프로세스 생명주기
프로세스 상태 변화 = 프로세스 생명주기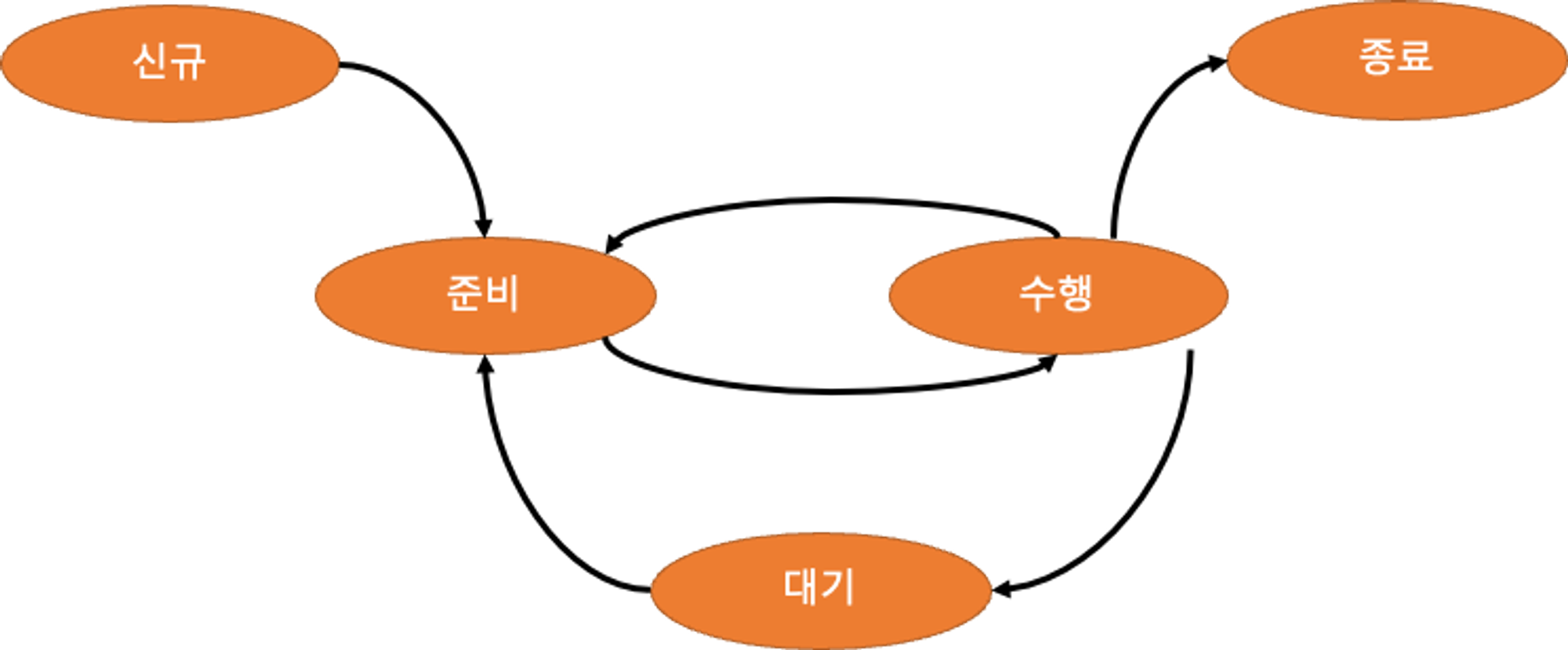
프로세스 상태(Status)
- 신규(New):
- 프로세스가 이제 막 메인메모리에 올라온 상태
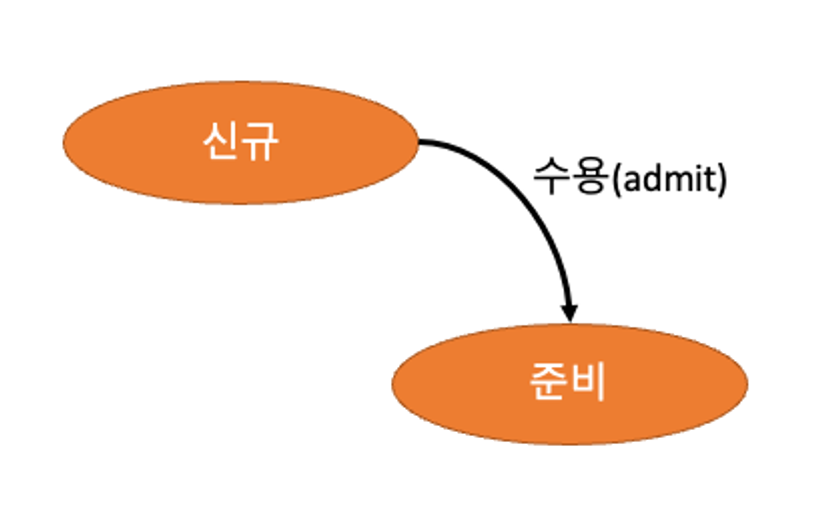
