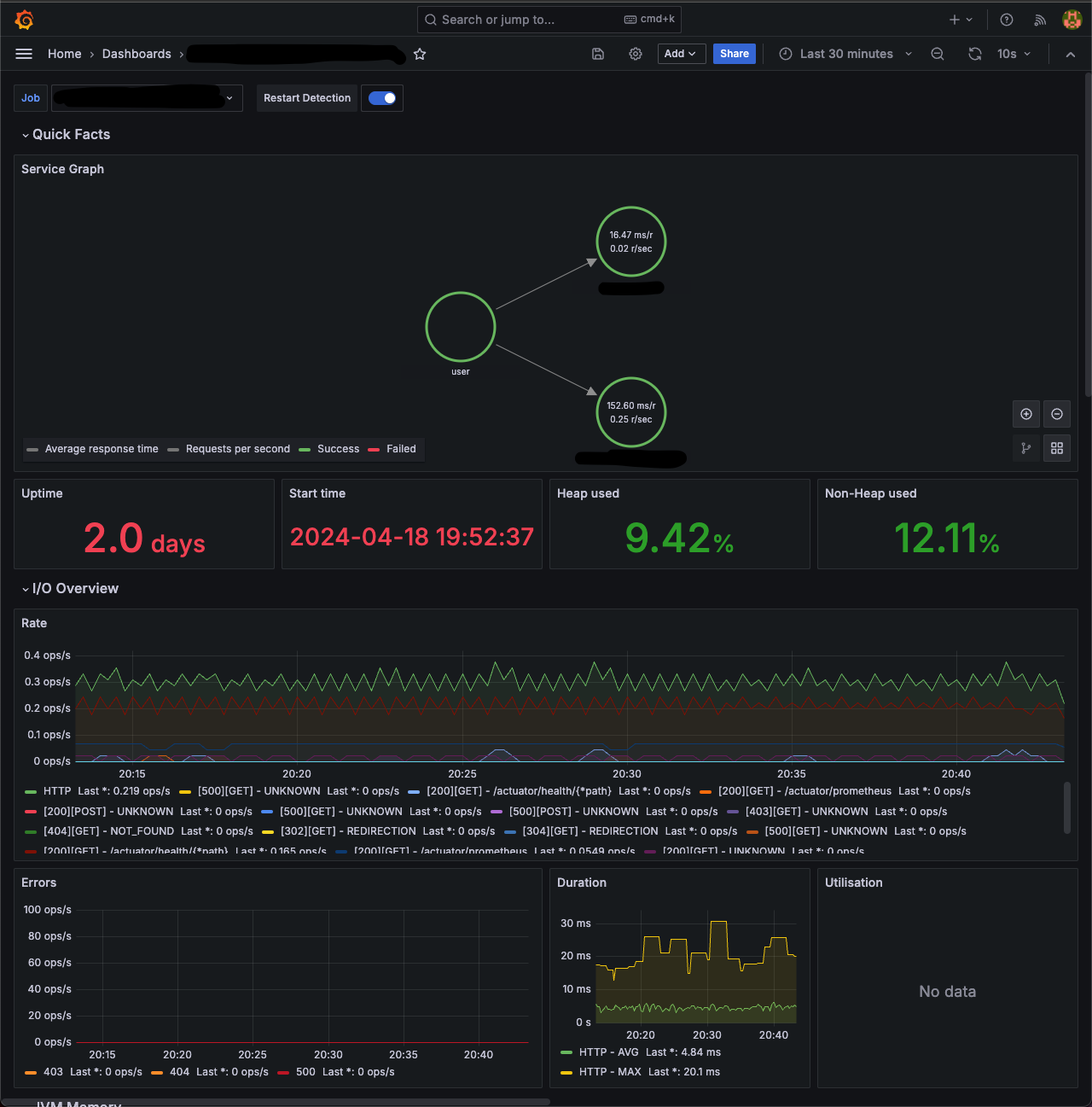
쿠버네티스에 서비스를 구성하게 되었다.
Observability를 위한 모니터링 시스템이 필요했고 grafana 재단에서 이에 필요한 기술들을 제공하고있다.
