
🦖 Operating System Concepts 10th
PART ONE OVERVIEW
Chapter 1 Introduction
💡 운영체제
- 컴퓨터 하드웨어를 관리(operate)하고 응용 프로그램 실행 환경을 제공하는 소프트웨어다.
- 컴퓨터 사용자와 컴퓨터 하드웨어 간의 매개체 역할을 한다.
- “컴퓨터에서 항상 실행되고 있는 하나의 프로그램”으로, 운영체제의 핵심은 커널(kernel)이다.
- 커널에는 시스템 프로그램과 응용 프로그램이 있다.
- 프로그램이란 명령(instruction)의 집합이다.
- 명령이란 컴퓨터의 하드웨어가 수행해야 할 작업을 알려주는 것이다.
Cf. instruction set architecture (ISA)
- 응용 프로그램에 system services를 제공한다. (자세한 내용은 Chapter 2에서 살펴보자)
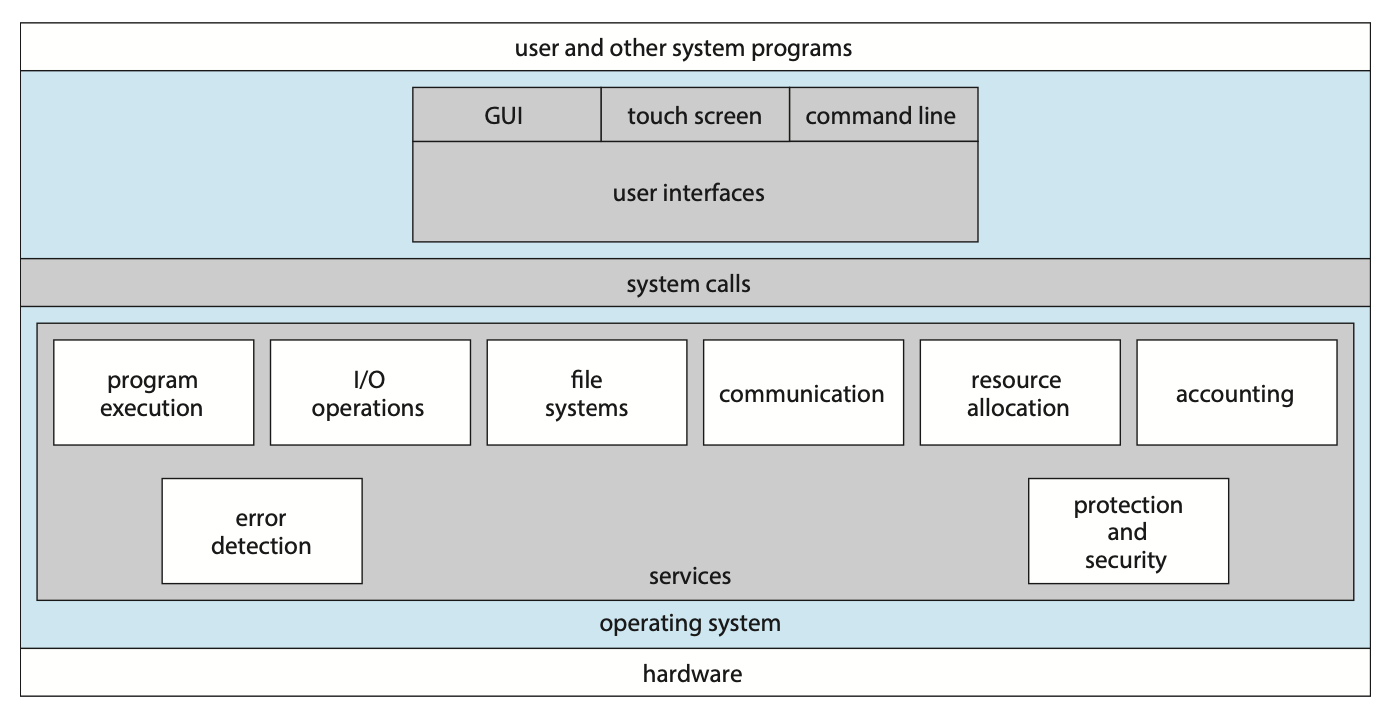
시스템 서비스란 운영체제가 프로그램 실행을 위해 제공한 환경을 통해, 프로그램과 해당 프로그램 사용자가 이용할 수 있는 서비스다.
