
이미지 속 원치 않는 객체를 지우거나 손상된 영역을 감쪽같이 채워 넣는 이미지 인페인팅(Image Inpainting) 기술은 컴퓨터 비전 분야에서 꾸준히 연구되고 있는 매력적인 주제입니다.
오늘은 기존 인페인팅 모델들이 겪고 있던 고질적인 한계를 멋지게 극복해 낸 논문 한 편을 소개해 드리려고 합니다. 바로 삼성 AI 센터(Samsung AI Center) 연구진이 발표한 "Resolution-robust Large Mask Inpainting with Fourier Convolutions (LaMa)"입니다.
🎯 기존 이미지 인페인팅의 한계와 문제 제기
최근의 현대적인 이미지 인페인팅 시스템들도 큰 누락 영역을 채우거나, 복잡한 기하학적 구조를 띄고 있거나, 고해상도의 이미지를 처리할 때는 종종 부자연스러운 결과를 만들어내며 어려움을 겪었습니다.
LaMa 연구진은 이러한 문제의 주된 원인이 인페인팅 네트워크와 손실 함수(Loss Function) 모두에서 충분한 유효 수용 영역(Effective Receptive Field)이 부족하기 때문이라는 점을 날카롭게 짚어냈습니다. 아주 넓은 영역을 자연스럽게 복원하려면 이미지 전체의 맥락(Global structure)을 폭넓게 이해해야 하지만, 기존에 주로 사용되던 합성곱(Convolution) 방식은 주변의 좁은 영역만 바라보는 데 그쳐 한계가 뚜렷했던 것입니다.
💡 LaMa를 완성한 3가지 핵심 혁신 요소
LaMa는 복잡하고 무거운 다단계 모델 대신, 아주 단순한 단일 단계(Single-stage) 네트워크만으로도 최고 수준(State-of-the-art)의 결과를 달성했습니다. 이를 가능하게 한 세 가지 핵심 아이디어를 살펴보겠습니다.
- Fast Fourier Convolutions (FFCs) 도입: 네트워크 초기 레이어부터 이미지 전체를 포괄하는 수용 영역을 확보할 수 있도록 최근 개발된 FFC 연산자를 과감하게 적용했습니다. 덕분에 네트워크는 시작부터 이미지의 전역적인 맥락(Global context)을 짚어낼 수 있습니다.
- 넓은 수용 영역의 지각적 손실 함수 (HRF PL): 전역적인 구조와 형태가 일관성 있게 유지되도록, 의미론적 분할(Semantic segmentation) 네트워크를 기반으로 한 새로운 지각적 손실 함수를 제안했습니다. 공식은 와 같이 정의됩니다.
- 공격적인 훈련 마스크 생성 (Aggressive Mask Generation): FFC와 HRF PL의 잠재력을 한계까지 끌어내기 위해, 모델 학습 시 폭이 매우 넓고 거대한 마스크를 무작위로 생성하여 훈련하는 공격적인 전략을 채택했습니다.
🔍 아키텍처 깊게 보기: LaMa는 어떻게 작동할까?
LaMa의 작동 원리는 크게 세 가지 파트로 나누어 이해할 수 있습니다. 기존의 지역적(Local) 방식과 푸리에 변환을 이용한 전역적(Global) 방식을 병렬로 결합한 것이 핵심입니다.
