제목: Language Models are Unsupervised Multitask Learners
저자: Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever
소속: OpenAI
학회: 미발표 / 아카이브 기반 사전 공개 (arXiv, Technical Report)
발표일: 2019년 2월 14일
논문 링크: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
코드 저장소: https://github.com/openai/gpt-2
📌 0. 간단한 설명
이 논문은 GPT-1의 Generative Pre-Training (GPT) 아이디어를 확장하여 더 큰 모델 규모(1.5B 파라미터)와 데이터셋(WebText, 40GB 이상)을 활용한 GPT-2를 소개합니다.
핵심은 언어 모델링(Language Modeling)만으로도 다양한 자연어 처리 과제(번역, 요약, 질문응답 등)를 별도의 태스크 특화 학습 없이 해결할 수 있다는 점을 보여주며, 이를 Zero-shot Learning이라고 정의했습니다.
주요 특징
- 입력: 인터넷에서 수집한 대규모 텍스트(WebText, 약 80만 개 문서, 40GB 이상)
- 출력: 문맥 기반 다음 토큰 예측, 문장 생성, 요약, 번역, 질의응답 등
- Zero-shot 평가: 특정 태스크 데이터로 fine-tuning 없이 단순히 프롬프트(prompt)를 다르게 주는 방식으로 성능 측정
아키텍처
-
모델 구조: Transformer decoder 기반 (최대 1.5억 → 15억 파라미터 규모 확장)
- GPT-2 Small (117M) / Medium (345M) / Large (762M) / XL (1.5B)
-
학습 방식:
- 사전 학습: 대규모 WebText 데이터셋에서 언어 모델링(다음 단어 예측)
- 태스크 수행: Fine-tuning 없이 프롬프트 설계를 통해 zero-shot으로 다양한 태스크 해결
사용된 태스크 (Zero-shot 평가)
- 기계 번역 (English → French, German 등)
- 문서 요약 (CNN/Daily Mail dataset)
- 질의응답 (QA)
- 독해 / 문장 완성
- 일반적인 상식 추론(Commonsense reasoning)
장점
- 범용성: 단일 모델로 번역, 요약, QA 등 다양한 태스크 수행 가능
- 데이터 효율성: 태스크별 라벨 데이터 없이도 준수한 성능 확보 (Zero-shot learning)
- 스케일 효과: 모델 크기를 키울수록 다양한 태스크에서 성능이 향상됨을 실험적으로 증명
👉 GPT-1이 사전 학습 + 미세 조정(fine-tuning) 패러다임을 열었다면, GPT-2는 이를 확장하여 사전 학습만으로도 범용적인 zero-shot 학습이 가능하다는 사실을 보여준 논문입니다.
📌 1. 개요 (Introduction)
🔹 배경
- 머신러닝 시스템은 큰 데이터셋 + 고용량 모델 + 지도학습을 통해 특정 과제에서 높은 성능을 보임.
- 하지만 데이터 분포 변화나 작은 입력 차이에도 쉽게 무너지고, 범용적이지 않고 "좁은 전문가(narrow experts)"에 불과함.
🔹 문제점
-
현재 접근 방식:
데이터 수집 → 모델 학습(정답 행동 모방) → IID (Independent and Identically Distributed) 검증셋에서 평가.
-
이 방식은 특정 작업에서는 성과가 있지만, 캡셔닝, 독해, 이미지 분류 등에서 다양한 입력을 잘 처리하지 못함.
-
원인: 단일 작업 + 단일 도메인 데이터셋 학습 중심 → 일반화 부족.
IID (Independent and Identically Distributed)란?
검증셋이 훈련 데이터와 같은 분포에서 독립적으로 뽑힌 데이터라는 가정하에 모델 성능을 평가한다는 뜻입니다. 즉, 모든 데이터 샘플이 서로 독립적이고, 동일한 분포에서 뽑혔다는 가정입니다.
🔹 멀티태스크 학습 (Multitask Learning)
- 여러 벤치마크(GLUE, decaNLP 등)가 등장하며 범용성 평가가 시도되고 있음.
- 멀티태스크 학습은 가능성이 있지만, 지금까지는 데이터셋-목표 쌍 10~17개 수준으로 제한적. → 데이터셋이 턱없이 부족함.
- ML 시스템은 일반적으로 수백~수천 개의 예제가 필요하므로, 멀티태스크도 매우 많은 훈련쌍이 필요.
