벌써 오라클 네번째 업로드! 입니다. 이번에는 그룹함수를 정리해보았습니다
그룹함수
그룹함수는 테이블의 데이터에 집계하는 함수들이며, 결과는 한개만 출력된다.
컬럼을 선택하는 것에 제한이 있고, 함계/평균/갯수/최대값/최소값 등을 구할 때 사용한다.
- SUM() : 테이블의 특정컬럼의 합계값을 출력해주는 함수
- AVG() : 테이블의 특정컬럼의 평균값을 출력해주는 함수
- COUNT() : 테이블의 ROW(데이터) 수를 출력해주는 함수
- MAX() : 테이블의 특정컬럼의 최대값을 출력해주는 함수
- MIN() : 테이블의 특정 컬럼의 최소값을 출력해주는 함수
(그룹함수는 다른컬럼을 추가조회할 수 없다)
- 사원의 급여 합계를 조회하기
SELECT SUM(SALARY)
FROM EMPLOYEE;where과의 차이점 : WHERE 사용하면 FILTER된 ROW만 가지고 계산을 한다.
- 부서가 D5인 사원의 급여 합계를 조회하기
SELECT SUM(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE='D5'; -- 실행순서 : FROM -> WHERE -> SELECT65- 평균 구하기
SELECT AVG(SALARY)
FROM EMPLOYEE;- D5부서의 금여 평균조회하기
SELECT AVG(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE='D5';SELECT문에서 그룹함수 두개 실행하기
SELECT SUM(SALARY),AVG(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE='D5';NULL값 처리
기본적으로 NULL값은 제외하고 계산되기 때문에 NVL로 NULL값 0으로 처리해주는 방법이 있다. (다른 값이 출력됨)
SELECT AVG(BONUS),AVG(NVL(BONUS,0)) --
FROM EMPLOYEE;➡️ 보너스가 없는 사람을 제외하고 평균값을 계산했을 때와 없는 사람의 값을 0으로 넣었을 때의 평균값은 다르기때문에 다른값이 출력된다.

테이블의 데이터수를 조회하기
- COUNT(컬럼명/*)
컬럼명 : 그 컬럼값이 NULL인 ROW는 제외하고 갯수를 출력
* : 모든컬럼값이 NULL이면 제외하고 출력 컬럼에 한개라도 값이 있으면 갯수에 포함
전체 사원수, 전체 부서수, 직책수 등을 구할 수 있다.
SELECT COUNT(*) AS 사원수 ,COUNT(DEPT_CODE) AS DEPT_CODECOUNT
FROM EMPLOYEE;
SELECT COUNT(*) AS 부서수
FROM DEPARTMENT;- 보너스를 받는 사원의 수
SELECT COUNT(*)
FROM EMPLOYEE
WHERE BONUS IS NOT NULL;
SELECT COUNT(BONUS)
FROM EMPLOYEE;✋ 문제풀이
- 급여를 400만원 이상받는 사원의 수는 ?
SELECT COUNT(*)
FROM EMPLOYEE
WHERE SALARY>=4000000;- D6부서의 사원수를 조회하기
SELECT COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE='D6';- 부서가 D6,D7,D5인 사원들의 사원수, 급여합계, 급여 평균을 조회
SELECT COUNT(*),SUM(SALARY),AVG(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE IN('D6','D5','D7');- 최대값, 최소값을 조회하기
-- 최대급여를 조회하기, 최소 급여를 조회하기등에 사용
SELECT MAX(SALARY),MIN(SALARY)
FROM EMPLOYEE;- D5 부서의 최고 급여액, 최소 급여액을 조회하기
SELECT MAX(SALARY),MIN(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE='D5';GROUP BY, HAVTIG
GROUP BY 절
ROW 를 특정컬럼을 기준으로 그룹으로 묶어주는 기능으로 동일한 컬럼값을 한개 그룹으로 묶어준다.