Figure 2.1 A view of operating system services.
- 프로세스, 자원, 사용자 인터페이스 등을 관리한다.
컴퓨터 시스템
컴퓨터 시스템은 크게 네 개의 컴포넌트 —하드웨어, 운영체제, 응용 프로그램, 사용자— 로 나눌 수 있다.
- 하드웨어는 중앙 처리 장치(CPU), 메모리 및 입출력(I/O) 장치로 구성되어, 시스템을 위한 기본적인 컴퓨팅(계산용) 자원을 제공한다.
- 응용 프로그램인 워드 프로세서, 스프레드시트, 컴파일러, 웹 브라우저 등은 사용자의 컴퓨팅(계산) 문제를 해결하기 위해 이들 자원이 어떻게 사용될지를 정의한다.
- 운영체제는 하드웨어를 제어하고 다양한 사용자를 위해 다양한 응용프로그램 간의 하드웨어 사용을 조정한다.
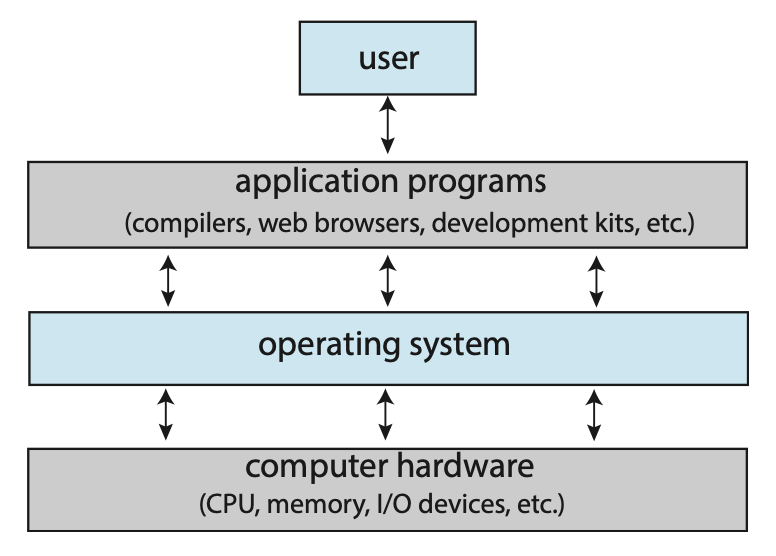
Figure 1.1 Abstract view of the components of a computer system.구성
다음은 폰 노이만 구조를 따르는 전통적인 컴퓨터 시스템으로, 신경망 컴퓨터나 네트워크 컴퓨터나 양자 컴퓨터를 새로운 형태의 현대 컴퓨터 시스템이라고 일컫는다.
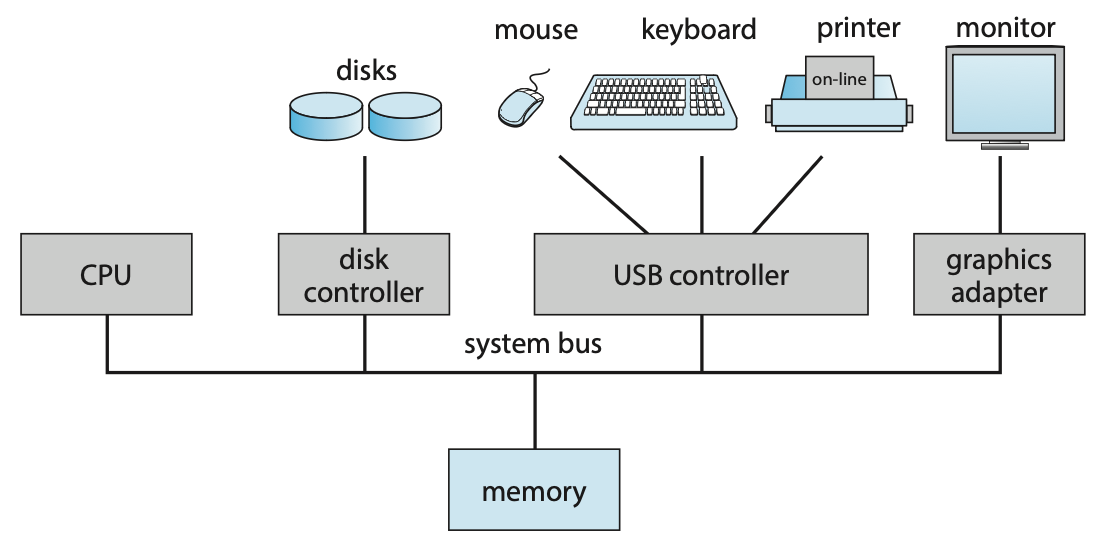
Figure 1.2 A typical PC computer system.인터럽트 (Interrupts)
💡 인터럽트
I/O 작업을 시작하기 위해 장치 드라이버는 장치 컨트롤러에 적절한 레지스터를 로드한다. 그러면 장치 컨트롤러는 장치에서 로컬 버퍼로 데이터 전송을 시작한다. 데이터 전송이 완료되면 장치 컨트롤러는 장치 드라이버에게 작업이 완료되었음을 알린다. 이는 인터럽트를 통해 수행된다.
