
1장에서는 타입스크립트의 큰 그림을 이해하는 데 도움이 될 내용을 다룬다.
타입스크립트는 사용 방식 면에서 조금 독특한 언어이다.
- 또 다른 고수준 언어인 자바스크립트로 컴파일 된다.
- 실행 역시 타입스크립트가 아닌 자바스크립트로 이루어진다.
- 타입스크립트와 자바스크립트의 관계는 필연적이다.
타입스크립트의 타입 시스템도 조금 독특한 특징을 가지고 있다.
요약
-
타입스크립트는 자바스크립트의 상위집합니다. 모든 자바스크립트 프로그램은 이미 타입스크립트 프로그램이다. 반대로, 타입스크립트는 별도의 문법을 가지고 있기 떄문에 일반적으로는 유효한 자바스크립트 프로그램이 아니다.
-
타입스크립트는 자바스크립트 런타임 동작을 모델링하는 타입 시스템을 가지고 있기 떄문에 런타임 오류를 발생시키는 코드를 찾아내려한다. 그러나 모든 오류를 찾아낼 수 없고, 타입 체커를 통과해도 런타임 오류를 발생시키는 코드가 있다.
-
타입스크립트 타입 시스템은 전반적으로 자바스크립트 동작을 모델링한다. 그러나 잘못된 매개변수 개수로 함수를 호출하는 경우처럼, 자바스크립트에서는 허용되지만 타입스크립트에서는 문제가 되는 경우도 있다. 이러한 문법의 엄격함은 취향차이이다.
아이템1 타입스크립트와 자바스크립트의 관계 이해하기
-
"타입스크립트는 자바스크립트의 상위 집합(superset) 이다.
-
타입 스크립트는 문법적으로 자바스크립트의 상위집합이다.
- 자바스크립트 프로그램에 문법 오류가 없다면, 유효한 타입스크립트 프로그램이다.
- 자바스크립트 프로그램에 이슈가 존재하면 문법오류가 아니라도 타입 체커에게 지적당할 가능성이 높다.
-
모든 자바스크립트 프로그램이 타입스크립트라는 명제는 참이지만, 그 반대는 성립하지 않는다.
- 타입스크립트 프로그램이지만 자바스크립트가 아닌 프로그램이 존재한다. 이는 타입스크립트가 타입을 명시하는 추가적인 문법을 가지기 때문이다. 다음은 유효한 타입스크립트 프로그램이다.
그러나 자바스크립트를 구동하는 node 같은 프로그램으로 코드를 실행하면 오류를 출력한다.
: string은 타입스크립트에서 쓰이는 타입 구문이다.
function greet(who: string){ console.log("Hello", who); } - 타입스크립트 프로그램이지만 자바스크립트가 아닌 프로그램이 존재한다. 이는 타입스크립트가 타입을 명시하는 추가적인 문법을 가지기 때문이다. 다음은 유효한 타입스크립트 프로그램이다.
-
타입 스크립트 컴파일러는 타입스크립트뿐만 아니라 일반 자바스크립트 프로그램에도 유용하다.
let city = 'new york city'; console.log(city.toUppercase());이 코드를 실행하면 다음과 같은 오류가 발생한다.
TypeError: city.toUppercase is not a funcion위 코드에는 타입 구문이 없지만, 타입 스크립트의 타입 체커는 문제점을 찾아 낸다.
let city = 'new york city'; console.log(city.toUppercase()); // 'toUppercase' 속성이 'string' 형식에 없습니다. // 'toUppserCase'을(를) 사용하시겠습니까?city 변수가 문자열 이라는 것을 알려 주지 않아도 타입스크립트는 초깃값으로 부터 타입을 추론한다.
-
타입 시스템의 목표 중 하나는 런타임에 오류를 발생시킬 코드를 미리 찾아 내는것이다.