- 표현법
SELECT 컬렴명,컬럼명 .... FROM 테이블명 [WHERE 조건식] [GROUP BY 컬럼명[,컬럼명...];
- 부서별 급여합계 조회하기
SELECT DEPT_CODE,SUM(SALARY)
FROM EMPLOYEE -- 전체 사원에 대한 합계를 구한것
GROUP BY DEPT_CODE;- 직책별 평균 급여를 조회하기
SELECT JOB_CODE,AVG(SALARY)
FROM EMPLOYEE
GROUP BY JOB_CODE;- 부서별 평균급여, 합계 , 사원수 조회하기
SELECT NVL(DEPT_CODE,'인턴'),AVG(SALARY),SUM(SALARY),COUNT(*)
FROM EMPLOYEE
--WHERE DEPT_CODE IS NOT NULL
GROUP BY DEPT_CODE;
GROUP BY절에 다수의 컬럼설정하기
SELECT JOB_CODE,DEPT_CODE,COUNT(*)
FROM EMPLOYEE
GROUP BY JOB_CODE,DEPT_CODE;➡️ WHERE 절에 그룹함수를 사용할 수 없다.
- 최대 급여를 받는 사원
SELECT *
FROM EMPLOYEE
-- WHERE SALARY=MAX(SALARY); --> WHERE에는 그룹함수 쓸 수 없음- 부서의 입원수가 3명 이상 부서
SELECT *
FROM EMPLOYEE
WHERE COUNT(*)>=3; --> 그룹함수 XHAVING
그룹함수를 조건으로 사용하려면 HAVING 절을 사용해야한다.
- 표현법
SELECT 컬럼명, 컬럼명
FROM 테이블명
[WHERE 조건식][GROUP BY 컬럼명]
[HAVIG 조건식]
✋문제풀이
- 부서의 인원수가 3명이상인 부서조회하기
SELECT DEPT_CODE,COUNT(*)
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING COUNT(*) >=3;- 부서의 평균급여가 300만원 이상인 부서 조회하기
SELECT DEPT_CODE,AVG(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING AVG(SALARY)>=3000000;- 직책별 인원수가 3명 이상인 직책 조회하기
SELECT JOB_CODE,COUNT(*)
FROM EMPLOYEE
GROUP BY JOB_CODE
HAVING COUNT(*)>=3;- 매니저가 관리하는 사원이 2명 이상인 매니저 아이디 조회하기
SELECT MANAGER_ID,COUNT(MANAGER_ID)
FROM EMPLOYEE
GROUP BY MANAGER_ID
HAVING COUNT(MANAGER_ID)>=2;- 남자,여자의 급여 평균,인원수 조회하기
SELECT DECODE(SUBSTR(EMP_NO,8,1),'1','남','2','여'),AVG(SALARY),COUNT(*)
FROM EMPLOYEE
GROUP BY SUBSTR(EMP_NO,8,1);- 1900년대 입사한 사원수, 2000년대 입사한 사원수 조회하기
-- 년도 인원수
-- 1900 8
-- 2000 15
로 출력하기
SELECT
DECODE(SUBSTR(TO_CHAR(EXTRACT(YEAR FROM HIRE_DATE)),1,2),
'19','1900년대','20','2000년대')
AS 년도,COUNT(*) AS 사원수
FROM EMPLOYEE
GROUP BY SUBSTR(TO_CHAR(EXTRACT(YEAR FROM HIRE_DATE)),1,2);- -- 1900년도 2000년도
-- 8 15
로 출력하기
SELECT --EXTRACT(YEAR FORM HIRE_DATE),
COUNT(DECODE(SUBSTR(TO_CHAR(EXTRACT(YEAR FROM HIRE_DATE)),1,2),'19','1')) AS "1900년대",
COUNT(DECODE(SUBSTR(TO_CHAR(EXTRACT(YEAR FROM HIRE_DATE)),1,2),'20','1')) AS "2000년대"
FROM EMPLOYEE;ROLLUP과 CUBE
컬럼기준 그룹함수결과, 총 그룹함수의 결과를 출력해주는 함수로,
GROUP BY에 작성한 기준컬럼이 한개일 경우에는 ROLLUP,CUBE차이가 없다.
