
HTTP/2의 등장
이전 글에서 알아본 대로, HTTP/1.1은 HTTP/1이 20년 이상 사용되며 발전해온 버전이었습니다.
Host 헤더를 통해 하나의 서버에서도 여러 도메인을 서빙할 수 있게 되었고, 지속적 커넥션을 통해 TCP 연결을 재사용하여 성능과 대역폭 사용의 효율성을 크게 높일 수 있었습니다.
다만, 인터넷 생태계가 확장됨에 따라 아무리 커넥션을 유지한다 하더라도 HTTP/1은 본질적으로는 단일 요청/응답 방식을 사용하기 때문에 여전히 성능적인 한계가 존재했습니다. 일반적으로 한번의 하나의 리소스만 응답할 수 있었기 때문이죠.
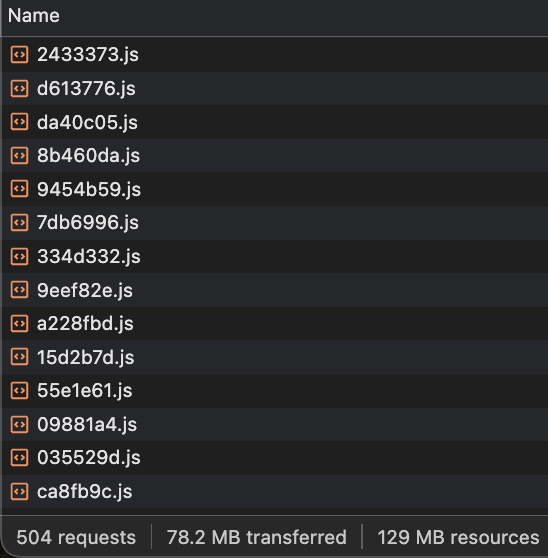
- 위 그림은 모 쇼핑몰 페이지 하나를 로딩한 결과입니다. 이 페이지는 총 500개 이상의 리퀘스트를 통해 수많은 문서와 이미지, 동영상을 보여줍니다.
SPDY 프로토콜의 등장
위에서 다룬 HTTP/1의 근본적인 문제를 해결하기 위해 다양한 시도가 있어왔고, 그 중 가장 유력한 것이 바로 구글에서 개발한 SPDY 프로토콜입니다. 이 프로토콜에서는 프레이밍, 멀티플렉싱, 헤더 압축이라는 세 가지 주요 개념을 도입했습니다.
프레이밍(Framing)
프레이밍이란, 수신자가 보다 정확하고 빠르게 데이터를 처리 할 수 있도록 데이터를 포장하는 방식이라고 볼 수 있습니다. 이를 간단하게 예시를 들어, HTTP/1.1의 문제점을 짚어보도록 하겠습니다.
-
HTTP/1.1 요청의 예시
GET /home HTTP/1.1\r\n Host: localhost:3000\r\n Connection: keep-alive\r\n Pragma: no-cache\r\n Cache-Control: no-cache\r\n Upgrade-Insecure-Requests: 1\r\n User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) \r\nAppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 \r\nSafari/537.36\r\n Accept: text/html,application/xhtml+xml,application/xml;q=0.\r\n9,image/avif,image/webp,image/apng,*/*;q=0.8,application/\r\nsigned-exchange;v=b3;q=0.7\r\n Accept-Encoding: gzip, deflate, br, zstd\r\n Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7,ja;q=0.6\r\n \r\n
위와 같은 텍스트 기반의 HTTP/1.1(이하 h1) 요청을 파싱하고 이해하는 것은 크게 어려운 문제는 아닙니다.
하지만 바이너리를 직접 활용한다면 이보다 더 빠른 속도로 데이터를 처리할 수 있습니다.
또한, h1에서는 구분자로 \r\n(crlf)를 사용하고 있는데, 일부 표준을 따르지 않는 사용자들이 \n만을 사용하는 경우도 있을 수 있습니다.
마지막으로 이러한 방식은 요청을 받는 시점에서 전체 길이를 미리 알 수도 없어 이를 메모리에 모두 올릴 수 있다는 보장도 없습니다.
이러한 문제를 해결하기 위해 HTTP/2(이하 h2)에서는 프레이밍을 도입했습니다.
정규화된 프레임 구조를 사용함으로써 요청의 길이를 미리 알 수 있게 되었고, 텍스트가 아닌 바이너리로 인코딩하여 전송함으로써 더 빠르고 안정적인 데이터 전송을 가능하게 했습니다.
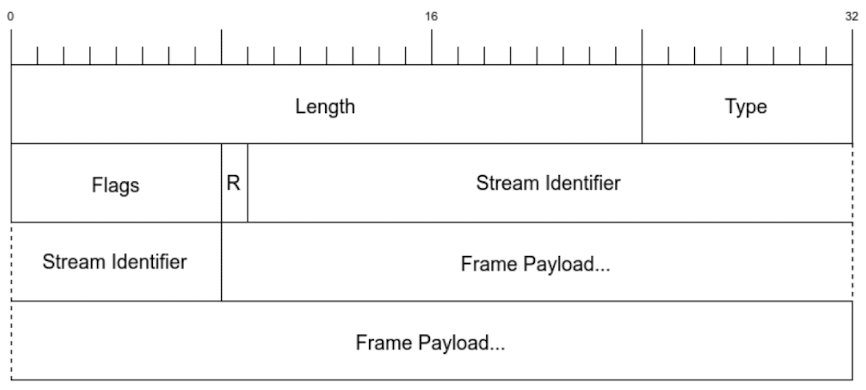
HTTP/2는 더이상 텍스트 기반의 프로토콜이 아니다.