- 데이터셋 제작을 무작정 늘리는 방식은 확장성의 한계가 있음.
결론적으로, GPT-2는 멀티태스크 학습을 한 게 아니라, 사전학습(업스트림) + 제로샷 다운스트림 적용이라는 모델링 전략이라고 보는 게 맞습니다.
🔹 사전학습 + 미세조정 (Pre-training & Fine-tuning)
-
과거 전이학습 발전 흐름:
- 단어 벡터(word vectors, ex. Word2Vec, GloVe) →
- 순환망의 문맥적 표현 전이 (RNN, LSTM 등) →
- self-attention 블록 전이 (BERT, GPT 등).
-
하지만 여전히 감독 학습 데이터가 필요.
-
감독 데이터가 부족할 때, 언어모델은 상식 추론, 감성 분석 등에서 가능성을 보여줌.
🔹 GPT-2의 기여
- 이 논문은 언어모델을 이용한 제로샷(zero-shot) 학습을 제안.
- 모델 구조나 파라미터 수정 없이 다양한 다운스트림 작업을 수행 가능함을 보임.
- 결과: 일부 작업에서는 경쟁력 있는 성능, 일부에서는 최신(state-of-the-art) 수준 달성.
다운스트림이란?
다운스트림 작업: 사전학습된 모델을 실제 응용 문제에 적용하는 구체적인 과제 (예: 감성 분석, 번역).
업스트림 작업: 모델을 사전학습할 때 사용하는 일반적이고 기본적인 학습 과제 (예: 다음 단어 예측).
👉 요약하면, GPT-2는 범용적이고 데이터 효율적인 학습을 위해 "사전학습된 언어모델을 제로샷으로 활용"하는 새로운 패러다임을 제시했다고 볼 수 있습니다.
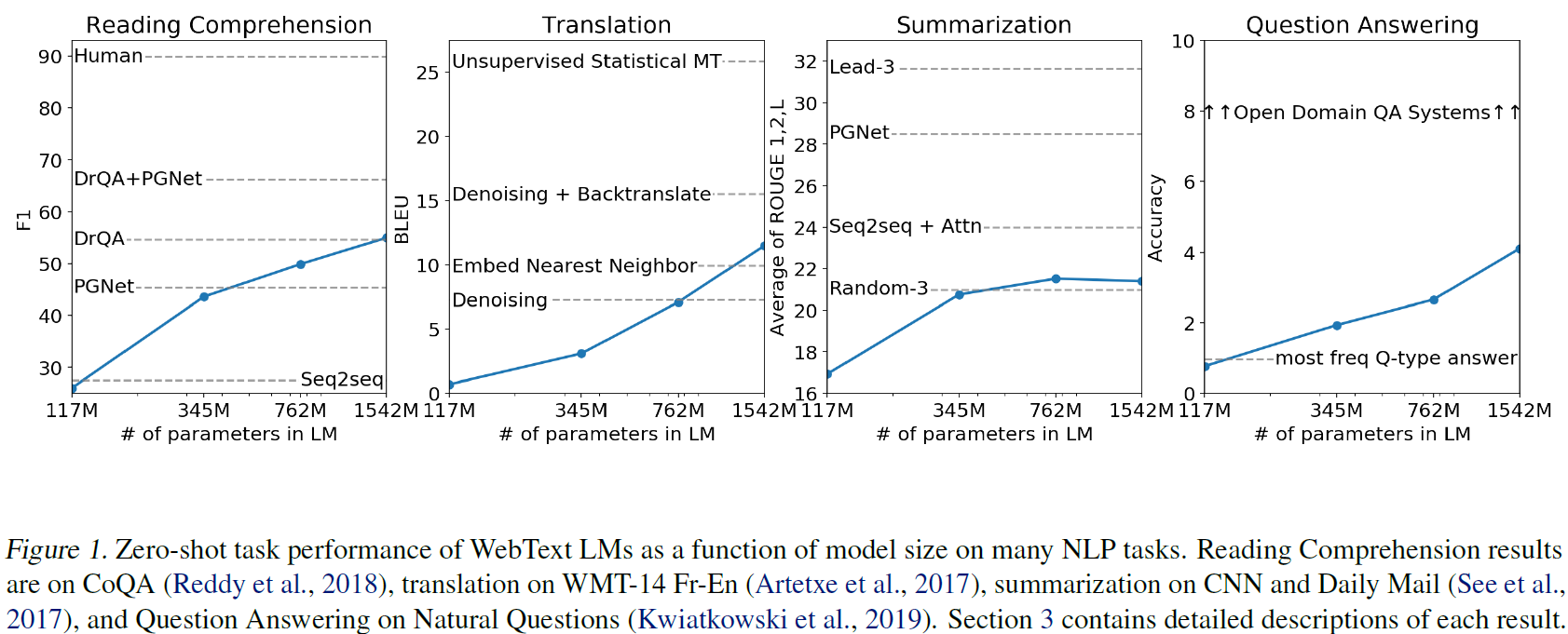
그림 해석:
X축: 언어모델의 크기 (파라미터 수: 117M, 345M, 762M, 1542M → GPT-2 Small~XL)
Y축: 각 과제별 성능 지표 (과제마다 다름)
파란선: GPT-2의 제로샷 성능
1. 모델 크기 증가 → 다양한 다운스트림 작업에서 제로샷 성능이 개선된다.
