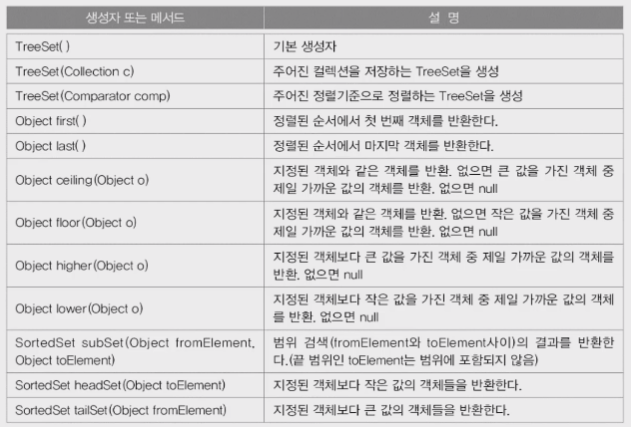
ch 11-42~45 TreeSet(2/2)
TreeSet의 주요 생성자와 메서드
- 기본적으로 add() / remove() / size() / isEmpty() / iterator() 가 있다.
- Comparator = 비교기준 제공 (없으면, Cmparable를 사용)
- first = 제일 작은 것
- last = 제일 큰 것
- ceiling = 올림
- floor = 버림
- higher = 객체보다 큰 값
- lower = 객체보다 작은 값
- subSet = 범위값
- headSet = 지정된 객체보다 작은 값
- tailSet = 지정된 객체보다 큰 값
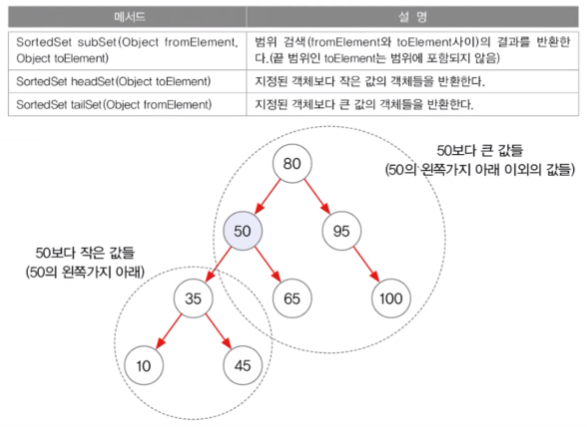
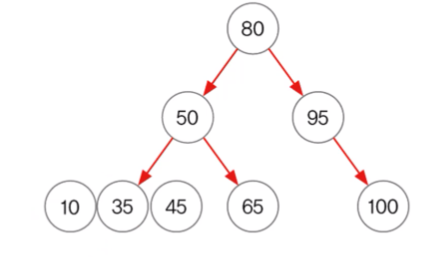
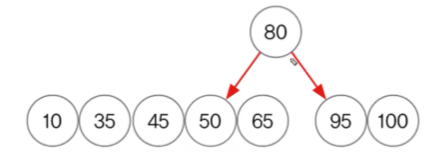
TreeSet 예제 (범위검색 subSet(), headSet(), tailSet())
- 50보다 작은 값들 = headSet
- 50보다 큰 값들 = tailSet
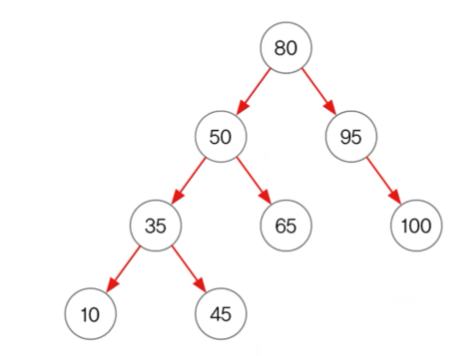
트리 순회(tree trabersal)
- 이진 트리의 모든 노드를 한번씩 읽는 것을 트리 순회라고 한다.
- 부모를 앞으로 보내는 것(부모를 읽고 자식을 읽는 것)을 전위순회(pre order)
- 부모를 나중에 보내는 것(자식을 읽고 부모를 읽는 것)을 후위순회(post order)
- 부모를 중간으로 보내는 것(왼쪽 자식 읽고 부모 읽고 오른쪽 자식 읽는 것)을 중위순회(inorder)
- 레벨 순회 = 레벨 순서대로(한 층씩) 읽는 것
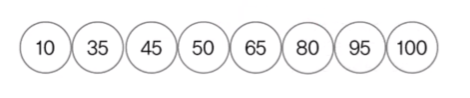
- 전위, 중위, 후위 순회법이 있으며, 중위 순회하면 오름차순으로 정렬된다.