- L(oki) : 로그 집계 시스템
- G(rafana) : 데이터 시각화 및 모니터링 툴
- T(empo) : 분산 트레이징 데이터 저장 시스템
- M(imir) : 확장 가능한 프로메테우스 호환 메트릭 저장소
이 포스팅은 3개의 master node, 3개의 worker node 로 구성된 쿠버네티스 클러스터에서 진행된다.
kubenetes version: 1.27.4
helm version: v3.13.2
셋업
깃헙 저장소 참고
Helm Repo
helm repo add grafana https://grafana.github.io/helm-charts
helm repo updateLoki
kubectl create ns loki
helm upgrade --install loki grafana/loki -f monitoring/loki-values.yaml -n lokiMimir
kubectl create ns mimir
helm upgrade --install mimir grafana/mimir-distributed -n mimirTempo
kubectl create ns tempo
helm upgrade --install tempo grafana/tempo-distributed -f monitoring/tempo-values.yaml -n temposervice-graphs
tempo 의 서비스 그래프 기능을 이용하려면 별도의 설정이 필요하다.
현재 metrics, logs, traces 등 다양한 지표를 그라파나 에이전트 를 통해 수집하고 있다.
문서를 보면 그라파나 에이전트에서 서비스 그래프를 활성화하는 방법을 안내하고 있는데
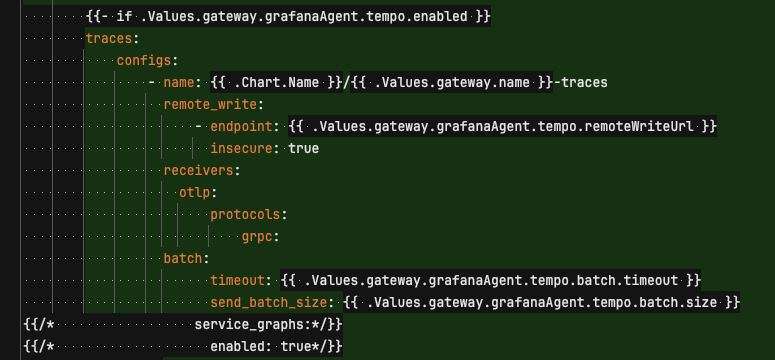
service_graphs 를 enable 해야한다고 한다.
하지만 위 설정은 필요없었고, tempo 의 metricsGenerator 를 사용해 서비스 그래프를 위한 데이터를 푸시할 수 있었다.
metricsGenerator:
enabled: true
config:
storage:
remote_write:
- url: http://mimir-nginx.mimir.svc.cluster.local:80/api/v1/push
send_exemplars: false
global_overrides:
metrics_generator_processors:
- service-graphs위 설정을 통해 tempo 의 metricsGenerator 를 활성화하고, mimir(prometheus)에 데이터를 푸시하도록 설정했다.
그리고, 그라파나의 tempo 데이터소스에서 아래와 같이 service graph 의 데이터소스로 mimir(prometheus)를 설정한다.
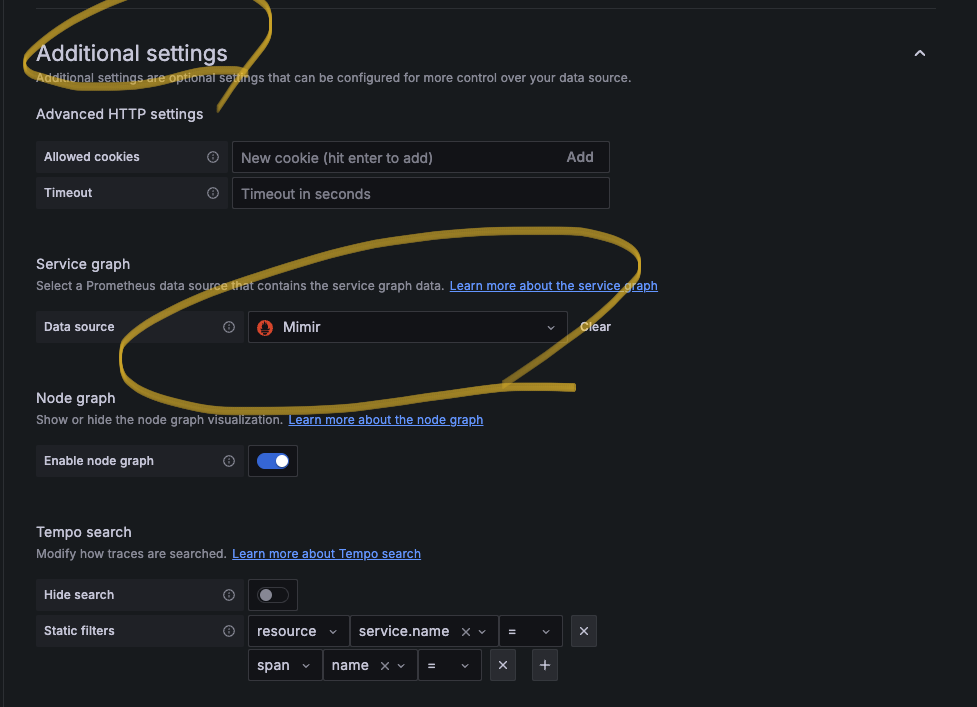
Grafana
kubectl create ns monitoring
helm upgrade --install grafana grafana/grafana -f monitoring/grafana-values.yaml -n monitoringimport k8s jvm dashboard template
monitoring/jvm-viewer.json 를 import
https://grafana.com/grafana/dashboards/4701-jvm-micrometer/
위 템플릿을 기반으로 수정했다.
