
🦖 Operating System Concepts 10th
PART TWO PROCESS MANAGEMENT
Chapter 5 CPU Scheduling
이전 글인 프로세스에서 프로세스 스케줄러의 세 가지 유형을 살펴보았다.
- Long Term Scheduler
- Medium Term Scheduler
- Short Term Scheduler (CPU Scheduler)
이 글에서는 단기 스케줄러에 해당하는 CPU 스케줄러를 알아보자.
Basic Concepts
CPU 스케줄링은 멀티 프로그램 운영체제의 기본이다. 운영체제는 CPU를 프로세스 간에 교환(switch)함으로써, 컴퓨터를 보다 생산적으로 만든다.
멀티 프로그래밍의 목적은 CPU 이용률을 최대화하기 위해 항상 실행 중인 프로세스를 가지게 하는 데 있다. 멀티 프로그래밍에서는 어느 한순간에 다수의 프로세스를 메모리 내에 유지하고, 어떤 프로세스가 대기(wait)해야 할 경우, 운영체제는 CPU를 그 프로세스로부터 회수해 다른 프로세스에 할당한다.
CPU-I/O Burst Cycle
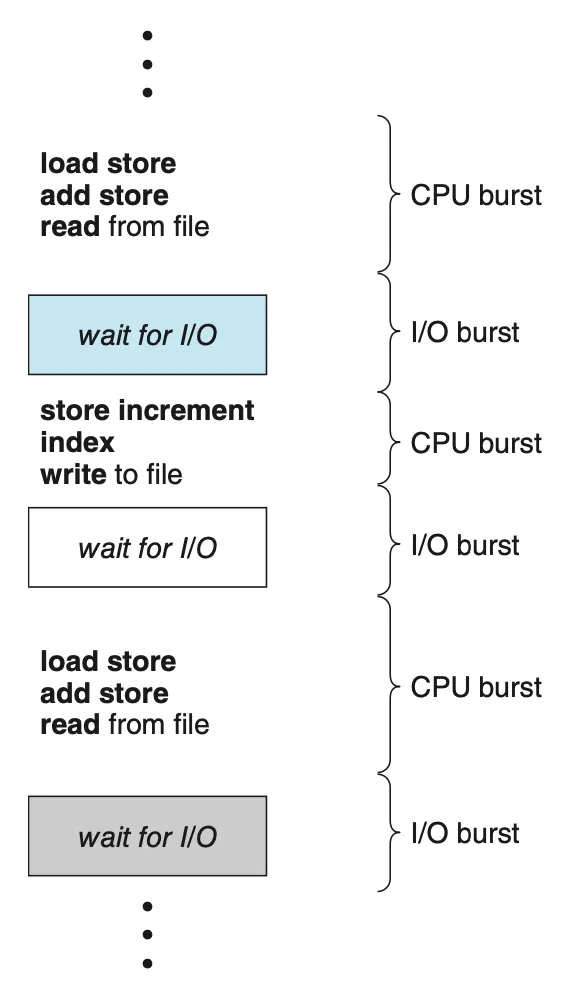
프로세스 실행은 CPU 실행과 I/O 대기(wait)의 사이클로 구성된다. 프로세스들은 두 상태 사이를 교대로 왔다 갔다 한다. 프로세스 실행은 CPU burst로 시작된다. 뒤이어 I/O burst가 발생하고, CPU와 I/O burst가 교차 발생한다.
 |  |
|---|---|
| Figure 5.1 Alternating sequence of CPU and I/O bursts. | Figure 5.2 Histogram of CPU-burst durations. |
CPU burst의 분포는 CPU 스케줄링 알고리즘을 구현할 때 매우 중요할 수 있다.
CPU Scheduler
CPU가 유휴 상태(idle)가 될 때마다, 운영체제는 준비(ready) 큐에 있는 프로세스 중에서 하나를 선택해 실행해야 한다. 선택 절차는 CPU 스케줄러에 의해 수행된다. 스케줄러는 실행 준비(ready)가 되어 있는 메모리 내의 프로세스 중에서 선택하여, 이들 중 하나에게 CPU를 할당(allocate)한다.
준비(ready) 큐를 구현하는 방식은 다양하다. (e.g. FIFO 큐, 우선순위 큐, 트리, 연결 리스트 등)
큐에 있는 레코드들은 일반적으로 프로세스들의 프로세스 제어 블록(PCB)들이다.
Preemptive and Nonpreepmtive Scheduling
비선점(nonpreemptive) 스케줄링
CPU가 한 프로세스에 할당되면 프로세스가 종료하거나 대기(wait) 상태로 전환해 CPU를 방출(release)할 때까지 점유한다. 이러한 스케줄링 방법을 비선점(nonpreemptive) 또는 협력적(cooperative)이라고 한다.
선점(preemptive) 스케줄링
프로세스가 스케줄러에 의해 선점(preemptive)될 수 있다. 시분할 시스템에서 time slice가 만료되었거나, 인터럽트나 시스템 호출 종료 시에 더 높은 우선 순위 프로세스가 있을 때, 실행되고 있는 프로세스로부터 강제로 CPU를 회수한다.
선점 스케줄링은 데이터가 다수의 프로세스에 의해 공유될 때 race condition을 초래할 수 있다. 선점은 또한 운영체제 커널 설계에 영향을 주는데, 선점형 커널에는 공유 커널 데이터 구조에 액세스 할 때 race condition 방지를 위해 mutex lock과 같은 기법이 필요하다.
Cf. Windows, macOS, Linux 및 UNIX를 포함한 거의 모든 최신 운영체제들은 선점 스케줄링 알고리즘을 사용한다.
CPU 스케줄링 결정 (Decision Making for CPU-Scheduling)
- 프로세스가 running 상태에서 waiting 상태로 전환될 때 (e.g. I/O 요청, 자식 프로세스 종료를 기다리기 위해
wait()호출) - 프로세스가 running 상태에서 ready 상태로 전환될 때 (e.g. 인터럽트 발생)
- 프로세스가 waiting 상태에서 ready 상태로 전환될 때 (e.g. I/O 종료)
- 프로세스가 종료(terminate)할 때
상황 1과 4의 경우에는 비선점(nonpreemptive) 스케줄링만 발생한다.
상황 2와 3의 경우에는 비선점(nonpreemptive)과 선점(preemptive) 스케줄링 중 선택이 가능하다.
Dispatcher
디스패처(dispatcher)는 CPU 코어의 제어를 CPU 스케줄러가 선택한 프로세스에 주는 모듈이다.
디스패처의 기능은 다음과 같다.
- 한 프로세스에서 다른 프로세스로 문맥 교환 (context-switching)
- 사용자 모드로 전환
- 프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동 (jump)
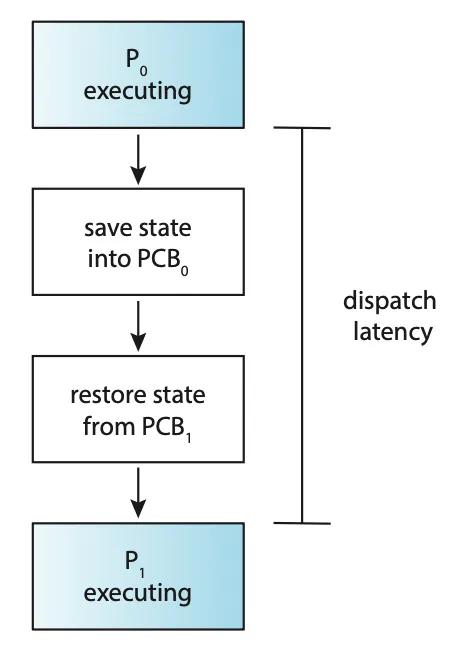
디스패처는 모든 프로세스의 문맥 교환 시 호출되므로, 가능한 한 빨리 수행되어야 한다. 디스패치 지연(dispatch latency)이란 디스패처가 한 프로세스를 정지하고 다른 프로세스의 수행을 시작하는 데까지 소요되는 시간이다.
 |
|---|
| Figure 5.3 The role of the dispatcher. |
Scheduling Criteria
CPU 스케줄링 알고리즘을 비교하기 위한 여러 기준이 있다.
CPU 이용률(utilization)
CPU를 가능한 한 최대한 바쁘게 유지하기를 원한다.
CPU 이용률은 개념적으로는 0에서 100% 범위를 갖지만, 실제 시스템에서는 40%(부하가 적은 시스템의 경우)에서 90%(부하가 큰 시스템의 경우)의 범위를 가져야 한다.
