Part 12. 오라클 데이터베이스 페이징 처리
12.2 order by 보다는 인덱스
- 데이터가 많은 상태에서 정렬 작업이 문제가 된다는 사실을 알았닫면, 이 문제를 어떻게 해결해야 하는지 살펴보려 한다.
- 가장 일반적인 해결책은 '인덱스'를 이용해서 정렬을 생략하는 방법이다.
- '인덱스'라는 존재가 이미 정렬된 구조이므로 이를 이용해 별도의 정렬을 하지 않는 방법이다.
- 우선 앞과 같은 상황에서 다음과 같은 SQL을 실행해 본다.
SELECT /*+ INDEX_DESC(TBL_BOARD PK_BOARD0 */ * FROM TBL_BOARD WHERE BNO > 0;
- 위의 SQL을 실행한 결과는 테이블 전체를 조사하고 정렬한 것과 결과는 동일하지만 실행 시간은 엄청 차이가 난다.
- 가장 중요한 점은 SQL의 실행 시간이 거의 2초 이하로 나온다는 점이다.
- SQL문의 실행 계획은 아래와 같다.
- SQL의 실행 게획에서 주의해서 봐야 하는 부분은 1) SORT를 하지 않았다는 점, 2) TBL_BOARD를 바로 접근하는 것이 아니라 PK_BOARD를 이용해 접근한 점, 3) RANGE SCAN DESCENDING, BY INDEX ROWID로 접근했다는 점이다.

12.2.1 PK_BOARD라는 인덱스
- TBL_BOARD 테이블을 생성했을 때의 SQL을 다시 한 번 살펴보면
CREATE TABLE TBL_BOARD ( BNO NUMBER(10,0), TITLE VARCHAR2(200) NOT NULL, CONTENT VARCHAR2(2000) NOT NULL, WRITER VARCHAR2(50) NOT NULL, REGDATE DATE DEFAULT SYSDATE, UPDATEDATE DATE DEFAULT SYSDATE ); ALTER TABLE TBL_BOARD ADD CONSTRAINT PK_BOARD PRIMARY KEY (BNO);
- 테이블을 생성할 때 제약 조건으로 PK를 지정하고 PK의 이름이 'PK_BOARD'라고 지정하였다.
- 데이터베이스에서 PK는 중요한 의미를 가지는데, 흔히 ㅁ라하는 '식별자'의 의미와 '인덱스'의 의미를 가진다.
- '인덱스'는 말 그대로 '색인'이다.
- 흔히 접하는 인덱스는 도서 뒤쪽 정리되어 있는 색인이다.
- 색인을 이용하면 사용자들은 책 전체를 살펴볼 필요 없이 색인을 통해 자신이 원하는 내용이 책의 어디에 있는지 알 수 있다.
- 데이터베이스에서 인텍스를 이해하는 가장 쉬은 방법은 데이터베이스 테이블을 하나의 책이라고 생각하고 어떻게 데이터를 찾거나 정렬하는지 생각하는 것이다.
- 색인은 사람들이 쉽게 찾아볼 수 있게 알파벳 순서나 한글 순서로 정렬한다.
- 이를 통해 원하는 내용을 위에서부터 혹은 반대로 찾아나가는데 이를 '스캔'이라 표현한다.
- 데이터베이스에 테이블을 만들 때 PK를 부여하면 지금까지 얘기한 '인덱스'라는 것이 만들어진다.
- 데이터베이스를 만들 때 PK를 지정하는 이유는 '식별'이라는 의미가 있지만, 구조상으로 '인덱스'라는 존재(객체)가 만들어지는 것을 의미한다.
- TBL_BOARD 테이블은 BNO라는 칼럼을 기준으로 인덱스를 생성한다.
- 인덱스에는 순서가 있기 때문에 그림으로 표현하면 다음과 같다.

- 그림의 왼쪽은 인덱스고 오른쪽은 실제 테이블이다.
- 왼쪽 그림을 보면 bno 값이 순서대로 정렬된 것을 볼 수 있다.
- 오른쪽 테이블은 마치 책장에 책을 막 넣은 것처럼 중간에 순서가 섞여 있는 경우가 대부분이다.
- 인덱스와 실제 테이블을 연결하는 고리는 ROWID라는 존재다.
- ROWID는 데이터베이스 내의 주소에 해당하는데 모든 데이터는 자신만의 주소를 가지고 있다.
- SQL을 통해 bno 값이 100번인 데이터를 찾고자 할 때는 SQL은 'where bno = 100'과 같은 조건을 주게 된다.
- 이를 처리하는 데이터베이스 입장에서는 tbl_board라는 책에서 bno 값이 100인 데이터를 찾아야만 한다.
- 만일 책이 얇아 내용이 많지 않다면 속히 전체를 살펴보는 것이 더 빠를 것이다.(이를 데이터베이스 쪽에서는 'FULL SCAN'이라 표현한다.)
- 하지만 내용이 많고, 색인이 존재한다면 당연히 색인을 찾고 색인에서 주소를 찾아 접근하는 방식을 이용할 것이다.
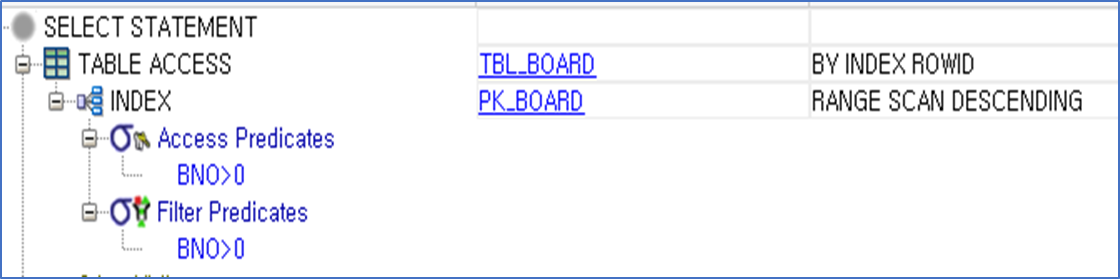
- 실행계획을 보면 이러한 생각이 데이터베이스 내에서 진행되는 것을 확인할 수 있다.
- 안쪽을 먼저 보면 PK_BOARD는 인덱스이므로 먼저 인덱스를 이용해 100번 데이터가 어디 있는지 ROWID를 찾아내고, 바깥쪽을 보면 'BY INDEX ROWID'라고 되어 있는 말 그대로 ROWID를 통해 테이블에 접근한다.

한 걸음 한 걸음 나아가는 개발자