- 오류가 발생하지 않지만 의도와 다르게 동작하는 코드가 있다. 타입 스크립트는 이러한 문제 중 몇가지를 찾아낸다.
const states = [ {name: 'Alabama', capital: 'Montgomery'}, {name: 'Alaska', capital: 'Juneau'}, {name: 'Arizona', capital: 'Phonenix'}, ]; for (const state of states){ console.log(state.capitol); }실행한 결과는 다음과 같다.
undefined undefined undefined앞의 코드는 유효한 자바스크립트(또한 타입스크립트) 이며 어떠한 오류도 없이 실행된다. 그러나 루프 내의 state.capitol은 의도한 코드가 아니다. 이런 경우에 타입스크립트 타입 체커는 추가적인 타입 구문 없이도 오류를 찾아낸다.
for (const state of states){ console.log(state.capitol); // 'capitol' 속성이 ... 형식에 없습니다. // 'capital' 을(를) 사용하시겠습니까? }
p5 예제 참고
타입스크립트는 타입 구문 없이도 오류를 잡을 수 있지만, 타입 구문을 추가하면 더 많은 오류를 찾아낼 수 있다.
코드의 '의도' 가 무엇인지 타입 구문을 통해 타입스크립트에게 알려줄 수 있기 때문에 코드의 동작과 의도가 다른 부분을 찾을 수 있다.
=> 명시적으로 states를 선언하여 의도를 분명하게 하는 것이 좋다.
interface State {
name: string;
capital:string;
}
const states: State[] = [
{name: 'Alabama', capitol: 'Montgomery'},
{name: 'Alaska', capitol: 'Juneau'},
{name: 'Arizona', capitol: 'Phonenix'},
];
// 객체 리터럴은 알려진 속성만 지정할 수 있지만 'State'형식에 'capitol' 이(가) 없습니다.
// 'capital'을(를) 쓰려고 했습니까?
for (const state of states){
console.log(state.capitol);
}=> 의도를 명확히 해서 타입스크립트가 잠재적 문제점을 찾을 수 있게 했다.
- 타입스크립트 타입 시스템은 자바스크립트의 런타임 동작을 '모델링'한다.
const x = 2 + '3'; // 정상, string 타입 입니다. const y = '2' + 3; // 정상, string 타입 입니다.- 이 예제는 다른 언어였다면 런타임 오류가 될 만한 코드다. 하지만 타입스크립트의 타입 체커는 정상으로 인식한다.
- 두 줄 모두 문자열 "23"이 되는 자바스크트립트 런타임 동작으로 모델링 된다.
- 반대로 정상 동작하는 코드에 오류를 표시하기도 한다. (런타임 오류가 발생하지 않는데, 타입 체커는 문제점을 표시한다.)
- 언제 자바스크립트 런타임 동작을 그대로 모델링할지, 또는 추가적인 타입 체크를 할지 분명하지 않다면 타입 스크립트를 사용해도 되는지 의문이 들 수 있다. 타입스크립트 채택 여부는 온전히 우리의 선택에 달렸다.
-
작성된 프로그램이 타입 체크를 통과하더라도 여전히 런타임에 오류가 발생할 수 있다.
const names = ['Alice', 'Bob']; console.log(names[2].toUpperCase());프로그램을 실행하면 다음과 같은 오류가 발생한다.
TypeError: Cannot read property 'toUpperCase' of undefined타입스크립트는 앞의 배열이 범위 내에서 사용될 것이라고 가정했지만 실제로는 그렇지 않았고, 오류가 발생했다.
-
앞서 등장한 오류들이 발생하는 근본 원인은 타입스크립트가 이해하는 값의 타입과 실제 값에 차이가 있기 때문이다. 타입 시스템이 정적 타입의 정확성을 보장해 줄 것 같지만 그렇지 않다.
아이템 2 타임스크립트 설저 이해하기
요약
- 타입스크립트 컴파일러는 언어의 핵심 요소에 영향을 미치는 몇 가지 설정을 포함하고 있다.
- 타입 스크립트 설정은 커맨들 라인을 이용하기 보다는 tsconfig.json 을 사용하는 것이 좋다.
- 자바스크립트 프로젝트를 타입스크립트로 전환하는게 아니라면 NoImplicitAny를 설정하는 것이 좋다.
- "undefined는 객체가 아닙니다" 같은 런타임 오류를 방지하기 위해 strictNullChecks 를 설정하는것이 좋다."
- 타입스크립트에서 엄격한 체크를 하고 싶다면 strict 설정을 고려해야한다.
NoImplicitAny
암시적(implicit) 이라는 단어를 사용한다. 암묵적으로 합의된 정도의 의미로 생각하면 된다.
-
변수들이 미리 정의된 타입을 가져야하는지 여부를 제어한다.
