HashTable(해시테이블)이란?
- 해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나
- 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다.
- Key값으로 데이터를 찾을 때 해시 함수를 1번만 수행하면 되므로 매우 빠르게 데이터를 저장/삭제/조회할 수 있다.
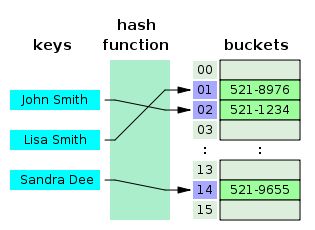
- 해시 테이블은 각각의 Key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색하게 된다. 여기서 실제 값이 저장되는 장소를 버킷 또는 슬롯이라고 한다.
장점
- 적은 리소스로 많은 데이터를 효율적으로 관리할 수 있다.
- 예) HDD, Cloud에 존재하는 많은 데이터들을 유한한 개의 해시(Hash)값으로 매핑하여 작은 크기의 캐쉬 메모리로 프로세스 관리가 가능하다.
- 배열의 인덱스(index)를 사용해서 검색, 삽입, 삭제가 빠르다. (평균 시간복잡도 : O(1))
- 인덱스를 사용해서 배열의 검색이 빠르다는 것은 당연한 소리이다. 하지만 삽입, 삭제는 왜 O(1)인가?
- 여기서의 인덱스는 데이터만의 고유한 위치이기 때문에 만약 삽입이나 삭제를 한다고 해도 다른 데이터로 채울 필요가 없다. 즉, 삽입이나 삭제할 때 데이터를 이동할 필요가 없기 때문이다.
- 키(key)와 해시값(Hash)이 연관성이 없어 보안에도 많이 사용된다.
- 데이터 캐싱(Data Caching)에 많이 사용된다.
- get(key), put(key)에 캐시 로직을 추가하면 자주 hit하는 데이터를 바로 찾을 수 있다.
- 중복을 제거하는데 유용하다.
단점
- 충돌
- 공간 복잡도가 커진다.
- 순서가 있는 배열에는 어울리지 않는다.
- 해시 함수 의존도가 높아진다.
시간 복잡도
해시테이블의 평균 시간복잡도는 O(1)
키값이 배열의 인덱스로 변환되기 때문에 탐색,저장,삭제가 빠르다. 평균 시간 복잡도가 O(1)이다.
- 평균 시작 복잡도인 이유는 collision 때문이다.
| 평균적인 경우 | 최악의 경우 | |
|---|---|---|
| 탐색 | O(1) | O(N) |
| 삽입 | O(1) | O(N) |
| 삭제 | O(1) | O(N) |
해시 테이블(Hash Table) VS 해시 맵(Hash Map)
Java에서 HashTable과 HashMap의 차이는 동기화 지원 여부이다. 키(Key)에 대한 해시(Hash)값을 사용하여 값을 저장, 조회 하는 것은 동일하다.
해시 테이블(Hash Table)
병렬 처리를 할 때 (동기화를 고려해야하는 상황)
Null 값을 허용하지 않는다.
해시 맵(Hash Map)
병렬 처리를 하지 않을 때 (동기화를 고려하지 않는 상황)
Null 값을 허용한다.
Hash 함수(해시 함수)
고유한 인덱스 값을 설정
대표적인 해시 함수
- Division Method
: 나눗셈을 이용하는 방법으로 입력값을 테이블의 크기로 나누어 계산한다.( 주소 = 입력값 % 테이블의 크기) 테이블의 크기를 소수로 정하고 2의 제곱수와 먼 값을 사용해야 효과가 좋다고 알려져 있다. - Digit Folding
: 각 Key의 문자열을 ASCII 코드로 바꾸고 값을 합한 데이터를 테이블 내의 주소로 사용하는 방법이다. - Multiplication Method
: 숫자로 된 Key값 K와 0과 1사이의 실수 A, 보통 2의 제곱수인 m을 사용하여 다음과 같은 계산을 해준다. h(k)=(kAmod1) × m - Univeral Hashing
: 다수의 해시함수를 만들어 집합 H에 넣어두고, 무작위로 해시함수를 선택해 해시값을 만드는 기법이다.
Reference