2. 하지만 여전히 전용 아키텍처 + 지도학습으로 훈련된 기존 모델들보다는 성능이 낮다.
3. 그럼에도 불구하고, 단일 언어모델이 파인튜닝 없이 여러 과제에 적용될 수 있다는 가능성을 보여줌.
→ 이 그림은 GPT-2가 "멀티태스크 학습"을 직접 하지 않고도, 모델 크기만 키워서 제로샷으로 여러 NLP 과제를 점점 더 잘 풀 수 있다는 것을 시각적으로 보여주는 결과입니다.
📌 2. 방법 (Approach)
🔹 핵심 개념: 언어 모델링(Language Modeling)**
- GPT-2의 기본 아이디어는 언어 모델링.
- 언어 모델링은 일반적으로 비지도 학습 기반의 확률 분포 추정으로 정의됨.
- 주어진 데이터 (ex. 문장): 각 샘플은 기호(sequence of symbols)로 구성된 가변 길이 시퀀스 (ex. 단어 및 토큰):
- 언어는 순차적 구조를 가지므로, 공동 확률(joint probability)를 조건부 확률의 곱으로 분해:
- 이 방식은 샘플링과 확률 추정을 가능하게 함 (여기서 은 출력 토큰의 개수).
2. 모델 구조의 발전
- 최근에는 Transformer(Self-Attention) 구조(Vaswani et al., 2017)로 조건부 확률 계산 능력이 크게 향상됨.
- 이로 인해 더 복잡하고 표현력이 높은 언어 모델이 가능해짐.
3. 멀티태스크 학습과 태스크 조건화(Task Conditioning)
- 단일 작업 학습은 확률적으로:
- 일반 시스템은 다양한 작업을 수행해야 하므로:
- 태스크 조건화 구현 방식:
- 구조적 접근: 작업별 인코더·디코더 (Kaiser et al., 2017)
- 알고리즘적 접근: MAML의 inner/outer loop (Finn et al., 2017)
- McCann et al. (2018): 언어를 통해 작업, 입력, 출력 모두를 기호 시퀀스로 표현 가능.
- 예시:
- 번역:
(translate to French, English text, French text) - 질의응답:
(answer the question, document, question, answer)
- 번역:
- 예시:
- MQAN 모델: 하나의 모델로 다양한 작업 수행 가능함을 입증.
4. GPT-2의 핵심 가설
- 언어 모델은 명시적 출력 구분 없이도 비지도 학습 목표로 동일한 작업을 학습 가능.
- 이유:
- 비지도 목표와 지도 목표는 동일하지만 평가 범위만 다름.
- 따라서 비지도 학습의 전역 최소값은 지도 학습의 전역 최소값과 동일.
- 문제:
- 실제로 비지도 목표를 충분히 최적화할 수 있는가?
- 초기 실험:
- 충분히 큰 언어 모델은 멀티태스크 학습 가능.
- 그러나 명시적 지도 학습보다 학습 속도가 느림.
5. 자연어 기반 학습의 확장
- Weston(2016): 대화(dialog) 기반 학습 제안 → 보상 신호 없이 QA 학습 가능.
- 그러나 대화는 제약적.
- 인터넷에는 방대한 자연어 데이터가 존재 → 상호작용 없이도 학습 가능.
