
RDS

RDS는 Relational Database Service의 약자로, SQL을 언어로 사용하는 완전 관리형 관계형 데이터베이스 서비스이다.
RDS의 특징
1. Read Replicas
- 백업과 성능향상을 위해서 데이터베이스를 여러 대의 서버에 복제하는 행위를 Replication이라고 하는데, RDS에서도 읽기 전용 복제본을 최대 5개까지 만들 수 있다.
- SELECT 쿼리와 같은 read 작업만 가능하다.
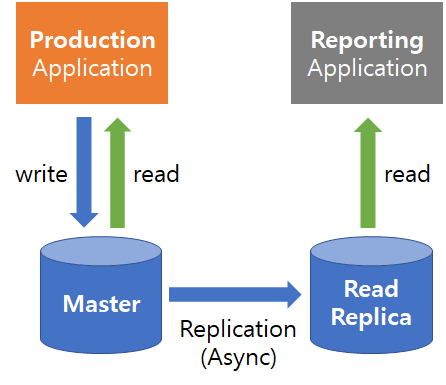 비동기 방식이라 짧은 시간 동안 Replica와 Master 간의 데이터 차이가 발생할 수 있다는 한계는 있다.
비동기 방식이라 짧은 시간 동안 Replica와 Master 간의 데이터 차이가 발생할 수 있다는 한계는 있다.
2. Storage Auto Scaling
- 데이터베이스 인스턴스의 수를 증가시키거나 감소시키는 horizontal scaling이다.
(* vertical scaling : adding more power (CPU, RAM, storage, etc.) to an existing machine.) - 읽기 부하가 높을 때에는 추가적인 read replica를 자동으로 생성(최대 5개)하여 부하를 분산한다.
3. Multi AZ (다중 AZ)
- 다중 AZ를 설정하면 AZ별 인스턴스에는 마스터 DB로부터 동기적인 복제가 일어난다.
- 하나의 작업이 완료될 때까지 다음 작업이 시작되지 않아서 동기적이 복제가 실패하지 않는 이상은 데이터의 일관성을 지킬 수 있다.
- 여러개의 RDS 이지만, 하나의 DNS만 바라본다.
(CNAME DNS를 통해 여러개의 RDS지만 하나의 도메인으로 접속해서 거기서 특정 데이터베이스로 접속하게 되는 것!)
서버를 이중화하는 방법
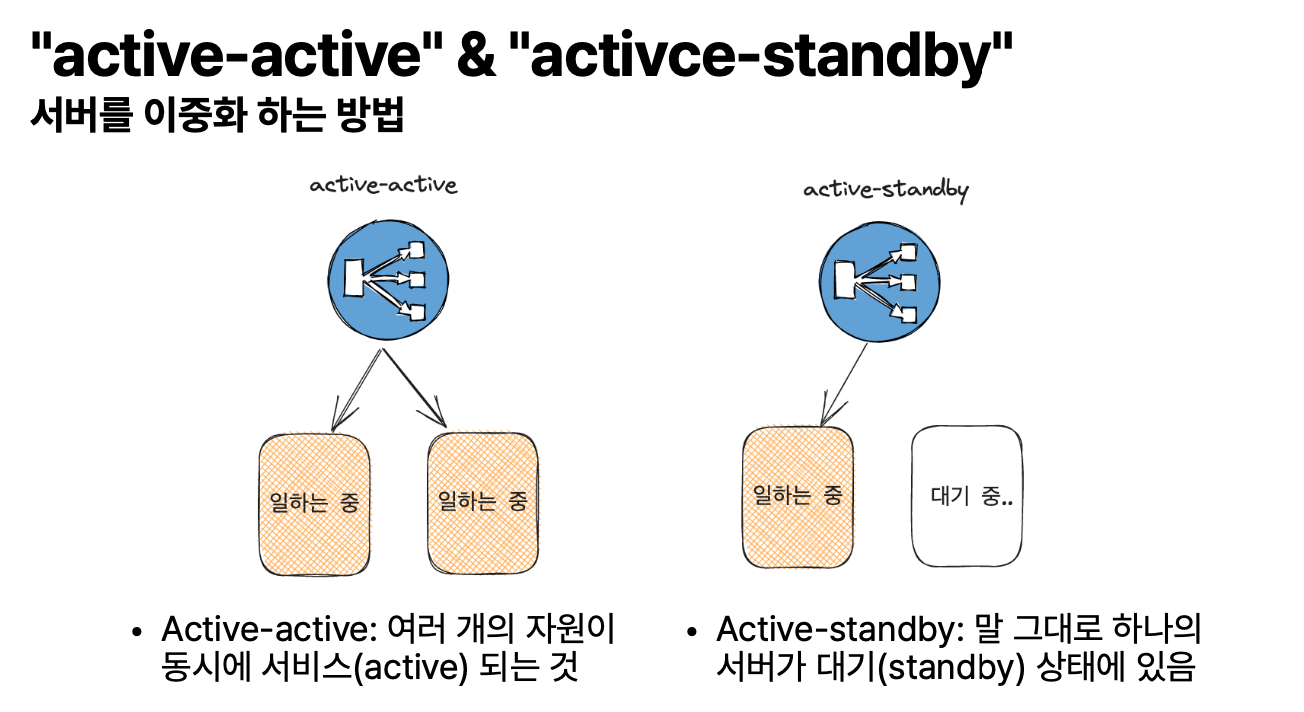 그래서 평소에는 read/write 작업 둘 다 지원을 하지 않는데, active에 장애가 되면 standby에서 active로 승격되서 그때부턴 read/write 둘 다 가능해진다고 한다! (인터레스팅)
그래서 평소에는 read/write 작업 둘 다 지원을 하지 않는데, active에 장애가 되면 standby에서 active로 승격되서 그때부턴 read/write 둘 다 가능해진다고 한다! (인터레스팅)
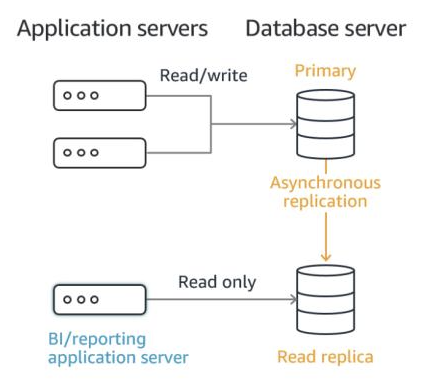
Read Replica는 Read만 가능하고 Primary 서버에서 read와 write가 가능하다!
RDS 사용하기 vs EC2에서 MySQL 사용하기

