몇 달 전에 진행했던 성능 개선 작업을 정리하려고 한다. 먼저 당시의 문제 상황을 간단히 정리해보자.
배경
특정 기능의 성능 테스트를 진행하는 과정에서 Redis를 이용한 분산 락으로 인해 병목 현상이 발생하는 것을 발견했다.
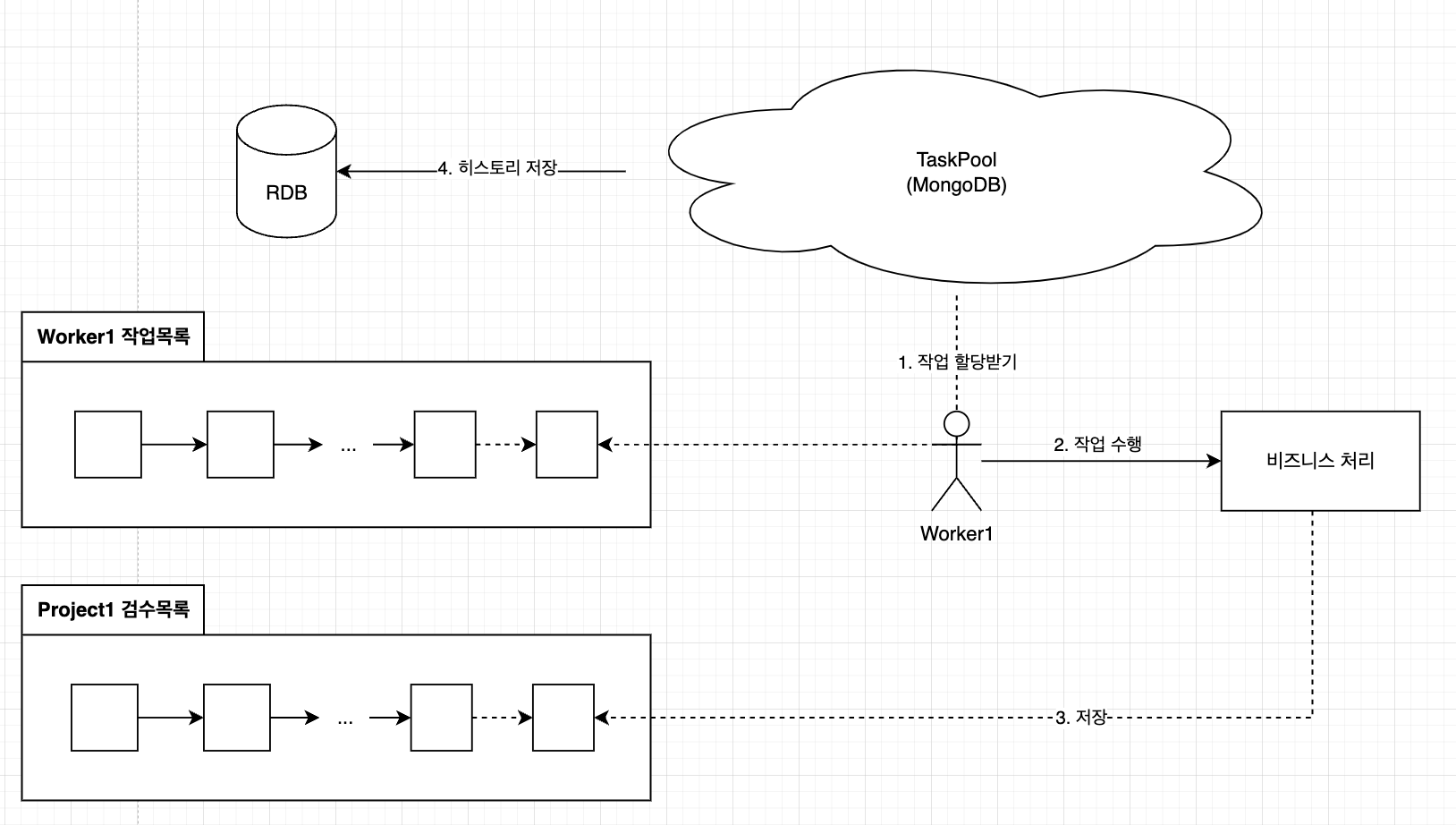
해당 기능은 사용자가 작업을 가져와 처리한 후 결과를 저장하는 프로세스였다.
