HTTP 애플리케이션은 여러 언어의 문자로 텍스트를 보여주고 요청하기 위해 문자집합 인코딩을 사용한다. 그리고 그것들은 사용자가 이해할 수 있는 언어만으로 콘텐츠를 서술하기 위해 언어 태그를 사용한다.
16.1 국제적인 콘텐츠를 다루기 위해 필요한 HTTP 지원
- HTTP 메시지는 어떤 언어로 된 콘텐츠든, 이미지, 동영상 혹은 그 외 다른 종류의 미디어처럼 실어 나를 수 있다.
- 서버는 클라이언트에게 문서의 문자와 언어를 HTTP Content-Type charset 매개 변수와 Content-Language 헤더를 통해 알려준다. 이 헤더들은 엔티티 본문의 '비트들로 가득 찬 상자'에 무엇이 들어있는지, 어떻게 콘텐츠를 화면에 출력될 올바른 글자들로 바꾸는지, 그 텍스트가 어떤 언어에 해당하는지 서술한다.
- 클라이언트는 서버에게 사용자가 어떤 언어를 이해할 수 있고 어떤 알파벳의 코딩 알고리즘이 브라우저에 설치되어 있는지 말해줄 필요가 있다. 클라이언트는 서버에게 자신이 어떤 차셋 인코딩 알고리즘들과 언어들을 이해하며 그중 무엇을 선호하는지 말해주기 위해서 Accept-Charset과 Accept-Language 헤더를 보낸다.
Accept-Language: fr, en;q=0.8
Accept-Charset: iso-8859-1, utf-8모국어를 선호하지만 피치 못할 경우에는 영어도 사용하는 프랑스어 사용자가 보냈을것이다.
이 사용자의 브라우저는 iso-8859-1 서유럽어 차셋 인코딩과 UTF-8 유니코드 차셋 인코딩을 지원할 것이다.
매개변수 'q=0.8'은 품질 인자 (quality factor)이다. 프랑스어(기본값 1.0)보다 영어에 낮은 우선순위(0.8)을 주었다.
16.2 문자집합과 HTTP
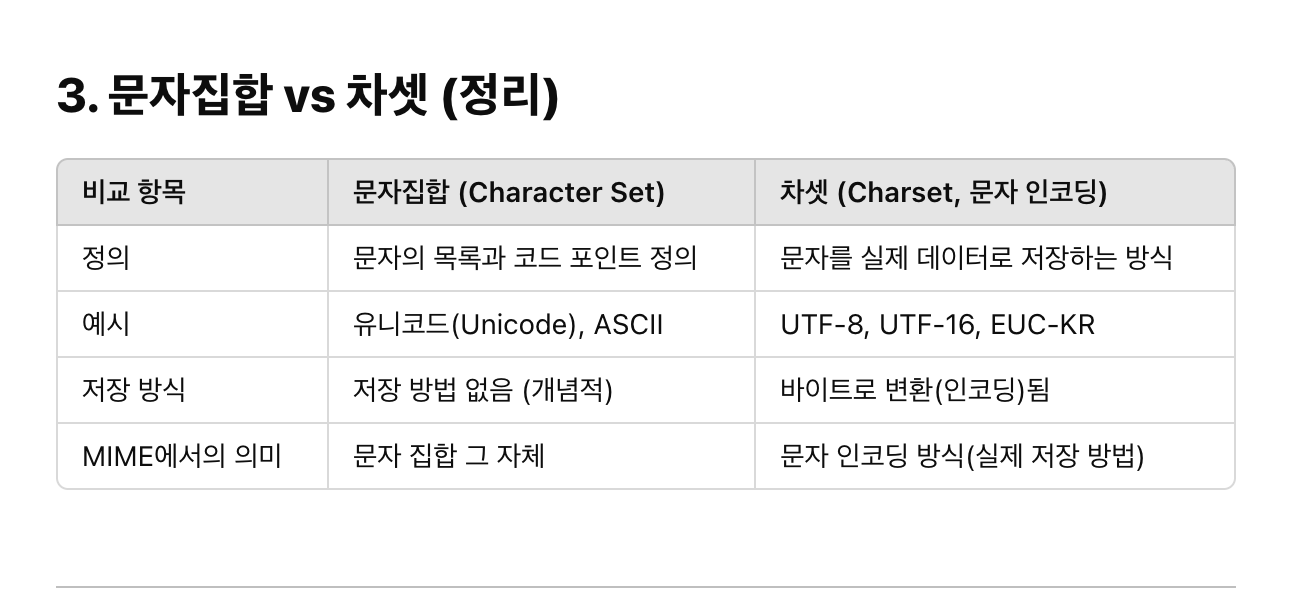
16.2.1 차셋(Charset)은 글자를 비트로 변환하는 인코딩이다.