$20.5 정도 차이가 난다고 생각하면 DBA(데이터베이스 관리자)를 고용하는 것보다는 나을지도 모르겠다.
관리형 서비스니까 데이터 내결함성( 시스템의 일부 구성 요소가 작동하지 않더라도 계속 작동할 수 있는 기능)이 중요하다면 RDS의 장점을 이용해보는 것도 나쁘지는 않을 것 같다.
 이 글을 참고해보면 EC2에서 mysql을 사용하는 것과 RDS를 사용하는 것의 차이를 이해하기 좋다!
이 글을 참고해보면 EC2에서 mysql을 사용하는 것과 RDS를 사용하는 것의 차이를 이해하기 좋다!
DynamoDB
managed serverless NoSQL DB로
- 완전 관리형
- 서버리스
- 관계형 데이터베이스가 아닌
서비스이다.
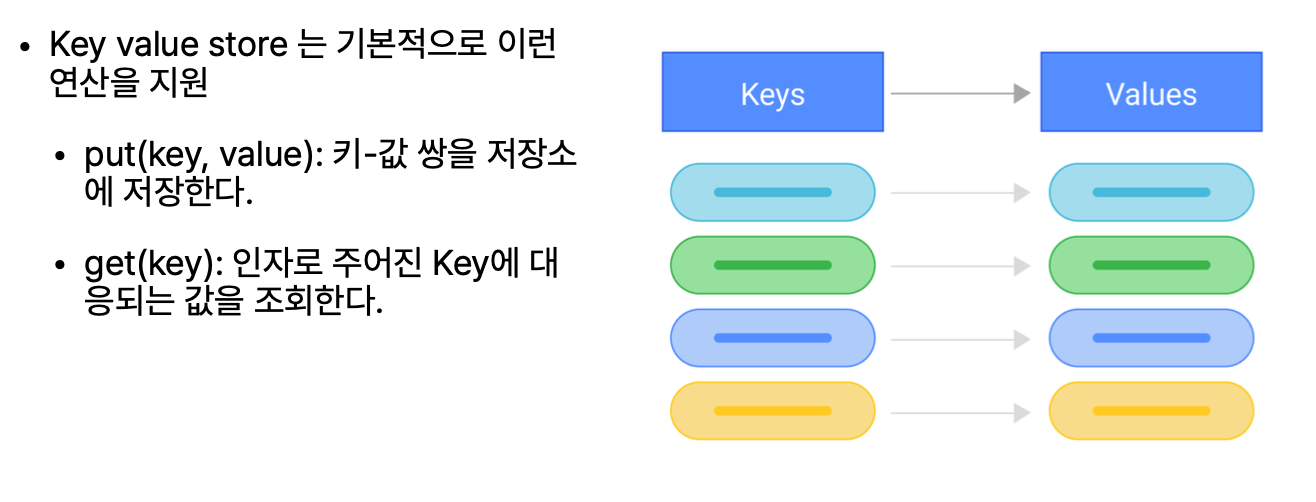 DynamoDB는 이렇게 key-value쌍으로 데이터를 저장한다.
DynamoDB는 이렇게 key-value쌍으로 데이터를 저장한다.
DynamoDB를 사용할만한 이유
- 특정 시간 동안만 데이터가 저장되는 TTL 기능을 지원한다.
- DAX 클러스터를 읽기 캐시로 사용할 수 있다.
- 클라이언트는 일반적으로 DynamoDB 엔드포인트 대신 DAX 엔드포인트를 사용하여 데이터에 액세스하여 ms 단위의 latency만 갖고도 충분히 데이터를 읽어올 수 있다.
- Global Table 기능
- 여러 서로 다른 리전에 테이블을 복사하고 이들 각각에 대해 active-active 설정을 하여 어디서든 빠르게 접근할 수 있다.
- DynamoDb 스트림과 Lambda/Kinesis Data Streams를 통합할 수 있다.
- Dynamo 테이블의 모든 변화에 따라 함수를 호출할 수 있다.
- 운영하다 장애가 발생하면 AWS support의 도움으로 어떻게든 문제를 해결 할 수 있다고 한다.
느낀점
DynamoDB가 뭔가 좋다는 건 알겠는데,,,
아직 DB에 대한 지식이 많이 부족해서 구조에 대한 글을 읽어도 좀 와닿지 않는 부분이 있어서 DB에 대해 공부를 좀 하고 다시 DynamoDB 문서를 읽어봐야겠다!

🌱Connecting the dots🌱