하드웨어는 언제든지 인터럽트를 트리거할 수 있다. 인터럽트는 하드웨어가 운영체제와 상호 작용하는 주요 방법으로, 하드웨어 장치는 CPU에 신호를 보내 인터럽트를 트리거한다.
- 일반적으로 시스템 버스를 통해 CPU에 신호를 보낸다.
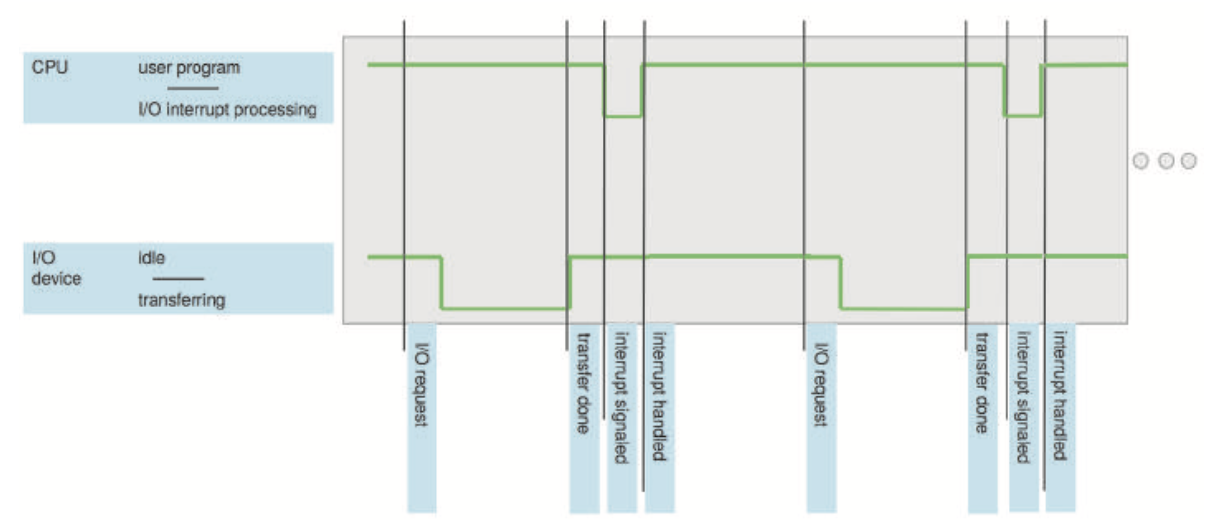
Figure 1.3 Interrupt timeline for a single program doing output.인터럽트는 인터럽트 핸들러로 관리된다.
저장장치 구조 (Storage Structure)
CPU는 메모리에서만 명령을 로드할 수 있으므로, 프로그램을 실행하려면 먼저 메모리에 로드해야 한다.
💡 폰 노이만 구조 (von Neumann architecture)
폰 노이만 구조는 명령 데이터와 프로그램 데이터가 동일한 메모리에 저장되는 stored-program 컴퓨터 개념을 기반으로 한다.
전형적인 instruction-execution 사이클이다.
출처: https://www.computerscience.gcse.guru/theory/von-neumann-architecture
- 처음에 메모리로부터 명령(instruction)을 fetch해온다.
- 그리고 해당 명령을 명령 레지스터(instruction register, IR)에 저장한다.
- 명령이 디코딩되고, 메모리로부터 피연산자를 불러와서 일부 내부 레지스터에 저장할 수도 있다.
