🧠 컨텍스트 윈도우 완벽 이해하기
— LLM이 정보를 기억하고 처리하는 방식은 어떻게 결정될까?
AI 언어 모델을 사용할 때 자주 마주치는 개념이 바로 컨텍스트 윈도우(Context Window)입니다.
이는 모델이 한 번에 기억하고 처리할 수 있는 모든 텍스트의 총량을 말합니다.
쉽게 비유하자면, AI가 답변을 만들 때 사용하는 ‘작업대(workbench)’ 크기, 혹은 단기 기억력과 같습니다.
이 작업대 위에 올라와 있는 텍스트만 참조하여 답변을 만들기 때문에, 이 범위를 벗어난 정보는 자연스럽게 잊혀집니다.
1. 컨텍스트 윈도우는 ‘토큰(Token)’으로 측정된다
컨텍스트 윈도우는 토큰(token)이라는 단위로 계산됩니다.
토큰은 모델이 텍스트를 이해하는 최소 단위입니다.
● 언어에 따라 토큰 수는 크게 차이난다
- 영어: 단어 하나가 거의 1 토큰
예) “Hello” = 1 토큰 - 한국어: 조사·어미가 분해되며 토큰 수가 늘어남
예) “안녕하세요” = 3~4 토큰
따라서, “8K(8,192) 토큰” 모델이면
영어 기준 약 6~7천 단어를, 한국어 기준 더 적은 양을 한 번에 처리할 수 있습니다.
2. 컨텍스트 윈도우가 중요한 이유
컨텍스트 윈도우 크기는 곧 모델이 얼마나 긴 문맥을 유지하면서 대화하거나 문서를 이해할 수 있는지를 결정합니다.
● 작은 윈도우(4K~8K)의 한계
- 긴 대화에서 앞부분을 잊음
- 논문, 보고서, 코드 저장소처럼 긴 문서 전체 분석이 불가능
● 큰 윈도우(128K~1M)의 장점
- 광범위한 문맥을 유지하면서 대화 가능
- 소설, PDF, 긴 코드 베이스 등 대용량 자료 기반의 요약·질의응답 가능
최근 모델들은 빠르게 대형 컨텍스트로 확장되고 있으며,
예를 들어 Gemini 1.5 Pro는 1M 토큰을 지원합니다.
3. 입력이 너무 길어지면 어떻게 될까?
컨텍스트 윈도우를 넘는 양의 텍스트가 들어오면,
모델은 가장 오래된 내용부터 순차적으로 잊어버립니다.
이를 일반적으로 슬라이딩 윈도우(sliding window) 방식이라고 부르며,
대화가 너무 길어질 때 AI가 맥락을 놓치는 이유가 바로 이것입니다.
4. 입력(Input)과 출력(Output)은 컨텍스트 윈도우를 '공유'한다
많은 분이 놓치는 핵심 포인트는 다음입니다.
컨텍스트 윈도우 = 입력 + 출력의 총합
즉, 컨텍스트가 8K인 모델에
사용자가 7K 토큰을 입력하면,
모델이 생성할 수 있는 답변은 최대 약 1K 토큰 정도로 제한됩니다.
이 때문에 매우 긴 문서를 넣으면 답변의 분량이 짧아지는 현상이 나타납니다.