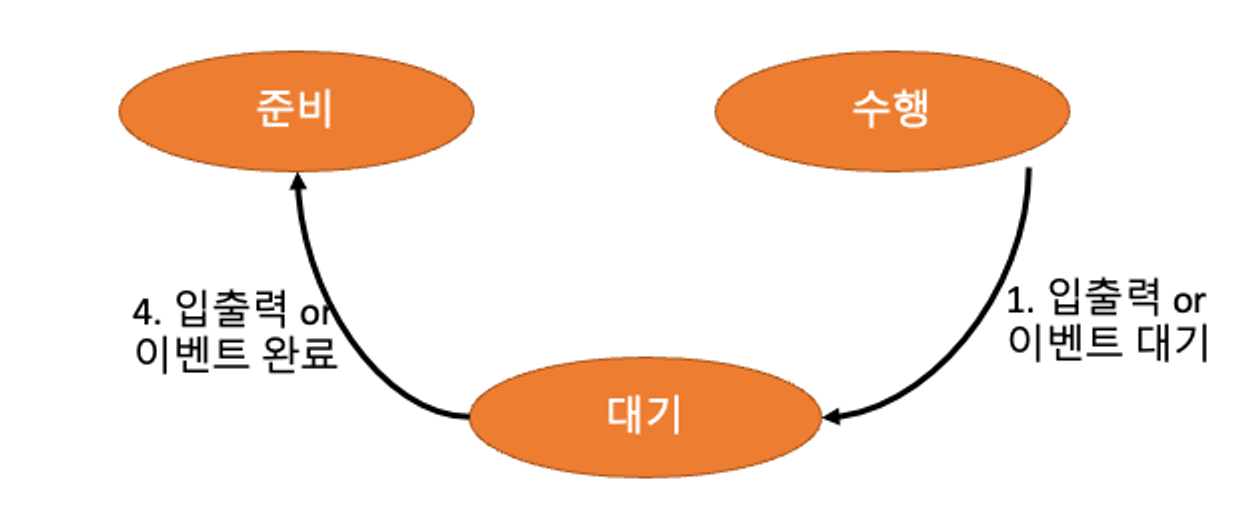
- 준비(Ready):
- 변수 초기화 등 기초 준비작업을 모두 끝내고 실행을 할 수 있는 상태
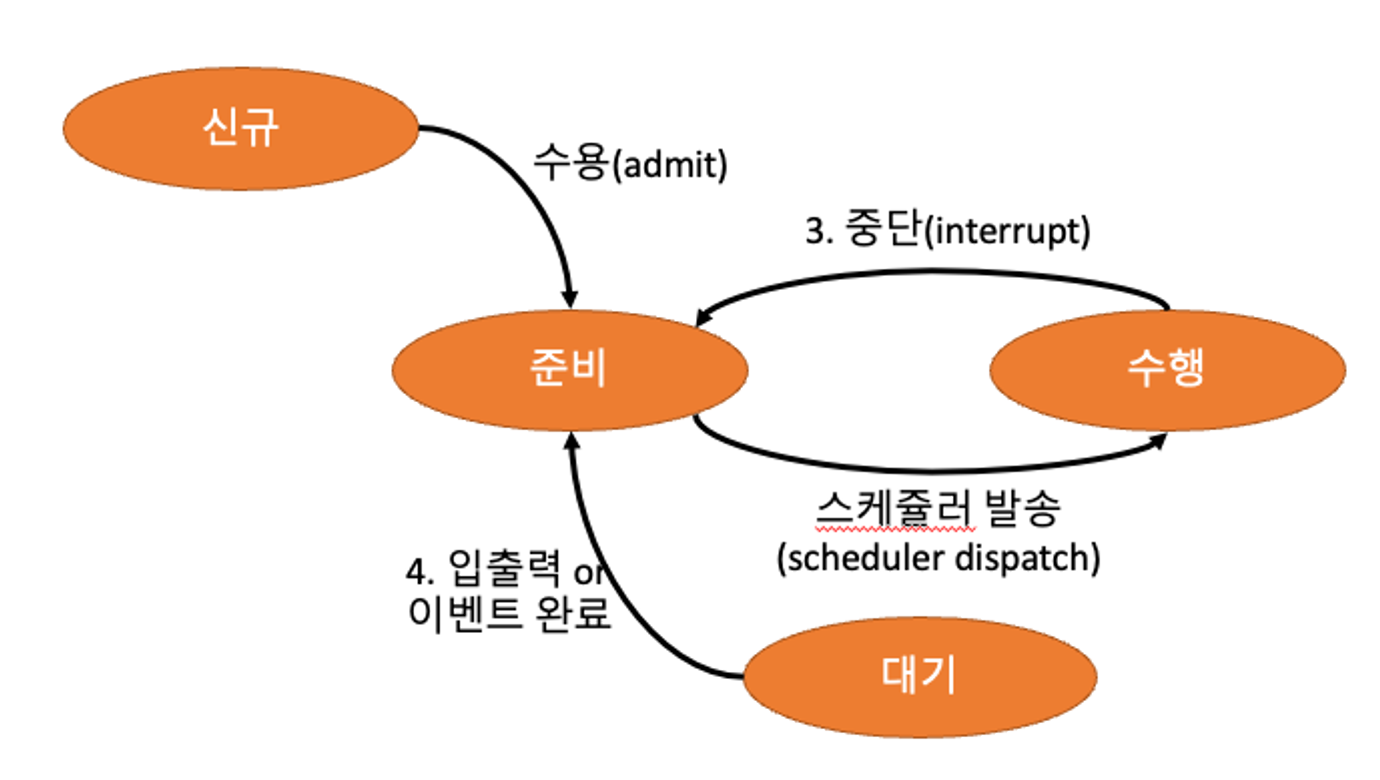