처리량(throughput)
CPU가 프로세스를 실행하느라 바쁘다면, 작업이 진행되고 있는 것이다.
작업량 측정의 한 방법은 단위 시간당 완료된 프로세스의 개수로, 이것을 처리량(throughput)이라고 한다.
총처리 시간(turnaround time)
프로세스의 제출(submission) 시간과 완료 시간의 간격을 총처리 시간이라고 한다.
총처리 시간 = 준비(ready) 큐에서 대기한 시간 + CPU에서 실행하는 시간 + I/O 시간을 합한 시간
대기 시간(waiting time)
CPU 스케줄링 알고리즘은 프로세스가 준비(ready) 큐에서 대기하는 시간의 양에만 영향을 준다.
대기 시간은 준비(ready) 큐에서 대기하면서 보낸 시간의 합이다.
응답 시간(response time)
대화식 시스템(interactive system)에서는 프로세스가 어떤 출력을 매우 일찍 생성하고, 앞의 결과가 사용자에게 출력되는 사이에 새로운 결과를 얻으려고 연산을 계속하는 경우가 종종 있다. 따라서 하나의 요구를 제출한 후 첫 번째 응답이 나올 때까지의 시간이 중요한 기준이 되는 경우가 있다.
응답 시간은 응답이 시작되는 데까지 걸리는 시간이지, 그 응답을 출력하는 데 걸리는 시간은 아니다.
CPU 이용률과 처리량을 최대화하고 총처리 시간, 대기 시간, 응답 시간을 최소화하는 것이 바람직하다.
Scheduling Algorithms
CPU 스케줄링은 준비(ready) 큐에 있는 어느 프로세스에 CPU 코어를 할당할 것인지를 결정하는 문제를 다룬다. 한 번에 하나의 프로세스만 실행할 수 있는, 한 개의 처리 코어를 가진 CPU가 한 개인 시스템이라고 가정하고, CPU 스케줄링 알고리즘을 살펴보자.
First-Come, First Served (FCFS) Scheduling
-
FCFS
- 가장 간단한 CPU 스케줄링 알고리즘은 선입 선처리(First-Come, FIrst Served, FCFS) 스케줄링 알고리즘이다.
- 이 방법에서는 CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받는다.
- FCFS 정책의 구현은 선입선출(FIFO) 큐로 쉽게 관리할 수 있다.
-
Preemptive or
NonpreemptiveFCFS 스케줄링 알고리즘은 비선점형(nonpreemptive)이다.
일단 CPU가 한 프로세스에 할당되면, 그 프로세스가 종료하든지 I/O 처리를 요구하여 CPU를 방출할 때까지 CPU를 점유한다.
-
Cons
-
FCFS 정책 하에서 평균 대기 시간은 일반적으로 최소가 아니며, 프로세스 CPU burst 시간이 크게 변할 경우에는 평균 대기 시간도 상당히 변할 수 있다.
-
추가로, 동적 상황에서 FCFS 스케줄링의 성능을 고려해 보자. 하나의 CPU 중심(CPU-bound) 프로세스와 많은 수의 I/O 중심(I/O-bound) 프로세스를 갖는다면 어떨까?
모든 다른 프로세들이 하나의 긴 프로세스가 CPU를 양도하기를 기다리는 호위 효과(convoy effect)가 발생하여, 짧은 프로세스들이 먼저 처리되도록 허용될 때보다 CPU와 장치 이용률이 저하되는 결과를 낳을 수 있다.
-
Shortest-Job-First (SJF) Scheduling
-
SJF
- 최단 작업 우선(shortest-job-first, SJF): shortest-next-CPU-burst
- SJF 알고리즘은 각 프로세스에 다음 CPU burst 길이를 연관시킨다.
- CPU가 이용 가능해지면, 가장 작은 다음 CPU burst를 가진 프로세스에 할당한다.
- 두 프로세스가 동일한 길이의 다음 CPU burst를 가지면, FCFS 스케줄링을 적용하여 순위를 정한다.
-
PreemptiveorNonpreemptiveSJF 알고리즘은 선점형일 수도 있고 비선점형일 수도 있다.
앞의 프로세스가 실행되는 동안, 현재 실행되고 있는 프로세스의 남은 시간보다도 더 짧은 CPU burst를 가진 새로운 프로세스가 준비 큐에 도착했다고 가정하자.- 선점형 SJF 알고리즘은 현재 실행하고 있는 프로세스를 선점할 것이다. Cf. Shortest Remaining Time First (SRTF) Scheduling
- 비선점형 SJF 알고리즘은 현재 실행하고 있는 프로세스가 자신의 CPU burst를 끝내도록 허용한다.
-
Pros
-
SJF 알고리즘은 주어진 프로세스 집합에 대해 최소의 평균 대기 시간을 가진다는 점에서 최적임을 증명할 수 있다.
짧은 프로세스를 긴 프로세스의 앞으로 이동함으로써, 짧은 프로세스의 대기 시간을 긴 프로세스의 대기 시간이 증가하는 것보다 더 많이 줄일 수 있으며 결과적으로 평균대기 시간이 줄어든다.
-
-
Cons
-
SJF 알고리즘이 최적이긴 하지만, 다음(next) CPU burst의 길이를 알 방법이 없기(no way to know) 때문에 CPU 스케줄링 수준에서는 구현할 수 없다.
-
SJF 스케줄링과 근사한 방법을 사용하여 다음 CPU burst를 예측(predict)할 수는 있다. 그러므로 다음 CPU burst 길이의 근삿값을 계산해, 가장 짧은 예상 CPU burst를 가진 프로세스를 선택한다.
일반적으로 이전의 CPU burst들의 길이를 지수 평균(exponential average)한 것으로 예측한다.
- 은 다음 CPU burst에 대한 예측값이다.
- 은 n번째 CPU burst의 길이로 최근의 정보를 가지며, 은 과거의 역사를 저장한다.
- 는 매개변수로 예측에서 최근의 값과 이전 값의 상대적인 무게를 제어한다. ≤ ≤
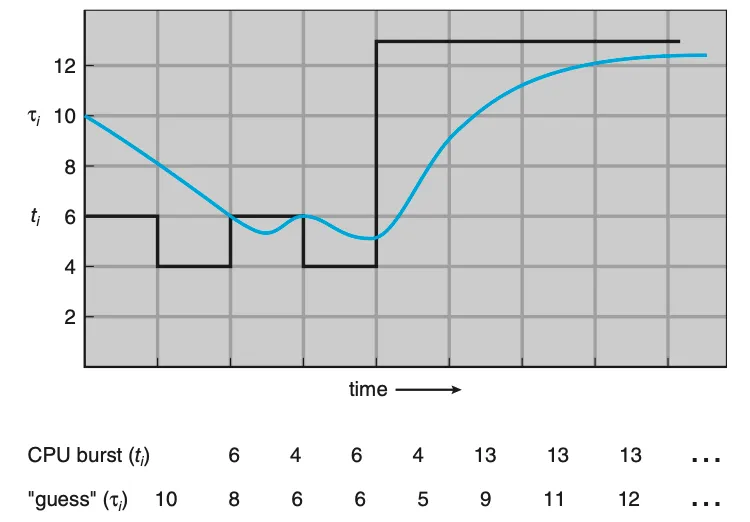
Figure 5.4 Prediction of the length of the next CPU burst.
-
Shortest Remaining Time First (SRTF) Scheduling
선점형 SJF 알고리즘은 때때로 최소 잔여 시간 우선(shortest remaining time first) 스케줄링이라고 불린다.
현재 실행하고 있는 프로세스의 남은 시간보다도 더 짧은 CPU burst를 가진 새로운 프로세스가 준비(ready) 큐에 도착하면, 현재 실행하고 있는 프로세스를 선점한다.
Round-Robin Scheduling (RR) Scheduling
-
RR
- 라운드 로빈(Round Robin, RR) 스케줄링 알고리즘은 FCFS 스케줄링과 유사하지만 시스템이 프로세스들 사이를 옮겨 다닐 수 있도록 선점이 추가된다.
- 시간 할당량(time quantum) 또는 time slice라고 하는 작은 단위를 시간을 정의한다. (일반적으로 10~100ms 동안)
- 준비(ready) 큐는 원형 큐(circular queue)로 동작하며, CPU 스케줄러는 준비 큐를 돌면서 한 번에 한 프로세스에 한 번의 시간 할당량 동안 CPU를 할당한다.
