Redis 캐시로 사용하기
캐시란?
데이터의 원래 소스보다 더 빠르고 효율적으로 액세스할 수 있는 임시 데이터 저장소이다.
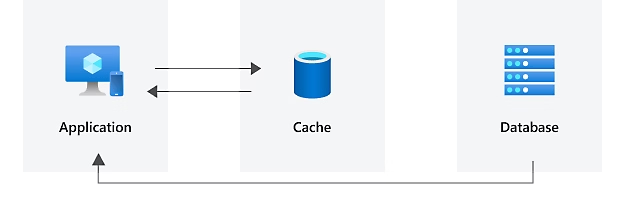
- 캐시가 유용하게 사용되려면 원본보다 빠른 접근 속도가 필요하다.
- 같은 데이터를 반복적으로 액세스할 때 캐시를 사용하는 것이 좋다. 즉, 데이터의 재사용 횟수가 한 번 이상이어야 캐시가 의미가 있게 된다.
- 잘 변하지 않는 데이터일수록 캐시가 보다 효율적이다.
Redis
redis는 캐시로 활용하기 좋은 솔루션이다.
장점
간편한 사용
단순하게 key-value 형태로 저장할 수 있기 때문에 어떤 데이터라도 쉽게 저장할 수 있다.
빠른 성능
In-memory 데이터 저장소로, 평균 작업속도는 1ms 미만으로, 초당 수백만 건의 작업이 가능하다. 때문에 latency가 감소하고 처리량도 증가하게 된다.
캐싱 전략(Caching Strategies)
Redis를 캐시로 사용할 때 어떻게 배치하는지가 시스템의 성능에 큰 영향을 끼친다. 이를 캐싱 전략이라고도 하며, 캐싱 전략은 데이터의 유형과 데이터에 대한 액세스 패턴을 고려해서 선택해야한다.
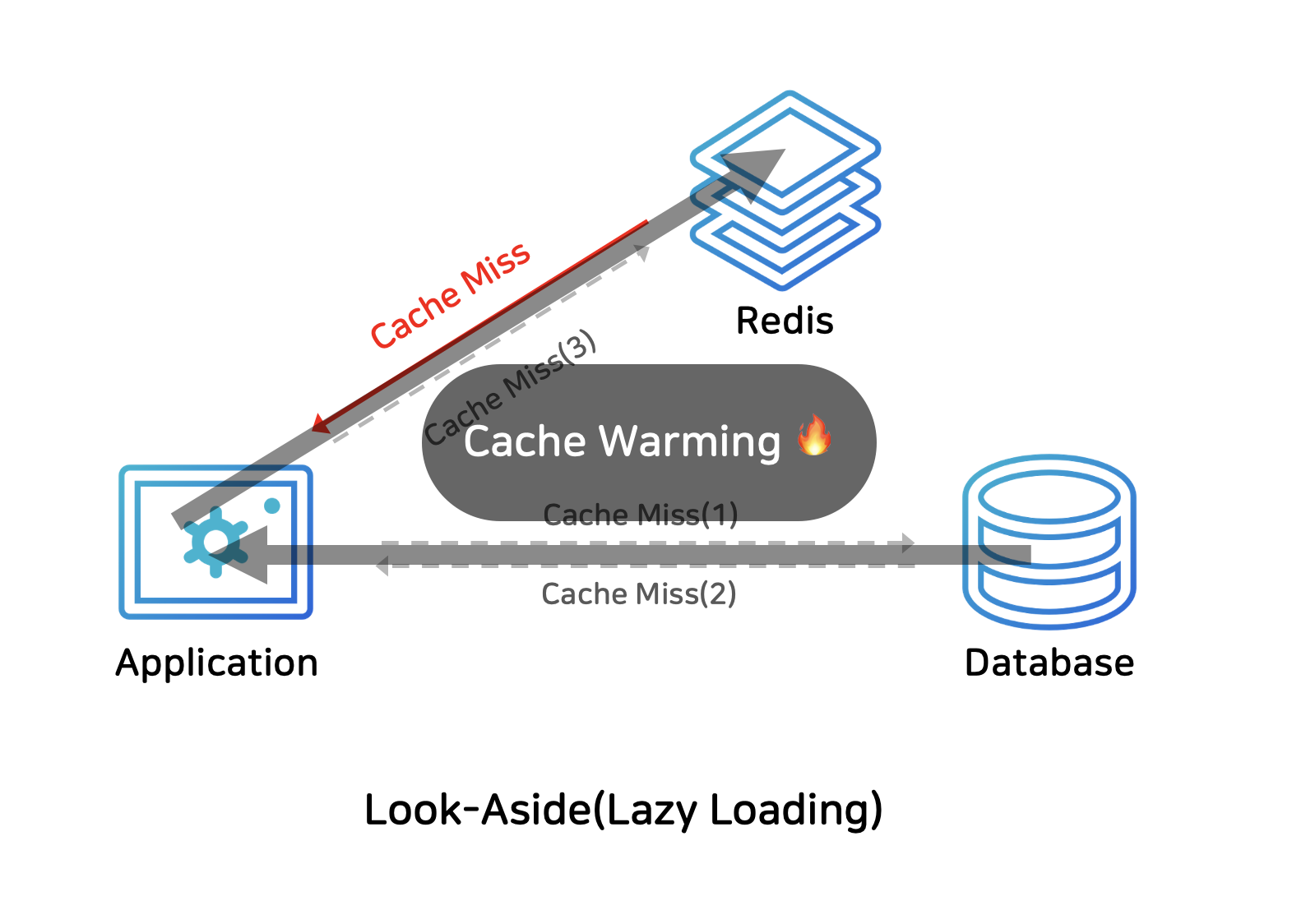