- angular 기반의 컴포넌트 마이그레이션
- 애플리케이션의 별도의 Bean 혹은 설정 제거
- grafana agent 에서 등록한 job_name 기반 필터링
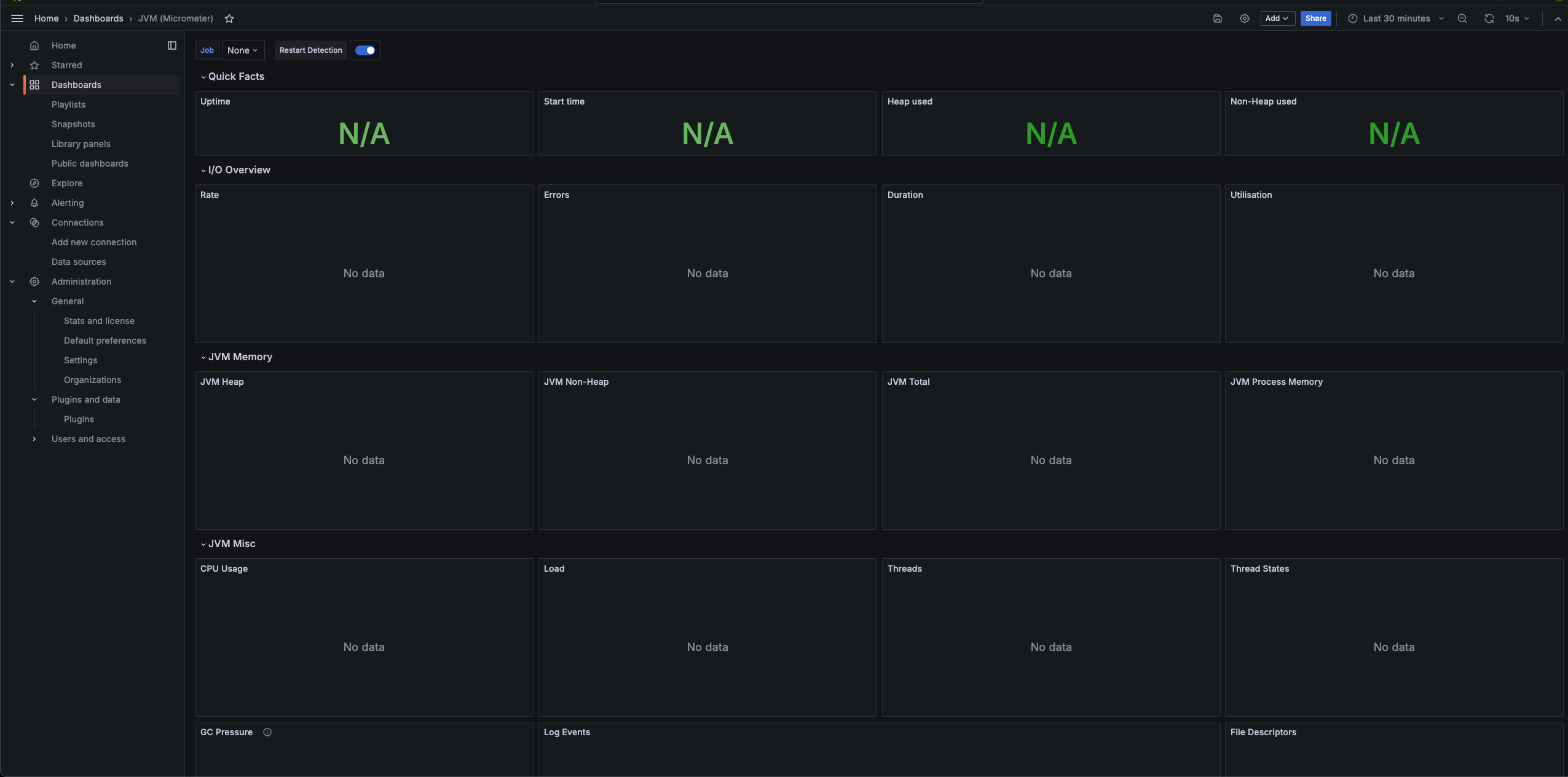
위와같이 import 된다. job을 등록해줘야한다.