새로운 프로세스들은 준비 큐의 tail에 추가되며, CPU 스케줄러는 준비 큐에서 첫 번째 프로세스를 선택해 시간 할당량 이후에 인터럽트를 걸도록 timer를 설정한 후, 프로세스를 dispatch 한다. - 두 가지 경우 중 하나가 발생할 것이다.
- less than one time quantum
프로세스의 CPU burst가 한 번의 시간 할당량보다 작을 수 있다.
프로세스 자신이 CPU를 자발적으로 내보낼(release) 것이다. 스케줄러는 그 후 준비 큐에 있는 다음 프로세스로 진행할 것이다. - longer than one time quantum
현재 실행 중인 프로세스의 CPU burst가 한 번의 시간 할당량보다 길 수 있다.
타이머가 끝나고 운영체제에 인터럽트를 발생할 것이다. 문맥 교환(context switch)이 일어나고 실행하던 프로세스는 준비 큐의 tail에 들어간다. 그 후 CPU 스케줄러는 준비 큐의 다음 프로세스를 선택할 것이다.
- less than one time quantum
-
Preemptiveor Nonpreemptive프로세스의 CPU burst가 한 번의 시간 할당량을 초과하면, 프로세스는 선점되고 준비 큐로 되돌아간다. 따라서 RR 스케줄링 알고리즘은 선점형이다.
-
Cons
- 종종 RR 정책하에서 평균 대기 시간은 길다.
-
Performance
RR 알고리즘의 성능은 시간 할당량(time quantum)의 크기(size)에 매우 많은 영향을 받는다.
- 시간 할당량이 매우 크면 RR 정책은 FCFS 정책과 같다.
- 시간 할당량이 매우 작다면 RR 정책은 매우 많은 문맥 교환(context switch)을 야기한다.
그러므로 시간 할당량이 문맥 교환 시간과 비교해 더 큰 것이 바람직하다.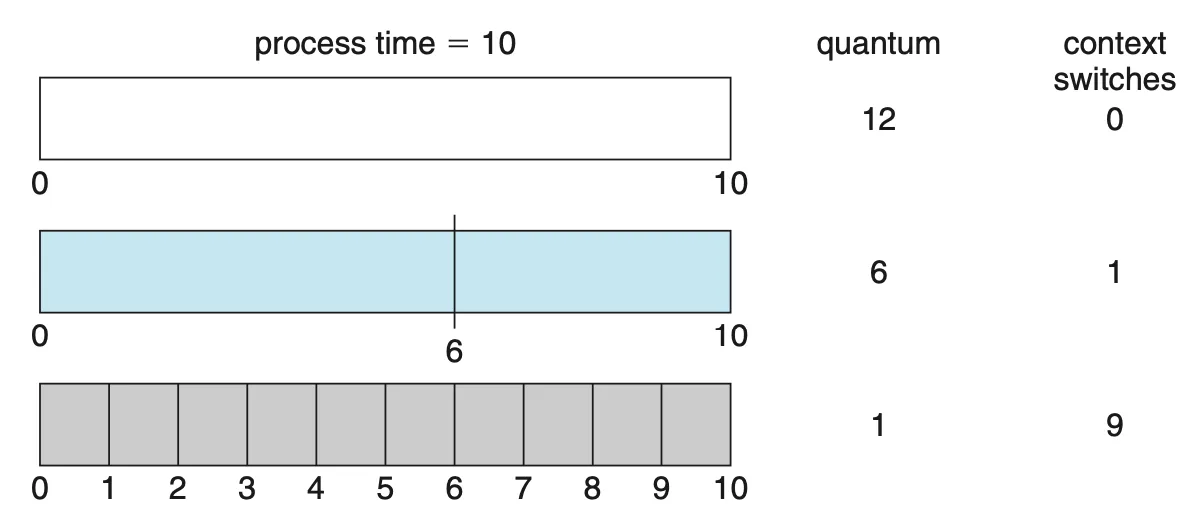
Figure 5.5 How a smaller time quantum increases context switches.
-
Turnaround time
총처리 시간 또한 시간 할당량의 크기에 좌우되지만, 평균 총처리 시간과 시간 할댱량이 정비례하지는 않는다.
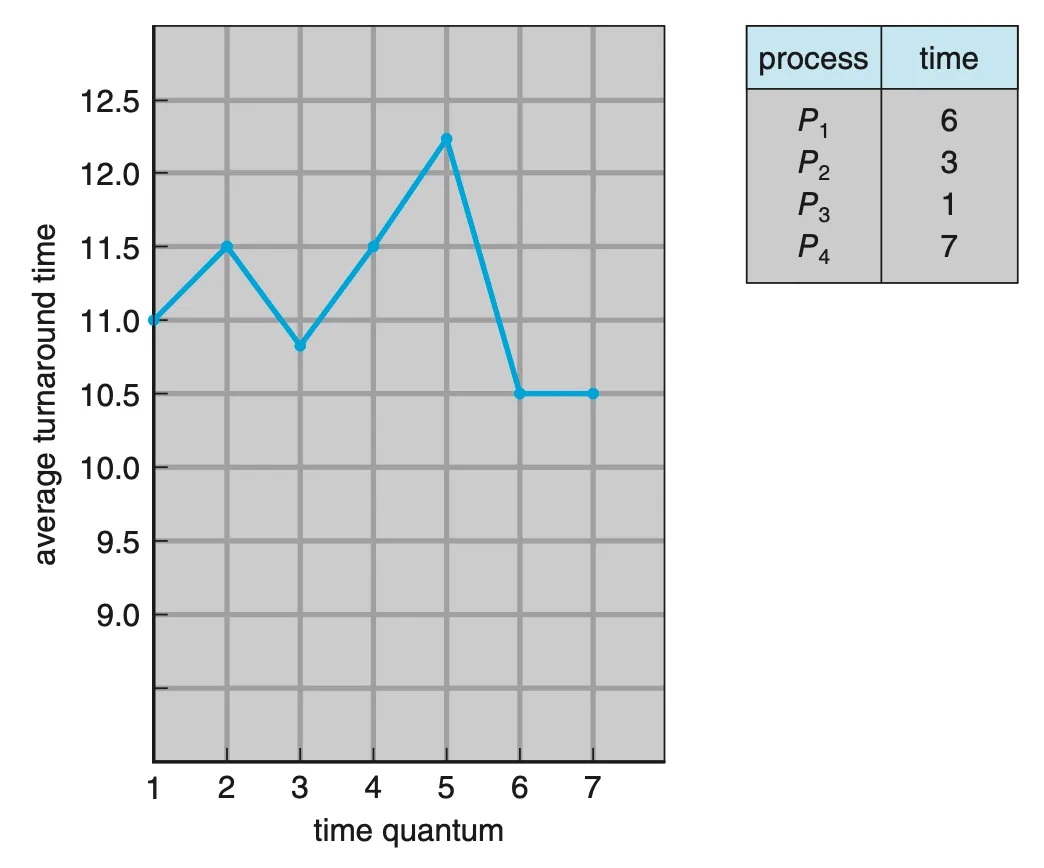
Figure 5.6 How turnaround time varies with the time quantum.
Priority Scheduling
-
Priority
- 우선순위(priority)가 각 프로세스들에 연관되어 있으며, CPU는 가장 높은 우선순위(highest priority)를 가진 프로세스에 할당된다.
Cf. 정하는 기준에 따라서 작은 수가 높은 우선순위를 나타낼 수도 있고, 큰 수가 높은 우선순위를 나타낼 수도 있다. - 우선순위가 같은(equal) 프로세스들은 FCFS 순서로 스케줄된다.
- SJF 알고리즘은 일반적인 우선순위 스케줄링 알고리즘의 특별한 경우이다.
- 이 경우의 우선순위는 next CPU burst의 역(inverse)이다.
- 우선순위(priority)가 각 프로세스들에 연관되어 있으며, CPU는 가장 높은 우선순위(highest priority)를 가진 프로세스에 할당된다.
-
PreemptiveorNonpreemptive우선순위 스케줄링은 선점형일 수도 있고 비선점형일 수도 있다.
프로세스가 준비 큐에 도착하면, 새로 도착한 프로세스의 우선순위를 현재 실행 중인 프로세스의 우선순위와 비교한다.- 선점형 우선순위 스케줄링 알고리즘은 새로 도착한 프로세스의 우선순위가 현재 실행되는 프로세스의 우선순위보다 높다면 CPU를 선점한다.
- 비선점형 우선순위 스케줄링 알고리즘은 단순히 준비 큐의 head에 새로운 프로세스를 추가한다.
-
Cons
-
우선순위 스케줄링 알고리즘의 주요 문제는 무한 봉쇄(indefinite blocking) 또는 기아 상태(starvation)이다.