-
다음 코드는 noImplicityAny가 해제 되어있을 때에는 유효하다.
function add(a, b){
return a + b;
}편집기에서 add 부분에 마우스를 올려보면, 타입스크립트가 추론한 함수의 타입을 알 수 있다.
function add(a: any, b:any) :anyany를 코드에 넣지 않았지만, any 타입으로 간주되기 때문에 이를 '암시적 any'라고 부른다.
그런데 같은 코드임에도 noImplicitAny가 설정되었다면 오류가 된다. 이 오류들은 명시적으로 :any라고 선언해주거나 더 분명한 타입을 사용하면 해결할 수 있다.
function add(a:number, b:number){
return a + b;
}stringNullChecks
- null 과 undefined가 모든 타입에서 허용되는지 확인하는 설정이다.
- 다음은 strictNullChecks가 해제되었을 떄 유효한 코드이다.
const x: number = null // 정상, null은 유효한 코드이다.그러나 strictNullChecks를 설정하면 오류가 된다.
const x: number = null // 정상, null은 유효한 코드이다.
// ~ 'null' 형식은 'number' 형식에 할당할 수 없습니다.null 대신 undefined를 써도 같은 오류가 난다. 만약 null을 허용하려고 한다면, 의도를 명시적으로 드러냄으로써 오류를 고칠 수 있다.
const x:number | null = null;아이템 3 코드 생성과 타입이 관계없음을 이해하기
큰 그림에서 보면, 타입스크립트 컴파일러는 두 가지 역할을 수행한다.
1. 최신 타입스크립트/자바스크립트를 브라우저에서 동작할 수 있도록 구버전의 자바스크립트로 트랜스파일(transpile) 한다.
2. 코드의 타입 오류를 체크한다.
두 가지는 서로 완벽히 독립적이다
=> 타입스크립트가 자바스크립트로 변환될 때 코드 내의 타입에는 영향을 주지 않는다
=> 자바스크립트의 실행 시점에도 타입은 영향을 미치지 않는다.
타입스크립트가 할 수 있는 일과 할수 없는 일을 짐작할 수 있다.
요약
- 코드 생성은 타입 시스템과 무관하다. 타입스크립트 타입은 런타임 동작이나 성능에 영향을 주지 않는다.
- 타입 오류가 존재하더라도 코드 생성(컴파일)은 가능하다.
- 타입스크립트 타입은 런타임에서 사용할 수 없다. 런타임에서 타입을 지정하려면, 타입 정보 유지를 위한 별도의 방법이 필요하다.
타입 오류가 있는 코드도 컴파일이 가능하다.
-
컴파일은 타입 체크와 독립적으로 동작하기 때문에, 타입 오류가 있는 코드도 컴파일이 가능하다.
-
타입스크립트 오류는 C나 자바 같은 언어들의 경고(warnig)와 비슷하다. 문제가 될 만한 부분을 알려주지만, 그렇다고 빌드를 멈추진 않는다.
-
만약 오류가 있을 때 컴파일하지 않으려면, tsconfig.json에 noEmitOnError를 설정하거나 빌드 도구에 동일하게 적용하면 된다.
런타임에는 타입 체크가 불가능하다

- instanceof 체크는 런타임에 일어나지만, Rectangle은 타입이기 때문에 런티임 시점에 아무런 역할을 할 수 없다.
- 타입스크립트의 타입은 '제거 가능' 하다. 실제로 자바스크립트로 컴파일 되는 과정에서 모든 인터페이스, 타입, 타입 구문은 제거된다.
shape 타입을 명확하게 하려면, 런타임에 타입 정보를 유지하는 방법이 필요하다.
- height 속성이 존재하는 지 체크해 본다.

- 속성 체크는 런타임에 접근 가능한 값에만 관련되지만, 타입 체커 역시도 shape의 타입을 Rectangle로 보정해 주기 때문에 오류가 사라진다.
- 타입 정보를 유지하는 또 다른 방법으로는 런타임에 접근 간으한 타입 정보를 명시적으로 저장하는 '태그' 기법이 있다.

- 여기서 Shape 타입은 '태그된 유니온'의 한 예이다. 이 기법은 런타임에 타입 정보를 손쉽게 유지할 수 있기 때문에, 타입스크립트에서 흔하게 볼 수 있다.
- 타입(런타임 접근 불가) 과 값(런타임 접근 가능)을 둘 다 사용하는 기법도 있다. 타입을 클래스로 만들면 된다.