Look-Aside(Lazy Loading)
애플리케이션에서 데이터를 읽는 횟수가 많을 때 사용하는 전략이다. Redis를 캐시로 쓸 때 가장 일반적으로 사용하는 전략이다.
애플리케이션은 데이터를 찾을 때 캐시를 먼저 확인한다. 캐시에 데이터가 있으면 캐시에서 데이터를 가져오는 작업을 진행한다. 만약 Redis에 찾는 데이터가 없다면 직접 db에 접근해서 데이터를 가져온 뒤 다시 Redis에 저장하는 과정을 거친다. 따라서 캐시는 찾는 데이터가 없을 때에만 입력되기 때문에 이를 Lazy Loading이라고도 부른다.
만약 Redis가 접근이 불가하더라도 db에 접근하여 데이터를 가져올 수 있다. 단, 캐시의 connection이 많았다면 그 connection이 db로 몰리기 때문에 부하가 증가할 수 있다.
이런 경우 캐시를 새로 투입하거나 db에만 새로운 데이터를 저장했다면 처음에 캐시 미스가 많이 발생하여 성능 저하가 올 수 있다.
이럴 때는 미리 db에서 캐시로 데이터를 밀어넣는 작업을 할 수 있는데, 이를 Cache Warming이라고 한다.
Write-Around
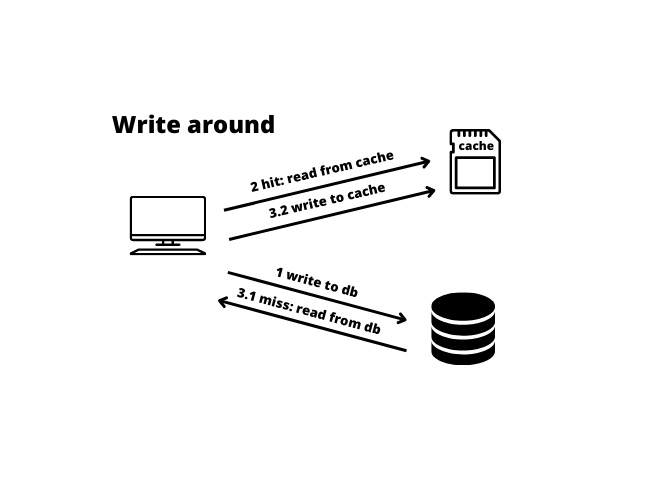
db에만 데이터를 저장한다. 캐시 미스가 발생한 경우 db에서 데이터를 끌어오게 된다.
