Part 12. 오라클 데이터베이스 페이징 처리
12.4 ROWNUM과 인라인뷰
- 페이징 처리를 위해 역순으로 게시물의 목록을 조회하는 작업이 성공했다면, 이제는 전체가 아닌 필요한 만큼의 데이터를 가져오는 방식이다.
- 오라클 데이터베이스는 페이지 처리를 위해 ROWNUM이라는 특별한 키워드를 사용해 데이터에 순번을 붙여 사용한다.
- ROWNUM은 쉽게 생각해 SQL이 실행된 결과에 넘버링을 해주는 것이다.
- 모든 SELECT문에는 ROWNUM이라는 변수를 이용해 해당 데이터가 몇 번 째로 나오는 알아낼 수 있다.
- ROWNUM은 실제 데이터가 아니라 테이블에서 데이터를 추출한 후에 처리되는 변수이므로 상황에 따라 그 값이 매 번 달라질 수 있다.
- 우선 아무 조건을 적용하지 않고 TBL_BOARD 테이블에 접근하고 각 데이터에 ROWNUM을 적용하면 다음과 같이 작성할 수 있다.
- SQL에 아무런 조건이 없기 때문에 데이터는 테이블에 섞여 있는 상태 그대로 나오게 된다.(테이블을 FULL 스캔한 것과 동일하다. 각자 사용하는 데이터베이스에 저장된 구조가 다르므로 아래 화면과 동일하지 않을 수 있으나 섞여 있다는 점은 동일하다.)
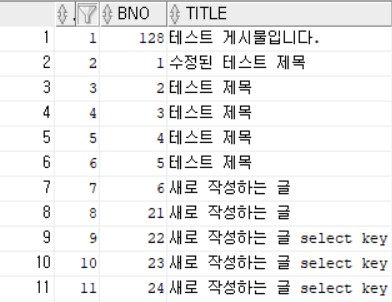
SELECT ROWNUM RN, BNO, TITLE FROM TBL_BOARD;
- ROWNUM은 테이블에는 존재하지 않고, 테이블에서 가져온 데이터를 이용해 번호를 매기는 방식으로 위의 결과는 테이블에서 가장 먼저 가져올 수 있는 데이터들을 꺼내 번호를 붙여주고 있다.
- 이 때 번호는 현재 데이터베이스의 상황에 따라 저장된 데이터를 로딩하는 것이므로 실븝 환경에 따라 다른 값이 나오게 된다.
- 위의 결과에서 1번 데이터는 1번째로 꺼내진 데이터라고 해석할 수 있다.
- 만일 테이블에서 데이터를 가져온 후에 정렬을 하게 된다면 128번의 ROWNUM 값은 동일하게 1이 된다.
SELECT /*+ FULL(TBL_BOARD) */ ROWNUM RN, BNO, TITLE FROM TBL_BOARD WHERE BNO > 0 ORDER BY BNO;
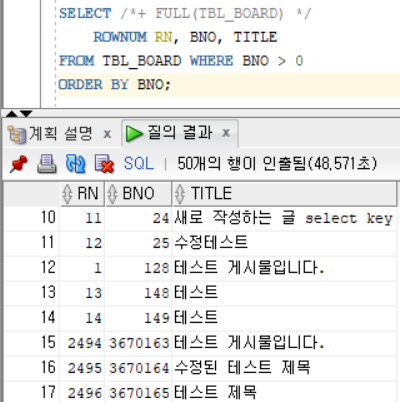
- 위의 SQL은 FULL 힌트를 이용해 전체 데이터를 조회하고 다시 정렬한 방식이다.
- 결과를 보면 1번 데이터는 1번째로 접근되었지만 정렬 과정에서 뒤쪽으로 밀리는 것을 볼 수 있다.
- 이를 통해 알 수 있는 사실은 ROWNUM이라는 것은 데이터를 가져올 때 적용되는 것이고, 이후에 정렬되는 과정에서 ROWNUM이 변경되지 않는다는 것이다.
- 다른 말로는 정렬은 나중에 처리된다는 의미이기도 하다.
12.4.1 인덱스를 이용한 접근 시 ROWNUM
- ROWNUM의 의미가 테이블에서 데이터를 가져오면서 붙는 번호라는 사실을 기억해 보면 결국 문제는 테이블에 어떤 순서로 접근하는가에 따라 ROWNUM 값은 바뀔 수 있다는 뜻이 된다.
- 다시 말해, 위의 경우 우선 FULL로 접근해 128번 데이터를 찾았고 이후에 정렬을 하는데 이미 데이터는 다 가져온 상태이므로 ROWNUM에는 아무런 영향을 주지 않는다.
- 만일 PK_BOARD 인덱스를 통해 접근한다면 다음과 같은 과정으로 접근한다.
1) PK_BOARD 인덱스를 통해 테이블에 접근
2) 접근한 데이터에 ROWNUM 부여- 1)의 과정에서 이미 정렬이 되었기 때문에 128번의 접근 순서는 1번째가 아니라 한참 뒤일 것이다.
- 이 경우 ROWNUM은 전혀 다른 값을 가지게 된다.
SELECT /*+ INDEX_ASC(TBL_BOARD PK_BOARD) */ ROWNUM RN, BNO, TITLE, CONTENT FROM TBL_BOARD;
- 위의 SQL은 인덱스를 찾는 순서가 다르므로 아래와 같은 방식으로 실행된다.
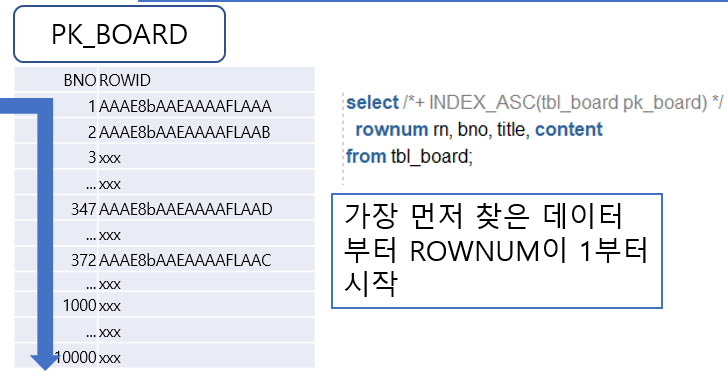
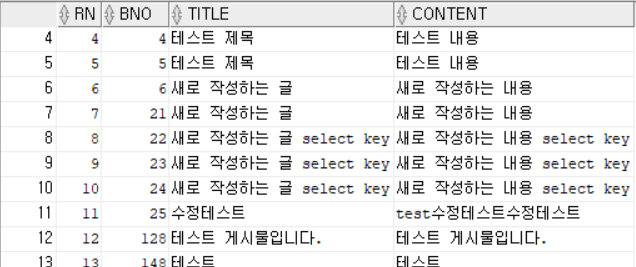
- 힌트를 이용해 TBL_BOARD 테이블을 PK_BOARD의 순번으로 접근하게 되면 ROWNUM의 값이 12로 달라진 것이 보인다.
- 이 때의 실행 계획은 다음과 같다.