- 피연산자에 대한 명령이 실행(execute)된 후 결과는 메모리에 다시 저장될 수 있다.
⇒ CPU는 instruction-execution 사이클 동안 메인 메모리로부터 명령어를 읽고, data-fetch 사이클 동안 메인 메모리에서 데이터를 읽고 쓴다.

스토리지 시스템은 스토리지 용량과 접근 시간에 따라 다음과 같은 계층 구조로 구성될 수 있다.
- 높은 레벨은 비용이 많이 들지만 빠르다. 계층 구조를 아래로 내려갈수록 비트당 비용은 일반적으로 감소하는 반면 액세스 시간은 일반적으로 증가한다.
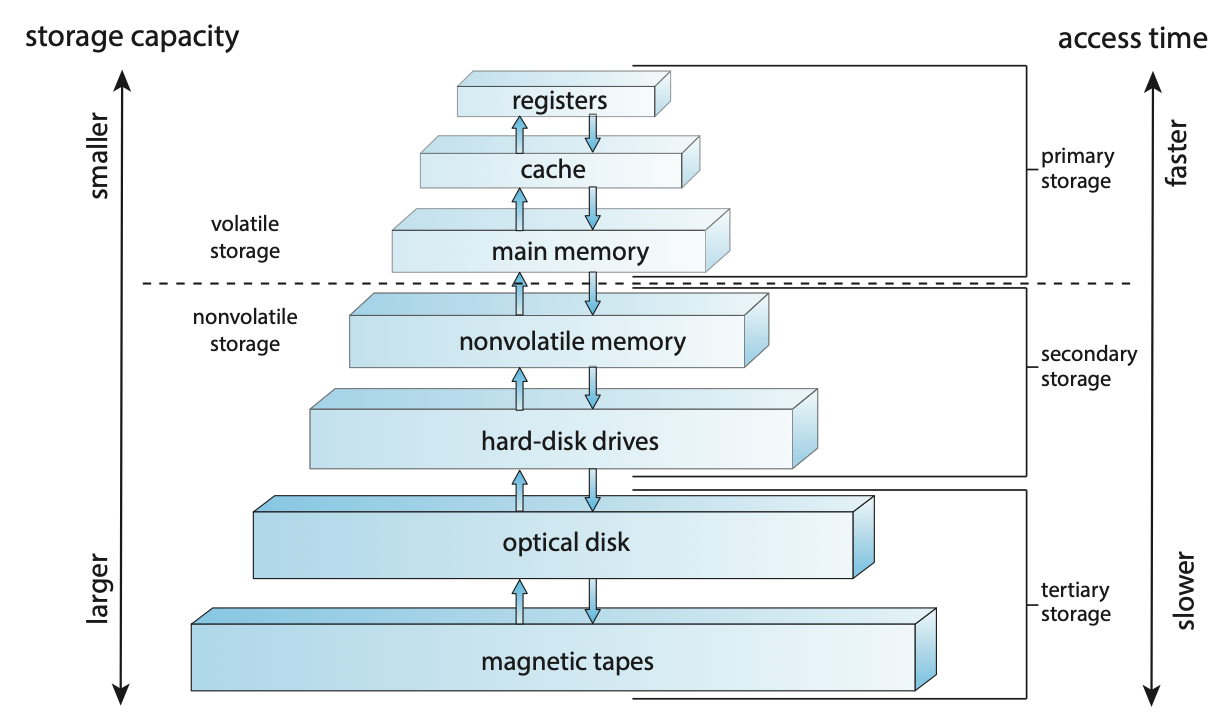
Figure 1.6 Storage-device hierarchy.주기억장치 (Main Memory)
범용 컴퓨터는 메인 메모리(Random Access Memory 또는 RAM이라고도 함)라고 하는 재기록 가능한(rewritable) 메모리에서 대부분의 프로그램을 실행한다. 메인 메모리는 일반적으로 DRAM(Dynamic Random-Access Memory)이라는 반도체 기술로 구현된다.
메인 메모리는 일반적으로 필요한 모든 프로그램과 데이터를 영구적으로 저장하기에는 너무 작고, 휘발성이므로 전원이 공급되지 않으면 내용을 잃어버린다.
