평균은 넘겠지 - 4344번
문제
대학생 새내기들의 90%는 자신이 반에서 평균은 넘는다고 생각한다. 당신은 그들에게 슬픈 진실을 알려줘야 한다.
입력
첫째 줄에는 테스트 케이스의 개수 C가 주어진다.
둘째 줄부터 각 테스트 케이스마다 학생의 수 N(1 ≤ N ≤ 1000, N은 정수)이 첫 수로 주어지고, 이어서 N명의 점수가 주어진다. 점수는 0보다 크거나 같고, 100보다 작거나 같은 정수이다.
출력
각 케이스마다 한 줄씩 평균을 넘는 학생들의 비율을 반올림하여 소수점 셋째 자리까지 출력한다.
풀이
입력 예시가 이러하니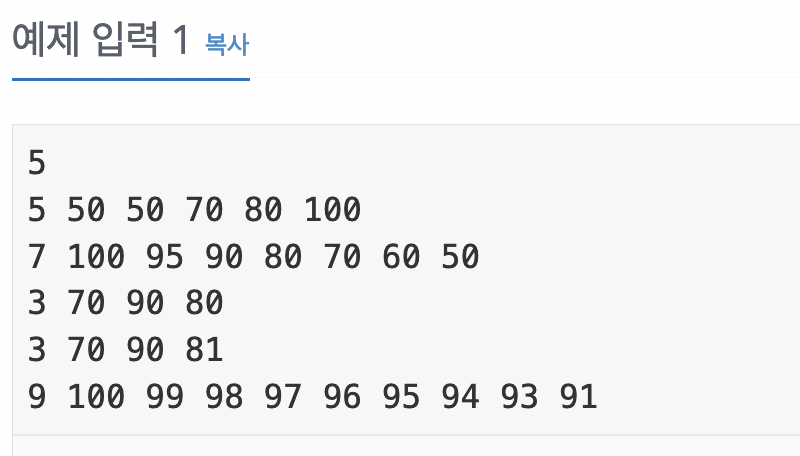 반복문 전에, 입력값의 맨 처음 값을 input을 한 번 받고 반복문을 돌린다. 반복은 처음 받았던 입력값의 첫번째 라인(int형)만큼 range를 설정한다.
반복문 전에, 입력값의 맨 처음 값을 input을 한 번 받고 반복문을 돌린다. 반복은 처음 받았던 입력값의 첫번째 라인(int형)만큼 range를 설정한다.
반복문 안에서는 공백으로 split처리한 list로 입력값을 받되 리스트의 2번째(index 1) 요소부터 끝까지를 받는다.
여기까지의 식 표현이 아래와 같다.
import sys
input = sys.stdin.readline
c = int(input()) # 첫째 줄에는 테스트 케이스의 개수 C가 주어진다.
for i in range(c):
arr = list(map(int, input().split()))
scores = arr[1:]
.
.이제 리스트 변수 scores에 대한 각 요소들의 총합, 즉 N명의 점수를 총합한 수를 학생의 명수, 즉 arr[0]로 나누어 평균을 낸다. 그런 뒤 반복문으로 리스트 변수 scores 안에서 그 평균의 점수보다 높은 요소들이 몇 명인지를 파악한다.
위까지의 식 표현을 하면 아래가 된다.
import sys
input = sys.stdin.readline
c = int(input()) # 첫째 줄에는 테스트 케이스의 개수 C가 주어진다.
for i in range(c):
arr = list(map(int, input().split()))
scores = arr[1:]
avrge = sum(scores)/arr[0]
p = 0
for score in scores:
if score > avrge:
p += 1
.
.변수 p에 평균보다 높은 점수를 받은 학생의 수. arr[0]을 p로 나누면 곧 평균을 넘는 학생들의 비율이 된다.
p/arr[0]이 비율을 나타내는 실수를 반올림하여 소수점 셋째 자리까지 출력한다. 콘솔로 어떻게 나오는지 확인해보았다. 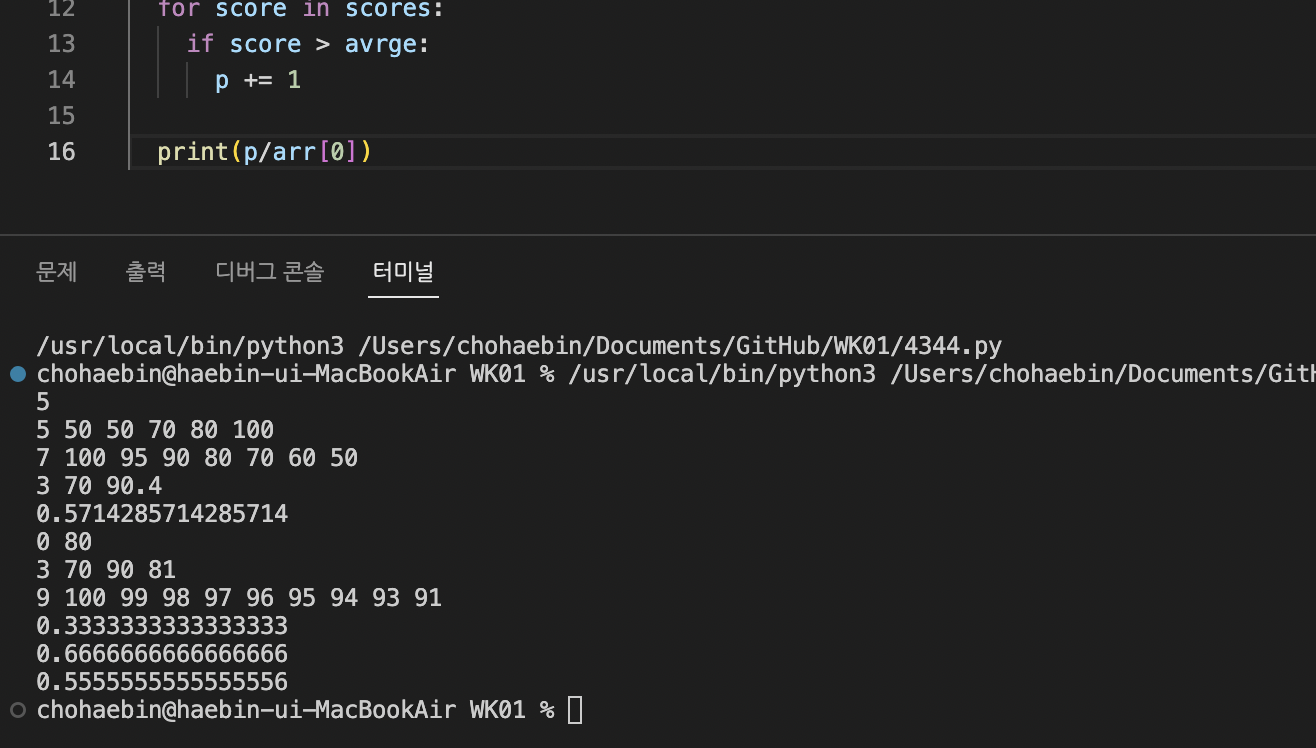
이때 황당했던 것은 터미널로 테스트를 돌릴 시, 입력한 값이랑 출력한 값이 순서대로 나오지 않고 속도때문에 밀려서 섞여나온다는 것이었다. 이 예제 입력과 예제 출력을 참고해서 보면,  위 콘솔에서 3 70 90.4 / 0.5714285714285714 / 0 80 라인은 입력값의 4번째 라인에 "3 70 9...."가 차마 다 터미널에 찍히기 전 2번째 입력값의 출력값인 0.4가 먼저 터미널에 찍힌 것이고, 그 다음에 2번째 입력값의 출력값인 0.57143... 이, 그 다음 입력값의 4번째 라인 나머지 내용이던 "...0 80"이 찍힌 것... 어이없다ㅠㅠ...