- TreeSet의 장점 : 1.정렬에 유리하다. 2.범위검색에 유리하다.
- TreeSet의 단점 : 1. Tree가 커질수록 추가, 삭제 시간이 오래 걸린다.
ch 11-46,47 HashMap(1/2)
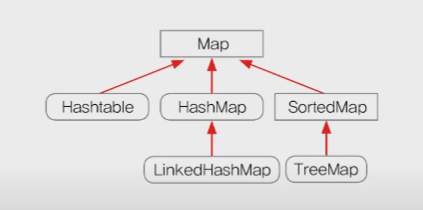
HashMap과 Hashtable - 순서X, 중복(키X, 값O)
- HashMap과 Hashtable은 Map 인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
- Hashtable은 old 버전으로 동기화가 되어 있지만, HashMap은 new 버전으로 동기화가 되어 있지 않다.
- TreeMap은 이진탐색트리를 가지고 있다.
- HashMap
- Map인터페이스를 구현한 대표적인 컬렉션 클래스
- 순서를 유지하려면, LinkedHashMap클래스를 사용하면 된다.
- TreeMap
- 범위검색과 정렬에 유리한 컬렉션 클래스
- HashMap보다 데이터 추가, 삭제에 시간이 더 걸림
HashMap의 키(key)와 값(value)
- 해싱(hashing)기법으로 데이터를 저장. 데이터가 많아도 검색이 빠르다.
- Map인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
- key는 중복값 허용 X / value는 중복값 허용O
HashMap map = new HashMap(); map.put("myId, "1234"); // put은 저장 map.put("asdf", "1111"); map.put("asdf", "1234");<결과>
key value
myId 1234
asdf 1234
- 처음에 asdf에 1111이 저장되었다가 1234로 값이 변경된다.
- Entry는 배열


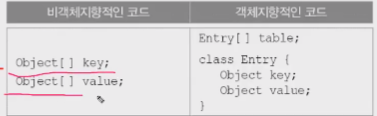
해싱(hashing) - (1/3)
해시함수는 key를 넣으면 해시코드(저장된 위치)를 반환한다.
- 해시함수를 이용해서 데이터를 저장하고 읽어오는 것.
해싱(hashing) - (2/3)
- 해시함수(has function)로 해시테이블(hash table)에 데이터를 저장, 검색
- 해시코드 = 배열 index(저장 위치)
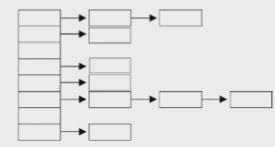
- 해시테이블은 배열과 링크드 리스트가 조합된 형태
- 2차원 배열과 같이 생겨서 테이블이라 한다.
- 변경이 쉽다.
- 배열의 장점 : 접근성 + 링크드리스트의 장점 : 변경유리 = 해시테이블
- Hashtable / HashMap / HashSet과 같은 hashCode들이 있는데, Object.hash()로 사용한다.
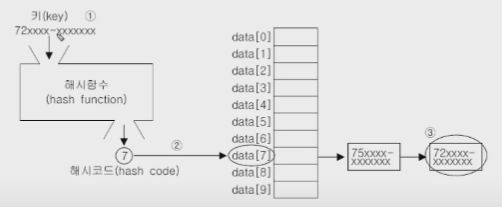
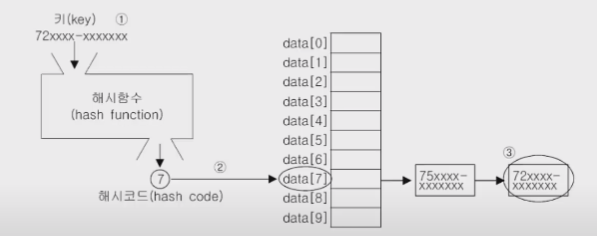
해싱(hashing) - (3/3)
- 해시테이블에 저장된 데이터를 가져오는 과정
- 1.키로 해시함수를 호출해서 해시코드(배열의 인덱스)를 얻는다.
- 2.해시코드(해시함수의 반환값)에 대응하는 링크드리스트를 배열에서 찾는다.
- 3.링크드리스트에서 키와 일치하는 데이터를 찾는다.
- 해시함수는 같은 키에 대해 항상 같은 해시코드를 반환해야 한다. 서로 다른 키일지라도 같은 값의 해시코드를 반환할 수도 있다. (저장할 때와 읽어올 때 같은 값을 가지고 와야 한다.)
- 서로 다른 키 값이라도 같은 값의 해시코드를 반환할 수 있다.(위치가 같을 수는 있다.)

한 걸음 한 걸음 나아가는 개발자