- 수행(Running):
- CPU가 실제로 프로세스를 수행하고 있는 상태
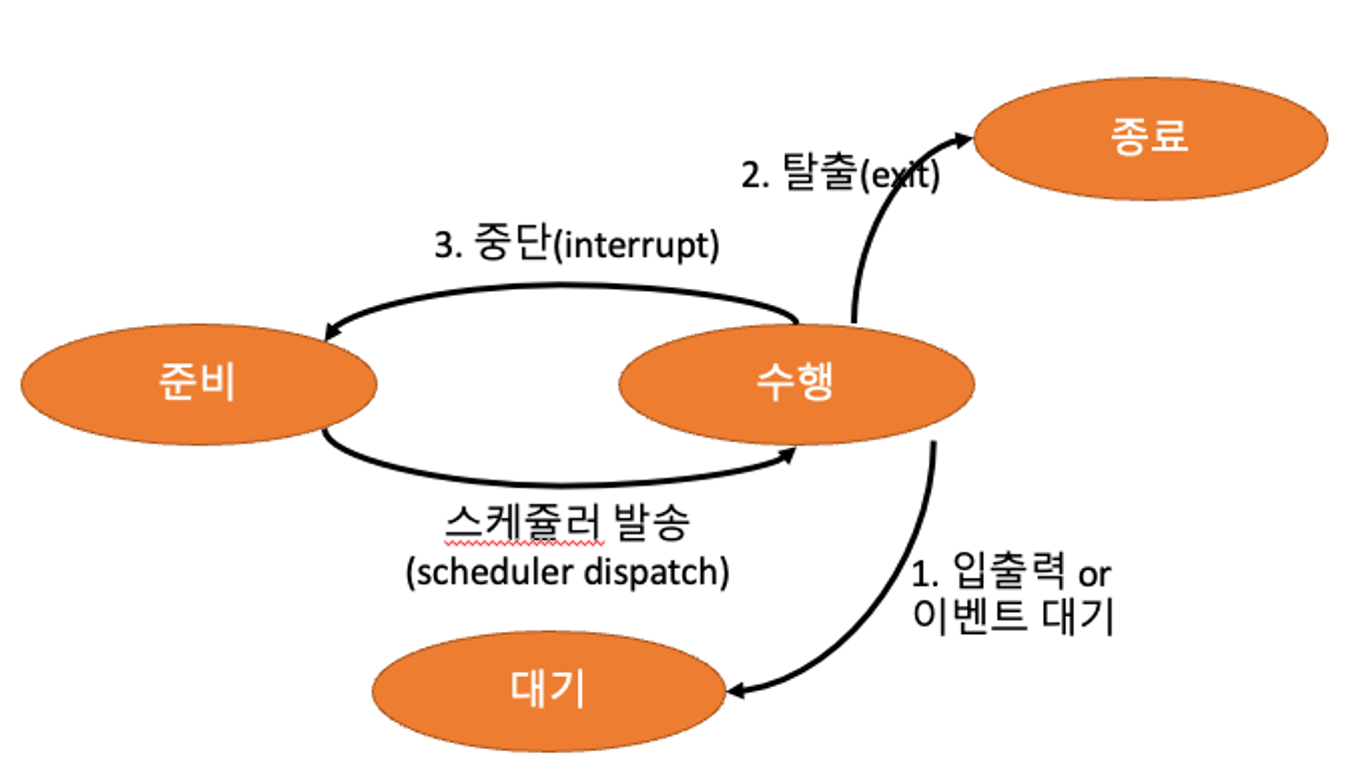
- 대기(Waiting):
-프로세스 도중에 I/O 작업이 필요하여 I/O 작업을 수행하는 상태