이 경우 캐시의 데이터와 db의 데이터가 다를 수 있다는 단점이 존재한다.
Write-Through
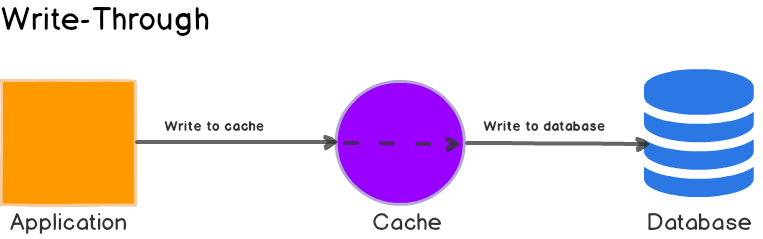
db에 데이터를 저장할 때 캐시에도 데이터를 저장하는 전략이다.
캐시는 항상 최신 데이터를 가지고 있다는 장점이 있지만, 데이터를 저장할 때마다 2번의 단계를 거쳐야하기 때문에 상대적으로 느리다고 볼 수 있다.
게다가 저장한 데이터가 재사용되지 않을 수 있는데 무조건 캐시에 넣어버리기 때문에 일종의 리소스 낭비라고도 볼 수 있다.
따라서 이렇게 데이터를 저장할 때는 몇 분, 몇 시간동안만 데이터를 저장하겠다는 의미인 expire time을 설정해주는 것이 좋다. 이 값을 어떻게 관리하는지에 따라 장애 포인트가 될 수도 있다.
Redis의 데이터 타입
Redis는 자체적으로 많은 자료구조를 제공하고 있다.
- String: 가장 기본적인 데이터 타입. set command를 이용해 저장되는 데이터는 모두 String 형태로 저장
- Bitmap: String의 변형이라고 볼 수 있고, bit 단위의 연산이 가능
- List: 데이터를 순서대로 저장, Queue로 사용하기 적절.
- Hash: 하나의 key 안에 여러 개의 field와 value 쌍으로 데이터를 저장
- Set: 중복되지 않은 문자열의 집합
- Sorted Set: Set과 동일하게 중복되지 않은 값을 저장하며, 모든 값은 score라는 숫자를 통해 정렬. 데이터가 저장될 때부터 score 순으로 정렬되며 score가 같을 때에는 사전 순으로 정렬되어 저장
- HyperLogLog: 굉장히 많은 데이터를 다룰 때 주로 사용. 중복되지 않은 값의 개수를 셀 때 사용
- Stream: log를 저장하기 가장 좋은 자료구조
Counting
String
key 하나를 만들어서 counting이 필요한 상황마다 증가시킬 수 있다. 이는 String의 Increment 함수를 활용하여 구현할 수 있다.
Bit
이를 활용하면 데이터 저장공간을 절약하며 counting 할 수 있다.
이 방법을 활용하려면 모든 데이터를 정수로 표현할 수 있어야 한다.
HyperLogLogs
Set과 비슷하지만 저장되는 용량이 12KB로 고정되어 매우 작다.
단, 저장된 데이터는 다시 확인할 수 없는데 경우에 따라 데이터를 보호하는 목적으로도 활용할 수 있다.
Messaging
List
Blocking 기능을 이용해 Event Queue로 사용할 수 있다.
만약 클라이언트 A가 queue에서 데이터를 꺼내오려고 하지만 데이터가 없어 대기를 하고 있다면, 클라이언트 B가 데이터를 넣었을 때 값을 바로 확인할 수 있다.
또 LPUSHX나 RPUSHX를 사용하면 키가 있을 때만 데이터를 저장할 수 있는데 이를 활용하면 비효율적인 데이터 이동을 막을 수 있다. 인스타그램, 페이스북, 트위터 같은 SNS에는 각 유저별로 타임라인이 존재하고, 타임라인에 팔로우한 사람들의 데이터가 제공된다. 트위터에서는 이 타임라인의 데이터를 보여주기 위해 redis의 캐싱을 활용하는데 이때 RPUSHX를 사용한다. 이를 활용해 자주 사용하는 유저의 타임라인 데이터만 캐싱해놓을 수 있으며, 자주 사용하지 않는 유저의 경우 캐싱 key 자체가 존재하지 않기 때문에 해당 유저들의 데이터를 미리 쌓아놓는 비효율적인 과정을 방지한다.