보조기억장치 (Secondary Storage)
따라서 대부분의 컴퓨터 시스템은 메인 메모리의 확장으로 보조기억장치(secondary storage)를 제공한다. 보조기억장치의 주요 요구 사항은 대량의 데이터를 영구적으로 보관할 수 있어야 한다는 것이다.
가장 일반적인 보조기억장치는 프로그램과 데이터 모두에 저장 공간을 제공하는 하드 디스크 드라이브(hard-disk drives, HDDs)와 비휘발성 메모리(nonvolatile memory, NVM) 장치다. 대부분의 프로그램(시스템 및 애플리케이션)은 메모리에 로드될 때까지 보조기억장치에 저장된다. 보조기억장치는 메인 메모리보다 훨씬 느리다. 보조저장장치의 적절한 관리는 컴퓨터 시스템에서 매우 중요하다.
3차 저장장치 (Tertiary Storage)
다른 장치에 저장된 자료의 백업 복사본을 저장하는 등 특별한 목적으로만 사용할 수 있을 만큼 느리고 큰 저장소를 3차 저장장치(tertiary storage)라고 한다. 각 저장 시스템은 데이터를 저장하고 나중에 검색할 때까지 해당 데이터를 보관하는 기본 기능을 제공한다.
💡 Volatile vs Nonvolatile
- 휘발성 저장 장치 (Volatile Storage)
- 메인 메모리는 일반적으로 휘발성 저장 장치로, 전원이 꺼지거나 손실되면 내용을 잃어버린다.
- 비휘발성 저장 장치 (Nonvolatile Storage)
- 비휘발성 저장 장치는 메인 메모리의 확장으로, 많은 양의 데이터를 영구적으로 유지할 수 있다.
- 가장 일반적인 비휘발성 저장 장치는 하드 디스크로, 프로그램과 데이터를 모두 저장할 수 있다.
I/O 구조
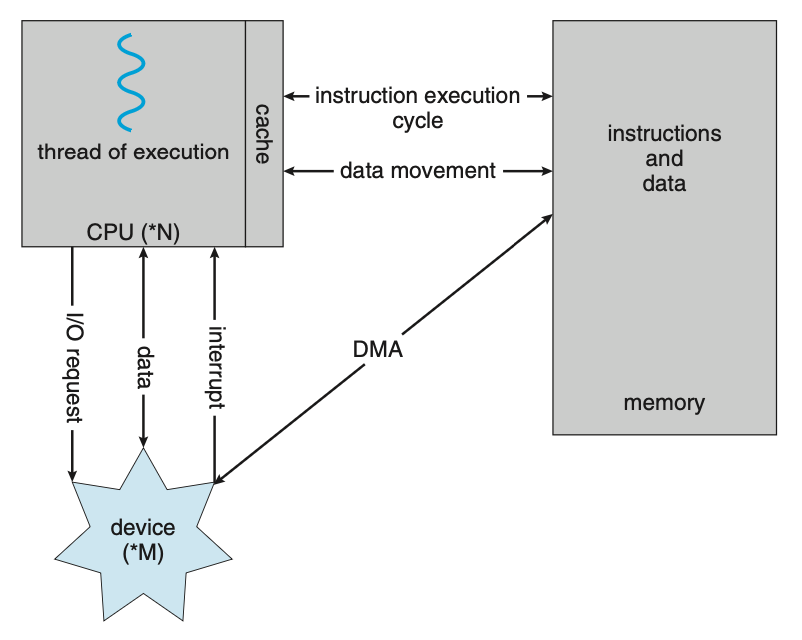
Figure 1.7 How a modern computer system works.인터럽트 중심 I/O는 소량의 데이터를 이동하는 데 적합하지만 NVS(nonvolatile storage) I/O와 같은 대량 데이터 이동에 사용될 때 높은 오버헤드를 생성할 수 있다. 이 문제를 해결하기 위해 DMA(Direct Memory Access)가 사용된다. I/O 장치에 대한 버퍼, 포인터 및 카운터를 설정한 후 장치 컨트롤러가 CPU의 개입 없이 전체 데이터 블록을 장치 및 메인 메모리에 직접 전송한다.
❗ Good to know
DMA는 비용이 큰 작업이므로, 사용을 지양하는 것이 좋다.
DMA는 캐시 일관성 문제를 야기할 수 있으며, DMA Controller는 시스템의 전반적인 비용과 소프트웨어의 복잡도를 증가시킨다.