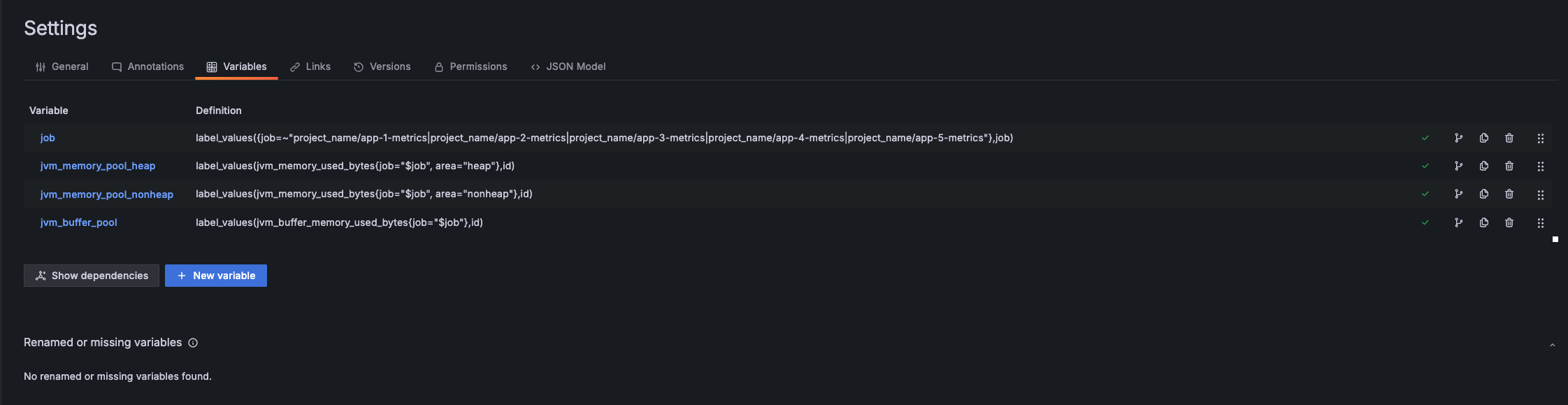

변수 job 에서 적절한 애플리케이션 이름으로 수정한다.
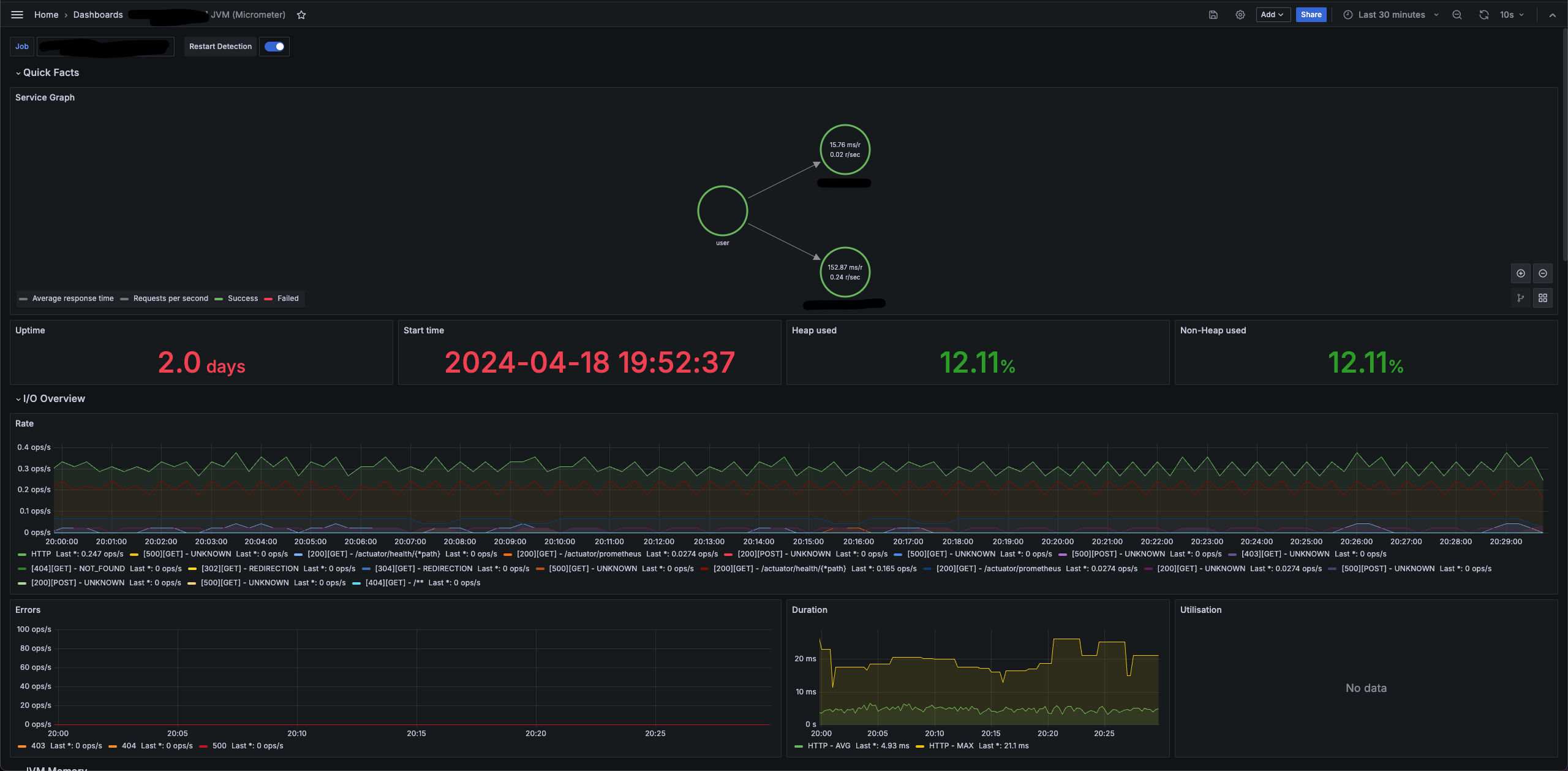
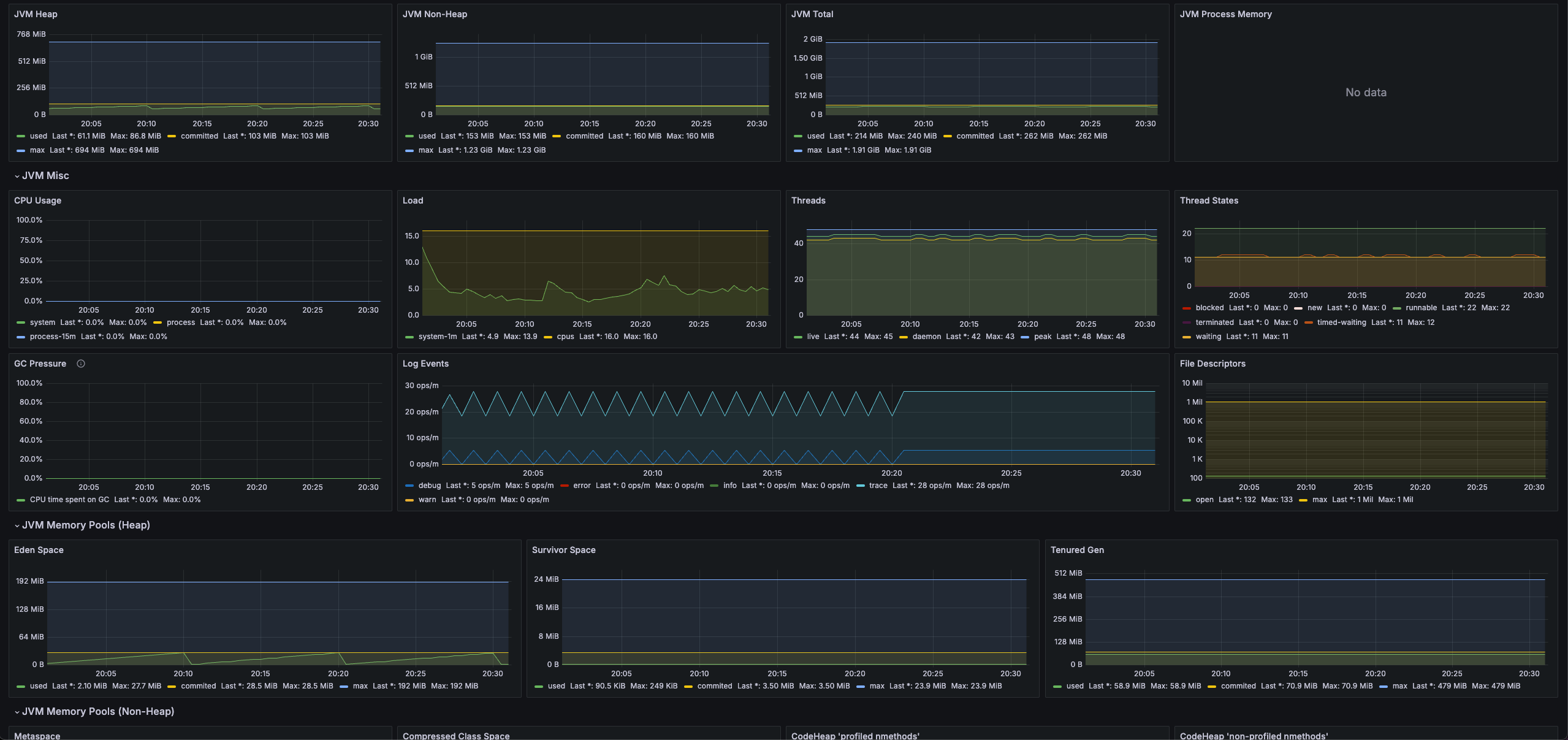
import k8s loki log dashboard template