- 만일 게시물의 역순으로 테이블을 접근하게 된다면 128번의 ROWNUM 값은 접근하는 순서가 뒤쪽이기 대문에 엄청나게 큰 값이 나오게 된다.
- ROWNUM은 데이터에 접근하는 순서이기 때문에 가장 먼저 접근하는 데이터가 1번이 되는데, 이를 이용하면 테이블을 bno의 역순으로 접근해 bno 값이 가장 큰 데이터가 ROWNUM 값이 1이 되도록 작성할 수 있다.
SELECT /*+ INDEX_DESC(TBL_BOARD PK_BOARD) */ ROWNUM RN, BNO, TITLE, CONTENT FROM TBL_BOARD WHERE BNO > 0;
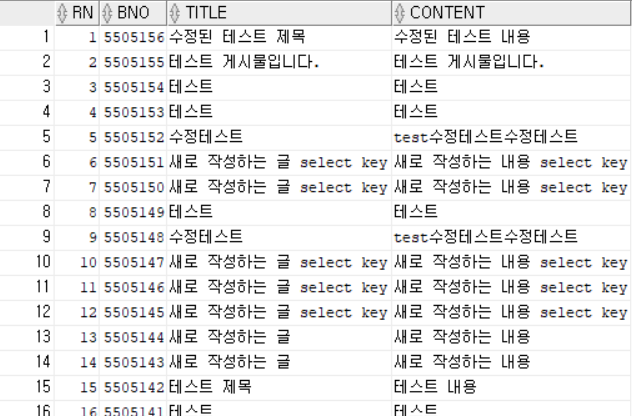
- 위의 SQL은 PK_BOARD 인덱스 역으로 타면서 테이블에 접근했기 때문에 BNO 값이 가장 높은 데이터를 가장 먼저 가져오게 도니다.
- 이 방식을 이용하면 각 게시물을 정렬하면서 순번을 매겨줄 수 있는데,
1 페이지의 경우는 위의 그림에서 RN이라는 칼럼의 값이 1부터 10에 해당한다고 볼 수 있다. (10개씩 페이징을 한다는 전제)