HTTP/2는 바이너리를 사용하여 더 빠르고 안정적인 데이터 전송을 가능하게 했다.
물론 텍스트 기반이라는 점이 h1의 큰 장점이었기에, 이러한 변화는 호환성 문제를 야기할 수 있습니다. 실제로 이러한 문제로 인해 아직까지도 많은 웹사이트들이 h1을 사용하고 있습니다.
그러나 이러한 변화로 인해 h2는 더 빠르고 안정적인 데이터 전송을 가능하게 했으며, 이는 더 빠른 웹 페이지 로딩 속도와 더 적은 대역폭 사용을 가능하게 했습니다.
멀티플렉싱(Multiplexing)
이전 글에서 언급하지 않았지만, h1에는 deprecated된 pipelining이라는 기능이 존재했습니다. 이 기능은 하나의 TCP 연결 안에서 여러 요청을 동시에 보내 다수의 요청을 빠르게 처리하고자 하는 목적으로 등장했었습니다.
그러나 이 기능은 아래와 같은 점에서 치명적인 문제가 발생했습니다.
- 파이프라인의 설계상, 요청은 무조건 순서대로 처리되어야 한다.
- 인터넷은 불안정하다. 따라서 요청이 중간에 끊기거나, 응답이 늦어지는 경우가 발생한다.
위 두 가지 문제점으로 인해, pipelining은 HOL(Head of Line) Blocking이라는 문제를 야기하게 되었습니다. 이는 하나의 요청이 지연되면 그 이후의 모든 요청이 지연되는 현상을 의미합니다.
이러한 문제를 해결하기 위해 h2에서는 멀티플렉싱을 도입했습니다.
눈썰미가 좋으시다면, 이전 프레임 구조에서 Stream Identifier라는 필드를 보셨을 수 있습니다.
이 필드는 각각의 프레임이 어떤 요청에 대한 응답인지를 식별하기 위한 필드로, 이를 통해 h2는 하나의 TCP 연결 안에서, 순서에 구애받지 않고 여러 요청을 동시에 처리할 수 있게 되었습니다.
여기서 h1의 keep-alive와 h2의 멀티플렉싱을 비교해보면, 두가지 모두 TCP 연결을 재사용하여 성능을 향상시키는 목적을 가지고 있습니다. 그러나 h1의 keep-alive는 여러 요청을 동시에 보내더라도 하나의 TCP커넥션에 대해서는 한가지 요청씩 순차적으로 처리되었지만, h2의 멀티플렉싱은 여러 요청을 동시에 보내고 동시에 처리할 수 있게 되었습니다.
구체적으로 이야기해 보자면, TCP 커넥션을 동시에 6개 사용하는 일반적인 브라우저에서는 어떤 사정으로 인해 6개의 커넥션에서 각각 하나씩의 패킷 전송이 지연되면 모든 통신이 먹통이 됩니다. 하지만 h2의 경우, streamID를 통해 사실상 무제한의 스트림을 이용 할수 있고, 하나의 스트림이 지연되더라도 다른 스트림의 전송에는 영향을 끼치지 않습니다.
HTTP/2는 하나의 TCP 연결 안에서 여러 요청(스트림)을
동시에처리할 수 있게 되었다.
또한 추가적으로, 동시에 처리되는 요청들의 특성상 필수적인 우선순위를 지정하고 제어하는 기능, PUSH_PROMISE라는 프레임과 멀티플렉싱을 사용한 서버 푸시(Server Push) 기능을 사용할 수 있게 되었으며, 이를 통해 클라이언트가 요청하지 않았지만 필요할 것으로 예상되는 리소스를 클라이언트에게 미리 전송할 수 있게 되었습니다.
헤더 압축(Header Compression)
마지막으로 h2가 해결한 문제점은 반복되는 헤더를 압축하여 제거했다는 점입니다.
-
HTTP/1.1의 헤더
GET /home HTTP/1.1\r\n Host: localhost:3000\r\n Connection: keep-alive\r\n Pragma: no-cache\r\n Cache-Control: no-cache\r\n Upgrade-Insecure-Requests: 1\r\n User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) \r\nAppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 \r\nSafari/537.36\r\n Accept: text/html,application/xhtml+xml,application/xml;q=0.\r\n9,image/avif,image/webp,image/apng,*/*;q=0.8,application/\r\nsigned-exchange;v=b3;q=0.7\r\n Accept-Encoding: gzip, deflate, br, zstd\r\n Accept-Language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7,ja;q=0.6\r\n \r\n
다시 한 번, 위에서 다룬 h1의 헤더들을 가져와 보았습니다. 그런데 자세히 보면, 이 헤더들은 매 요청마다 반복되는 부분이 많다는 것을 알 수 있습니다.