위 콘솔에서 3 70 90.4 / 0.5714285714285714 / 0 80 라인은 입력값의 4번째 라인에 "3 70 9...."가 차마 다 터미널에 찍히기 전 2번째 입력값의 출력값인 0.4가 먼저 터미널에 찍힌 것이고, 그 다음에 2번째 입력값의 출력값인 0.57143... 이, 그 다음 입력값의 4번째 라인 나머지 내용이던 "...0 80"이 찍힌 것... 어이없다ㅠㅠ...
어쨌든, 그리고 반례들에 대한 방어로 반복문을 수정해보았다.
import sys
input = sys.stdin.readline
c = int(input())
for i in range(c):
arr = list(map(int, input().split()))
scores = arr[1:]
avrge = sum(scores)/arr[0]
p = 0
for j in range(len(scores)):
if scores[j]>avrge:
p += 1
.
.입력된 시험 점수보다 변수 scores의 length가 더 길 경우를 고려.
그리고...
이제 퍼센테이지로 나타내야 하는데 실수를 소수 n자리까지 반올림하고 출력하는 법은 몇 가지가 있다.
풀이 1
우선 f-string을 이용한다.
문자열내에서 값을 삽입하는 것을 포맷팅(formating)이라고 한다.
https://bodhi-sattva.tistory.com/67
f'{num}'는 num을 출력하는데, 아래 예제와 같이 :.nf를 붙이면 소수 n자리까지 반올림하고 그 값을 출력한다.
n = 3.1415926535
print(f'{n}')
print(f'{n:.3f}')
print(f'{n:.6f}')위의 코드는 출력이 다음과 같다.
3.1415926535
3.142
3.141593f-string을 활용한다면 최종 답의 print식이 다음과 같다.
print(f'{p/arr[0]*100:.3f}%')풀이 2
정식으로 format()을 써보자.
https://planharry.tistory.com/11
print('{0:.3f}%'.format(p/arr[0]*100))만약, 퍼센테이지만 출력해도 됐었으면 아래와 같이 포맷 코드(예: %ㅇd, %s, %f....)를 사용했어도 된다.
# print('%0.3f' % (p/arr[0]*100)) # 퍼센테이지 숫자만그래서 최종적으로, 다음이 정답인 코드다.
import sys
input = sys.stdin.readline
c = int(input())
for i in range(c):
arr = list(map(int, input().split()))
scores = arr[1:]
avrge = sum(scores)/arr[0]
p = 0
for j in range(len(scores)):
if scores[j]>avrge:
p += 1
print('{0:.3f}%'.format(p/arr[0]*100)) # 답
# print(f'{p/arr[0]*100:.3f}%') # 답
# print('%0.3f' % (p/arr[0]*100)) # 퍼센테이지 숫자만 답으로 제출할 때
# print(str(round(p/arr[0], 5)*100)+'%') # 오답오답에 대해
다만 round()를 사용해서 string으로 답을 출력하려 했더니 틀렸다.
제출했던 오답은 다음과 같다.
# print(str(round(p/arr[0], 5)*100)+'%') # 오답아직 정확하게 이게 왜 안 되는지 아직 설명할 순 없으나 확실한 건 python의 print문 안에서 함수나 연산 처리를 하는 것은 바람직하지 않다는 점이다. 아예 불가능한가? 실험 안 해봄...