- 인터페이스는 타입으로만 사용 가능하지만, Rectangle을 클래스로 선언하면 타입과 값으로 모두 사용할 수 있으므로 오류가 없다.
- type Shape = Square | Rectangle 부분에서 Rectangle은 타입으로 참조되지만, shape instanceof Rectangle 부분에서는 값으로 참조된다.
타입 연산은 런타임에 영향을 주지 않는다.
string 또는 number 타입인 값을 항상 number로 정제하는 경우를 가정해보자. 다음 코드는 타입 체커를 통과하지만 잘못된 방법을 썼다.
function asNumber(val:number | string): number {
return val as number;
}변환된 자바스크립트 코드를 보면 이 함수가 실제로 어떻게 동작하는지 알 수 있다.
function asNumber(val){
return val;
}코드에 아무런 정제 과정이 없다. as number는 타입 연산이고 런타임 동작에는 아무런 영향을 미치지 않는다. 값을 정제하기 위해서는 런타임의 타입을 체크해야하고 자바스크립트 연산을 통해 변환을 수행해야한다.
function asNumber(val:number|string):number {
return typeof(val) === 'string' ? Number(val) : val;
}런타임 타입은 선언된 타입과 다를 수 있다.
다음 함수를 보고 마지막의 console.log까지 실행될 수 있을지 생각해보자
function setLightSwitch(value: boolean){
switch(value){
case true:
turnLightOn();
break;
case false;
turnLightOff();
break;
default:
console.log('실행되지 않을까 봐 걱정');
}
}-
타입스크립트는 일반적으로 실행되지 못하는 죽은(dead) 코드를 찾아내지만, 여기서는 strict를 설정하더라도 찾아내지 못한다.
-
:boolean은 런타임에 제거된다.
-
api response로 value를 받을때 얼마든지.. 타입이 바뀔 수 있다.
-
타입스크립트에서는 런타임 타입과 선언된 타입이 맞지 않을 수 있다.
타입스크립트 타입으로는 함수를 오버로드할 수 없다.
C++ 같은 언어는 동일한 이름에 매개변수만 다른 여러 버전의 함수를 허용한다. 이를 '함수 오버로딩'이라고한다. 그러나 타입스크립트에서는 타입과 런타임의 동작이 무관하기 때문에, 함수 오버로딩을 불가능하다.

타입스크립트가 함수 오버로딩 기능을 지원하지만, 온전히 타입수준에서만 동작한다. 하나의 함수에 대해 여러 개의 선언문을 작성할 수 있지만, 구현체 는 오직 하나다.
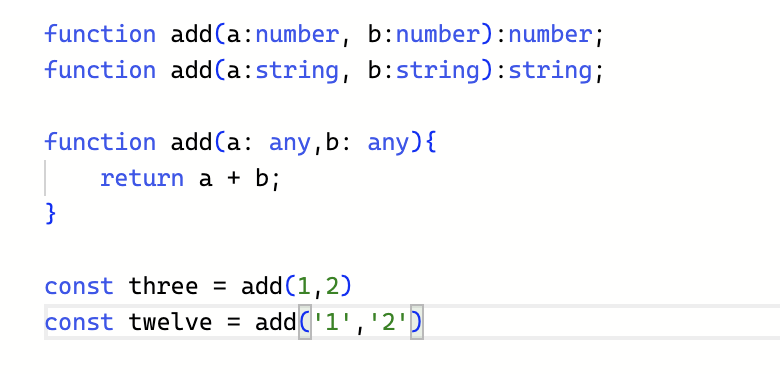
- add 에 대한 처음 두 개의 선언문은 타입 정보를 제공할 뿐이다. 이 두 선언문은 타입스크립트가 자바스크립트로 변환 되면서 제거되며, 구현체만 남는다..
타입스크립트 타입은 런타임 성능에 영향을 주지 않는다.
-
타입과 타입 연산자는 자바스크립트 변환 시점에 제거되기 때문에, 런타임의 성능에 아무런영향을 주지 않는다.
-
타입스크립트의 정적 타입은 실제로 비용을 들지 않는다.
-
'런타임' 오버헤드가 없는 대신, 타입스크립트 컴파일러는 '빌드타임' 오버헤드가 있다.
-
컴파일은 일반적으로 상당히 빠른 편이며 특히 증분 빌드 시에 더욱 체감된다.
-
오버헤드가 커지만, 빌드 도구에서 '트랜스파일만(transpile only)' 을 설정하여 타입 체크를 건너뛸 수 있다.