우선순위 스케줄링 알고리즘을 사용할 경우, 낮은 우선순위 프로세스들이 실행 준비 되어있더라도 CPU를 무한히 대기하는 경우가 발생한다.Solution
- Aging
무한 blocking 문제에 대한 한 가지 해결 방안은 노화(aging)다. Aging은 오랫동안 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 증가시킨다. - RR + Priority Scheduling
다른 옵션은 라운드 로빈과 우선순위 스케줄링을 결합하는 방법이다. 시스템이 우선순위가 가장 높은 프로세스를 실행하고 우선순위가 같은 프로세스들은 라운드 로빈 스케줄링을 사용하여 스케줄 하는 방식이다.
- Aging
-
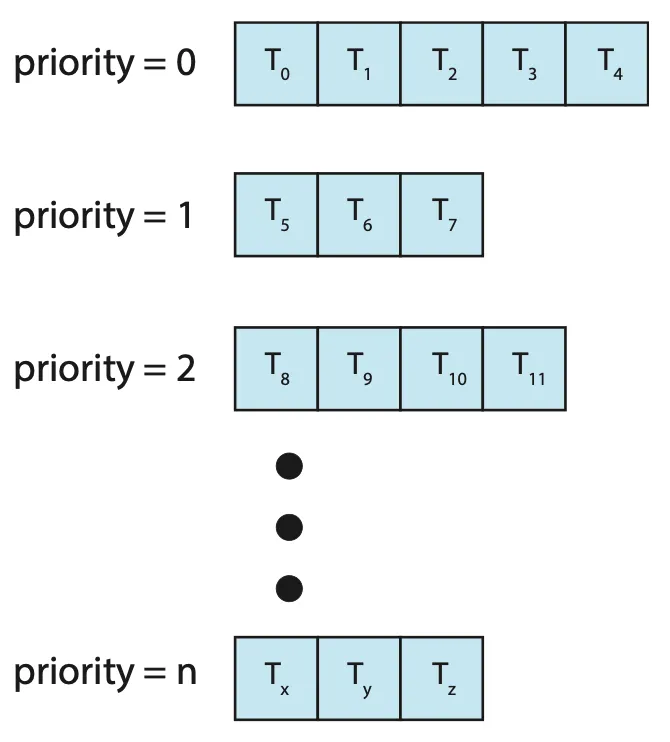
Multilevel Queue Scheduling
 | 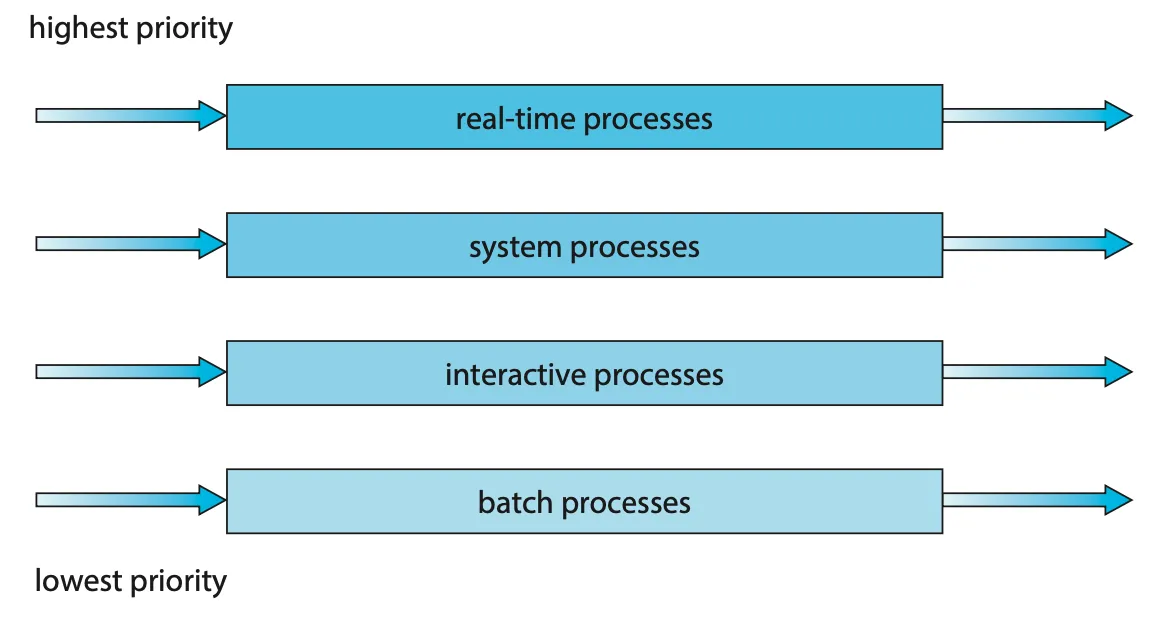 |
|---|---|
| Figure 5.7 Separate queues for each priority. | Figure 5.8 Multilevel queue scheduling. |
- MLQ
- 다단계 큐(multilevel queue) 스케줄링은 우선순위마다 별도의 큐를 갖고, 우선순위가 가장 높은 큐에서 프로세스를 스케줄하는 방식이다.
Cf. 모든 프로세스가 단일 큐에 배치된다면, 우선순위가 가장 높은 프로세스를 선택하기 위해 의 검색이 필요할 수 있다. - 이 방법은 우선순위 스케줄링이 라운드 로빈과 결합한 경우에도 효과적이다.
우선순위가 가장 높은 큐에 여러 프로세스가 있는 경우 라운드 로빈 순서로 실행된다. 보통 우선순위가 각 프로세스에 정적(영구적)으로 할당되며 프로세스는 실행시간(runtime) 동안 동일한 큐에 남아 있다. - 프로세스 유형에 따라 프로세스를 여러 개의 개별 큐로 분할하기 위해 다단계 큐 스케줄링 알고리즘을 사용할 수도 있다. (e.g. foreground(interactive) 프로세스와 background(batch) 프로세스 구분)
- 각 큐에는 자체 스케줄링 알고리즘이 있을 수 있다. (e.g. background 큐는 FCFS, foreground 큐는 RR)
- 큐와 큐 사이에 스케줄링도 반드시 있어야 한다.
- 일반적으로 고정 우선순위의 선점형 스케줄링으로 구현된다.
- 다른 가능성은 큐들 사이에 시간을 나누어 사용하는 것이다. (e.g. foreground 큐에는 CPU 시간의 80%, background 큐에는 20% 할당)
- 다단계 큐(multilevel queue) 스케줄링은 우선순위마다 별도의 큐를 갖고, 우선순위가 가장 높은 큐에서 프로세스를 스케줄하는 방식이다.
Multilevel Feedback Queue Scheduling
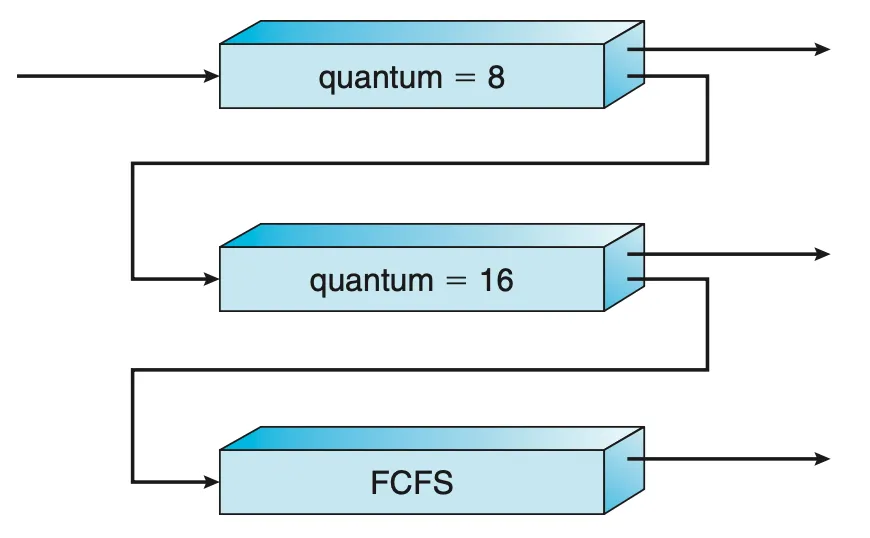 |
|---|
| Figure 5.9 Multilevel feedback queues. |
-
MLFQ
- 다단계 피드백 큐(multilevel feedback queue) 스케줄링 알고리즘에서는 프로세스가 큐들 사이를 이동하는 것을 허용한다.
