
앞의 글에서 배열을 사용했을 때의 과정과 한계에 대해 경험했다.
하지만, 배열의 index를 활용하는 과정에서 배열의 순회가 불가피 했으며 이는 비효율적인 연산이라 판단했다.
따라서, 2차 시도에서는 다른 자료구조를 선택하게 되었다.
2차 시도: 연결 리스트
배열 이외의 다른 자료구조를 고려하면서 가장 먼저 떠오른 자료구조가 연결 리스트였다.
(문자의 삽입/삭제가 빈번히 발생할 것이기 때문)
우리는 문자열을 다루게 될 것이고 문자열은 문자들이 일렬로 늘어선 것이라 생각했다.
이는 연결 리스트를 이용해 구현할 수 있었으며 왼쪽에서 오른쪽으로 글을 읽듯이 연결 리스트를 활용할 수 있다고 생각했다.
단, 이중 연결 리스트 까지는 불필요 할 것으로 판단했다.
Head 부터 마지막 Node 까지 순회하는 경우 밖에 없을 것이라 생각했다.
(글을 거꾸로 읽을 일이 없을 것이며, 기본적인 연결 리스트로도 모두 구현이 가능 할 것이라 생각)
배열을 사용할 때와 마찬가지지만 다시 한 번 글자를 입력할 때 고려할 사항을 확인해보면 다음과 같다.
1. 어느 index에
2. 어떤 글자를 삽입하는지
출력의 경우는 연결 리스트를 한 번 순회하면서 출력할 수 있다.
이는 배열을 순회할 때 걸리는 시간과 동일한 시간인 O(N)이 소모될 것으로 보인다.
서로 다른 사용자가 같은 위치에 서로 다른 글자를 입력하는 경우에는 충돌이 발생한다.
이를 해결하기 위해 우선 순위를 정하는 등의 방법을 통해 일관성 있는 데이터를 생성해야 한다.
(배열을 사용할 때는 index, time, id)
| a | b | c |
|---|---|---|
| 0 | 1 | 2 |
(초기 문자열)
| a | b | x | c |
|---|---|---|---|
| 0 | 1 | 2 |
(A가 b 뒤에 x를 삽입)
| a | b | y | c |
|---|---|---|---|
| 0 | 1 | 2 |
(B가 b 뒤에 y를 삽입)
위와 같은 경우는 기존에 입력 시간을 기준으로 우선 순위를 설정하고 입력 시간이 동일한 경우는 id를 기준으로 정렬했었다.
연결 리스트에서도 이 방법을 활용하기 위해 Node가 해당 정보를 갖도록 구성한다.
class Identifier {
time: number;
id: string;
constructor(time: number, id: string) {
this.time = time;
this.id = id;
}
}
class Node {
identifier: Identifier;
letter: string;
nextNode: Node | null;
constructor(id: string, letter: string, time: number) {
this.identifier = new Identifier(time, id);
this.letter = letter;
this.nextNode = null;
}
}연결 리스트의 각 노드는 데이터 (a, b, x와 같은 문자)와 구분자 (Node를 구분할 수 있는 time, id 등의 정보)를 갖도록 구성한다.

(Node의 정보)
위와 같은 데이터 구조를 갖고 print를 입력하는 경우 결과는 위와 같을 것이다.
(단, 0번 index는 head)
위의 Node를 활용한 연결 리스트를 사용하여 CRDT를 구성해보면 다음과 같다.
export default class CRDT {
id: string;
head: Node | null;
constructor(id: string) {
this.id = id;
this.head = null;
}
insertLocal(index: number, letter: string, time: number) {
const newNode = new Node(this.id, letter, time);
newNode.nextNode = this.searchNodeByIndex(index);
if (index - 1 <= 0) {
this.head = new Node(this.id, '', 0); // head가 없는 경우이므로 head를 먼저 생성
this.head.nextNode = newNode;
} else {
this.searchNodeByIndex(index - 1)!.nextNode = newNode;
}
console.log(this.toString());
return newNode;
}
removeLocal(index: number) {
console.log(index, '노드를 삭제');
this.searchNodeByIndex(index - 1)!.nextNode = this.searchNodeByIndex(index + 1);
console.log(this.head)
console.log(this.toString())
return index;
}
insertRemote(index: number, node: Node) {
this.insertLocal(index, node.letter, node.identifier.time);
}
removeRemote(index: number) {
this.removeLocal(index);
}
searchNodeByIndex(index: number): Node | null {}
toString(): string {}
}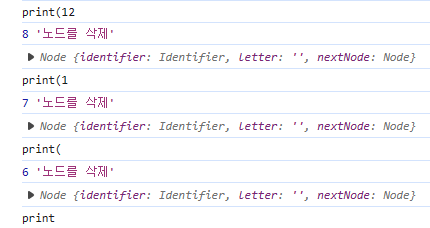
(print(1234)에서 글자를 삭제하는 경우)
달라진 점은 기존에는 인덱스로 정확하게 글자의 정보를 얻을 수 있었지만, 연결 리스트를 활용하기 때문에 searchNodeByIndex라는 메소드가 추가되었다는 것이다.