- 핵심 추측:
- 충분히 큰 언어 모델은 자연어 시퀀스에서 작업을 추론하고 수행하는 법을 학습.
- 이는 사실상 비지도 멀티태스크 학습.
- 검증 방법:
- 다양한 작업에서 Zero-shot 성능 분석.
핵심 요약
- GPT-2는 대규모 언어 모델을 통해, 명시적 태스크 지시 없이도 자연어 데이터에서 다양한 작업을 학습하고 수행할 수 있는 가능성을 탐구.
- 목표: 비지도 멀티태스크 학습 → Zero-shot 평가로 검증.
아래는 GPT-2 논문 2.1 Training Dataset 부분의 상세 정리입니다.
2.1 Training Dataset

1. 기존 연구의 한계
- 대부분의 이전 언어 모델 연구는 단일 도메인 데이터에서 학습:
- 뉴스 기사 (Jozefowicz et al., 2016)
- 위키피디아 (Merity et al., 2016)
- 소설/픽션 (Kiros et al., 2015)
하지만 GPT-2는 다양한 도메인과 맥락에서 자연어 작업 예시를 최대한 많이 확보하는 것을 목표로 함.
2. 데이터 소스 선택
- Common Crawl: 웹에서 크롤링한 방대한 데이터 → 사실상 무제한 텍스트 제공.
- 문제점:
- 데이터 품질이 낮음 → 많은 문서가 읽기 어려움(Trinh & Le, 2018).
- Trinh & Le는 Winograd Schema Challenge에 맞춰 Common Crawl의 일부만 사용 → 특정 작업에 최적화된 방식.
GPT-2는 사전 작업 가정 없이 다양한 작업을 학습하고자 함 → 특정 태스크에 맞춘 필터링은 피함.
3. 새로운 데이터셋(WebText) 구축
- 목표: 품질 높은 웹 텍스트 확보.
- 방법:
- Reddit에서 3 karma 이상 받은 링크의 아웃바운드 URL을 크롤링.
- 이유: Reddit 사용자들이 흥미롭거나 유익하다고 평가한 콘텐츠일 가능성이 높음.
- HTML에서 본문 텍스트 추출:
- Dragnet + Newspaper1 콘텐츠 추출기 사용.
- Reddit에서 3 karma 이상 받은 링크의 아웃바운드 URL을 크롤링.
- 결과:
- WebText 데이터셋:
- 약 4,500만 개 링크 기반.
- 중복 제거 및 휴리스틱 기반 정제 후:
- 800만 개 문서
- 총 40GB 텍스트
- 2017년 12월 이후 링크는 제외(초기 버전 기준).
- Wikipedia 문서 제거:
- 다른 데이터셋과 중복 방지.
- 평가 시 데이터 누수 방지.
- WebText 데이터셋:
핵심 특징
- 다양성: Reddit 기반 → 뉴스, 블로그, 기술 글, 창작물 등 다양한 도메인 포함.
- 품질 보장: Reddit 커뮤니티의 집단 필터링(karma) 활용.
- 규모: 기존 언어 모델 데이터셋보다 훨씬 큼 (40GB).
핵심 요약
- GPT-2는 단일 도메인 데이터의 한계를 극복하기 위해, Reddit 기반의 고품질 웹 텍스트(WebText)를 구축.
- WebText는 다양성 + 품질 + 대규모를 모두 만족하는 데이터셋으로, GPT-2의 제로샷 학습 능력을 뒷받침.
2.2 Input Representation
1. 일반 언어 모델의 요구사항
- 이상적인 언어 모델(LM)은 어떤 문자열이든 확률을 계산하고 생성할 수 있어야 함.
- 하지만 기존 대규모 LM은 다음과 같은 전처리 제약이 있음:
- 소문자 변환(lowercasing)
- 토큰화(tokenization)
- OOV(Out-of-Vocabulary) 토큰 처리
- 이런 제약은 모델이 다룰 수 있는 문자열의 범위를 제한함.
2. 기존 접근법과 한계
- UTF-8 바이트 단위 처리:
- 모든 유니코드 문자열을 자연스럽게 처리 가능.
- 예시: Gillick et al. (2015)
- 문제: 대규모 데이터셋(예: One Billion Word Benchmark)에서는 성능이 단어 수준 LM보다 낮음.