- 프로세스들을 CPU burst 특징에 따라서 구분하여, CPU 시간을 너무 많이 사용하는 프로세스는 낮은 우선순위의 큐로 이동된다.
- 이 방법에서는 I/O 중심의 프로세스와 대화형 프로세스들을 높은 우선순위의 큐에 넣는다. (보통 짧은 CPU burst가 특징인 프로세스들)
- 낮은 우선순위의 큐에서 너무 오래 대기하는 프로세스는 높은 우선순위의 큐로 이동할 수 있다. aging을 통해 기아(starvation) 상태를 예방한다.
- MLFQ 스케줄러의 정의에 의하면, 이 스케줄링 알고리즘이 가장 일반적인 CPU 스케줄링 알고리즘으로, 설계 중인 특정 시스템에 부합하도록 구성 가능하다.
-
Cons
- 가장 좋은 스케줄러로 동작하기 위해서는 모든 매개변수들의 값을 선정하는 특정 방법이 필요하기 때문에 가장 복잡한 알고리즘이다.
Multi-Processor Scheduling
여러 개의 CPU를 사용할 수 있다면, 여러 스레드가 병렬로 실행될 수 있으므로 부하 공유(load sharing)가 가능해진다. 그러나 스케줄링 문제는 그만큼 더 복잡해진다.
멀티프로세서는 다음 시스템 아키텍처들에 사용할 수 있다.
- 프로세서가 기능 면에서 동일한(homogeneous) 시스템 이 경우, 사용 가능한 CPU를 사용하여 큐에 있는 임의의 프로세스를 실행할 수 있다.
- Multicore CPUs
- Multithreaded cores
- NUMA 시스템
- 프로세스의 기능이 동일하지 않은 시스템
- 이기종(heterogeneous) 멀티프로세싱
Approaches to Multiple-Processor Scheduling
비대칭 멀티프로세싱(asymmetric multiprocessing)
멀티프로세서 시스템의 CPU 스케줄링에 관한 해결 방법으로, master server라는 단일 프로세서가 모든 스케줄링 결정, I/O 처리, 다른 시스템 활동을 처리하는 것이다. 다른 프로세서들은 사용자 코드만 수행한다.
- 오직 하나의 코어만 시스템 자료구조에 접근하여 자료 공유의 필요성을 배제하기 때문에 간단하다.
- 하지만 마스터 서버가 전체 시스템 성능을 저하할 수 있는 병목이 된다는 단점이 있다.
대칭 멀티프로세싱(symmetric multiprocessing, SMP)
멀티프로세서를 지원하기 위한 표준 접근 방식으로, 각 프로세서는 스스로 스케줄링할 수 있다. 각 프로세서의 스케줄러가 준비(ready) 큐를 검사하고 실행할 스레드를 선택하여 스케줄링이 진행된다.
스케줄 대상이 되는 스레드를 관리하기 위한 두 가지 전략이 있다.
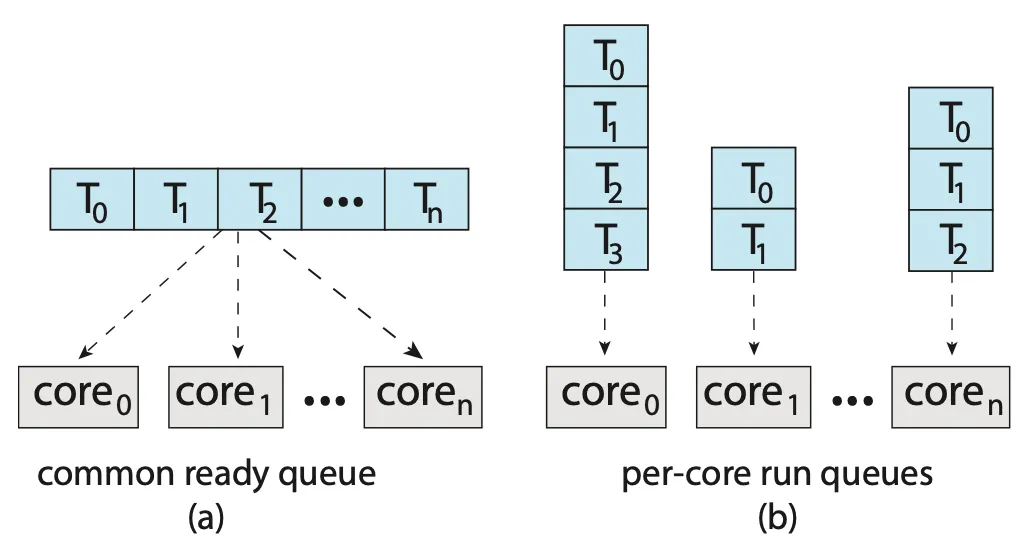 |
|---|
| Figure 5.11 Organization of ready queues. |
-
모든 스레드가 공통 준비(common ready) 큐에 있을 수 있다.
공유 준비 큐에 경쟁 조건(race condition)이 생길 수 있으므로 두 개의 다른 프로세서가 동일한 스레드를 스케줄 하지 않도록, 큐에서 스레드가 없어지지 않도록 보장해야 한다.
이 경쟁 조건으로부터 공통 준비 큐를 보호하기 위해 locking 기법 중 하나를 사용할 수 있으나, 큐에 대한 모든 액세스에 lock 소유권이 필요하므로 locking은 매우 경쟁이 심할 것이고 공유 큐 액세스가 성능의 병목이 될 수 있다.
-
각 프로세서는 자신만의 스레드 큐를 가질 수 있다.
각 프로세서가 자신만의 실행 큐에서 스레드를 스케줄 할 수 있도록 허용하므로 공유 실행 큐와 관련되어 발생할 수 있는 성능 문제를 겪지 않는다. 따라서 SMP를 지원하는 시스템에서 가장 일반적인 접근 방식이다. 또한 자신만의 프로세스별 큐가 있으면 캐시 메모리를 보다 효율적으로 사용할 수 있다. 프로세스별 실행 큐마다 부하의 양이 다를 수 있으나, 균형 알고리즘을 사용하여 모든 프로세스 간에 부하를 균등하게 만들 수 있다. Cf. Load Balancing
Cf. Windows, Linux 및 macOS와 Android, iOS의 모바일 시스템을 포함한 거의 모든 최신 운영체제는 SMP를 지원한다.
Multicore Processors
SMP 시스템은 다수의 물리 프로세서를 제공함으로써 다수의 프로세스가 병렬로 실행되게 한다.
Multicore Processor
현대 컴퓨터 하드웨어는 동일한 물리적인 칩 안에 여러 개의 처리 코어를 장착하여 multicore 프로세서가 된다. 각 코어는 구조적인 상태를 유지하고 있어서 운영체제 입장에서는 개별적인 논리적 CPU처럼 보인다.
multicore 프로세서를 사용하는 SMP 시스템은 각 CPU가 자신의 물리 칩을 가지는 시스템과 비교해 비교적 속도가 빠르고 적은 전력을 소모한다.
그러나 스케줄링 문제를 복잡하게 하는 단점이 있다.
💡 메모리 스톨 (Memory Stall)
프로세서가 메모리에 접근할 때 데이터가 가용해지기를 기다리면서 많은 시간을 허비하는 상황이다. 최신 프로세서가 메모리보다 훨씬 빠른 속도로 작동하기 때문에 주로 발생한다. 그러나 cache miss(캐시 메모리에 없는 데이터를 액세스)로 인해 메모리 스톨이 발생할 수도 있다.
Multithreaded Core
메모리 스톨을 해결하기 위해 최근의 많은 하드웨어 설계는 멀티스레드 처리 코어를 구현하였다. 이러한 설계에서 하나의 코어에 2개 이상의 하드웨어 스레드(hardware threads)가 할당된다. 이렇게 하면 메모리를 기다리는 동안 하나의 하드웨어 스레드가 중단되면 코어가 다른 스레드로 전환되며, 각 스레드의 실행이 인터리브된다.