기존 구조
기존 구조는 다음과 같은 특징이 있었다.
- 작업(Task)은 프로젝트(Project)에 속해있으며, 각 프로젝트는 여러 개의 작업을 포함한다. (Project : Task = 1 : N)
- 각 사용자는 서로 독립적인 작업을 할당받아 수행한다. (하나의 작업을 동시에 여러 사용자가 처리하지 않는다.)
- 작업은 MongoDB에 저장되며, 복잡한 JSON 구조로 이루어져 있다.
- 각 작업은 두 개의 링크드 리스트로 관리하고 있었다.
- 할당 링크드 리스트: 작업이 사용자에게 할당되는 순서를 관리한다.
- 검수 링크드 리스트: 작업 완료 후 검수 순서를 관리한다.
- 작업자가 작업을 완료하면 검수 링크드 리스트를 다음과 같이 갱신한다.
- 현재 작업의 이전/다음 검수 작업을 찾는다.
- 이전/다음 작업과 현재 작업을 서로 연결한다.
- 변경 사항을 MongoDB에 저장한다.
- 검수가 완료된 작업은 목록에서 제거된다.
이 과정에서 크게 두 가지 API 호출이 발생하고 있었다.
1. 새로운 작업 할당받기
작업자가 새로운 작업을 요청할 때 발생하는 과정이다.
- 진행 중인 작업이 있는지 확인한다.
- MongoDB의
findAndModify를 사용해 동시성을 제어하며 새 작업을 조회하고 할당받는다. - 이전 작업을 조회하고, 이전 작업과 새로 할당받은 작업을 연결한 후 MongoDB에 저장한다. (성능 병목 지점)
- 최종적으로 RDB에 변경 이력을 저장한다.
2. 작업 완료 처리
사용자가 작업을 완료한 후 발생하는 과정이다.
- 현재 사용자가 할당받은 작업이 맞는지 확인한다.
- 비즈니스 로직을 수행한다.
- 이전 작업과 다음 작업을 각각 조회한다.
- 이전 작업, 다음 작업, 현재 작업을 연결하여 MongoDB에 저장한다. (성능 병목 지점)
- 할당 링크드 리스트에서도 현재 작업과 연결된 이전/다음 작업을 조회한다.
- 현재 작업을 제거하고 이전/다음 작업을 다시 연결하여 저장한다. (성능 병목 지점)
- 최종적으로 RDB에 변경 이력을 저장한다.
강조한 부분들이 성능 병목 현상의 원인이 되었다.
문제 분석 및 개선 필요성
위 내용을 보면, 링크드 리스트 관리가 복잡하고 비효율적이라는 점을 알 수 있다.
링크드 리스트를 도입한 이유는 이전/다음 작업을 조회할 때 링크의 ID를 통해 빠르게 접근하기 위함이었다. 당시에는 조회 성능이 저장 성능보다 더 중요할 것으로 판단해 이 구조를 선택했다.
하지만 실제 사용 환경에서 빈번히 발생하는 저장 작업의 부하를 제대로 고려하지 않아 오히려 성능이 크게 저하되는 원인이 되었다.
주요 문제점 정리
- 링크드 리스트 관리를 위해 MongoDB의 여러 번 읽기/쓰기 연산이 발생했다.
- 분산 환경에서 원자성을 유지하기 위해 Redis의 분산 락을 사용했으며, 락의 범위가 개별 작업(Task)이 아닌 프로젝트(Project) 단위로 설정되어 있어 성능 저하가 더욱 심각해졌다.