Stream
모든 데이터는 append-only 방식으로 저장되며 중간에 데이터가 바뀌지 않는다.
Stream은 Kafka의 개념을 많이 사용하여, message broker가 필요할 때 Kafka를 대체하여 간단하게 사용할 수 있다.
Redis에서의 데이터 영구 저장
Redis Persistence
Redis는 In-memory 데이터 스토어로 서버나 redis 인스턴스가 재시작되면 모든 데이터가 유실된다.
복제 기능을 사용하더라도 코드 상의 문제가 있거나 사람의 실수로 인해 문제가 생긴다면 데이터는 복원할 수 없다. 따라서 Redis를 캐시 이외의 용도로 사용한다면 적절한 데이터 백업이 필요하다.
Redis에서는 데이터를 영구적으로 저장하는 2가지 방법을 제공하고 있다.
- AOF: Append Only File
- RDB: snapshot
AOF의 경우 append only 방식이기 때문에 데이터가 추가만 되어서 일반적으로 RDB보다 파일의 용량이 커지기 때문에 주기적으로 압축하여 재작성하는 과정이 필요하다.
만약 redis를 캐시로만 사용한다면 굳이 해당 기능을 활용할 필요는 없다.
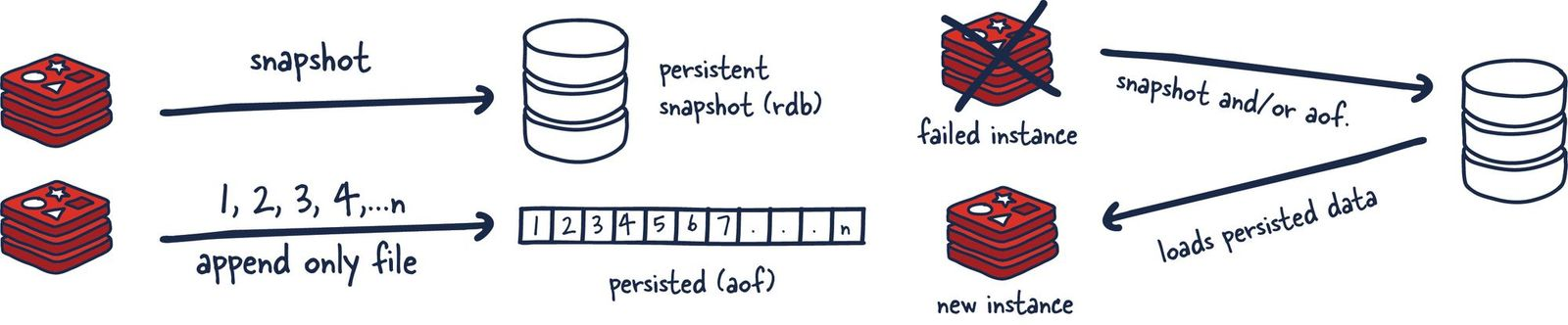
RDB
시간 단위로 파일을 자동으로 생성되게 설정할 수 있다.
백업은 필요하지만 어느 정도의 데이터 손실이 발생해도 괜찮은 경우 사용하는 것이 좋다.
AOF
파일의 크기를 기준으로 하여 압축되는 시점을 정할 수 있다.
장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우 사용하는 것이 좋다.
만약 강력한 내구성이 필요한 경우에는 RDB와 AOF를 같이 사용하는 것이 좋다.