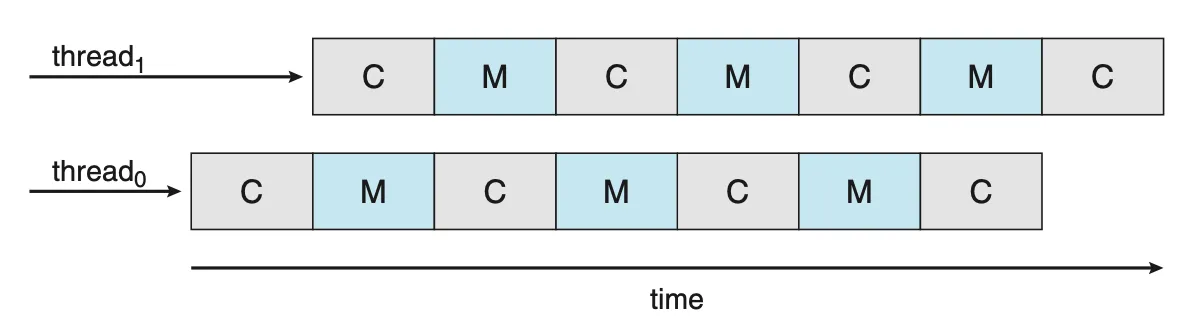 |
|---|
| Figure 5.13 Multithreaded multicore system. |
운영체제 관점에서 각 하드웨어 스레드는 명령어 포인트 및 레지스터 집합과 같은 구조적 상태를 유지하므로 소프트웨어 스레드를 실행할 수 있는 논리적 CPU로 보인다. 이 기술은 chip multithreading(CMT)이라고 알려져있다.
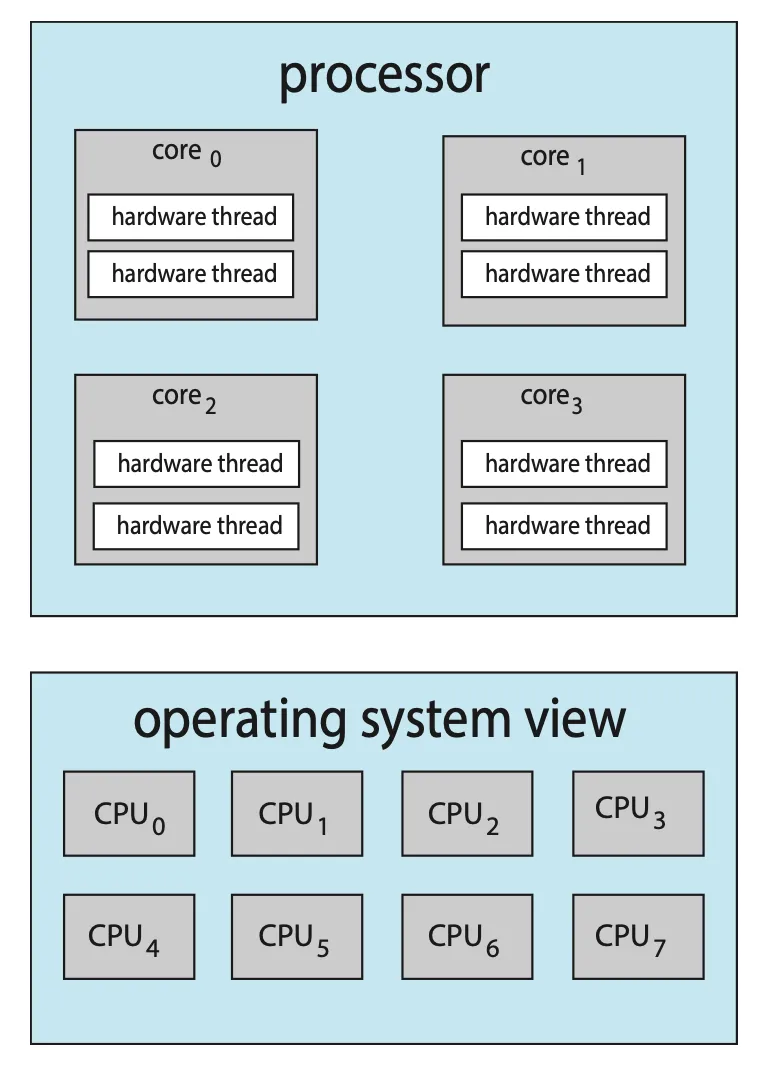 |
|---|
| Figure 5.14 Chip multithreading. |
Load Balancing
SMP 시스템에서 프로세서가 하나 이상이라는 것을 최대한 활용하려면, 부하(workload)를 모든 프로세서에 균등하게 배분하는 것이 매우 중요하다. Load balancing은 SMP 시스템의 모든 처리기 사이에 부하가 고르게 배분되도록 시도한다. 로드 밸런싱은 통상 각 처리기가 실행할 스레드를 위한 자신만의 준비 큐를 가지고 있는 시스템에서만 필요한 기능이라는 것을 주의해야 한다. 공통의 실행 큐만 있는 시스템에서는 한 프로세서가 쉬게 되면 곧바로 공통 큐에서 새로운 프로세스를 선택하여 실행하기 때문에 로드 밸런싱은 필요하지 않다. Cf. 대칭 멀티프로세싱(symmetric multiprocessing, SMP)
로드 밸런싱을 위해서는 push migration과 pull migration 방식의 두 가지 일반적인 접근법이 있다.
- Push migration 특정 태스크가 주기적으로 각 프로세서의 부하를 감시하고 만일 불균형 상태로 밝혀지면 과부하인 프로세서에서, 쉬고(idle) 있거나 덜 바쁜 프로세서로 스레드를 이동(또는 push)시킴으로써 부하를 분배한다.
- Pull migration 쉬고(idle) 있는 프로세서가, 바쁜 프로세서를 기다리고 있는 프로세스를 pull할 때 일어난다.
Push migration과 pull migration은 상호 배타적일 필요는 없으며 실제로 로드 밸런싱 시스템에서 종종 병렬적으로 구현된다.
“균등 부하(balanced load)”라는 개념은 다른 의미를 가질 수도 있다.
- 모든 큐에 비슷한 수의 스레드가 있어야 한다.
- 모든 큐에 스레드 우선순위를 균등하게 분배해야 한다.
- …
Real-Time CPU Scheduling
실시간 운영체제에서 CPU를 스케줄링 할 때는 일반적으로 soft 실시간 시스템과와 hard 실시간 시스템으로 구분한다.
-
Soft real-time system
soft 실시간 시스템은 중요한 실시간 프로세스가 스케줄 되는 시점에 관해 아무런 보장을 하지 않는다. 오직 중요 프로세스가 그렇지 않은 프로세스들에 비해 우선권을 가진다는 것만 보장한다.
-
Hard real-time system
hard 실시간 시스템은 더 엄격한 요구 조건을 만족시켜야 한다. 태스크는 반드시 마감시간(deadline)까지 받은 서비스에만 해당된다.
지연시간 최소화 (Minimizing Latency)
이벤트 지연시간 (Event latency)
시스템은 일반적으로 실시간으로 발생하는 이벤트를 기다린다. 이벤트가 발생하면, 시스템은 가능한 빨리 그에 응답을 하고 그에 맞는 동작을 수행해야 한다. 이벤트 지연시간은 이벤트가 발생해서 그에 맞는 서비스가 수행될 때까지의 시간을 말한다.
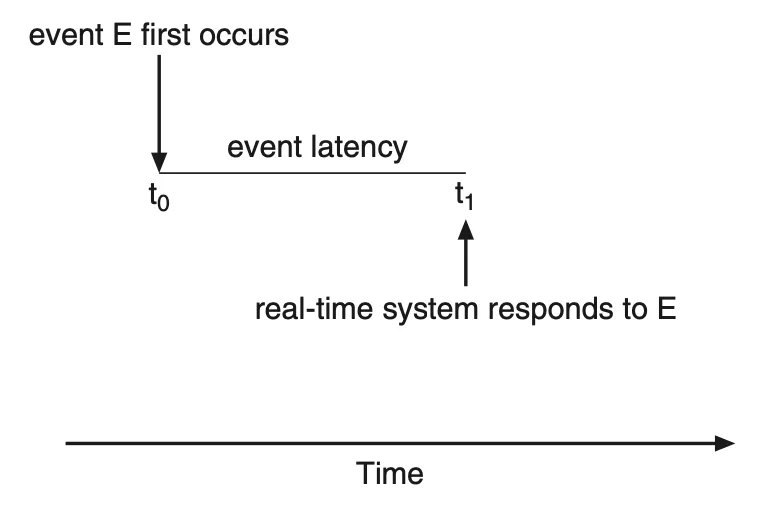 |
|---|
| Figure 5.17 Event latency. |
인터럽트 지연시간과 디스패치 지연시간이 실시간 시스템의 성능을 좌우한다.