-
타입스크립트가 컴파일하는 코드는 오래된 런타임 환경을 지원하기 위해 호환성을 높이고 성능 오버헤드를 감안할지, 호환성을 포기하고 성능중심의 네이티브 구현체를 선택할지의 문제에 맞닥뜨릴 수 있다. 하지만 어떤 경우든지 호환성과 성능 사이의 선택은 컴파일 타깃과 언어 레벨의 문제이며 여전히 타입과는 무관하다.
아이템 4 구조적 타이핑에 익숙해지기
자바스크립트는 본질적으로 덕 타이핑(duck typing) 기반이다.
덕 타이핑이란, 객체가 어떤 타입에 부합하는 변수와 메서드를 가질 경우 객체를 해당 타입에 속하는 것으로 간주하는 방식이다. 덕 테스트에서 유래되었는데, 다음과 같은 명제로 정의된다. 만약 어떤 새가 오리처럼 걷고, 헤엄치고, 꽥꽥 거리는 소리를 낸다면 나는 그 새를 오리라고 부를 것이다.
요약
-
자바스크립트가 덕 타이핑(duck typing) 기반이고 타입스크립트가 이를 모델링하기 위해 구조적 타이핑을 사용함을 이해해야한다. 어떤 인터페이스에 할당 가능한 값이라면 타입 선언에 명시적으로 나열된 속성들을 가지고 있다. 타입은 '봉인' 되어있지 않다.
-
클래스 역시 구조적 타이핑 규칙을 따른다. 클래스의 인스턴스가 예상과 다를 수 있다.
-
구조적 타이핑을 사용하면 유닛 테스팅을 손쉽게 할 수 있다.
interface Vector2D{
x: number;
y: number;
}
function calculateLength(v: Vector2D){
return Math.sqrt*v.x * v.x + v.y * v.y);
}이제 이름이 들어간 벡터를 추가한다.
interface NamedVector {
name: string;
x: number;
y: number;
}NamedVector는 number 타입의 x와 y 속성이 있기 때문에 calculateLength 함수로 호출가능하다.
const v: NamedVector = {x: 3, y: 4, name: 'Zee'};
calculateLength(v); // 정상, 결과는 5- Vector2D와 NamedVector의 관계를 전혀 선언하지 않았다.
- NamedVector 를 위한 별도의 calculateLength를 구현할 필요도 없다.
- 타입스크립트 타입 시스템은 자바스크립트의 런타임 동작을 모델링한다. NamedVector 의 구조가 Vector2D와 호환되기 때문에 calculateLength 호출이 가능하다.
- 여기서 '구조적 타이핑' 이라는 용어가 사용된다.
구조적 타이핑 때문에 문제가 발생하기도 한다. 3D 벡터를 만들어보자.
interface Vector3D {
x: number;
y: number;
z: number;
}벡터의 길이를 1로 만드는 정규화 함수를 작성한다.
function normalize(v: Vector3D){
const length = calculateLength(v);
return {
x: v.x / length,
y: v.y / length,
z: v.z / length,
}
}
그러나 이 함수는 1보다 조금 더 긴 (1.41) 길이를 가진 결과를 출력한다.
normalize({x:3, y:4, z:5})
{x: 0.6, y: 0.8, z:1}-
calculateLength는 2D 벡터를 기반으로 연산하는데, 버그로 인해 normalize가 3D 벡터로 연산되었다. z가 정규화에서 무시된 것이다. 그런데 타입 체커가 이 문제를 잡아내지 못했다.
-
calculateLength가 2D벡터를 받도록 선언되었음에도 불구하고 3D 벡터를 받는 데 문제가 없었던 이유는 무엇일까?
-
Vector3D와 호환되는 {x,y,z} 객체로 calculateLength를 호출하면, 구조적 타이핑 관점에서 x와 y가 있어서 Vector2D와 호환된다. 따라서 오류가 발생하지 않았고, 타입 체커가 문제로 인식하지 않았다.
-
타입스크립트는 타입의 확장에 열려있다. 즉, 타입에 선언된 속성 외에 임의의 속성을 추가하더라도 오류가 발생하지 않는다.
가끔 당황스러운 결과가 발생한다.