또한, 연결 리스트는 head로 부터 출발하기 때문에 head 노드가 없다면 생성하는 과정이 추가되었다.
이렇게 만들어진 알고리즘은 Node를 서로 주고 받을 수 있도록 구성했다.
(전체 연결 리스트가 아니라 Node를 주고 받는 것이다. 위에서 삽입/삭제시 Node를 생성하여 연산을 수행하고 Node를 반환한다. 반환된 Node를 외부에 있는 WebRTC DataChannel을 이용해서 전송하는 것)
단, Node가 삭제된 것인지 생성된 것인지는 외부에서 판단하여 적절한 메소드를 호출하도록 구성했다.
외부에서 값을 받은 경우 (Remote) 외부에서 전송된 Node의 내용을 토대로 자신의 상태를 업데이트 했다.
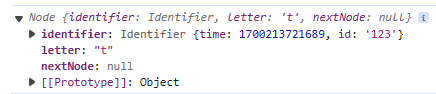
위와 같은 Node를 수신하게 되면 해당 Node의 정보를 토대로 자신의 연결 리스트에 추가하도록 했다.
각 Node는 고유하기 때문에 어떤 순서로 삽입하더라도 같은 결과를 반환할 것을 보장한다.
1차 시도와의 차이점
위의 내용만 봤을 때는 배열을 사용한 1차 시도와 다른 점이 없는 것 처럼 보인다.
똑같이 유니크한 데이터를 만들고, 자신의 CRDT에 추가, 원격으로 전송의 과정을 갖는다.
1차 시도에서 Node의 index가 결과에 영향을 미쳤다면 (index가 유의미한 값을 갖는다)
2차 시도에서 Node의 index는 단지 어느 위치에 삽입될 지를 알려주는 정보일 뿐 그 이상의 의미를 갖지 않는다.
다시 말해, 1차 시도에서는 index가 정렬에 활용되기 때문에 로컬에서는 3, 4, 5, 6, 3, 4, 5, 6이 되지만 원격에서는 3, 3, 4, 4, 5, 5, 6, 6이 되었다.
1234가 있을 때 앞에 test가 추가된다면 순서대로
t: 0번 인덱스 (로컬: t1234 / 원격: t1234)
e: 1번 인덱스 (로컬: te1234 / 원격: t1e234 => 1번 인덱스에 해당하는 글자는 e와 2이며 같은 인덱스라면 나중에 추가된 것이 앞에 오는 규칙 때문)
s: 2번 인덱스 (로컬: tes1234 / 원격: t1e2s34 => 위와 동일)
t: 3번 인덱스 (로컬: test1234 / 원격: t1e2s3t4 => 위와 동일)
하지만, 2차 시도에서의 index는 단순히 어느 위치에 삽입되는지에 관한 정보이며 정렬에 활용되지 않았다.
1234가 있을 때 앞에 test가 추가된다면 순서대로
t: 0번 인덱스에 추가 (t1234)
e: 1번 인덱스에 추가 (te1234)
s: 2번 인덱스에 추가 (tes1234)
t: 3번 인덱스에 추가 (test1234)
인덱스가 정렬에 활용되지 않고 "특정 위치에 삽입"이라는 정보이므로 어떤 문자열이 있더라도 해당 위치에 글자를 삽입한다면 같은 결과가 될 것이다.

위 사진과 같이 어떤 글자를 어느 위치에 삽입하는지에 관한 정보를 활용한 것이다.
결과
2차 시도는 1차 시도와 다르게 병합이 제대로 수행되었다.
고유한 Node를 생성하고 연결 리스트를 사용하여 Node 들을 관리했다.
배열을 활용한 방식과 어느 정도 유사하지만 index를 다루는 방식의 차이가 있었다.
그 결과 원하는 기능을 수행할 수 있게 되었지만 몇 가지 문제점이 남아있다.
현재 상태로는 여러 글자를 생성하거나 삭제할 수 없다.
(붙여넣기 또는 드래그를 통한 복수 글자 삭제)
또한, 데이터 교환을 위해 네트워크를 사용하고 있는 상황에서 네트워크 지연 등의 문제로 상대방의 변경 사항을 반영하기 전에 로컬에서 변경점이 생기는 경우(충돌)에 대한 대비가 되어있지 않다.
연결 리스트가 정답은 아니다.
여러 가지 시도 중 하나일 뿐이고 아직 해결되지 않은 문제점이 많기에 정답이 아니라 배열 보다 조금 더 나은 방법으로 보는 것이 맞을 것이다.
(연결 리스트로 해결할 수 없다면 또 다른 자료구조를 활용해야 할 것이다...)