컴퓨터 시스템 아키텍처
📖 DEFINITIONS OF COMPUTER SYSTEM COMPONENTS
- CPU — 명령을 실행하는 하드웨어
- Processor — 하나 이상의 CPU를 포함하는 물리적 칩
- Core — CPU의 기본 계산 단위
- Multicore — 동일한 CPU에 여러 컴퓨팅 코어 포함
- Multiprocessor — 다중 프로세서 포함
단일 프로세서 시스템 (Single-Processor Systems)
수년 전에는 대부분의 컴퓨터 시스템이 단일 처리 코어와 하나의 CPU를 포함하는 단일 프로세서를 사용했다. 코어(core)는 데이터를 로컬에 저장하기 위한 명령과 레지스터를 실행하는 구성 요소다. 코어가 있는 하나의 메인 CPU는 프로세스의 명령을 포함하여 범용 명령 세트를 실행할 수 있다. 디스크, 키보드, 그래픽 컨트롤러와 같은 장치별 프로세서의 형태로 제공될 수 있다.
멀티프로세서 시스템 (Multiprocessor Systems)
모바일 장치에서 서버에 이르기까지 최신 컴퓨터에서는 다중 프로세서 시스템(multiprocessor systems)이 이제 컴퓨팅 환경을 지배하고 있다. 전형적으로 이러한 시스템에는 각각 단일 코어 CPU가 있는 두 개 이상의 프로세서가 있다. 다중 프로세서 시스템의 주요 이점은 처리량 증가다. 즉, 프로세서 수를 늘리면 더 짧은 시간에 더 많은 작업을 수행할 수 있을 것으로 예상된다. 그러나, 여러 프로세서가 작업에 협력할 때 모든 부분이 올바르게 작동하도록 유지하는 데 발생하는 일정량의 오버헤드와 공유 리소스에 대한 경합으로 인해 추가 프로세서에서 예상되는 이득이 낮아진다.
Symmetric multiprocessing (SMP)
가장 일반적인 다중 프로세서 시스템은 각 peer CPU 프로세서가 운영체제 기능 및 사용자 프로세스를 포함한 모든 작업을 수행하는 대칭적 다중 처리(SMP, symmetric multiprocessing)를 사용한다.
Cf. Asymmetric multiprocessing — 각 프로세서가 특정 작업만을 수행한다.
일반적인 SMP 아키텍처는 각각 자체 CPU가 있는 두 개의 프로세서로 구성되어 있으며, 각 CPU 프로세서에는 자체 레지스터 세트와 개인 또는 로컬 캐시가 있다. 그러나 모든 프로세서는 시스템 버스를 통해 물리적 메모리를 공유한다.
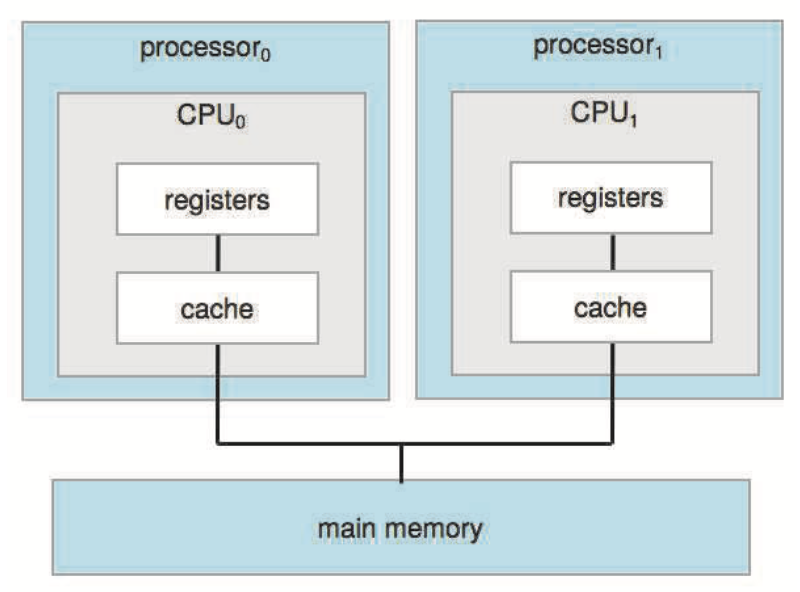
Figure 1.8 Symmetric multiprocessing architecture.이 모델의 이점은 성능을 크게 저하시키지 않고 많은 프로세스를 동시에 실행할 수 있다는 것이다. 즉, N CPU가 있는 경우 N 프로세스를 실행할 수 있다. 그러나 CPU가 분리되어 있기 때문에 하나는 유휴 상태이고 다른 하나는 과부하되어 비효율성이 발생할 수 있다. 프로세서가 특정 데이터 구조를 공유하면 프로세스와 리소스(e.g. 메모리)를 다양한 프로세서 간에 동적으로 공유할 수 있으며 프로세서 간의 작업 부하 차이를 낮출 수 있다.