컬럼기준 그룹함수결과, 총 그룹함수의 결과를 출력한다.
GROUP BY 작성한 기준컬럼이 두개일경우
- ROLLUP : 두개컬럼에 대한 그룹함수 결과, 첫번째 매개변수있는 컬럼의 그룹함수결과, 총 그룹함수의 결과 출력
- CUBE : 두개 컬럼에 대한 그룹함수 결과, 첫번째 매개변수에 있는 컬럼의 그룹함수결과, 두번째 매개변수에 있는 컬럼의 그룹함수결과, 총 그룹함수의 결과출력
- GROUP BY 절 이용해서 조회하기
그냥 WHERE절로 썼을 때 -> 2개로 나눠서 조회해야함👇
SELECT DEPT_CODE,COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY DEPT_CODE;SELECT COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL;➡️ ROLLUP 사용
위의 두개를 안쓰고 한번에 처리가능하다
SELECT DEPT_CODE,COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY ROLLUP(DEPT_CODE);➡️ CUBE
SELECT DEPT_CODE,COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY CUBE(DEPT_CODE);- 두개 컬럼을 기준으로 설정했을 때 ROLLUP
SELECT DEPT_CODE,COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
GROUP BY ROLLUP(DEPT_CODE,JOB_CODE); 두개 컬럼을 기준으로 설정했을 때 CUBE
-> 두개의 컬럼에 대한 집계결과를 출력
-- GROUP BY 없는 것
-- GROUP BY DEPT_CODE
-- GROUP BY JOB_CODE
-- GROUP BY DEPT_CODE,JOB_CODESELECT DEPT_CODE,JOB_CODE,COUNT(*),SUM(SALARY),AVG(SALARY) FROM EMPLOYEE WHERE DEPT_CODE IS NOT NULL GROUP BY CUBE(DEPT_CODE,JOB_CODE);
데이터 정렬하기
조회하는 데이터를 정렬해서 가져오는 함수,
컬럼값을 기준으로 오름차순, 내림차순으로 정렬할 수 있다.
- 표현법
ORDER BY 컬럼명 정렬방식[ASC(DEFAULT)/DESC][컬럼명 정렬방식...] //안적으면 DEFAULT값 (생략이 가능하다)
SELECT 컬럼명
FROM 테이블명
[WHERE]
[GROUPO BY]
[HAVING]
[ORDER BY]✋문제 풀이
- 사원명을 기준으로 내림차순 정렬해서 조회하기
--사원명, 급여, 보너스, 부서코드
SELECT EMP_NAME,SALARY,BONUS,DEPT_CODE
FROM EMPLOYEE
ORDER BY EMP_NAME ASC;- 급여를 많은순으로 사원정보 조회하기
SELECT *
FROM EMPLOYEE
ORDER BY SALARY DESC;- ORDER BY 구문에 여러컬럼 지정하기
기준컬럼값이 동등할 때 다음 기준으로 정렬을 함
SELECT EMP_NAME,DEPT_CODE,JOB_CODE,SALARY
FROM EMPLOYEE
ORDER BY DEPT_CODE,JOB_CODE,SALARY DESC;정렬시 NULL값처리
ORDER BY BONUS ASC; --NULL값을 하단에 배치
ORDER BY BONUS DESC; --NULL값을 상단에 배치
ORDER BY BONUS ASC NULLS LAST;-->NULL값 반대로 상단에 배치
ORDER BY BONUS DESC NULLS LAST;--> NULL값 반대로 하단에 배치
- ORDER BY 절에는 컬럼명이 아닌 인덱스 번호를 사용할 수 있다.
SELECT*FROM EMPLOYEE ORDER BY 2;
- 가상컬럼을 생성했을 때 사용할 수 있다.