Redis 아키텍처 선택
Replication
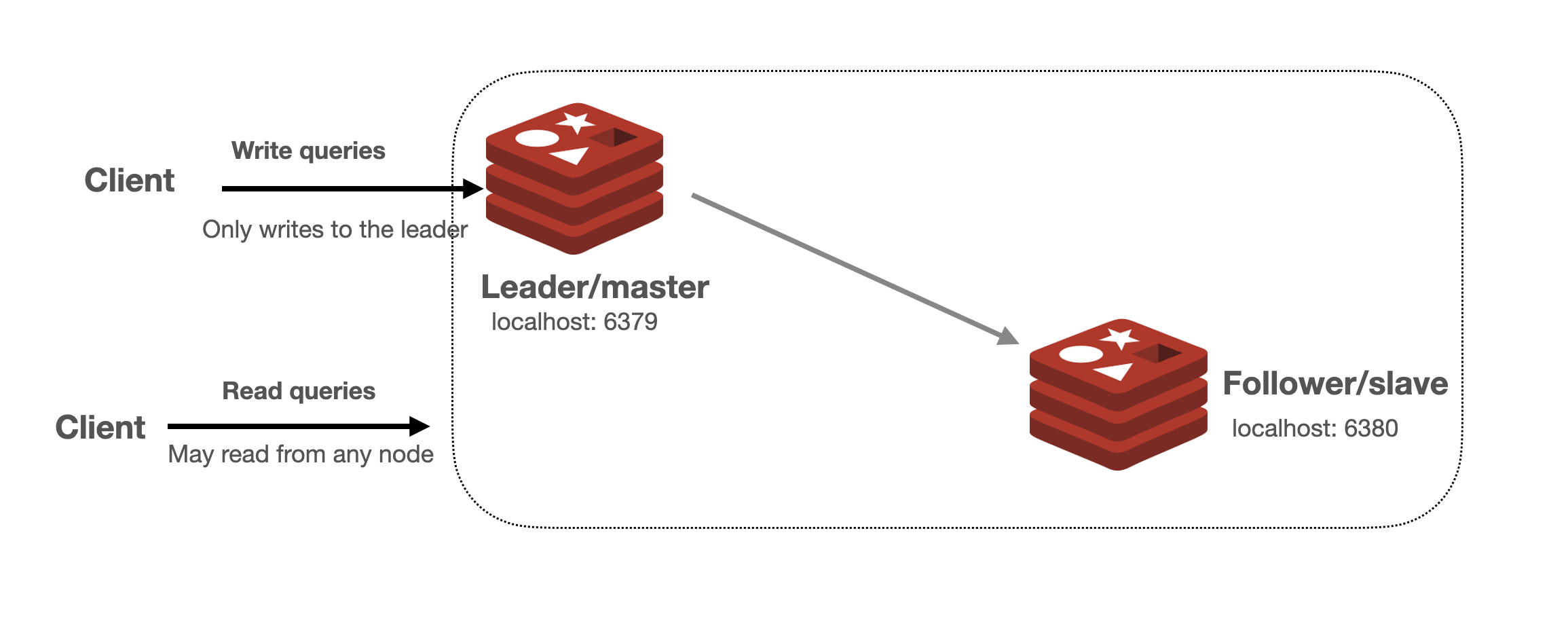
단순한 복제만 연결된 상태를 말한다. 모든 redis의 구조에서 복제는 비동기적으로 동작하는데, master에서 복제본에 데이터가 잘 전달됐는지 매번 확인하고 기다리지 않는다.
HA 기능이 없기 때문에 장애 상황 시 수동으로 복구해야하는 경우가 많다. 우선 replica에 직접 접속해서 복제를 끊어야하고 애플리케이션에서 연결 정보를 변경하고 배포하는 작업이 필요하다.
