접속 -> mysql -u root -p
명령어는 대소문자를 구분하지 않는다.
하지만;는 반드시 붙여준다.
Database
데이터베이스 사용자 정보 확인
SHOW DATABASES;데이터베이스 생성 ; create
CREATE DATABASE 데이터베이스_이름;데이터베이스 사용 ; use
데이터베이스를 이용해 작업을 하려면, 먼저 사용하겠다는 명령을 전달해야 한다.
USE 데이터베이스_이름;데이터베이스 삭제 ; drop
DROP DATABASE 데이터베이스_이름;Table
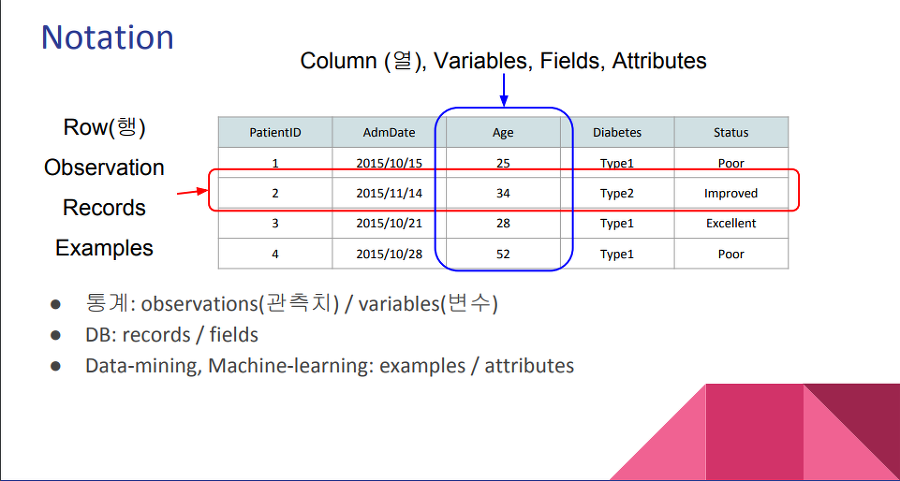
개체(Entity) ; Record
정보 혹은 개념의 단위.
하나의 개체는 여러 속성(필드)을 가진다.
속성(Attribute) ; Field
데이터의 가장 작은 논리적 단위
관계(Relationship)
개체와 개체 사이의 의미가 존재할 때 관계가 있다.
테이블 생성
USE로 데이터베이스를 선택했다면, 테이블을 만들 수 있다.
생성하고자 하는 테이블명과 필드명을 지정한다.
소괄호() 내부는 마치 객체처럼, 컬럼명(필드)과 레코드의 데이터 타입을 정해준다.
create table 테이블_이름 (
id int PRIMARY KEY AUTO_INCREMENT,
... more
);데이터 타입
CHAR, VARCHAR, TEXT; 문자열 타입
CHAR vs VARCHAR
길이(byte)를 함께 명시한다.
CHAR는 고정형으로 길이에 못 미치더라도 그 만큼의 데이터를 잡는다.
추후 크기에 따라 연산할 필요가 없어 속도가 월등히 빠르다.
아이디, 주민번호처럼 길이가 고정적일 때 사용한다.
VARCHAR(variable char)은 가변형으로 데이터의 실제 길이에 따라 정해진다.
상황에 맞게 타입을 정한다면 공간과 시간복잡도를 고려한 효율적인 관리일 것이다.
-
INT; 정수 타입 -
TIMESTAMP; 날짜 및 시간 타입
테이블 삭제
drop table 테이블_이름;
truncate table 테이블_이름;테이블 확인
- 테이블 목록 확인
show tables;
show tables from 데이터베이스_이름;- 특정 테이블 정보(구조) 확인 DESCRIBE
desc 테이블_이름;Record(Data) CRUD
CREATE
Insert into
INSERT INTO 문과 VALUES 절을 사용하여 해당 테이블에 새로운 레코드를 추가할 수 있다.
Insert into 테이블_명 (
필드_명1, 필드_명2, 필드_명3, ...)