monitoring/log-viewer.json 를 import
https://grafana.com/grafana/dashboards/15141-kubernetes-service-logs/
위 템플릿을 기반으로 수정했다.
app라벨로 서비스 필터링- Log Level 로 필터링
- trace-id, span-id 로 필터링
- spring sleuth 에서 생성되는 값을 logback 에서 json 으로 로깅 후 필터링
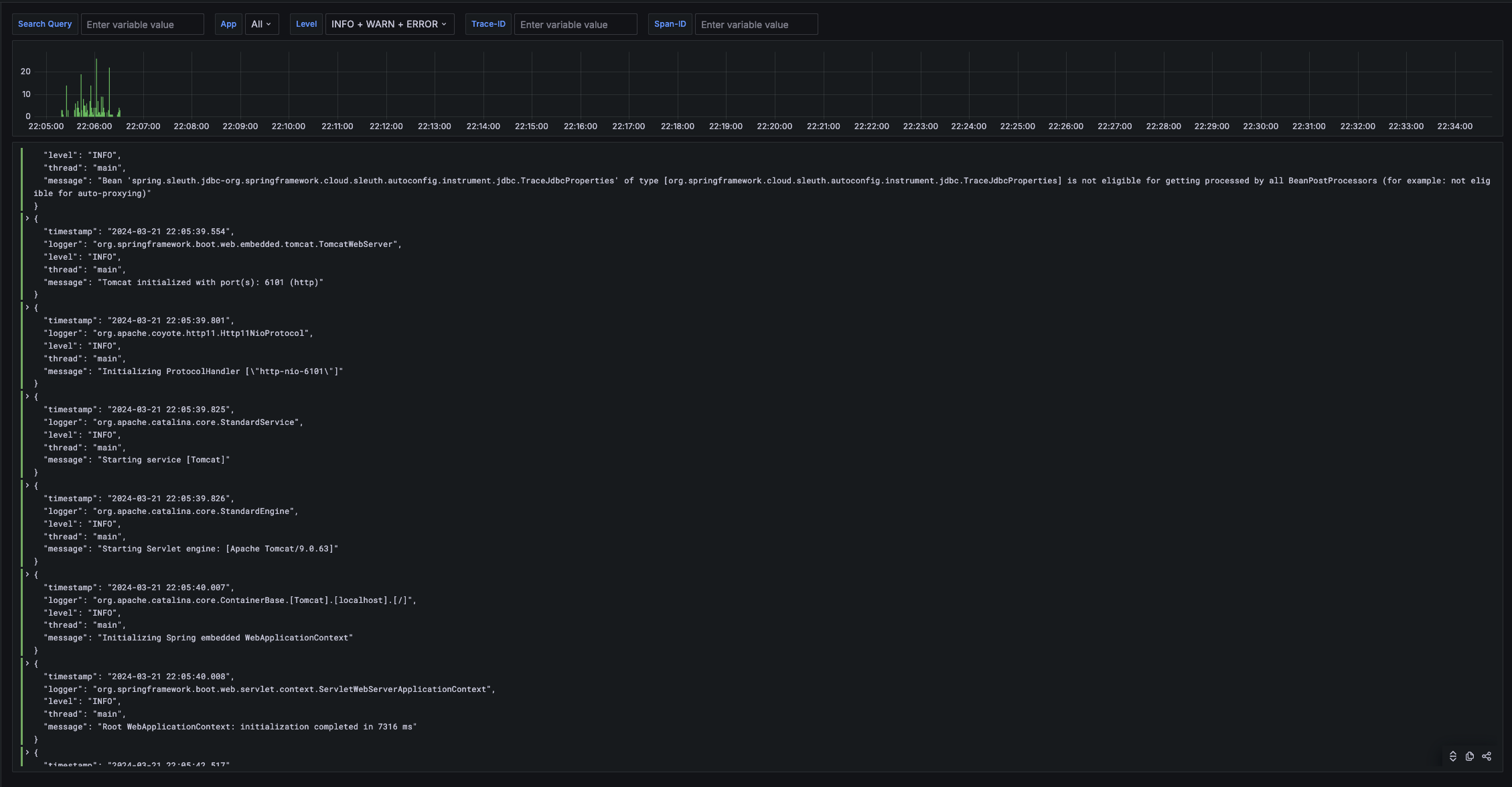
loki -> tempo internal link
loki datasource 에서 internal link 를 설정할 수 있다.
