전립선암 세포 병리영상을 학습하여 등급 분류
논문에서 사용한 대비 향상
- 영상 대비 향상 (Image Adjustment, IA),
- 히스토그램 균일화(Histogram Equalization, HE),
- 대비 제한 적응 히스토그램 균일화(Contrast-Limited Adaptive Histogram Equalization, CLAHE)
결과
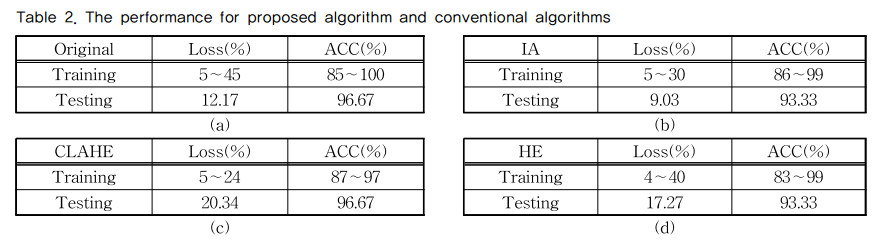
정확도는 원본과 CLAHE이 96%로 가장 높은 정확도를 얻었으며, 손실률에서는 IA가 9%로 가장 낮은 손실률을 보여주었다.
데이터
512x512크기의 격자로 나누고, 그 중 병리학자가 주석처리한 부분이 50%이상인 영상을 분활하여 JPG 형식의 부분 영상으로 저장
부분 영상에서 대비 향상 함수들을 적용시킨 영상들을 따로 생성하여 컨볼루션 신경망에 사용하였다. 각각의 등급에 300장의 영상들을 준비 8:2로 학습과 시험으로 나눔
원본, IA, HE, CLAHE 4가지 데이터 셋을 이용
사용한 영상 향상 기법
영상대비 향상(IA) : 대비 향상은 영상의 명암도를 높여주는 알고리듬이다. 기본적으로 원본 데이터의 낮고 높은 화소에 데이터의 1%가 포화상태가 되도록 값을 매핑하는 방식이다. 어두운 부분을 더 어둡게, 밝은 부분은 더욱 밝게 픽셀간의 대비를 향상시켜 주는 기능이다
히스토그램 균일화(HE) : 대비 향상은 영상의 명암도를 높여주는 알고리듬이다. 기본적으로 원본 데이터의 낮고 높은 화소에 데이터의 1%가 포화상태가 되도록 값을 매핑하는 방식이다. 어두운 부분을 더 어둡게, 밝은 부분은 더욱 밝게 픽셀간의 대비를 향상시켜 주는 기능이다.
대비 제한 적응 히스토그램 균일화(CLAHE) : 대비 제한 적응 히스토그램 균일화는 히스토그램 균일화와는 다르게 전체 영상이 아닌 작은 영역을 분할하여 동작한다. 또한 HE의 단점이었던 잡음 또한 대비 제한 방식을 사용하여 억제하는 방식이다.
사용한 컨볼루션 신경망 모델
VGGNet
- 다른 모델과 다른 간단한 구조와 단일 네트워크에서 좋은 성능을 보여줌
- ‘깊이(Depth)’가 어떻게 영향을 주는지 연구한 학습 모델이라는 것이다. 다른 학습 모델에서는 커널 크기를 사용한 중첩 층으로 모델을 만들지만 VGGNet 모델은 사용되는 커널의 크기를 3 × 3 화소로 고정하여 층의 깊이에 중점을 둔 모델이다
- 분석에 있어 다른 모델보다 비선형적이다. 커널의 크기를 3 × 3 화소로 고정하여 중첩 층을 사용하기 때문에 2중첩은 5 × 5와 동일한 수용영역을, 3중첩은 7 × 7과 동일한 수용영역을 처리하지만 더 비선형적 분류 및 분석이 가능하게 된다.