SELECT EMP_NAME,SALARY*12 FROM EMPLOYEE ORDER BY 2 DESC;
- ORDER BY 에서 컬럼별칭 사용 가능할까 ? -> 가능하다
SELECT EMP_NAME,SALARY*12 AS TOTAL_SAL FROM EMPLOYEE -- WHERE TOTAL_SAL>=1000000; --오류 ORDER BY TOTAL_SAL DESC;
GROUPING
SELECT CASE WHEN GROUPING(DEPT_CODE)=0 AND GROUPING(JOB_CODE)=1 THEN'부서별 인원수' WHEN GROUPING(DEPT_CODE)=1 AND GROUPING(JOB_CODE)=0 THEN'직책별 인원수' WHEN GROUPING(DEPT_CODE)=1 AND GROUPING(JOB_CODE)=1 THEN'총 인원수' ELSE'직책부서별 인원수' END AS 구분, COUNT(*),DEPT_CODE,JOB_CODE FROM EMPLOYEE GROUP BY CUBE(DEPT_CODE,JOB_CODE) ORDER BY 1;
집합 연산자
여러개의 SELECT문을 한개의 결과(RESULT SET)으로 출력해주는 연산자로
첫번째 SELECT문의 컬럼수와 이후 작성되는 SELECT문의 컬럼수가 같아야하고,
컬럼의 타입도 동일해야한다
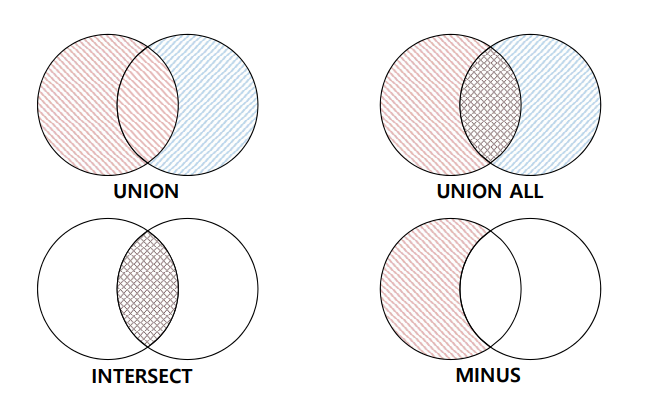
UNION
SELECT문
UNION
-SELECT문
[UNION
SELECT문] SELECT EMP_ID,EMP_NAME,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE DEPT_CODE='D5'
UNION
SELECT EMP_ID,EMP_NAME,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE SALARY>=3000000;UNIONALL
- 중복값도 출력함
SELECT EMP_ID,EMP_NAME,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE DEPT_CODE='D5'
UNION ALL
SELECT EMP_ID,EMP_NAME,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE SALARY>=3000000;- 부서코드, 부서명과 직책코드와 직책명을 다 조회하기
(테이블이 다르기때문에 연관관계가 없음)
SELECT DEPT_ID,DEPT_TITLE
FROM DEPARTMENT
UNION
SELECT JOB_CODE,JOB_NAME
FROM JOB;- 컬럼의 타입도 같아야한다.
DESC JOB; --> 타입 : 문자열
DESC DEPARTMENT; --> 타입 : 문자열
SELECT DEPT_ID,DEPT_TITLE
FROM DEPARTMENT
UNION
SELECT JOB_CODE,JOB_NAME
FROM JOB;INTERSECT
SELECT EMP_ID,EMP_NAME,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE DEPT_CODE='D5'
INTERSECT
SELECT EMP_ID,EMP_NAME,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE SALARY>=3000000; MINUS
SELECT EMP_ID,EMP_NAME,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE DEPT_CODE='D5'
MINUS
SELECT EMP_ID,EMP_NAME,DEPT_CODE,SALARY
FROM EMPLOYEE
WHERE SALARY>=3000000;
JOIN
두개 이상의 테이블을 특정컬럼을 기준으로 연결하는 기능으로 두가지의 종류가 있다.