HTTP 차셋 값은,어떻게 엔티티 콘텐츠 비트들을 특정 문자 체계의 글자들로 바꾸는지 말해준다. 각 차셋 태그는 비트들을 글자들로 변환하거나 혹은 그 반대의 일을 해주는 알고리즘을 명명한다.
다음 Content-Type 헤더는 수신자에게 콘텐츠가 HTML파일임을 말해주고, charset 매개변수는 수신자에게 콘텐츠 비트들을 글자들로 디코딩하기 위해 iso-8859-6 아랍 문자집합 디코딩 기법을 사용하라고 말해준다.
Content-Type:text/html; charset=iso-8859-616.2.2 문자집합과 인코딩은 어떻게 동작하는가
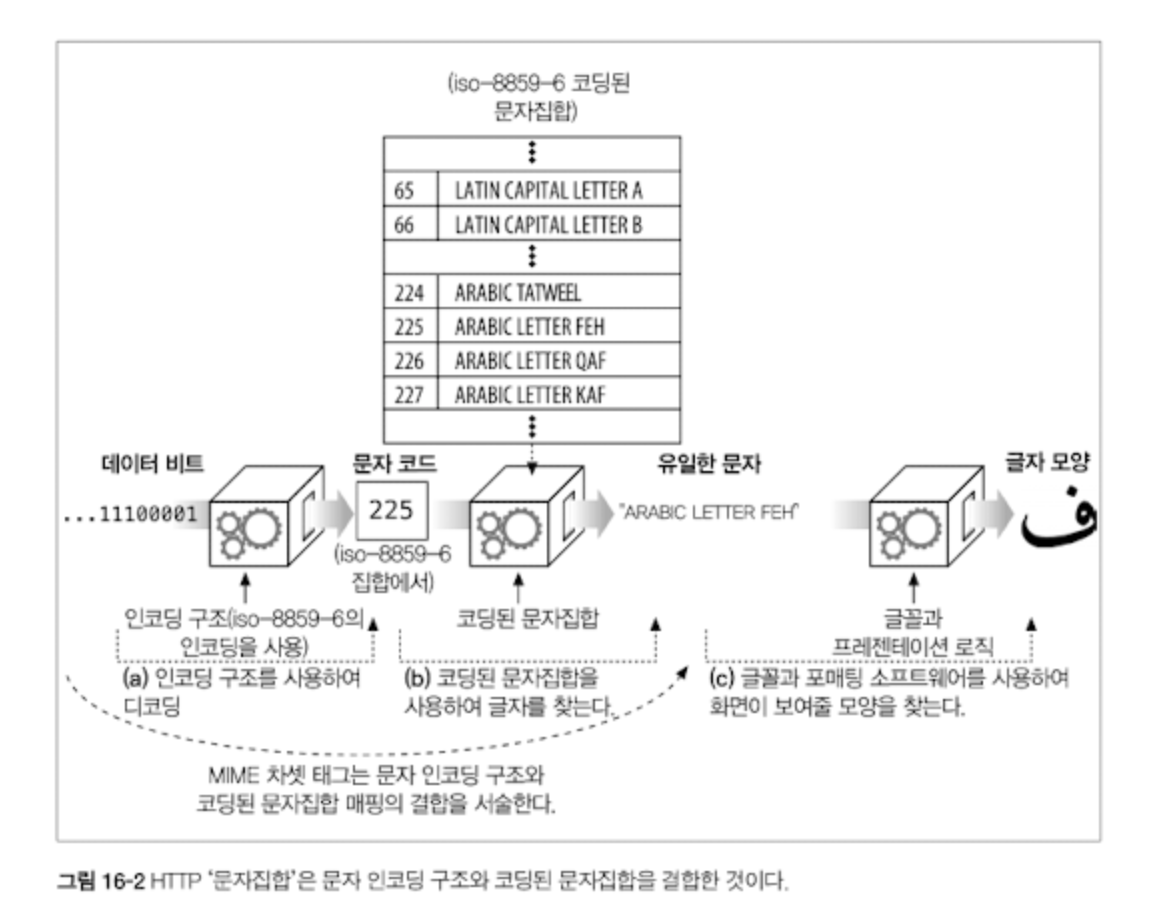
비트들을 문자로 변환하는 것은 두 단계에 걸쳐 일어난다.
- 그림 16-2a, 문서를 이루는 비트들은, 특정 코딩된 문자집합의 특정 문자(각각 번호가 매겨져 있다)로 식별될 수 있는 문자 코드로 변환된다. 이 예에서, 디코딩된 문자 코드는 225로 번호가 붙어있다.
- 그림 16-2b 문자 코드는 코딩된 문자집합의 특정 요소를 선택하기 위해 사용된다. iso-8859-6에서, 값 225는 'ARABIC LETTER FET' 에 해당한다. 단계 a와 b에서 사용되는 알고리즘은 MINE 차셋 태그를 통해 결정된다.
국제화된 문자 시스템의 핵심 목표는 표헌(시각적인 표현 방식)에서 의미(글자들(를 분리하는 것이다.