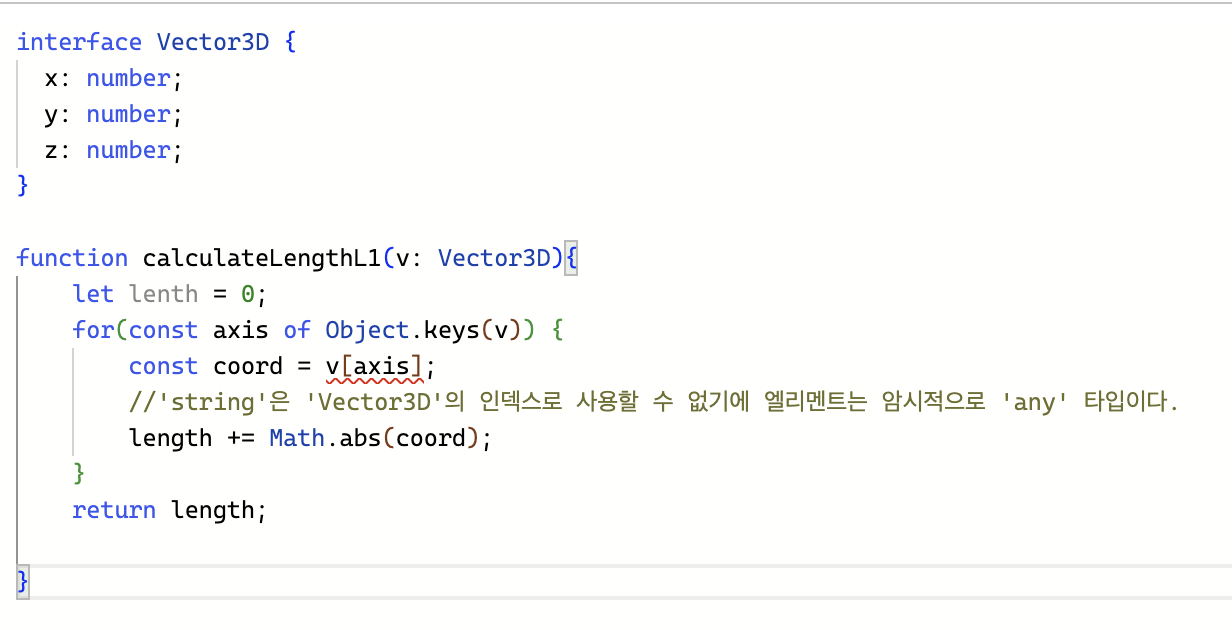
-
axis는 Vector3D 타입인 v의 키 중 하나이기 때문에 "x", "y", "z" 중 하나여야한다. 그리고 Vector3D 의 선언에 따르면, 이들은 모두 number이므로 coord의 타입이 number가 되어야 할 것으로 예상된다.
-
다음 코드 처럼 작성 할 수 있다.
const vec3D = {x: 3, y: 4, z: 1, address: '123 Broadway'}; calculateLengthL1(vec3D); //정상, NaN을 반환합니다. -
v는 어떤 속성이든 가질 수 있기 때문에, axis의 타입은 string이 될 수도 있다. 그러므로 타입스크립트는 v[axis]가 어떤 속성이 될지 알 수 없기 때문에 number라고 확정할 수 없다.
-
정확한 타입으로 객체를 순회하는 것은 까다로운 문제이다.
-
결론은 루프보다는 모든 속성을 각각 더하는 구현이 더 낫다.
function calculateLengthL1(v: Vector3D){
return Math.abs(v.x) + Math.abs(v.y) + Math.abs(v.z);
}- 테스트를 작성할 때는 구조적 타이핑이 유리하다. 데이터 베이스에 쿼리하고 결과를 처리하는 함수를 가정해보자.
interface Author{
first: string;
last: string;
}
function getAuthors(database: PostgresDB): Author[] {
const authorRows = database.runQuery(`SELECT FIRST, LAST FROM AUTHORS`);
return authorRows.map(row => ({first: row[0], last: row[1]}));
}getAuthors 함수를 테스트하기 위해서 모킹한 PostgresDB를 생성해야한다. 그러나 구조적 타이핑을 활용하여 더 구체적인 인터페이스를 정의하는 것이 더 나은 방법이다.
interface Author{
first: string;
last: string;
}
interface DB {
runQuery: (sql: string) => any[];
}
function getAuthors(database: DB): Author[] {
const authorRows = database.runQuery(`SELECT FIRST, LAST FROM AUTHORS`);
return authorRows.map(row => ({first: row[0], last: row[1]}));
}runQuery 메서드가 있기 때문에 실제 환경에서도 getAuthors에 postgresDB를 사욯알 수 있다.