- JOIN 두가지 종류
- INNER JOIN : 기준컬럼값과 일치하는 값이 있는 ROW만 연결하는 JOIN문 * 없는 ROW 제외
- OUTER JOIN : 기준 컬럼값과 일치하는 값이 없는 ROW도 가져오게 하는 JOIN문 * 전체 ROW를 가져올 테이블 설정/ 일치하는 값이 없는 ROW NULL값으로 연결
JOIN문 작성법
1. 오라클 조인 : SELECT 컬럼명, 컬럼명, ... FROM 테이블, 테이블 B WHERE 테이블,컬럼명=테이블B 컬럼명
2. ANSI : SELECT 컬럼명, 컬럼명 .... FROM 테이블 JOIN 테이블 B ON 테이블.컬럼명=테이블 B.컬럼명
-> JOIN 기준의 컬럼은 유일한값을 가지고 있어야한다. -> PK설정된 컬럼값 이용
➡️ 사원정보, 사원의 부서정보 전체 출력하기
- 오라클 조인으로 EMPLOYEE,DEPARTMENT 조인하기
SELECT*FROM EMPLOYEE,DEPARTMENT WHERE DEPT_CODE=DEPT_ID;INNER조인
SELECT EMP_NAME,SALARY,DEPT_TITLE FROM EMPLOYEE,DEPARTMENT WHERE DEPT_CODE=DEPT_ID;- ANSI조인으로도 해보기
- INNER JOIN
SELECT *FROM EMPLOYEE JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID;
SELECT EMP_NAME,SALARY,DEPT_TITLE,LOCATION_ID
FROM EMPLOYEE JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID; -- OUTER JOIN 은 JOIN앞에 LEFT를 써준다.✋문제풀이
- 사원에 대한 사원명, 이메일, 전화번호, 부서명을 조회하기
SELECT EMP_NAME,EMAIL,PHONE,DEPT_TITLE
FROM EMPLOYEE JOIN DEPARTMENT ON DEPT_ID=DEPT_CODE;- 사원 중 회계관리부에 근무하는 사원의 부서명, 사원명, 급여 보너스 조회하기
SELECT DEPT_TITLE, EMP_NAME,SALARY,BONUS
FROM EMPLOYEE JOIN DEPARTMENT ON DEPT_ID =DEPT_CODE
WHERE DEPT_TITLE='회계관리부';- 사원 중 대리 직책을 가지고 있는 사원의 직책명, 사원명, 급여, 보너스 조회하기
SELECT *FROM JOB;
SELECT *FROM EMPLOYEE;컬렴명이 동일하다면 앞에 테이블명. 을 찍어서 구분해야하거나 별칭을 부여하여 구분해야함
SELECT JOB_NAME, EMP_NAME,SALARY,BONUS -- FROM EMPLOYEE JOIN JOB ON EMPLOYEE.JOB_CODE=JOB.JOB_CODE; FROM EMPLOYEE E JOIN JOB J ON E.JOB_CODE=J.JOB_CODE;SELECT에도 동일한 컬럼명일 때 사용해서 구분해줘야함
SELECT E.JOB_CODE,JOB_NAME,EMP_NAME,SALARY,BONUS FROM EMPLOYEE E JOIN JOB J ON E.JOB_CODE=J.JOB_CODE;
USING
USING : JOIN할 때 연결할 컬럼 명칭이 동일하면 USING 예약어를 사용할 수 있다.
- USING으로 묶었을 때 JOB_CODE는 하나만 출력됨
- USING을 사용할 때 SELECT에는 식별자를 쓰지 못한다.