12.4.2 페이지 번호 1,2의 데이터
- 한 페이지당 10개의 데이터를 출력한다고 가정하면 ROWNUM 조건을 WHERE 구문에 추가해 다음과 같이 작성할 수 있다.
SELECT /*+INDEX_DESC(TBL_BOARD PK_BOARD) */ ROWNUM RN, BNO, TITLE, CONTENT FROM TBL_BOARD WHERE ROWNUM <= 10;
- WHERE 구문에는 ROWNUM 관련 조건을 줄 수 있는데, 위의 SQL 처리 결과는 다음과 같다.
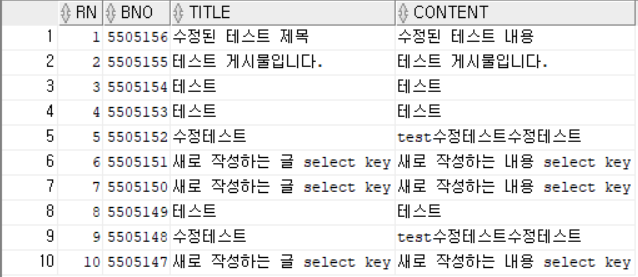

- SQL의 실행 결과를 보면 가장 높은 번호의 게시물 10개만이 출력되는 것을 볼 수 있다.
- 이 때 실행 계획을 통해 PK_BOARD 인덱스를 역순으로 접근하는 것을 확인할 수 있다.
- WHERE 조건에서 특이하게 ROWNUM 조건은 테이블을 접근할 때 필터링 조건으로 적용된 것을 볼 수 있다.
- 1페이지 데이터를 구했다면 흔히 동일한 방식으로 2페이지 데이터를 구할 수 있을 것이라고 생각한다.
- 하지만 절대로 원하는 결과를 구할 수 없는데 그 원인을 알아야 한다.
-- 아무 결과가 나오지 않는다. SELECT /*+INDEX_DESC(TBL_BOARD PK_BOARD) */ ROWNUM RN, BNO, TITLE, CONTENT FROM TBL_BOARD WHERE ROWNUM > 10 AND ROWNUM <= 20;
- 위의 SQL을 보면 ROWNUM이 10보다 크고 20보다 작거나 같은 데이터들을 가져올 것이라고 기대하지만 실제로는 아무 결과가 나오지 않는다.
- 이렇게 되는 이유를 알기 위해서는 실행 계획을 봐야 한다.

- 실행 계획은 안쪽에서부터 바깥쪽으로, 위에서부터 아래로 보게 되므로 위의 실행 계획은 우선 ROWNUM > 10, 데이터들을 찾게 된다.
- 문제는 TBL_BOARD에 처음으로 나온 ROWNUM의 값이 1이라는 것이다.
- TBL_BOARD에서 데이터를 찾고 ROWNUM 값이 1이 된 데이터는 WHERE 조건에 의해 무효화 된다.
- 이후에 다시 다른 데이터를 가져오면 새로운 데이터가 첫 번째 데이터가 되므로 다시 ROWNUM은 1이 된다.
- 이 과정이 반복되면 ROWNUM 값은 항상 1로 만들어지고 없어지는 과정이 반복되므로 테이블의 모든 데이터를 찾아내지만 결과는 아무것도 나오지 않게 된다.
- 이러한 이유로 SQL을 작성할 때 ROWNUM 조건은 반드시 1이 포함되어야 한다.
- SQL에 ROWNUM 조건이 1이 포함되도록 다음과 같이 수정해보면 결과가 나오는 것을 볼 수 있다.
-- ROWNUM은 반드시 1이 포함되어야 한다. SELECT /*+INDEX_DESC(TBL_BOARD PK_BOARD) */ ROWNUM RN, BNO, TITLE, CONTENT FROM TBL_BOARD WHERE ROWNUM <= 20;
- 달라진 점은 ROWNUM 조건이 1을 포함하도록 변경한 것뿐이다.
- 위의 SQL 결과는 아래와 같이 역순으로 데이터를 20개 가져온다.