구조적 타이핑 덕분에, PostgresDB가 DB 인터페이스를 구현하는지 명확히 선언할 필요가 ㅇ벗다.
테스트를 작성할 때 , 더 간단한 객체를 매개변수로 사용할 수도 있다.
test('getAuthors', () => {
const authors = getAuthors({
runQuery(sql:string){
return [['Toni','Morrison'], ['Maya', 'Angelou']]
}
expect(authors).toEqual([{first: 'Toni', last: 'Morrison'},{first:'Maya', last: 'Angelou'}])
}타입스크립트는 테스트 DB가 해당 인터페이스를 충족하는지 확인한다.
테스트 코드에는 실제 환경의 데이터베이스에 대한 정보가 불필요하다.
모킹 라이브러리도 필요없다.
추상화(DB) 함으로써, 로직과 테이스를 특정한 구현(PostgresDB)로 부터 분리한 것이다.
아이템 5 any 타입 지양하기
타입스크립트의 타입 시스템은 점진적이고 선택적이다. 이 기능들의 핵심은 any 타입이다.
일부 특별한 경우를 제외하고는 any를 사용하면 타입스크립트의 수많은 장점을 누릴 수 없다. any를 사용하더라도 그 위험성을 알고 있어야한다.
any 타입에는 타입 안전성이 없다.
let age: number;
age = '12' as any; //OKage는 number 타입으로 선언되었으나 as any를 사용하면 string 타입으로 할당할 수 있다. 타입 체커는 선언에 따라 number 타입으로 판단할 것이고 혼돈은 걷잡을 수 없다.
age += 1; //런타임에 정상, age는 "121"any는 함수 시그니처를 무시한다.
함수를 작성할 때는 시그니처를 명시해야 한다. 호출하는 쪽은 약속된 타입의 입력을 제공하고, 함수는 약속된 타입의 출력을 반환한다.
그러나 any 타입을 사용하면 이런 약속을 어길 수 있다.
function calculateAge(birthDate: Date): number {
//...
}
let birthDate: any = '1990-01-19';
calculateAge(birthDate); //정상birthdate 매개변수는 string이 아닌 Date 타입이어야한다. any 타입을 사용하면 calculateAge의 시그니처를 무시한다.
any 타입에는 언어 서비스가 적용되지 않는다.
- 어떤 심벌에 타입이 있다면 타입스크립트 언어 서비스는 자동완성 기능과 적절한 도움말을 제공한다. 그러나 any 타입인 심벌을 사용하면 아무런 도움을 받지 못한다.
- 이름 변경 기능은 또다른 언어 서비스인데.. any를 사용하면 활용할 수 없다.
any 타입은 코드 리팩터링 때 버그를 감춘다.
어떤 아이템을 선택할 수 있는 웹 애플리케이션을 만든다. 애플리케이션에는 onSelectItem 콜백이 있는 컴포넌트가 있다. 선택하려는 아이템의 타입이 무엇인지 알기 어려우니 any를 ㅅ사용한다.
interface ComponentProps {
onSelectItem: (item:any) => void;
}다음과 같이 onSelectItem 콜백이 있는 컴포넌트를 사용하는 코드도 있다.
function renderSelector(props: ComponentProps) {...}
let selectedId: number = 0
function handleSelectItem(item:any){
selectedId = item.id
}
rederSelector({onSelectItem: handleSelectItem}) onSelectItem에 아이템 객체를 필요한 부분만 전달하도록 컴포넌트를 개선해보자. 여기서는 id만 필요하다. ComponentProps의 시그니처를 다음처럼 변경한다.
interface ComponentProps {
onSelectItem: (id: number) => void;
}타입체커를 통과했지만 런타임에는 오류가 발생한다.
any는 타입 설계를 감춘다.
- 설계가 명확히 보이도록 타입을 일일히 작성합시다.
any는 타입시스템의 신뢰도를 떨어뜨린다.
- any타입을 쓰지 않으면 런타임에 발견될 오류를 미리 잡을 수 있고 신뢰도를 높인다.
- 코드내에 존재하는 수많은 any타입으로 인해 자바스크립트보다 일을 더 어렵게 만들기도 한다.
any 쓰지 맙시다.