Values (필드_값1, 필드_값2, 필드_값3, ...);
Insert into 테이블_명
Values (필드_값1, 필드_값2, 필드_값3, ...);필드값이 문자열이면 반드시 따옴표를 사용해야 한다.
추가하는 레코드가 반드시 모든 필드값을 가져야 할 필요는 없다.
(일부 필드만 가진 레코드를 추가 할 수도 있다. 나머지 NULL)
필드명을 생략한다면, 데이터베이스의 스키마와 같은 순서대로 필드값이 자동 대입된다.
생략할 수 있는 필드는 다음과 같다.
-
NULL을 저장할 수 있도록 설정된 필드
-
DEFAULT 제약 조건이 설정된 필드
-
AUTO_INCREMENT 키워드가 설정된 필드
READ
Select, From
Select A From B
-> B 테이블에서 A 필드의 데이터를 가져오라
Select * From 테이블_명;
Select 특정_필드_명 From 테이블_명;Distinct 유니크한 값들만 선택할 때
Where
필터 역할을 하는 쿼리문으로 선택적으로 사용한다.
= 특정값과 동일한 데이터 찾기
<> 특정값을 제외한 데이터 찾기
>, <, <=, >= 특정값과 비교해 데이터 찾기
IN 리스트의 값들과 일치하는 데이터를 필터링할 때
WHERE 필드_명 IN ("특정값_1", "특정값_2")IS (NOT) NULL NULL을 찾거나 제외할 때
NOT 제외하고 필터링할 때
BETWEEN
AND OR
LIKE 특정값을 포함한 값을 필터링할 때
'a%' a로 시작하는 문자열
'%a' a로 끝나는 문자열
'%a%' a를 가진 문자열
'a%b' a로 시작하고 b로 끝나는 문자열
'_a%' 두번째 문자가 a인 문자열
'[abc]%' 시작 문자가 a || b || c인 문자열
'[a-f]%' 시작 문자가 a와 f 사이인 문자열
'[!abc]%' 시작 문자가 a && b && c가 아닌 문자열
Order By
데이터 결과를 어떤 기준으로 정렬하여 출력할지 결정
기본적으로 alphabetically 오름차순이다.
끝에 DESC를 붙이면 reversed 내림차순이다.
Group By
집계함수의 결과를 특정 필드 기준으로 묶어 조회하는 쿼리이다.
HAVING GROUP BY로 조회된 결과를 필터링
SELECT column1, 집계함수(column2)
FROM table
WHERE column2 = data
GROUP BY column1;
HAVING 집계함수(column2) > 비교할_값
ORDER BY ~HAVING vs WHERE
HAVING은 그룹화한 결과에 대한 필터이고, WHERE는 저장된 레코드를 필터링한다.
따라서 실제로 그룹화 전에 데이터를 필터해야 한다면, WHERE을 사용한다.
Limit
출력할 데이터의 갯수를 정할 수 있다. 쿼리문의 가장 마지막에 추가한다.
ALIAS
사전적 의미로 '가명', '별명'이며, 본래 이름 대신에 사용 한다는 뜻이다.
SELECT문에AS절로 표현한다.
Update
UPDATE문과 SET절을 사용해 레코드를 변경할 수 있다.
UPDATE 테이블_명
SET 필드_명 = 원하는_필드_값;
UPDATE 테이블_명
SET 필드_명2 = 원하는_필드_값
WHERE 필드_명1 = 필드명_값;DELETE
DELETE FROM 테이블_명;
DELETE FROM 테이블_명
WHERE 필드_명 = 필드명_값;JOIN
테이블을 연결할 때 ON절과 함께 쓰인다.
INNER JOIN
둘 이상의 테이블을 서로 공통된 부분 기준으로 연결
JOIN INNER JOIN
SELECT *
FROM 테이블_1
JOIN 테이블_2 ON 테이블_1.필드_A = 테이블_2.필드_BOUTER JOIN
LEFT JOIN RIGHT JOIN
출처