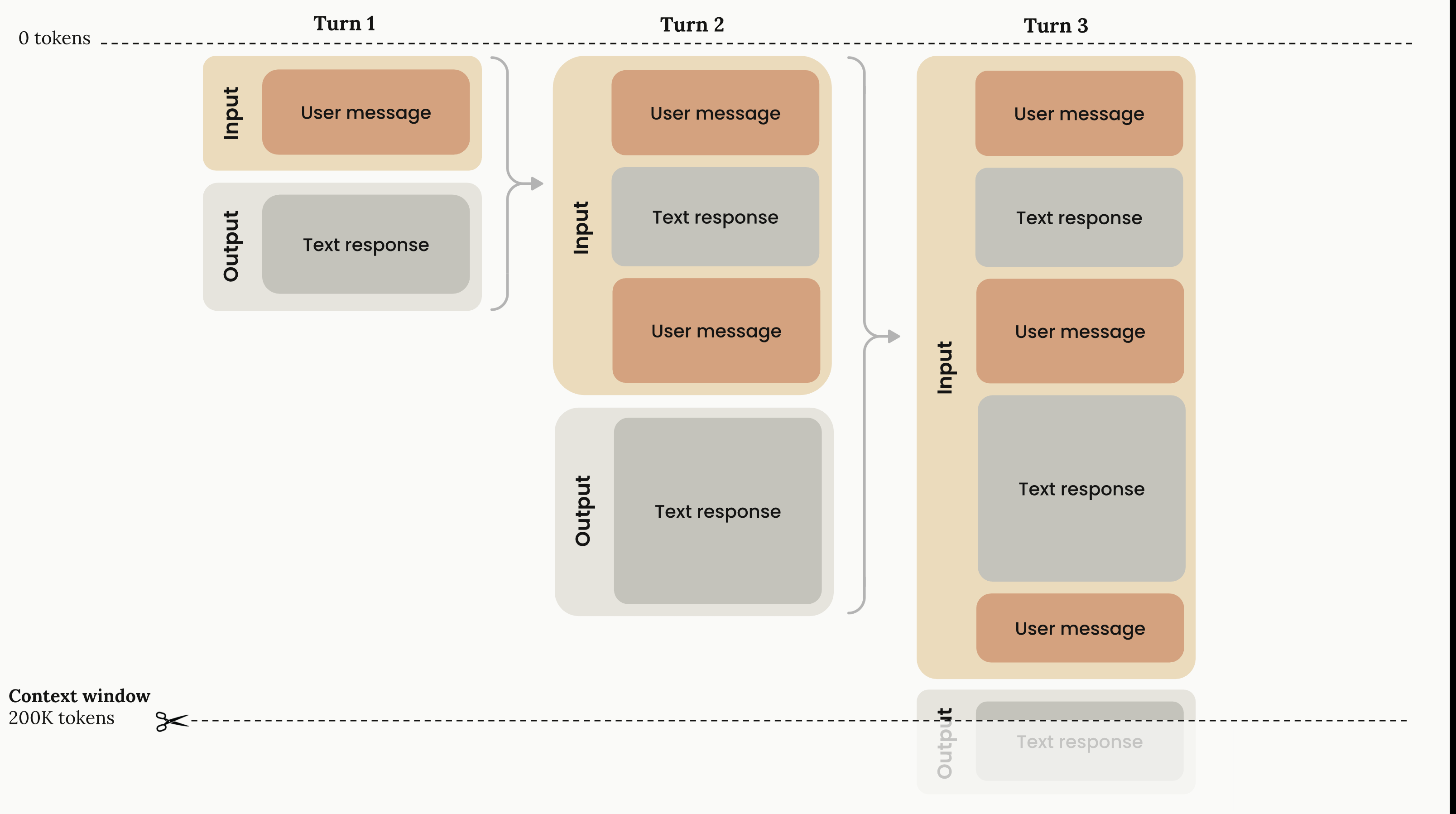
출처: Claude Docs
5. 컨텍스트 윈도우는 API 규칙이 아니다 — 모델 구조적 한계다
많은 사람들이 컨텍스트 윈도우를 API 제한으로 오해하지만,
실제로는 트랜스포머(Transformer)라는 구조 자체의 기술적·이론적 한계에서 비롯됩니다.
● 핵심 원인: Self-Attention의 복잡도 한계
트랜스포머는 모든 토큰이 서로를 비교하는 방식을 사용합니다.
이 계산량은 O(N²), 즉 토큰 수의 제곱으로 증가합니다.
- 100 토큰 → 10,000 연산
- 1,000 토큰 → 1,000,000 연산
- 10,000 토큰 → 100,000,000 연산
토큰이 조금만 길어져도 메모리와 연산량이 폭발하기 때문에
컨텍스트 윈도우에는 물리적 한계가 생길 수밖에 없습니다.
● 학습(Training) 시 길이 제한
모델은 특정 길이 예를 들어 4,096 토큰로 학습됩니다.
학습 중 본 적 없는 위치(예: 5,000번째 토큰)가 들어오면
모델은 관계를 학습한 적이 없어 성능이 떨어집니다.
이를 외삽(Extrapolation) 문제라고 합니다.
따라서 윈도우 크기는 결국
- 연산량
- 메모리
- 학습 데이터의 구조
이 세 가지가 결정하는 구조적 한계입니다.
API가 임의로 정한 규칙이 아니라,
모델의 태생적인 제약을 그대로 반영한 것에 불과합니다.
마무리
컨텍스트 윈도우는 AI 모델의 문맥 이해 능력과 처리 가능한 정보량을 결정하는 핵심 개념입니다.
이는 단순한 API 규칙이 아니라, 트랜스포머 구조에서 비롯된 본질적인 한계이자 기술적 특징입니다.
필요하시다면,
- 특정 모델의 컨텍스트 윈도우 비교
- 토큰 계산 방법
- 긴 문서 처리 팁
등도 이어서 자세히 설명해 드릴게요!