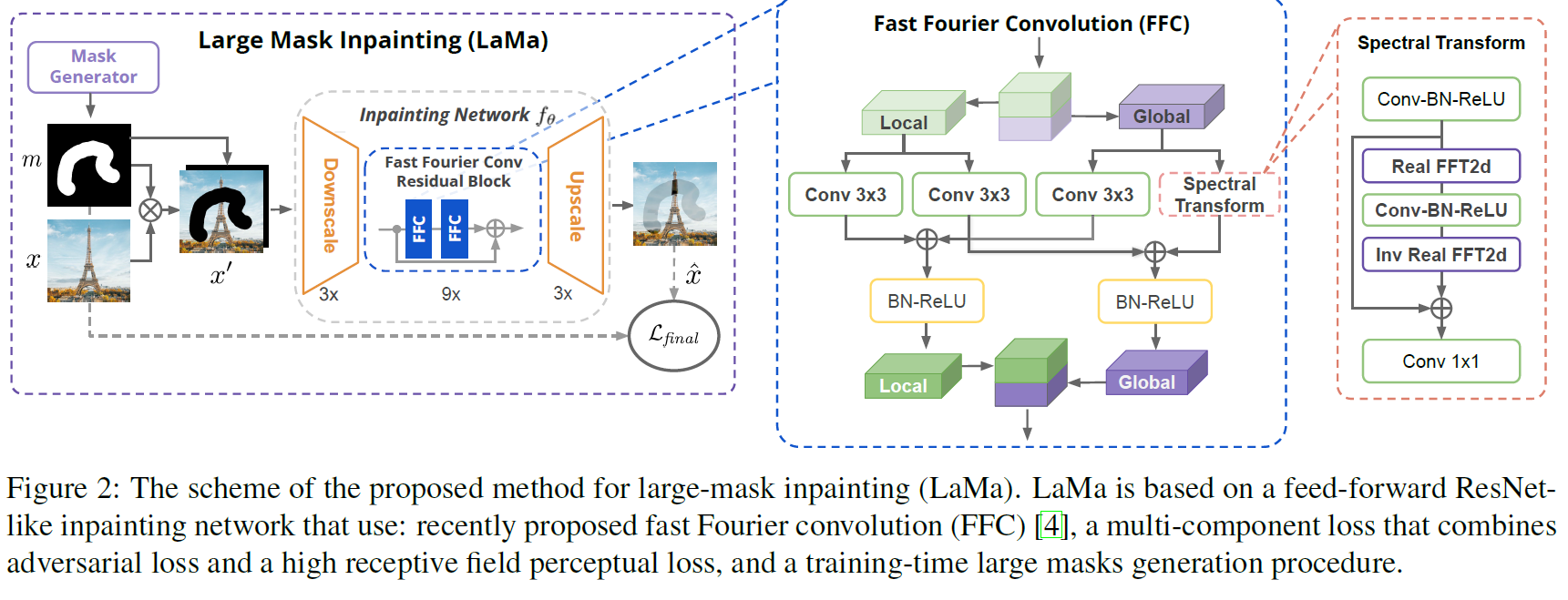
1. 전반적인 인페인팅 네트워크 흐름
원본 이미지 와 마스크 이 결합되어 구멍이 뚫린 입력 텐서 가 만들어지면, ResNet 구조와 유사한 생성기(Generator) 네트워크 로 들어갑니다. 해상도를 줄이며 특징을 뽑아내는 3번의 Downscale을 거친 후, 이 모델의 심장부인 9개의 FFC 잔차 블록(Fast Fourier Conv Residual Block)을 통과하며 공간적/전역적 특성을 동시에 학습합니다. 이후 3번의 Upscale을 통해 원래 해상도로 뼈대를 갖추고, 최종 복원된 이미지 를 출력합니다.
2. 고속 푸리에 합성곱 구조 (FFC)
네트워크 중간에 위치한 FFC 잔차 블록은 입력 채널을 두 개의 길(Branch)로 나누어 영리하게 처리합니다.
- Local Branch: 기존의 일반적인 3x3 합성곱을 사용해 이미지의 지역적인 텍스처와 세부 구조를 파악합니다.
- Global Branch: 이미지 전체의 문맥을 한 번에 파악하기 위해 스펙트럼 변환(Spectral Transform) 블록을 거칩니다.
두 브랜치는 완전히 따로 노는 것이 아니라, 중간에 합성곱 연산을 거쳐 서로의 정보를 교환하고 합산(⊕)되어 다음 단계로 넘어갑니다.
3. 스펙트럼 변환 과정 (Spectral Transform)
전역 브랜치 내에서는 2D 실수 고속 푸리에 변환(Real FFT2d)을 통해 공간 도메인의 신호를 주파수 도메인으로 변환합니다. 이를 통해 단번에 이미지 전체를 아우르는 시야를 확보하고, 주파수 상에서 연산(Conv-BN-ReLU)을 수행한 뒤, 다시 역변환(Inv Real FFT2d)하여 공간 도메인의 이미지 형태로 되돌려 놓습니다.
🏆 놀라운 성과와 결론
LaMa 모델은 다음과 같은 압도적인 강점을 보여줍니다.
- 해상도를 뛰어넘는 일반화 (Resolution Robustness): 놀랍게도 256x256의 낮은 해상도 데이터로만 학습되었지만, 학습 시 한 번도 본 적 없는 512x512 이상의 고해상도 이미지에서도 깨짐이나 아티팩트 없이 완벽하게 작동합니다.
- 복잡한 주기적 구조 복원: 창문, 벽돌, 사다리 등 인간이 만든 환경에서 흔히 볼 수 있는 복잡한 반복 패턴을 훌륭하게 잡아내어 자연스럽게 이어 붙입니다.
- 가볍고 빠른 효율성: CoModGAN이나 MADF 등 쟁쟁한 경쟁 모델들과 비교했을 때, 파라미터 수는 현저히 적고 추론 시간(Inference time) 비용도 낮아 실무적인 활용도가 매우 높습니다.
결론적으로 LaMa는 나무(Local)와 숲(Global)을 동시에 보는 푸리에 변환을 적절히 융합하여, 넓은 결측치도 놀랍도록 자연스럽게 메꾸는 인페인팅 기술의 새로운 패러다임을 제시했습니다. 컴퓨터 비전과 생성 모델에 관심 있는 분들이라면 꼭 한 번 깊게 읽어보시기를 권해드립니다!