- GPT-2의 초기 실험에서도 바이트 단위 LM은 WebText에서 성능이 떨어짐.
3. Byte Pair Encoding (BPE)
- BPE는 단어 수준과 문자 수준 사이의 실용적 절충안:
- 자주 등장하는 기호 시퀀스는 단어 수준으로 처리.
- 드물게 등장하는 시퀀스는 문자 수준으로 처리.
- 문제점:
- 기존 BPE 구현은 유니코드 코드 포인트 기반 → 모든 유니코드 기호를 포함해야 함.
- 기본 어휘 크기: 130,000+ (너무 큼)
- 일반적으로 BPE는 32,000~64,000 토큰 사용.
4. GPT-2의 해결책: 바이트 기반 BPE
- 바이트 단위 BPE:
- 기본 어휘 크기: 256 (바이트 값)
- 문제:
- BPE는 빈도 기반 탐욕적 병합을 사용 → 비효율적 병합 발생.
- 예: "dog", "dog!", "dog?" → 각각 다른 토큰으로 병합 → 어휘 낭비.
- 해결:
- 문자 카테고리 간 병합 금지 (예: 알파벳과 구두점은 병합하지 않음)
- 공백(space)은 예외 → 압축 효율 향상, 단어 분절 최소화.
5. 장점
- 단어 수준 LM의 경험적 이점 + 바이트 수준의 일반성 결합.
- 어떤 유니코드 문자열에도 확률 할당 가능 → 사전 토큰화나 어휘 크기 제약 없음.
- 다양한 데이터셋에서 전처리 없이 평가 가능.
핵심 요약
- GPT-2는 바이트 기반 BPE를 사용해:
- 어휘 크기 문제 해결 (256 기본 토큰)
- 모든 유니코드 문자열 처리 가능
- 단어 수준 성능 유지
- 결과: 범용성 + 효율성을 동시에 달성.
2.3 Model 상세 정리
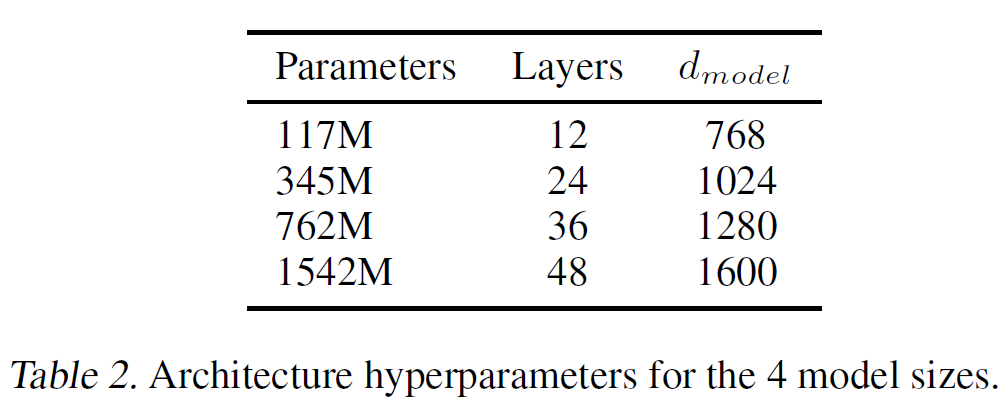
1. 기본 구조
- GPT-2는 Transformer 기반 아키텍처(Vaswani et al., 2017)를 사용.
- 기본적으로 OpenAI GPT (Radford et al., 2018) 모델을 따르지만, 몇 가지 수정 사항이 있음.
2. 주요 변경점
(1) Layer Normalization 위치 변경
- 기존 GPT는 서브블록 출력에 LayerNorm 적용.
- GPT-2는 서브블록 입력에 LayerNorm 적용 → Pre-activation Residual Network 방식(He et al., 2016)과 유사.
- 추가로, 마지막 Self-Attention 블록 뒤에 LayerNorm을 하나 더 추가.
(2) 초기화 방식 수정
- Residual 경로에서 깊이에 따른 누적 효과를 고려한 초기화 사용.
- Residual Layer의 가중치를 초기화 시 로 스케일링 ( = Residual Layer 개수).
3. 모델 하이퍼파라미터 변경
- 어휘 크기(Vocabulary size):
- 기존 GPT보다 확장 → 50,257 토큰.
- 컨텍스트 길이(Context size):
- 512 → 1024 토큰 (더 긴 문맥 처리 가능).