-
반복되는 헤더들
Host,Connection,Pragma,Cache-Control,Upgrade-Insecure-Requests,User-Agent,Accept,Accept-Encoding,Accept-Language
-
HTTP/2의 연속된 요청의 헤더들
-
요청 1
:authority: www.akamai.com :method: GET :path: / :scheme: https accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 accept-language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7,ja;q=0.6 cookie: some_cookie upgrade-insecure-requests: 1 user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ -
요청 2
:authority: www.akamai.com :method: GET :path: /scripts/main.js <--- 변경된 헤더 :scheme: https accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 accept-language: ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7,ja;q=0.6 cookie: some_cookie upgrade-insecure-requests: 1 user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
-
이러한 반복되는 헤더들은 매 요청마다 전송되어야 함에도 불구하고, 매 요청마다 변경되는 경우는 드물기 때문에 이는 매우 비효율적이라고 볼 수 있습니다.
이러한 문제를 해결하기 위해 h2에서는 헤더 압축을 도입했고 HPACK이라는 알고리즘을 사용하여 헤더를 압축하고 전송하게 되었습니다. 이 방식을 통해 h2에서는 대역폭을 평균적으로 30% 이상 줄일 수 있게 되었습니다.
+α TCP의 태생적인 한계
h2의 특징들을 다루는 과정에서 알게 된 h3가 등장하게 된 계기에는, TCP의 태생적 한계가 있습니다.
물론 TCP는 굉장히 안정적이고 신뢰도 높은 프로토콜입니다. 하지만 이런 점이 '더 빠른 속도'를 원하는 개발자들의 발목을 잡고있습니다.
TCP는 본질적으로 신뢰성 있는 데이터 전송을 보장하기 위해 설계되었습니다. 이를 위해 수많은 혼잡제어 매커니즘이 도입되었구요. 그러나 이제는, 이로 인해 최대 통신속도를 사용하지 못하게 되는 양날의 검이 되었습니다.
대표적인 혼잡 제어 알고리즘으로 TCP Reno가 있습니다. 이 알고리즘은 크게 네 가지 단계로 작동합니다.
1. 느린 시작(Slow start)
2. 혼잡 회피(Congestion Avoidance)
3. 빠른 재전송(Fast Retransmit)
4. 빠른 회복(Fast Recovery)
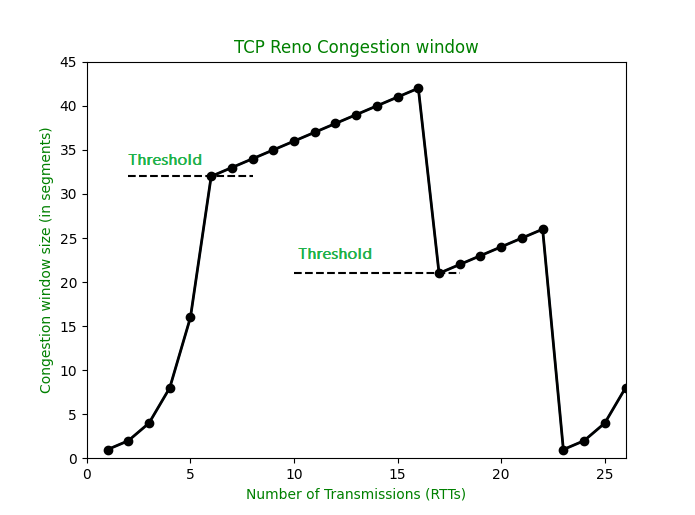
조금 더 자세히 다뤄보자면, TCP 연결이 맺어진 후 첫 통신은 '느린 시작'단계를 거칩니다. 이로인해 최대 속도가 아닌, 1MSS(Maximum Secment Size)로 시작하게 되고, 이후 통신이 성공할 때 마다 속도를 2배씩 늘려나갑니다.
계속해서 통신이 성공하면 이제는 '혼잡 회피' 단계에 들어섭니다. 이때부터는 속도가 2배가 아닌 1MSS씩 증가합니다. 즉, 느리게 증가합니다.
만약 통신이 제대로 이루어지지 않는다면 어떨까요? Reno는 중복된 ack를 세 번 받으면 이를 통신의 실패로 간주하고 해당 패킷을 재전송합니다. 이를 '빠른 재전송'이라고 하며 이 과정에서 '빠른 회복'을 위해 통신의 속도를 절반으로 줄입니다. 이후에는 다시 선형적으로 천천히 속도를 회복합니다.
위와 같은 혼잡 제어 매커니즘은 확실히 우리가 원하는 '빠른 통신속도'를 얻는데에는 부적절해 보입니다. 초기 전송속도도 느릴 뿐더러, 항상 문제가 있기 마련인 네트워크 상에서 문제가 발생할 때 마다 속도가 절반으로 줄어든다면 이는 확실히, 유리한 조건은 아닙니다.
HTTP/1.1과 HTTP/2의 비교