- HTTP는 문자 데이터 및 그와 관련된 언어와 차셋 레벨의 전송에만 관심을 갖는다. 그림 16-2c와 같이, 글자의 모양을 어떻게 표현할 것인가 하는 것은 사용자의 그래픽 디스플레이 소프트웨어(브라우저, 운영체제, 글꼴)가 결정한다.
16.2.3 잘못된 차셋은 잘못된 글자들을 낳는다.
만약 클라이언트가 잘못된 charset 매개변수를 사용한다면, 클라이언트는 이상한 꺠진 글자를 보여주게 될것이다.
16.2.4 표준화된 MIME 차셋 값
특정 문자 인코딩과 특정 코딩된 문자집합의 결합을 MIME 차셋이라고 부른다.
HTTP는 표준화된 MIME 차셋 태그를 Content-Type과 Accept-Charset 헤더에 사용한다.
MIME 차셋의 값은 LANA에 등록되어있다.
16.2.6 Accept-Charset 헤더
세상에는 수천 가지의 정의된 문자 인코딩과 디코딩 방법이 존재한다.
대부분의 클라이언트는 모든 종류의 문자 코딩과 매핑 시스템을 지원하지는 않는다.
HTTP 클라이언트는 서버에게 정확히 어떤 문자 체계를 그들이 지원하는지 Accept-Charset 요청 헤더를 통해 알려준다. Accept-Charset 헤더의 값은 클라이언트가 지원하는 문자 인코딩의 목록을 제공한다.
다음의 HTTP 요청 헤더는 클라이언트가 서유럽 iso-8859-1 문자 시스템을 UTF-8 가변길이 유니코드 호환 시스템만큼 잘 받아들일 수 있음을 말해준다.