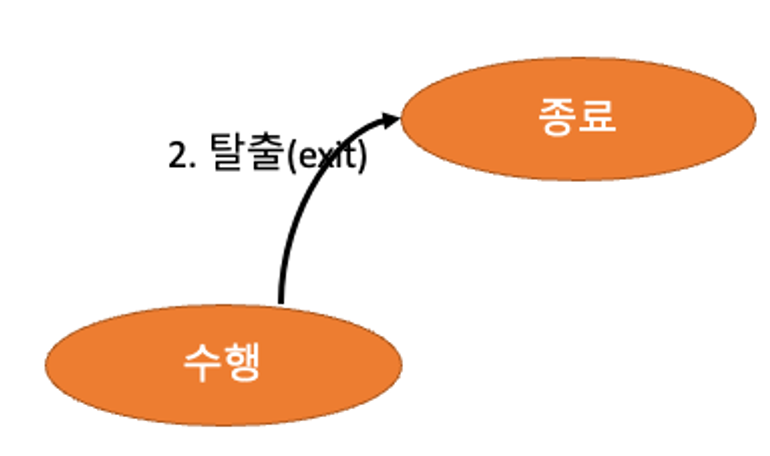
- 종료(Terminated):
- 최종적으로 프로세스가 종료된 상태
대기 큐 (Waiting Queue)
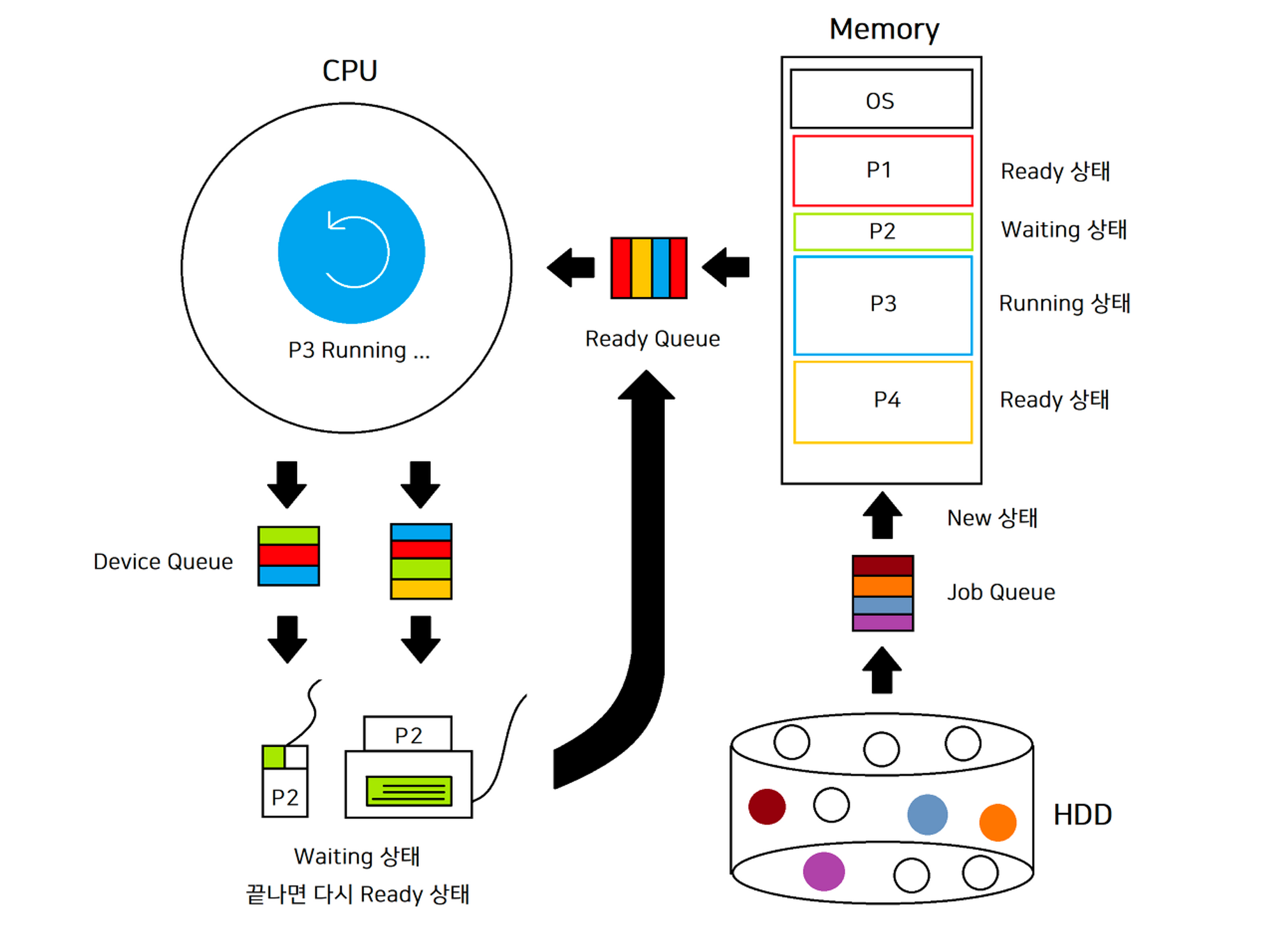
- Job Queue
- 메인 메모리가 가득 찼거나 CPU가 다른 작업을 수행 중이라 HDD의 프로그램이 대기하는 곳
- Ready Queue
- 메인 메모리에 올라온 프로세스들이 실행을 위해 대기하는 곳
- Device Queue
- I/O 장치들의 대기 큐
- Terminated는 큐가 없다!