12.4.3 인라인뷰(In-Line-View) 처리
- 10개씩 목록을 출력하는 경우 2페이지의 데이터 20개를 가져오는 데는 성공했지만, 1페이지의 내용이 같이 출력되는 문제가 있으므로 마지막으로 이 문제를 수정해야 한다.
- 이 문제를 해결하기 위해서 인라인뷰라는 것을 이용한다.
- 인라인뷰는 'SELECT문 안쪽 FROM에서 다시 SELECT문'으로 이해할 수 있다.
- 인라인뷰는 논리적으로는 어떤 결과를 구하는 SELECT문이 있고, 그 결과를 다시 대상으로 삼아서 SELECT를 하는 것이다.
- 데이터베이스에서는 테이블이나 인덱스와 같이 뷰(View)라는 개념이 존재한다.
- '뷰'는 일종의 '창문'같은 개념으로 복잡한 SELECT 처리를 하나의 뷰로 생성하고, 사용자들은 뷰를 통해 복잡하게 만들어진 결과를 마치 하나의 테이블처럼 쉽게 조회한다는 개념이다.
- 인라인뷰는 이러한 뷰의 작성을 별도로 표시하지 않고 말 그대로 FROM 구문 안에 바로 작성하는 형태다.

- 외부에서 SELECT문은 인라인뷰로 작성된 결과를 마치 하나의 테이블처럼 사용한다.
- 예를 들어, 위의 경우 20개의 데이터를 가져오는 SQL을 하나의 테이블처럼 간주하고 바깥쪽에서 추가적인 처리를 하는 것이다.

- 만일 위의 결과를 하나의 테이블로 보면 해당 테이블은 RN, BNO, TITLE, CONTENT라는 칼럼을 가지는 테이블이 된다.
- 이 경우 테이블에서 원하는 것은 RN 칼럼 값이 10보다 큰 데이터만 가져오면 된다.
- 인라인뷰를 적용한 2페이지 데이터의 처리는 아래와 같이 작성될 수 있다.
SELECT BNO, TITLE, CONTENT FROM ( SELECT /*+INDEX_DESC(TBL_BOARD PK_BOARD) */ ROWNUM RN, BNO, TITLE, CONTENT FROM TBL_BOARD WHERE ROWNUM <= 20 ) WHERE RN > 10;
- 기존의 SQL과 비교해 보면 20개의 데이터를 가져온 후 2페이지에 해당하는 10개만을 추출하는 방식으로 구현된다.
< 인라인 뷰의 내용 >
**< 인라인 뷰에서 필요한 부분만 추출 >

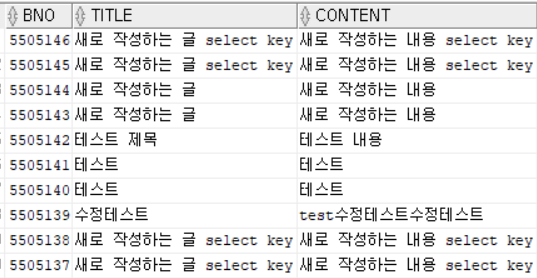
- 이 과정을 정리하면 다음과 같은 순서다.
- 필요한 순서로 정렬된 데이터에 ROWNUM을 붙인다.
- 처음부터 해당 페이지의 데이터를 'ROWNUM <= 30'과 같은 조건을 이용해 구한다.
- 구해놓은 데이터를 하나의 테이블처럼 간주하고 인라인뷰로 처리한다.
- 인라인뷰에서 필요한 데이터만을 남긴다.

한 걸음 한 걸음 나아가는 개발자