- MongoDB 트랜잭션까지 동시에 사용해 락의 대기 시간이 증가했다.
즉, 링크드 리스트를 사용해 얻는 조회 성능 향상보다, 이를 관리하기 위한 저장 시 발생하는 지연이 훨씬 컸다. 또한 락의 범위가 지나치게 넓어 병목이 심해진 구조였다.
개선 내용
링크드 리스트를 제거했을 때 작업 흐름이 얼마나 간소화되는지 확인해보자.
1. 새로운 작업 할당
기존 (개선 전)
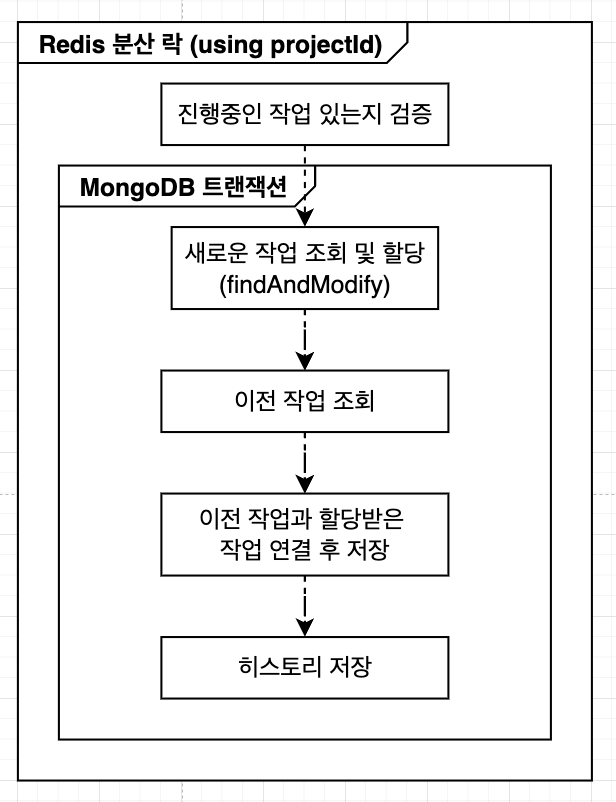
개선 후
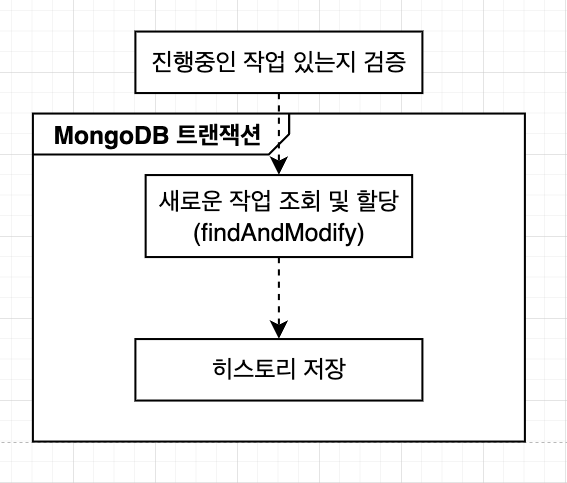
개선된 점
- 분산 락 제거: 할당 시 Redis의 분산 락이 불필요해졌다. 대신 MongoDB의 내장 트랜잭션과
findAndModify를 사용해 원자성을 충분히 보장할 수 있게 되었다. - 불필요한 조회 및 저장 로직 제거로 코드가 단순화되고 관리가 쉬워졌다.
- 추가적인 성능 향상이 필요하면, 작업 히스토리 저장은 별도의 이벤트 처리 시스템으로 분리하여 비동기 처리할 수 있다.