이 문자 인코딩 구조 중 어떤 것으로 콘텐츠를 반환할지는 서버의 자유이다.
Accept-charset: iso-8859-1, utf-8유니코드(Unicode)
-
정의: 전 세계 모든 문자를 통합하여 표현할 수 있도록 설계된 문자 집합(Character Set).
-
역할: 한글, 영어, 중국어, 일본어 등 모든 문자를 하나의 체계에서 다룰 수 있도록 함
-
코드 포인트: 각 문자는 고유한 숫자(코드 포인트, 예: U+0041(A), U+AC00(가))로 표현됨.
-
예제
U+0041 -> 'A' U+AC00 -> '가' U+1F600 -> 😀 (이모지)
UTF-8 (Unicode Transformation Format - 8 bit)
-
정의: 유니코드 문자를 저장하고 전송하기 위한 인코딩 방식 중 하나.
-
특징:
- 가변 길이(1~4바이트) 사용.
- ASCII(0~127)는 1바이트 그대로 유지 → 기존 ASCII 기반 시스템과 호환성 좋음.
- 한글, 한자 등 비ASCII 문자는 2~4바이트로 인코딩됨.
-
예제
'A' (U+0041) -> 1바이트 (0x41) '가' (U+AC00) -> 3바이트 (0xEA 0xB0 0x80) 😀 (U+1F600) -> 4바이트 (0xF0 0x9F 0x98 0x80)
UTF-8과 유니코드의 관계
- 유니코드는 문자 집합(어떤 문자들이 존재하는가)을 정의.
- UTF-8은 유니코드 문자를 실제로 저장하는 방법(인코딩) 을 정의.
- UTF-8 외에도 다른 인코딩 방식(UTF-16, UTF-32 등)이 있지만, UTF-8이 가장 널리 사용됨.
UTF-8이 널리 쓰이는 이유
- ASCII와 완벽 호환됨.
- 메모리 절약 가능 (필요한 만큼만 바이트를 사용).
- 인터넷, 웹(HTML, JSON, XML)에서 기본적으로 UTF-8이 사용됨.
유니코드와 아스키 코드의 관계
- 아스키 코드는 유니코드의 하위 집합
- 유니코드의 첫 128개의 문자는 아스키 코드와 동일합니다. 즉, 유니코드의 첫 128개 코드 포인트(0–127)는 아스키 코드의 문자들과 일치
- 예를 들어, 아스키 코드에서 A는 65이고, 유니코드에서도 A는 65
- 아스키 코드로 표현할 수 있는 문자는 유니코드에서도 동일하게 표현되지만, 유니코드는 아스키 코드 외에도 많은 문자를 지원함
유니코드는 "문자의 표준 번호 체계", UTF-8은 "그 번호를 실제 데이터로 저장하는 방식" 이다.
16.4 언어 태그와 HTTP
언어 태그는 언어에 이름을 붙이기 위한 짧고 표준화된 문자열이다.
영어(en), 독일어(de), 한국어(ko), 그리고 많은 다른 언어에 대한 언어 태그가 존재한다.
언어 태그는 브라질 포루투갈어(pt-BR), 미국 영어(en-US), 허난 중국어(zh-xian)등과 같이 지역에 따라 변형된 언어나 방언을 표현할 수 있다.
16.4.1 Content-Language 헤더
Content-Language 엔터티 헤더 필드는 엔터티가 어떤 언어 사용자를 대상으로 하고 있는지 서술한다. 만약 주로 프랑스어 사용자를 대상으로 하고 있다면, Content-Language 헤더 필드는 다음을 포함할 것이다.
Content-Language: fr특정 언어 사용자를 대상으로 하는 어떤 종류의 미디어(오디오 클립, 동영상 애플리케이션)라도 Content-Language헤더를 가질 수 있다.