인터럽트 지연시간 (Interrupt latency)
인터럽트 지연시간은 CPU에 인터럽트가 발생한 시점부터 해당 인터럽트 처리 루틴이 시작하기까지의 시간을 말한다. 인터럽트가 발생하면 운영체제는 수행 중인 명령어를 완수하고 발생한 인터럽트의 종류를 결정한다. 해당 인터럽트 서비스 루틴(ISR)을 사용하여 인터럽트를 처리하기 전에, 문맥 교환을 위해 현재 수행 중인 프로세스의 상태를 저장해 놓아야 한다.
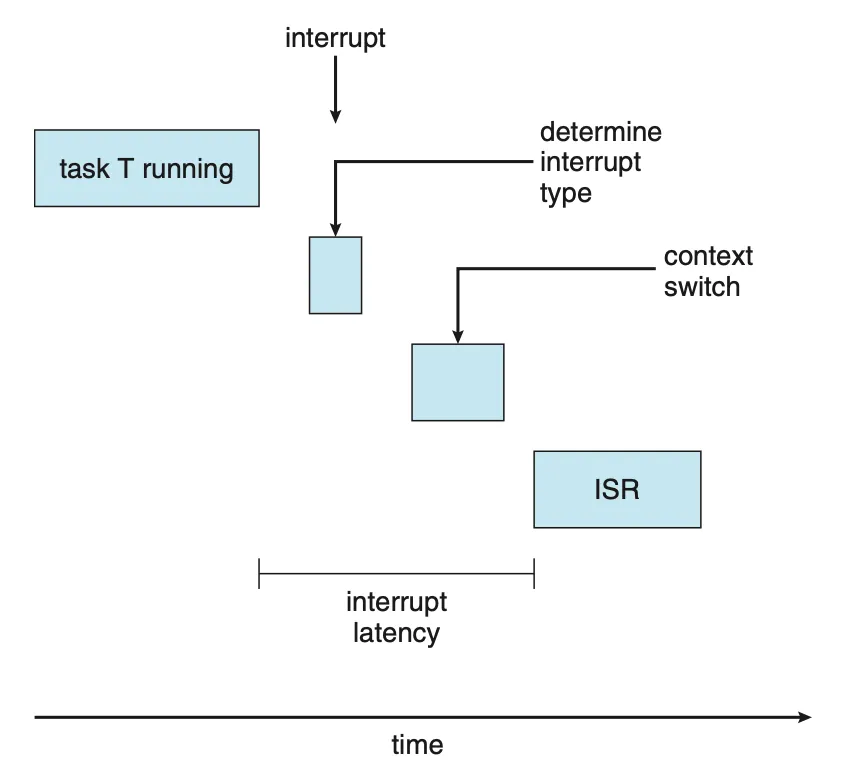 |
|---|
| Figure 5.18 Interrupt latency. |
실시간 태스크가 즉시 수행될 수 있도록 인터럽트 지연시간을 최소화하는 것은 실시간 운영체제에 매우 중요한 일이다. 인터럽트 지연시간에 영향을 주는 요인 중 하나는 커널 데이터 구조체를 갱신하는 동안 인터럽트가 사용 불가능해지는 시간이다. 실시간 운영체제는 인터럽트 불능 시간을 매우 짧게 해야 한다.
디스패치 지연시간 (Dispatch latency)
디스패치 지연시간은 스케줄링 디스패처가 하나의 프로세스를 멈추게 하고 다른 프로세스를 시작하는 데까지 걸리는 시간을 말한다. CPU를 즉시 사용해야 하는 실시간 태스크가 있다면, 실시간 운영체제는 이 지연 시간을 최소화해야 한다. 디스패치 지연시간을 최소화하는 가장 효과적인 방법은 선점형 커널이다.
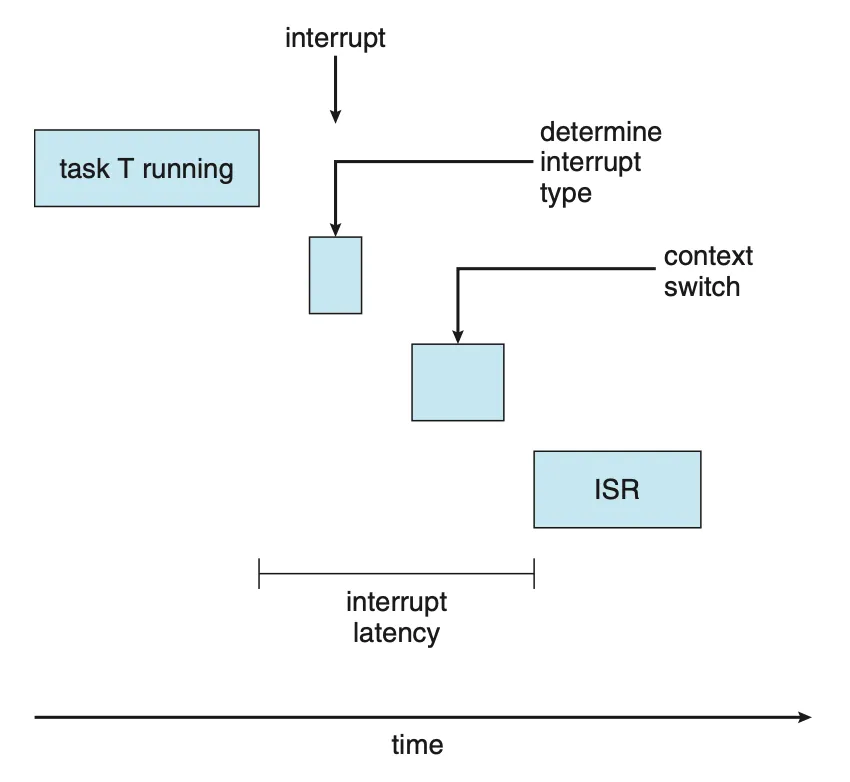 |
|---|
| Figure 5.19 Dispatch latency. |
디스패치 지연시간의 충돌 단계(conflict phase)는 다음의 두 가지 요소로 구성되어 있다.
- 커널에서 동작하는 프로세스에 대한 선점
- 낮은 우선순위 프로세스가 높은 우선순위의 프로세스가 필요한 자원 방출(release)
충돌 단계에 이어 디스패치 단계는 우선순위가 높은 프로세스를 사용 가능한 CPU에 스케줄 한다.
Priority-Based Scheduling
실시간 운영체제에서 가장 중요한 기능은 실시간 프로세스에 CPU가 필요할 때 바로 응답을 해주는 것이다.
따라서 실시간 운영체제의 스케줄러는 선점을 이용한 우선순위 기반의 알고리즘을 지원해야 한다. 우선순위 기반의 스케줄링 알고리즘은 각각의 프로세스의 중요성에 따라서 우선순위를 부여한다. 스케줄러가 선점 기법을 제공한다면, 현재 CPU를 이용하고 있는 프로세스가 더 높은 우선순위를 갖는 프로세스에 선점될 수도 있다.
그러나 선점 및 우선순위 기반의 스케줄러를 제공하는 것은 soft 실시간 기능을 제공하는 것에 불과하다. hard 실시간 시스템에서는 실시간 태스크가 마감시간 내에 확실히 수행되는 것을 보장해야만 하기 때문에 부가적인 스케줄링 기법이 필요하다.
프로세스들은 주기적(periodic)이므로, 프로세스들은 일정한 간격으로 CPU가 필요하다. 각각의 주기 프로세스들은 CPU 사용권을 얻었을 때마다 고정된 수행 시간 , CPU로부터 반드시 서비스를 받아야 하는 마감시간(deadline) 와 주기 가 정해져 있어서, 스케줄러는 마감시간과 주기적 프로세스의 실행 빈도에 따라서 우선순위를 정한다. 이런 형식의 스케줄링에서 일반적이지 않은 것은 프로세스가 자신의 마감시간을 스케줄러에게 알려야만 할 수도 있다는 것이다. 따라서 승인 제어(admission-control) 알고리즘을 이용해서 스케줄러는 마감시간 이내에 완수할 수 있는 프로세스는 실행을 허락하고 그렇지 못한 경우에는 요구를 거절한다.
Rate-Motonic Scheduling
Rate-monotonic 스케줄링 알고리즘은 선점 가능한 정적 우선순위 정책을 이용하여 주기 태스크들을 스케줄 한다. 각각의 주기 태스크들은 시스템에 진입하게 되면 주기에 따라서 우선순위가 고정된다. () 이 정책은 CPU를 더 자주 필요로 하는 태스크에 더 높은 우선순위를 주려는 원리에 기반을 둔다.