스케쥴링
-
Job Schedular
- Job Queue의 프로그램들을 어떤 순서로 메모리에 올릴 것인지 결정
- Long Term Scheduler
- 자주 일어나지 않고 긴 간격으로(수분 ~ 수십분) 동작하는 스케줄러
-
CPU Schedular
- Ready Queue의 프로세스들을 어떤 순서로 서비스 할 것인지에 대한 스케줄러
- 모든 스케줄링 중에서 CPU 스케줄링이 가장 중요
- Short Term Scheduler
- 1초에도 수십번에서 많게는 수백번도 동작하는 스케줄러
-
Device Schedular
- Device Queue의 프로세스들을 어떤 순서로 I/O 장치를 이용하게 할 것인지에 대한 스케줄러
주-보조 교환 (Swapping)
- 서버와 같이 여러 사용자가 하나의 메모리를 공유하는 경우에 만약 한 사용자가 자리를 비우면 그 사용자가 돌아올 때 까지 해당 프로세스에 메모리를 할당할 이유가 없다
- PCB(Process Control Block)의 CPU Time등을 확인해서 오랫동안 동작이 없는 프로세스는 잠시 HDD로 내려놓고, 다른 프로세스를 실행하거나 기존 프로세스에 메모리를 더 할당하는 등 메모리를 더 효율적으로 활용하는 방법
- 그러다가 동작없던 프로세스 사용자가 돌아와서 작업을 수행하면 다시 HDD에서 메모리로 프로세스를 올린다
- Swap Out
- 메모리에서 HDD로 내리는 작업
- Swap In
- HDD에서 다시 메모리로 올리는 작업
- Backing Store / Swap Device
- 임시 메모리의 목적으로 사용되는 HDD 공간
- Midium Term Scheduler
- Short Term Scheduling 보다는 적게 일어나지만 Long Term Scheduling 보다는 자주 일어나는 스케쥴러
문맥 교환 (Context Switching)
- Context Switching
- CPU 시간공유 시스템의 경우 일정 시간이 지나면 기존 프로세스를 준비 상태로 만들고 다른 프로세스를 수행 상태로 만들어서 실행
- Scheduler
- Context Switching을 전문적으로 담당하는 스케줄러는 CPU 스케줄러
- Dispatcher
- 만일 프로세스 A의 코드 중 100번 라인까지 실행했고 작업 중에 10개의 데이터를 레지스터에 저장했었다면, 스위치할 때 이 정보들을 보존해야 A의 차례가 돌아왔을 때 이전에 수행하던 작업이 끊기지 않고 수행될 수 있다