16.4.2 Accept-Language 헤더
HTTP는 우리에게 우리의 언어 제약과 선호도를 웹 서버에 전달할 수 있게 해준다. 만약 웹 서버가 어떤 자원에 대해 여러 언어로 된 버전을 갖고 있다면, 웹 서버는 우리가 선호하는 언어로 된 콘텐츠를 줄 수 있다.
Accept-Language: es16.5 국제화된 URI
16.5.1 국제적 가독성 vs 의미 있는 문자들
URI 설계자들은 전 세계의 모두가 URI를 이메일, 전화, 광고판, 심지어 라디오를 통해 다른 이들과 공유할 수 있기를 원했다. 그들은 URI가 사용하기 쉽고 기억하기 쉽길 바랐다. 이 두 가지 목표는 서로 충돌한다.
URI 저자들은 리소스 식별자의 가독성과 공유 가능성의 보장이, 대부분의 의미있는 문자들로 구성될 수 있도록 하는 것보다 더 중요하다고 여겼다.
그래서 우리들은(오늘날) ASCII 문자들의 제한된 집합으로 이루어진 URI를 갖게 되었다.
16.5.2 URI에서 사용될 수 있는 문자들
URI에서 사용할 수 있는 US-ASCII 문자들의 부분집합은 예약된 문자들, 예약되지 않은 문자들, 이스케이프 문자들로 나뉜다.
예약되지 않음: [A-Za-z0-9] | "-" | "_" | "." | "!" | "~" | "*" | "" | "(" | ")"
예약됨: ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" | "$" | ","
이스케이프: "%" <HEX> <HEX>16.5.3 이스케이핑과 역이스케이핑(unescaping)
URI 이스케이프는 예약된 문자나 다른 지원하지 않는 글자들(스페이스와 같이)을 안전하게 URI에 삽입할 수 있는 방법을 제공한다.
이스케이프는 퍼센트 글자(%)하나와 뒤이은 16진수 글자 둘로 이루어진 세 글자 문자열이다. 16진수 두 글자는 US-ASCII 문자의 코드를 나타낸다.
내부적으로 HTTP 애플리케이션은 URI를 데이터가 필요할 때만 언이스케이핑 해야한다. 그리고 더 중요한 것은, 애플리케이션은 어떤 URI도 결코 두 번 언이스케이핑 되지 않도록 해야한다. 왜냐하면 이스케이핑된 퍼센트 기호를 포함한 URI를 언이스케이핑하면 퍼센트 기호가 포함된 URI가 만들어지게 될텐데 여기서 잘못하여 한 번 더 언이스케이핑을 하면 이 퍼센트 기호 뒤에있는 문자들이 이스케이프의 일부인 것처럼 처리되어 데이터의 손실을 유발 할 수도 있다.
URI에는 ASCII 코드만 사용할 수 있을까?
원칙적으로 URI(Uniform Resource Identifier)에는 ASCII 문자만 사용할 수 있다. 하지만, 비ASCII 문자(한글, 특수문자 등)도 퍼센트 인코딩(percent-encoding)을 사용하면 표현할 수 있다.
비ASCII 문자를 URI에 포함하는 방법 (퍼센트 인코딩)
- 비ASCII 문자(예: 한글) 를 URI에 넣으려면 퍼센트 인코딩(percent-encoding, URL 인코딩) 을 사용해야 함.
- 퍼센트 인코딩은 문자를 UTF-8로 변환한 후, 16진수(%XX) 형태로 바꿔서 표현하는 방식.
예제: "한글"을 퍼센트 인코딩하면?
"한" → UTF-8 바이트: 0xED 0x95 0x9C → %ED%95%9C
"글" → UTF-8 바이트: 0xEA 0xB8 0x80 → %EA%B8%80
"한글" → `%ED%95%9C%EA%B8%80`📌 즉, URI에 한글을 직접 사용할 수 없지만, %ED%95%9C%EA%B8%80처럼 퍼센트 인코딩하면 가능!