Sentinel
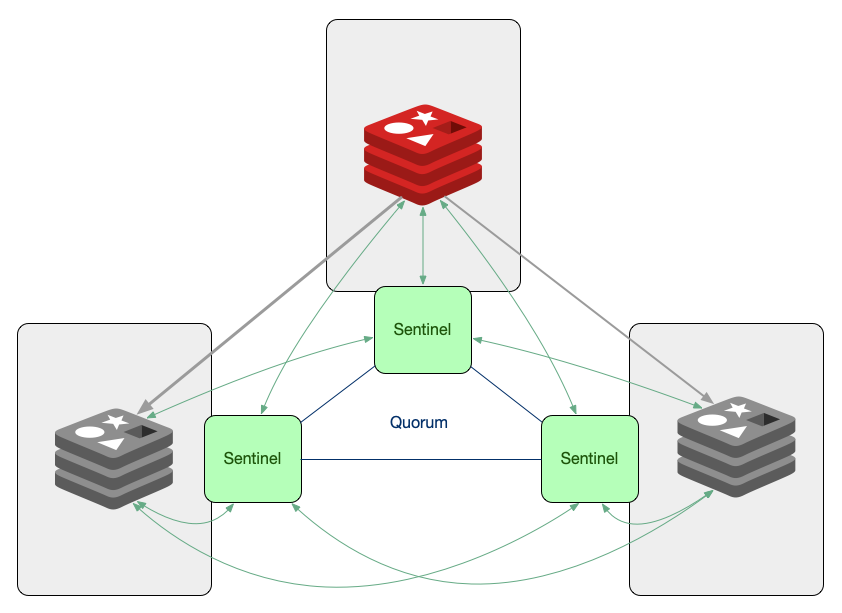
sentinel 노드는 다른 노드들을 monitoring 하는 역할을 담당한다. Master 노드가 죽으면 자동으로 페일오버(컴퓨터 서버, 시스템, 네트워크 등에서 이상이 생겼을 때 예비 시스템으로 자동전환되는 기능)를 발생시켜 기존의 replica 노드가 master 노드가 된다. 이때 애플리케이션에서는 연결 정보를 변경할 필요가 없다. 애플리케이션에서는 sentinel에 대한 정보만 알고 있으면 되고, sentinel의 노드가 바로 변경된 master 노드로 연결시켜준다.
이 구조를 사용하려면 sentinel 프로세스를 추가로 구성해야하는데 항상 3대 이상의 홀수로 존재해야 한다.
Cluster
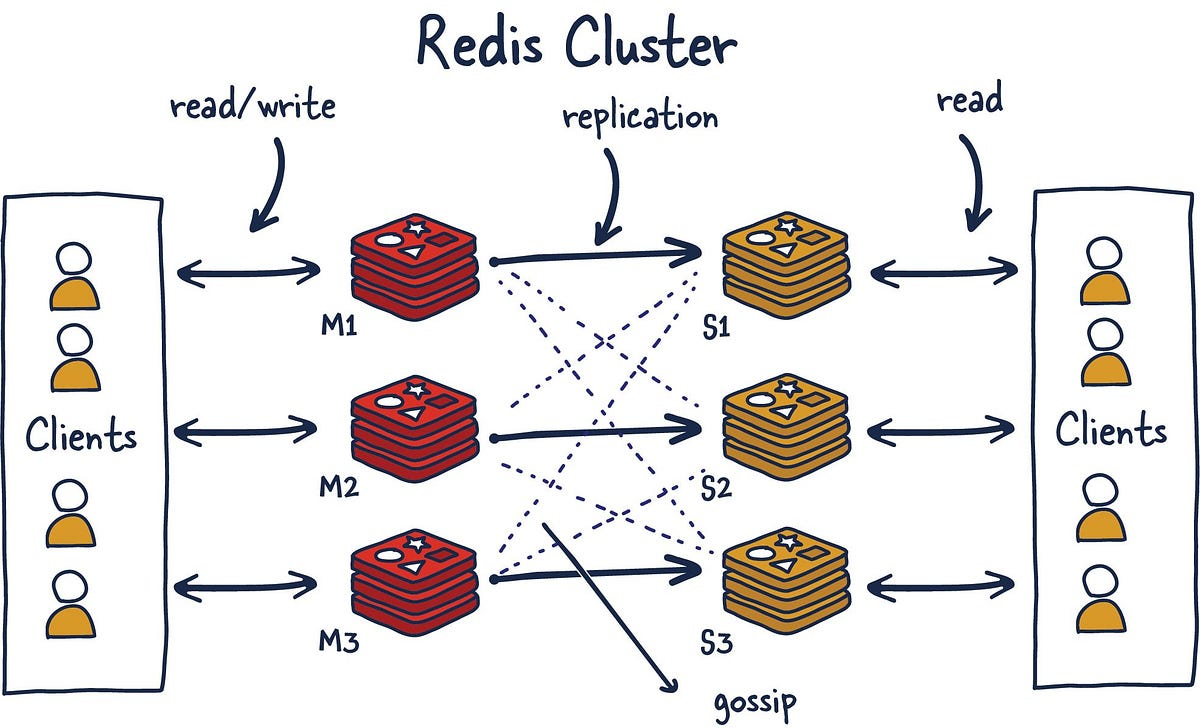
Cluster 구조에서는 데이터가 여러 master 노드에 자동으로 분할되어 저장되는 sharding 기능을 제공한다. 이 구성에서 모든 노드가 서로를 감시하고 있다가 master 노드가 비정상일 때 자동으로 페일오버를 진행한다.