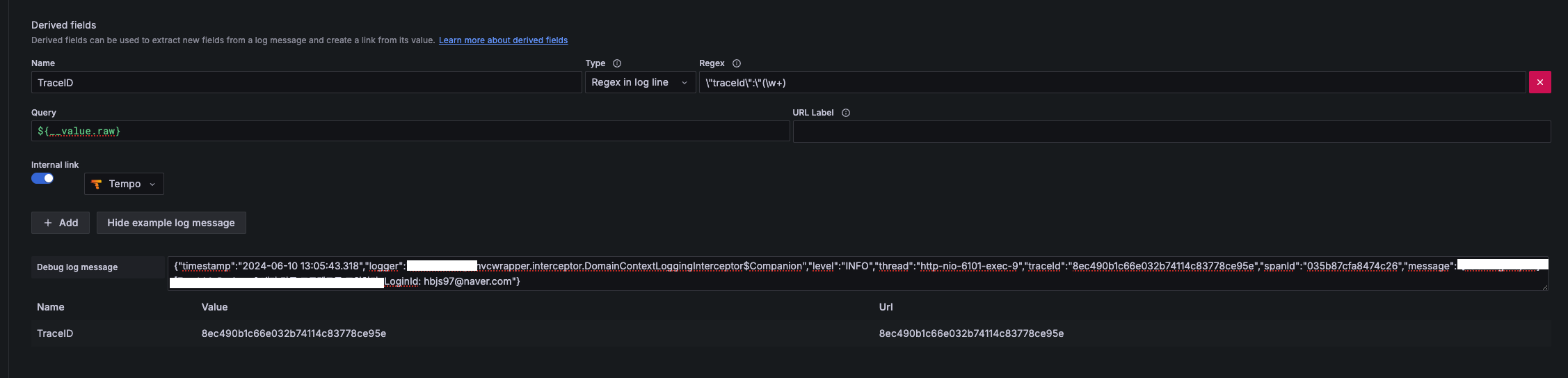
logback 에서 json 형식의 로그를 내보내고있고, traceId 필드에 link 를 생성한다.
debug log message 에 실제 로그를 붙여넣고 필드가 잘 추출되는지 확인할 수 있다.