- 때문에 프로세스 A를 수행하다가 B로 넘어가면 그러한 정보를 저장하고, 다시 A의 차례가 왔을 때, 정보를 다시 꺼내서 PC, SP, Register 등에 할당한다
- 이러한 작업을 수행하는 프로그램을 Dispatcher라고 한다
프로세스 메모리
프로세스의 메모리 구조
- 메모리 사용 용도
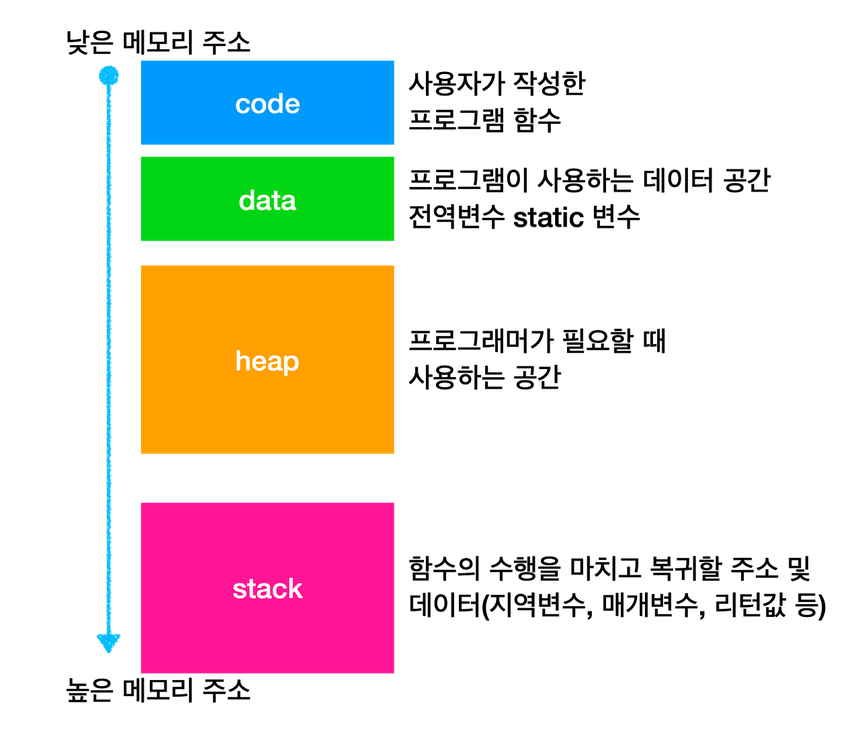
-
Code 영역
- 실행할 프로그램의 코드 저장
- CPU는 이 영역에서 명령어를 하나씩 가져와 처리
-
Data 영역
- 전역변수와 정적변수 저장
- 프로그램이 시작될 때 할당되어 프로그램 종료 시 소멸
- BSS 영역
- 초기화 되지 않은 전역변수 저장
-
Stack 영역
- 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터(지역변수, 매개변수, 리턴값 등)를 임시로 저장하는 공간
- 함수 호출시 기록하고 함수의 수행이 완료되면 소멸
- LIFO(Last In First Out) 방법으로 저장/출력 한다
- 컴파일 시 stack 영역의 크기가 결정되기 때문에 무한정 할당 불가
- 재귀함수가 반복해서 호출되거난 함수가 지역변수를 메모리를 초과할 정도로 너무 많이 가지고 있다면 stack overflow가 발생한다 (알고리즘 시험풀 때 많이 발생!)
- 위 세 영역은 컴파일 할 때 data, stack 영역의 크기를 계산해 메모리 영역을 결정
- Heap 영역
- 동적 데이터 영역
- 메모리 주소 값에 의해서만 참조되고 사용되는 영역
- 프로그램 동작 시(런타임)에 크기가 결정
커널 프로세스의 메모리
커널
- 커널은 대부분의 운영 체제(OS)의 주요 구성 요소이며 컴퓨터 하드웨어와 프로세스를 잇는 핵심 인터페이스이다
- Code 영역
- 시스템 콜, 중단(인터럽트) 처리 코드
- CPU, 메모리 등 자원 관리를 위한 코드
- 편리한 인터페이스 제공을 위한 코드
- Data 영역
- CPU, Memory 등 하드웨어 자원을 관리하기 위한 자료구조가 저장
- PCB(Process Controll Block) 자료구조가 저장
- PCB는 각 프로세스에 대한 다양한 정보를 담고 있는 데이터로써 사람으로 따지면 주민등록증과 유사하다.
- Stack 영역
- 각 Process의 커널 스택을 저장
- 프로세스는 함수 호출시 자신의 복귀 주소를 저장하지만, 커널은 커널 내의 주소가 된다.
- 각각의 프로세스마다 별도의 스택을 두어 관리한다.
- 각 Process의 커널 스택을 저장

The secret of getting ahead is getting started.