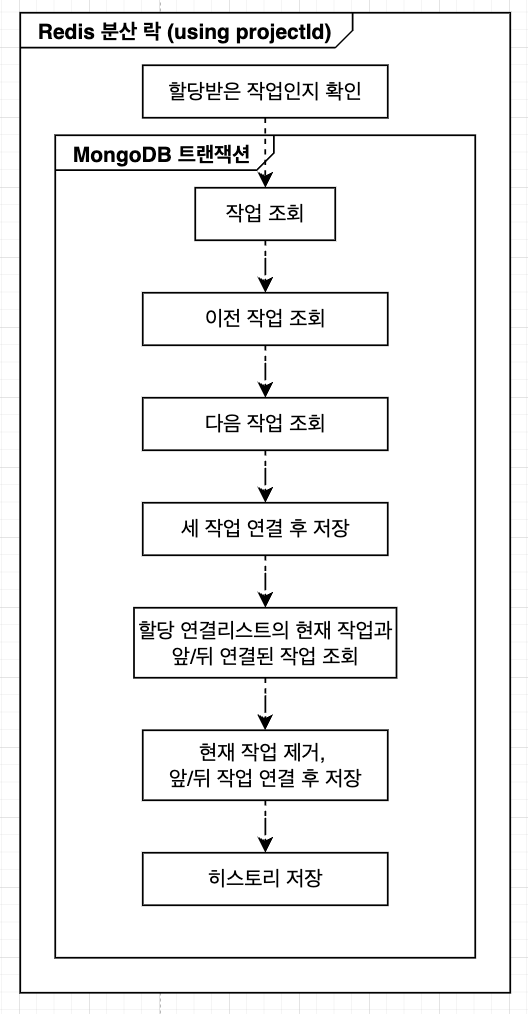
2. 작업 완료 처리
기존 (개선 전)
개선 후
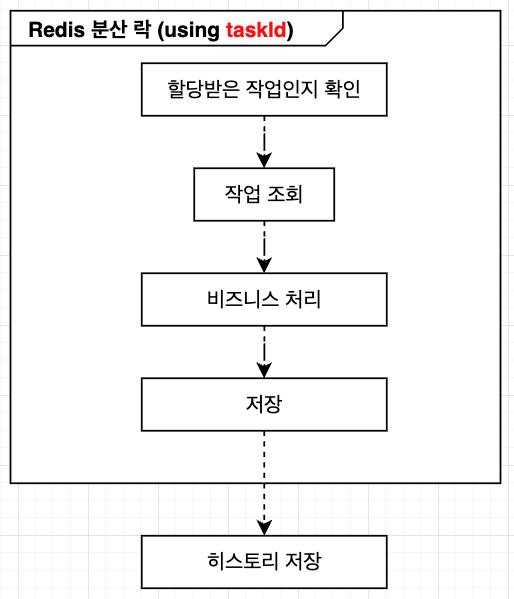
개선된 점
- 링크드 리스트 제거로 조회 및 저장 과정이 크게 단순화되었다.
- 분산 락의 범위를 기존의 Project 단위에서 개별 Task 단위로 더 세부화하여 동시성 관리가 효율적으로 개선되었다.
- 기존에는 Redis 분산 락과 MongoDB 분산 트랜잭션을 중복 사용했으나, 링크 관리가 없어지면서 MongoDB의 분산 트랜잭션은 제거할 수 있었다.
- 히스토리 저장 로직은 시스템에 큰 영향을 주지 않으므로, 트랜잭션이나 분산 락 범위에서 제외하고 독립적으로 비동기 처리하도록 구성했다.
테스트
개선이 끝났고, 다시 성능테스트를 진행했다.