- 역전파(Back-Propagation)기능이 좋다. 층의 깊이가 깊어질수록 역전파기능이 깊이를 따라가지 못한다. 하지만 각 층에 사용되는 활성화 함수를 역전파의 기능이 뛰어난 ReLu함수로 사용하기 때문에 문제없이 역전파가 가능하다. 하지만 역전파에도 한계가 있기 때문에 16 층∼19 층 이상 사용하게 되면 오히려 학습 과정에서 오류가 증가하는 모습이 관측된다. 때문에 적절한 층의 사용이 중요한 사항이 된다.
사용한 컨볼루션 신경망 모델 구조
2중첩 층 및 3중첩 층을 사용하여 구조를 이루고 있으며, 각 층에 사용되는 커널의 크기는 동일하게 3 × 3을 사용하고 있다. 또한 활성화 함수 역시 ReLu를 공통으로 사용하고 있는 모습이다. VGGNet의 단점으로 언급한 층의 개수도 제한하여 만들었으며, 과적합(Overfitting)을 예방하기 위해 모델의 마지막에 드롭아웃(Drop Out) 층을 사용하였다.
2중첩 층 및 3중첩 층을 사용하여 구조를 이루고 있으며, 각 층에 사용되는 커널의 크기는 동일하게 3 × 3을 사용하고 있다. 또한 활성화 함수 역시 ReLu를 공통으로 사용하고 있는 모습이다. VGGNet의 단점으로 언급한 층의 개수도 제한하여 만들었으며, 과적합(Overfitting)을 예방하기 위해 모델의 마지막에 드롭아웃(Drop Out) 층을 사용하였다.
이전 연구를 바탕으로 3중첩 층을 먼저 사용하여 넓은 영역을 학습하도록 하였으며, 그 뒤에 2중첩 층를 사용하여 세밀한 부분을 학습하도록 하였다. 또한 입력 영상의 크기가 512 × 512 화소일 때, 마지막 맥스풀링(Max Pooling) 층을 지난 출력 영상의 크기는 11 × 11 화소가 되도록 설정하였다. 아래의 모델을 사용하여 전립선암 병리영상을 학습하여 영상을 양성과 악성으로 분류할 수 있도록 학습하였다.
실험 결과 및 고찰
대표적 양상으로는 세포 핵의 크기, 색, 밀도, 침습 등이 있다. 이로보아 세포 핵의 특징을 뚜렷이 나타낼 수 있는 방식을 찾았으며, 세포 핵과 배경과의 대비를 증가 시키는 방식을 선정하였다. 원본의 영상은 전체적으로 밝은 강도의 화소들이 많이 분포하고 있는 모습이며, IA 결과 영상은 원본 영상과 비교했을 때 히스토그램 분포의 양상은 비슷하지만 어둡고 밝은 부분이 증가되어 원본보다 대비가 벌려져 있는 모습이다. CLAHE의 경우 결과 영상으로만 보았을 때 IA 보다 어두운 부분이 증가 되어있는 것이 관찰되며, 히스토그램을 보았을 때 많은 부분이 어두운 명도(Intensity)부분으로 변경되어있는 것을 볼 수 있다. HE의 경우 CLAHE와는 다르게 대비한계(Contrast Limited)가 적용되지 않아 다른 결과들보다 많은 부분이 어두운 강도로 변경된 것을 볼 수 있는데,히스토그램을 보았을 때도 어두운 부분으로 상당량의 화소들이 변경된 것을 볼 수 있다.
1000epoch
손실도는 IA가 9.03%로 가장 낮았으며, 정확도는 원본과 CLAHE가 96.67%로 가장 높은 값까지 올라갔다
결론
본 논문에서는 대비 향상된 전립선암 병리영상을 사용하여 컨볼루션 신경망으로 사용된 영상을 양성
과 악성으로 분류해보았다. 하지만 검증 단계에서 손실(Loss)이 갑자기 치솟는 현상이 여전히 문제가 되고 있다. 또한 부족한 데이터의 문제 또한 해결되지 못 하였다. 이 후 연구에서는 데이터의 다양성을 높이고, ‘Skip-Connection’ 기능을 사용하여 학습 및 검증 단계에서 튀는 손실도를 해결할 수 있을 것으로 본다.
