 17이라는 것만 알려주면 끝남. 물론 21이 들어있는 원소는 memory leak을 방지하기 위해 없애줄 필요가 있음.
제거하는 것도 비슷하게 21을 지워본다고 하면 그냥 65에 너의 다음 원소를 21이 아닌 17이라는 것만 알려주면 끝남. 물론 21이 들어있는 원소는 memory leak을 방지하기 위해 없애줄 필요가 있음.
3. 메모리 상의 배치는 배열은 연속적, 연결리스트의 경우 불연속.
4. 추가적으로 필요한 경우, 즉 overhead는 배열은 데이터만 딱딱 저장하면 될 뿐 추가적으로 필요한 경우가 없음. 굳이 따지자면 길이 정보를 저장할 int 1개가 필요할 수 있지만 이건 미미하기 때문에 굳이 신경 쓸 필요 x. 다만 연결 리스트의 경우 각 원소가 다음 원소, 혹은 이전과 다음 원소의 주소값을 가지고 있어야 하기 때문에 32비트 컴퓨터라면 주소값이 32비트 단위이므로 4N, 64비트 컴퓨터는 8N, 즉 N에 비례하는 만큼의 메모리를 추가로 쓰게 됨.