( 따로 부여할 필요 없음 )SELECT** FROM EMPLOYEE E JOIN JOB J USING(JOB_CODE); -> 같은 JOB_CODE 컬럼으로 묶어줬기때문에 (컬럼명이 같기때문에 USING 사용 가능)
✋문제풀이
- ASIA 가 근무지역인 부서의 부서명 조회하기
SELECT *FROM LOCATION;
SELECT *FROM DEPARTMENT;
SELECT DEPT_TITLE
FROM DEPARTMENT JOIN LOCATION ON LOCATION_ID=LOCAL_CODE
WHERE LOCAL_NAME LIKE 'ASIA%';- JOIN문에서 GROUP BY 이용하기
부서명별 사원수, 평균급여를 조회하기, 평균급여가 3000000이상
SELECT DEPT_TITLE,COUNT(*) AS EMP_COUNT,AVG(SALARY) AS AVG_SAL
FROM EMPLOYEE JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
GROUP BY DEPT_TITLE
HAVING AVG(SALARY)>=3000000
ORDER BY 3;
OUTER JOIN
- JOIN 표현법
JOIN 테이블명 LEFT/LIGHT JOIN 테이블명 ON 조건SELECT * FROM EMPLOYEE JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID; --DEPT_CODE가 NULL인사람들은 빼고 나옴 얘네도 출력하고 싶을때 OUTER을 사용함
- OUTER사용해서 NULL값도 포함시키기
- LEFT
SELECT * FROM EMPLOYEE LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID;➡️ TRUE가 나오는 값들은 ROW로 연결하고 연결이 안돼서 FALSE가 나오는 값들은 NULL로 출력( 왼쪽 기준 컬럼값)
- RIGHT
SELECT * FROM EMPLOYEE RIGHT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID;➡️ TRUE가 나오는 값들은 ROW로 연결하고 연결이 안돼서 FALSE가 나오는 값들은 NULL로 출력(오른쪽 기준 컬럼값)
- 참조되는 컬럼값이 필수일때는 INNER JOIN으로 데이터를 가져오고
- 참조되는 컬럼값이 선택일 때는 OUTER JOIN으로 데이터를 가져온다.
- 사원이 없는 부서 조회하기
- 부서명 조회
SELECT DEPT_TITLE
FROM DEPARTMENT LEFT JOIN EMPLOYEE ON DEPT_CODE=DEPT_ID
WHERE DEPT_CODE IS NULL;
- CROSS JOIN : 전체 ROW를 연결하는 JOIN 구문
SELECT * FROM EMPLOYEE CROSS JOIN DEPARTMENT ORDER BY 2;
- SELF JOIN : 테이블 한개를 이용해서 JOIN을 하는 것
-- 자기 자신을 참조하는 컬럼이 있어야 한다.
SELECT*FROM EMPLOYEE;--EMP_ID와 MANAGER_ID가 같음
- 사원의 매니저 정보를 조회하기
사원번호, 사원명, 매니저 사원 번호, 매니저 사원명 출력
SELECT E.EMP_ID,E.EMP_NAME,E.MANAGER_ID,M.EMP_NAME
FROM EMPLOYEE E JOIN EMPLOYEE M ON E.MANAGER_ID=M.EMP_ID;
- 비동등조인
SELECT EMP_ID,SAL_GRADE.SAL_LEVEL FROM EMPLOYEE JOIN SAL_GRADE ON SALARY BETWEEN MIN_SAL AND MAX_SAL;
- 다중 조인 : 두개 이상의 테이블을 조인함
사원의 사원명, 부서명, 직책명, 급여, 보너스 조회하기 등에 사용- 표현법
FROM 테이블 JOIN 테이블 ON 조건 JOIN 테이블 ON 조건 SELECT EMP_NAME,DEPT_TITLE,JOB_NAME,SALARY,BONUS FROM EMPLOYEE LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID JOIN JOB USING(JOB_CODE);
- 사원명, 부서명,직책명, 지역명, 지역코드, 국가 코드를 조회하기
SELECT EMP_NAME,DEPT_TITLE,JOB_NAME,LOCAL_NAME,LOCAL_CODE,NATIONAL_CODE
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
JOIN JOB USING(JOB_CODE)
LEFT JOIN LOCATION ON LOCATION_ID=LOCAL_CODE
LEFT JOIN NATIONAL USING(NATIONAL_CODE);✋ 문제풀이
- 주민번호가 1970년대 생이면서 성별이 여자이고, 성이 전씨인 직원들의 사원명, 주민번호, 부서명, 직급명을 조회하시오.
SELECT*FROM TAB;
SELECT EMP_NAME,EMP_NO,DEPT_TITLE,JOB_NAME
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
JOIN JOB USING(JOB_CODE)
WHERE SUBSTR(EMP_NO,1,1)=7 AND SUBSTR(EMP_NO,8,1)=2 AND EMP_NAME LIKE '전%';- 이름에 '형'자가 들어가는 직원들의 사번, 사원명, 부서명을 조회하시오.