- 배치 크기(Batch size):
- 512로 증가 (대규모 학습 지원).
핵심 요약
- GPT-2는 Transformer 기반이지만, 안정성과 성능 향상을 위해:
- LayerNorm 위치 조정
- Residual 초기화 개선
- 어휘 확장, 컨텍스트 길이 증가, 대규모 배치 적용
- 결과적으로 더 깊고 안정적인 학습과 긴 문맥 처리 능력 확보.
📌 3. 논의 (Discussion)
-
사전학습 표현에 대한 연구 배경
- 기존 연구들은 표현 학습, 표현 이해, 표현 평가에 집중해 왔음.
- GPT-2 연구 결과는 비지도 학습 기반 태스크 학습(unsupervised task learning)이 유망한 연구 분야임을 보여줌.
-
비지도 사전학습의 의미
- 이 연구는 사전학습 기법이 단순히 표현을 학습하는 것을 넘어, 지도학습 없이도 직접 태스크를 수행하는 능력을 얻게 됨을 보여줌.
- 이는 사전학습 기법이 다운스트림 NLP 작업에서 성공적인 이유를 설명하는 단서가 됨.
-
Zero-shot 성능 분석
- 독해(Reading comprehension): GPT-2는 지도학습 기반 모델과 경쟁 가능한 성능을 보임.
- 요약(Summarization): 질적으로는 요약을 수행하지만, 정량적 평가 기준에서는 아직 미흡.
- 따라서 연구적 시사점은 크지만, 실제 응용 측면에서는 아직 사용하기 어려움.
-
한계와 과제
- GPT-2는 여러 전형적인 NLP 과제에서 Zero-shot 성능을 평가했지만, 아직 평가되지 않은 과제가 많음.
- 실제 많은 과제에서는 GPT-2 성능이 무작위 수준에 불과할 수 있음.
- 예: 질문응답(Question Answering), 번역(Translation) 같은 일반적 태스크조차도 충분히 큰 모델 용량(capacity)일 때만 기본선을 초과함.
-
Fine-tuning의 필요성
- Zero-shot 결과는 GPT-2의 잠재적 성능을 보여주는 출발점일 뿐, Fine-tuning 시 최대 성능(ceiling)이 어디까지 올라갈지는 불확실.
- GPT-2의 추상적(abstractive) 출력은 기존 추출적(extractive) 접근(예: Pointer Network, Vinyals et al. 2015)과 매우 다르며, 이는 QA·독해 데이터셋에서 최신 성능과 차이가 있음.
- 따라서 연구진은 decaNLP, GLUE 같은 벤치마크에서 Fine-tuning을 계획.
- 특히, GPT-2의 더 많은 데이터와 모델 용량이 BERT(Devlin et al., 2018)가 보여준 단방향(unidirectional) 표현의 한계를 극복할 수 있는지 탐구할 예정.
📌 4. 결론 (Conclusion)
-
대규모 언어모델의 효과
- 충분히 크고 다양한 데이터셋으로 학습된 대형 언어모델은 다양한 도메인과 데이터셋에서 좋은 성능을 발휘함.
-
GPT-2의 성과
- GPT-2는 8개의 언어모델링 벤치마크 중 7개에서 zero-shot으로 SOTA(최신 성능) 달성.
-
Zero-shot의 시사점
- Zero-shot 설정에서 다양한 과제를 수행할 수 있다는 점은, 대규모 언어모델이 명시적 지도(supervision) 없이도 상당한 범위의 태스크를 학습할 수 있다는 것을 보여줌.
- 즉, 충분히 큰 모델 + 충분히 다양한 데이터를 통해, 단순한 언어 확률 모델이 실질적인 과제 수행 능력을 얻게 됨.
✅ 정리하면, GPT-2의 논의와 결론은 다음과 같습니다:
- Zero-shot은 연구적으로 매우 의미 있으나, 실용적 응용까지는 아직 부족.
- Fine-tuning 연구가 필수적이며, BERT와 같은 기존 접근의 한계를 극복할 수 있을지 탐구할 필요가 있음.
- 결론적으로, 대규모 모델 + 대규모 데이터가 만나면 지도학습 없이도 다양한 NLP 과제를 수행할 수 있는 능력이 자연스럽게 나타난다는 것을 GPT-2가 보여줌.