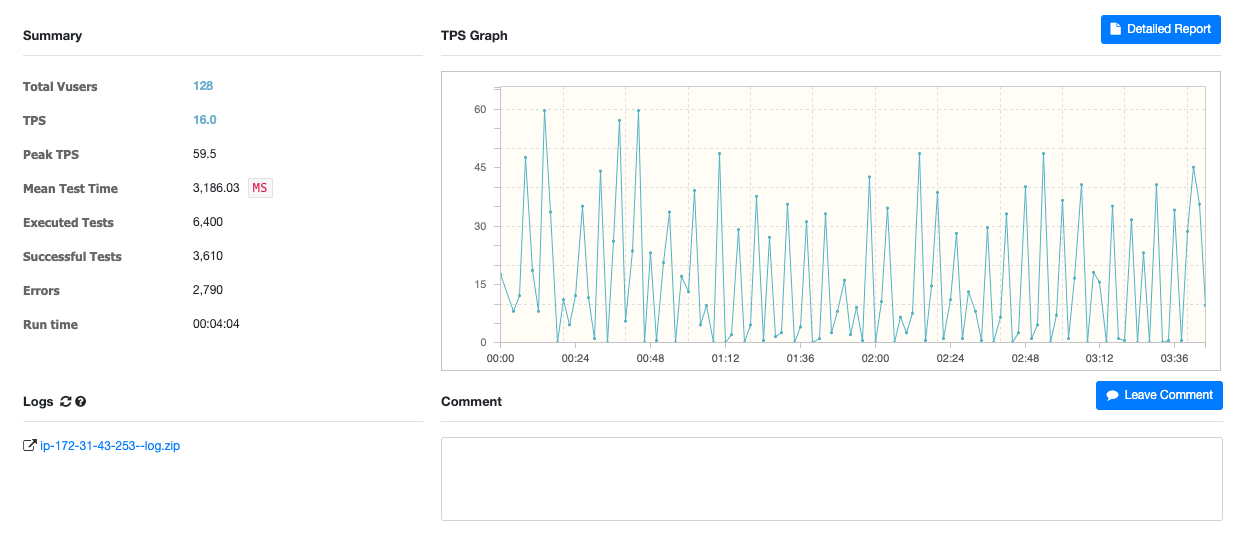
테스트 결과 요약
| 구분 | Mean TPS 증가율 | Peak TPS 증가율 | MMT 감소율 |
|---|---|---|---|
| 1차 테스트 | 487.5% | 135.29% | 67.1% |
| 2차 테스트 | 470.63% | 150.42% | 65.22% |
| 3차 테스트 (VUser 약 2배 증가) | 590.63% | 182.35% | 35.40% |
| --------------------------- | --------------- | ---------------- | ------------ |
| 동일 부하 테스트 (1, 2차 평균) | 479.07% | 142.86% | 66.16% |
| 부하 2배 증가 테스트 (3차 테스트 결과) | 590.63% | 182.35% | 35.40% |
동일 부하 조건에서는 평균 TPS가 약 4.8배 증가, 응답시간(MMT)은 약 66% 감소했습니다.
VUser를 2배 증가시킨 상황에서도 평균 TPS가 약 5.9배 증가, 응답시간은 약 35% 감소한 것으로 나타나, 부하가 크게 증가한 환경에서도 높은 개선 효과가 있음을 입증했습니다.
성능 개선이 가능했던 이유
- 링크드 리스트 제거로 인해 여러 번의 조회 및 저장 작업이 단순화되었다.
- 기존의 분산 락이 프로젝트 단위로 설정되어 병목이 발생했지만, 링크드 리스트 제거 후 각 Task별 원자적 처리가 가능해져 락을 Task 단위로 세부화할 수 있었다.
- MongoDB의 내장 트랜잭션과
findAndModify를 통해 개별 작업 처리의 원자성을 보장할 수 있어, 추가적인 Redis 분산 락이 불필요해졌다. - 히스토리 저장 로직은 비즈니스 로직이나 데이터 무결성에 큰 영향을 주지 않기 때문에, 성능과 운영 효율을 높이기 위해 비동기적으로 분리 처리했다.
앞으로의 개선 방향
- 성능을 추가로 높이려면, 히스토리 저장이나 로그 기록 같은 비핵심 로직을 이벤트 기반 비동기 처리 시스템으로 전환하여 처리량을 더욱 증대시킬 수 있다.