Rate-monotonic 스케줄링 기법이 스케줄 할 수 없는 프로세스 집합의 경우 정적 우선순위를 이용하는 다른 알고리즘들 역시 스케줄 할 수 없는 측면에서 최적(optimal)이기는 하지만, 많은 제약이 있다. CPU 이용률은 한계가 있기 때문에 CPU 자원을 최대화해서 사용하는 것을 불가능하다. 개의 프로세스를 스케줄 하는 데 있어 최악의 경우 CPU 이용률은 이다.
Earliest-Deadline-First Scheduling
Earliest-deadline-first (EDF) 스케줄링 기법은 마감시간(deadline)에 따라서 우선순위를 동적으로 부여한다. 마감시간이 빠를수록 우선순위는 높아지고, 늦을수록 낮아진다. EDF 정책에서는, 프로세스가 실행 가능하게 되면 자신의 마감시간을 시스템에 알려야 한다. 우선순위는 새로 실행 가능하게 된 프로세스의 마감시간에 맞춰서 다시 조정된다.
Rate-monotonic 알고리즘과는 달리 EDF 스케줄링 알고리즘은 프로세스들이 주기적일 필요도 없고, CPU 할당 시간도 상수 값으로 정해질 필요가 없다. 그러나 프로세스가 실행 가능해질 때 자신의 마감시간을 스케줄러에게 알려줘야 한다. EDF는 이론적으로, 모든 프로세스가 마감시간을 만족시키도록 스케줄 할 수 있고, CPU 이용률 역시 100%가 될 수 있으므로 최적이다. 그러나 실제로는 프로세스 사이, 또는 인터럽트 핸들링 때의 문맥 교환 비용 때문에 100%의 CPU 이용률은 불가능하다.
Proportionate Share Scheduling
일정 비율의 몫(proportional share) 스케줄러는 모든 애플리케이션들에게 개의 시간 몫을 할당하여 동작한다. 한 개의 애플리케이션이 개의 시간 몫을 할당받으면 그 응용은 모든 프로세스 시간 중 시간을 할당받게 된다.
일정 비율의 몫 스케줄러는 애플리케이션이 시간 몫을 할당받는 것을 보장하는 승인 제어(admission-control) 정책과 함께 동작해야만 한다. 승인 제어 정책은 사용 가능한 충분한 몫이 존재할 때, 그 범위 내의 몫을 요구하는 클라이언트들에게만 실행을 허락한다.
Operating-System Examples
Linux, Windows 및 Solaris 운영체제의 스케줄링 정책을 알아보자. 사실 Solaris와 Windows 시스템의 경우에는 kernel threads 스케줄링이고, Linux 스케줄러의 경우에는 tasks 스케줄링이지만, 일반적인 의미로 process 스케줄링이라는 용어를 사용한다.
Linux Scheduling
표준 Linux 커널은 두 스케줄링 클래스를 구현한다.
-
완전 공평 스케줄러(Completely Fair Scheduler, CFS)를 사용하는 디폴트 스케줄링 클래스
CFS 스케줄러는 각 태스크에 CPU 처리시간의 비율을 할당한다. 이 비율은 각 태스크에 할당된 nice 값에 기반을 두고 계산된다. Nice 값(-20 ≤ nice ≤ 19)이 작을 수록 우선순위는 높아지며, 우선순위가 높을수록 더 큰 비율의 CPU 처리시간을 할당받는다.
CFS는 이산 값인 시간 할당량(time slice) 대신에 목적 지연시간(targeted latency)을 찾는다. 목적 지연시간은 다른 모든 수행 가능한 태스크가 적어도 한 번씩은 실행할 수 있는 시간 간격을 나타낸다.
CFS는 직접 우선순위를 할당하지 않고, 각 태스크별로
vruntime이라는 변수에 태스크가 실행된 시간을 기록하여 가상 실행 시간(virtual run time)을 유지한다.CFS 스케줄러는 처리 코어 간의 부하를 균등하게 유지하면서도 NUMA를 인식하고 스레드 이동을 최소화하는 정교한 기술을 사용하여 로드 밸런싱을 지원한다. 스케줄링 도메인(scheduling domain)의 계층적 시스템을 결정하여 다른 NUMA 노드(프로세서 수준 도메인) 간 스레드 이동을 최소화하며 부하를 균등화한다.
-
실시간 스케줄링 클래스(scheduling classes)
Linux 스케줄러는 각 클래스별로 특정 우선순위를 부여받는 스케줄링 클래스에 기반을 두고 동작한다. 다음에 실행될 태스크를 결정하기 위해 스케줄러는 높은 우선순위 클래스에 속한 가장 높은 우선순위의 태스크를 선택한다.
Windows Scheduling
Windows는 우선순위에 기반을 둔 선점 스케줄링 알고리즘을 사용한다. Windows 스케줄러는 가장 높은 우선순위의 스레드가 항상 실행되도록 보장한다. Windows 커널 중 스케줄링을 담당하는 부분을 디스패처(dispatcher)라고 한다.
디스패처는 스레드의 실행 순서를 정하기 위하여 32단계의 우선순위를 두고 있으며, 두 클래스로 구분된다.
-
가변 클래스(variable class) — 우선순위 1부터 15까지의 스레드를 포함한다.
이 클래스에 속한 스레드의 우선순위는 변할 수 있다. 스레드의 시간 할당량이 만료되면, 그 스레드는 인터럽트되면서 우선순위가 낮아진다. 우선순위를 낮추게 되면 계산 중심(compute-bound) 스레드들이 CPU를 독점하는 것을 제한하게 된다. 가변 우선순위 스레드가 대기(wait) 연산에서 풀려나면 디스패처는 그 우선순위를 높여준다.
-
실시간 클래스(real-time class) — 우선순위 16부터 31까지의 스레드를 포함한다.
우선순위 0인 스레드는 메모리 관리를 위해 사용한다. 준비(ready) 상태에 있는 스레드가 없으면 디스패처는 idle 스레드라고 불리는 특수한 스레드를 실행시킨다.
Windows는 멀티 프로세서 시스템 스케줄링을 지원하여, 해당 스레드에 가장 적합한 처리 코어에 스레드가 스케줄 되도록 시도한다. 가장 적합한 처리 코어를 선정하기 위해 스레드의 선호도(preferred)와 최근에 실행된 프로세서를 유지하고 있어야 한다. Windows에서 사용하는 기법의 하나는 논리 프로세서 집합(SMT 집합)을 생성하는 것이다. 여러 논리 프로세서에 부하를 분배하기 위해 각 스레드에는 스레드가 선호하는 프로세서를 나타내는 숫자인 이상적인 프로세서(ideal processor)가 배정된다.
Solaris Scheduling
Solaris는 우선순위 기반 스레드 스케줄링을 사용한다. Solaris는 우선순위에 따라 6개의 스케줄링 클래스를 정의하며, 각 클래스에는 서로 다른 우선순위와 서로 다른 스케줄링 알고리즘이 존재한다.
- 시분할(time-sharing, TS)
- 대화형(interactive, IA)
- 실시간(real time, RT)
- 시스템(system, SYS)
- 공평 공유(fair share, FSS)
- 고정 우선순위(fixed priority, FP)
스케줄러는 가장 높은 우선순위를 가진 스레드를 실행하도록 선택하고, 선택된 스레드는 (1) block 되거나, (2) 시간 할당량(time slice)를 전부 사용하거나, (3) 높은 우선순위의 스레드에 의해 선점될 때까지 CPU 상에서 실행된다.
Algorithm Evaluation
특정 시스템을 위한 CPU 스케줄링 알고리즘은 선택하기 위해서는, 선택 기준을 정의하고 고려 중인 여러 가지 알고리즘들을 평가해야 한다.
알고리즘을 선택하는 데 사용할 기준은 종종 CPU 이용률, 응답 시간 또는 처리량에 의해 정의된다. (Cf. Scheduling Criteria) 알고리즘을 선택하기 위해, 먼저 이들 값의 상대적인 중요성을 반드시 정의해야 한다.
평가 방법으로는 결정론적 모델링(deterministic modeling), 큐잉 네트워크 분석(queueing-network analysis), 시뮬레이션 등이 있다.
Additional Resources
React Scheduler
React에서 동시성을 위해 사용하는 Scheduler도 CPU Scheduler와 유사한 개념으로 구현되어 있다. 자세한 내용은 React Internals Deep Dive - Scheduler를 참고하자.
References
- Operating System Concepts 10th
- PART TWO PROCESS MANAGEMENT
- Chapter 5 CPU Scheduling
- PART TWO PROCESS MANAGEMENT
- 운영체제 공룡책 전공강의 | 주니온 - 인프런
- 섹션 4. Chapter 5. CPU Scheduling