SELECT EMP_ID,EMP_NAME,DEPT_CODE
FROM EMPLOYEE LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
WHERE EMP_NAME LIKE '%형%';- 해외영업부에 근무하는 사원명, 직급명, 부서코드, 부서명을 조회하시오.
SELECT EMP_NAME,JOB_NAME,DEPT_CODE,DEPT_TITLE
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
WHERE DEPT_TITLE LIKE'해외%';- 보너스포인트를 받는 직원들의 사원명, 보너스포인트, 부서명, 근무지역명을 조회하시오.
SELECT EMP_NAME,BONUS,DEPT_TITLE,LOCAL_NAME
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
LEFT JOIN LOCATION ON LOCAL_CODE=LOCATION_ID
WHERE BONUS IS NOT NULL;- 부서코드가 D2인 직원들의 사원명, 직급명, 부서명, 근무지역명을 조회하시오.
SELECT EMP_NAME,JOB_NAME,DEPT_TITLE,LOCAL_NAME
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
LEFT JOIN LOCATION ON LOCAL_CODE=LOCATION_ID
WHERE DEPT_CODE='D2';- 급여등급테이블의 최대급여(MAX_SAL)보다 많이 받는(실수령액) - 보너스를 포함한 월급 직원들의 사원명, 직급명, 급여, 연봉을 조회하시오.
(사원테이블과 급여등급테이블을 SAL_LEVEL컬럼기준으로 조인할 것)
SELECT EMP_NAME,JOB_NAME,SALARY,(SALARY+(SALARY*NVL(BONUS,0)))*12 AS 연봉
FROM EMPLOYEE
JOIN JOB USING(JOB_CODE)
LEFT JOIN SAL_GRADE USING(SAL_LEVEL)
WHERE MAX_SAL<SALARY+SALARY*NVL(BONUS,0);- 한국(KO)과 일본(JP)에 근무하는 직원들의 사원명, 부서명, 지역명, 국가명을 조회하시오.
SELECT EMP_NAME,DEPT_TITLE,LOCAL_NAME,NATIONAL_NAME
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID
LEFT JOIN LOCATION ON LOCAL_CODE=LOCATION_ID
LEFT JOIN NATIONAL USING(NATIONAL_CODE)
WHERE NATIONAL_NAME IN('한국','일본');- 같은 부서에 근무하는 직원들의 사원명, 부서명, 동료이름을 조회하시오. (self join 사용)
SELECT E.EMP_NAME,DEPT_TITLE,D.EMP_NAME
FROM EMPLOYEE E JOIN EMPLOYEE D ON E.DEPT_CODE=D.DEPT_CODE
LEFT JOIN DEPARTMENT ON E.DEPT_CODE=DEPT_ID
WHERE E.EMP_NAME!=D.EMP_NAME
ORDER BY 1;- 보너스포인트가 없는 직원들 중에서 직급이 차장과 사원인 직원들의 사원명, 직급명, 급여를 조회하시오. 단, join과 IN 사용할 것
SELECT EMP_NAME,JOB_NAME,SALARY
FROM EMPLOYEE JOIN JOB USING(JOB_CODE)
WHERE BONUS IS NULL AND JOB_NAME IN('차장','과장');- 재직중인 직원과 퇴사한 직원의 수를 조회하시오.
SELECT COUNT(ENT_DATE) AS 재직중인직원, COUNT(*)- COUNT(ENT_DATE) AS 퇴사한직원
FROM EMPLOYEE;-- 다르게 푸는 방법
SELECT DECODE(ENT_YN,'N','재직','퇴사') 재직여부,COUNT(*) 수
FROM EMPLOYEE
GROUP BY DECODE(ENT_YN,'N','재직','퇴사');오라클 하면서 첫번째 난관에 부딫힌 느낌이지만 많은 문제를 풀어보는게 도움이 될거같아요. 화이팅