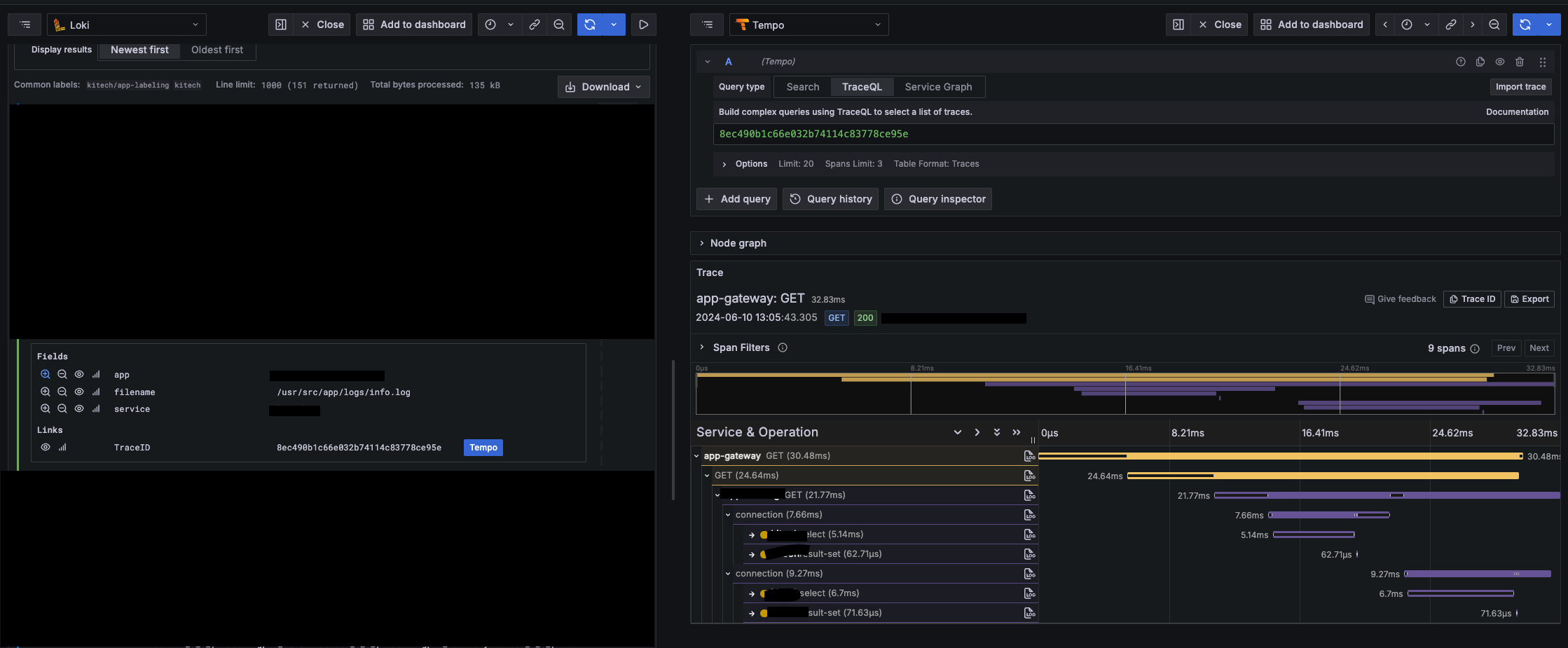
loki 에서 tempo 로 link 를 걸어 바로 확인할 수 있다.
문제해결
grafana agent `too many open files` 에러
sudo sysctl -w fs.inotify.max_user_instances=512파일 디스크립터 사용량: Grafana Agent는 로그 데이터를 모니터링하고 수집하는 도구로서, 많은 수의 파일을 동시에 열어서 로그를 추적하거나, 네트워크 소켓을 통해 데이터를 전송합니다. Kubernetes 환경에서는 이런 동작이 다른 컨테이너와 공유하는 호스트 리소스에 영향을 줄 수 있습니다.
리눅스 inotify 리소스: Grafana Agent가 파일 시스템의 변화를 모니터링하기 위해 inotify 인스턴스를 사용할 수 있습니다. inotify는 파일 시스템 이벤트를 모니터링하기 위한 리눅스 커널 서브시스템으로, 파일이나 디렉토리에 변경이 생겼을 때 알림을 받을 수 있게 해줍니다. 각 inotify 인스턴스는 하나 이상의 파일을 감시하는데 사용되며, 이들 각각이 파일 디스크립터를 사용합니다.
더 많은 파일이나 디렉토리를 동시에 감시할 수 있게 fs.inotify.max_user_instances=512 로 inotify 인스턴스의 최대 개수를 늘려줬다. (128 -> 512)
tomcat_threads_busy_threads 지표가 표시되지 않는 문제
Utilisation 패널이 보이지 않는다. tomcat_threads_busy_threads 메트릭이 수집되지 않아서 그렇다.
아래와 같이 설정을 추가해준다.
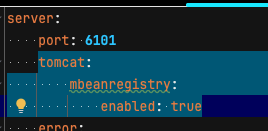
단, webflux 기반의 애플리케이션(spring gateway 등)은 tomcat 지표가 없다.
위 내용은 LGTM 스택을 하나씩 직접 배포하는 케이스인데, 권장사항은 아니다.
prometheus 로 k8s native 한 메트릭을 추적하려면 직접 설정해야할 사항이 너무 많다.
kube-prometheus-stack를 사용해 grafana, prometheus 를 대체하고 loki 과 tempo 만 별도로 배포하길 권장한다.