최소 3대의 master 노드가 필요하며 replica 노드를 하나씩 추가하는 것이 일반적인 구조이다.
Redis 운영 팁과 장애 포인트
사용하면 안되는 커맨드
Redis는 싱글 스레드로 동작한다. 한 사용자가 오래 걸리는 요청을 한다면 나머지 사용자들은 대기하게 된다. 따라서
keys * -> scan같이 오래 걸리는 작업을 방지할 필요가 있다.
또한 Hash나 Sorted Set 같은 자료구조는 내부에 여러 item을 저장할 수 있는데, key 내부에 item의 개수가 많아질수록 성능이 저하되기 때문에 하나의 key에 100만개 이상의 데이터는 저장하지 않도록 key를 적절하게 나누는 것이 권장된다.
또한 key에 많은 데이터가 들어있을 때 key를 delete로 지우면 지우는 동안 다른 동작을 할 수 없게 된다. 때문에 del 대신 unlink를 활용하여 background로 지우는 것이 권장된다.
Cache Stampede
Look aside 패턴에서는 redis에 데이터가 없다는 응답을 받은 서버가 직접 db에 데이터를 요청하고 이를 redis에 저장하는 과정을 거친다.
TTL 값을 너무 작게 설정하게 되면 연결된 애플리케이션들이 동시에 같은 데이터를 db에 가서 찾게 되는 duplicate read가 발생한다. 또 읽은 값을 각각 redis에 write하는 duplicate write도 발생하게 된다.
이런 상황이 발생하면 불필요한 처리량이 증가하기 때문에 장애로 이어질 수 있다.
MaxMemory 값 설정
redis의 데이터를 파일로 저장할 때 fork를 통해 자식 프로세스를 생성한다. 자식 프로세스를 통해 background에서 저장하고 있지만, 원래 프로세스를 지속적으로 일반적인 요청을 처리한다. Copy-On-Write(리소스가 복제되었지만 수정되지 않은 경우에 새 리소스를 만들 필요 없이 복사본과 원본이 리소스를 공유하고, 복사본이 수정되었을 때만 새 리소스를 만드는 리소스 관리 기법)로 인해 메모리를 복사해서 사용하기 때문에 가능한 것인데, 이로인해 서버의 메모리 사용률이 2배로 증가하는 상황이 발생할 수 있다.
만약 데이터를 영구 저장하지 않더라도 복제 기능을 사용하고 있다면 주의해야 한다. 복제 연결을 처음 시도하거나 복제 연결이 끊긴 후 재시도를 할 때 새로 RDB 파일을 저장하는 과정을 거치기 때문이다. 따라서 이런 경우 MaxMemory 값을 실제 메모리의 절반으로 설정하는 것이 권장된다.
Memory 관리
redis는 memory를 사용하여 데이터를 저장하기 때문에 운영 단계에서 memory 관리가 가장 중요하다.
monitoring을 할 때 used_memory 값이 아닌 used_memory_rss 값을 보는 것이 더 중요하다.
used_memory는 물리적으로 redis에 데이터가 얼마나 저장되어 있는 지를 나타내고, used_memory_ss는 OS가 redis에 실제로 얼만큼의 메모리를 할당했는 지를 보여준다.
따라서 실제 데이터는 적은데 rss는 큰 상황이 발생할 수 있고, 이 차이가 클 때 fragmetation이 크다고 말한다. 주로 삭제되는 데이터가 많을 때 fragmentation이 증가한다.