Multi-core design
멀티프로세서의 정의는 시간이 지남에 따라 발전해 왔으며 이제는 여러 컴퓨팅 코어가 단일 칩에 상주하는 멀티코어 시스템을 포함한다. 온칩 통신이 칩 간 통신보다 빠르기 때문에 멀티코어 시스템은 단일 코어가 있는 다중 칩보다 더 효율적일 수 있다.
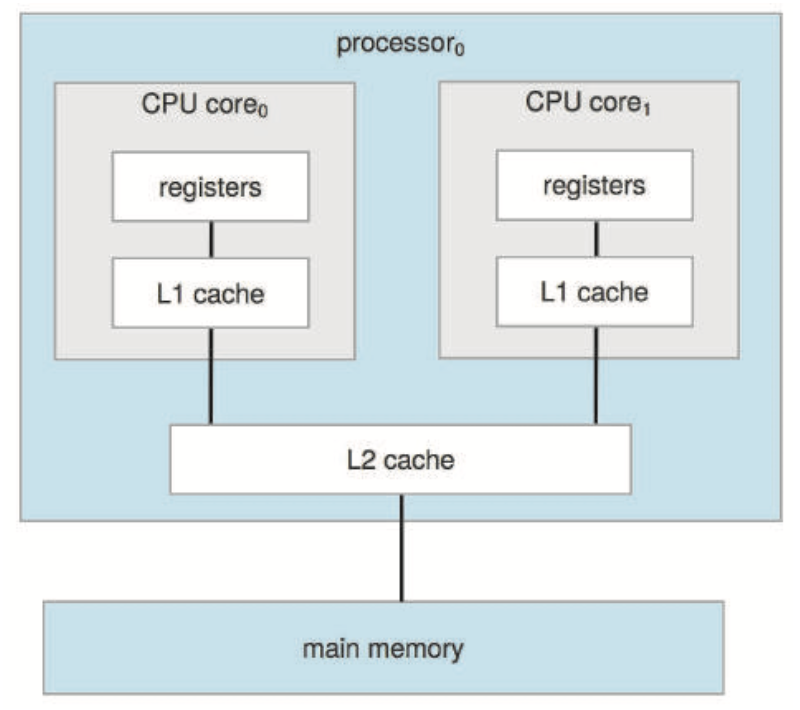
Figure 1.9 A dual-core design with two cores on the same chip.또한, 다중 코어를 가진 하나의 칩은 다중 단일 코어 칩에 비해 훨씬 적은 전력을 사용하는데, 이는 노트북은 물론 모바일 장치에 있어서 중요한 문제다. 듀얼 코어 설계는 동일한 프로세서 칩에 두 개의 코어가 있으며, 각 코어에는 자체 레지스터 세트는 물론 레벨 1 또는 L1 캐시라고도 하는 자체 로컬 캐시도 있다. 또한 레벨 2(L2) 캐시는 칩에 로컬이지만 두 개의 처리 코어에서 공유된다. 여기서 로컬, 하위 수준 캐시는 일반적으로 상위 수준 공유보다 작고 빠르다.
클러스터형 시스템 (Clustered Systems)
멀티프로세서 시스템의 또 다른 유형은 여러 CPU를 함께 모으는 클러스터 시스템이다. 클러스터 시스템은 둘 이상의 개별 시스템(또는 노드)이 함께 구성된다는 점에서 위에서 설명한 멀티프로세서 시스템과 다르다. 각 노드는 일반적으로 멀티코어 시스템이며 느슨하게 결합되어 있다. 일반적인 클러스터형 시스템의 정의는 클러스터된 컴퓨터가 스토리지를 공유하고 LAN과 같은 더 빠른 상호 연결을 통해 밀접하게 연결되어 있다는 것이다.
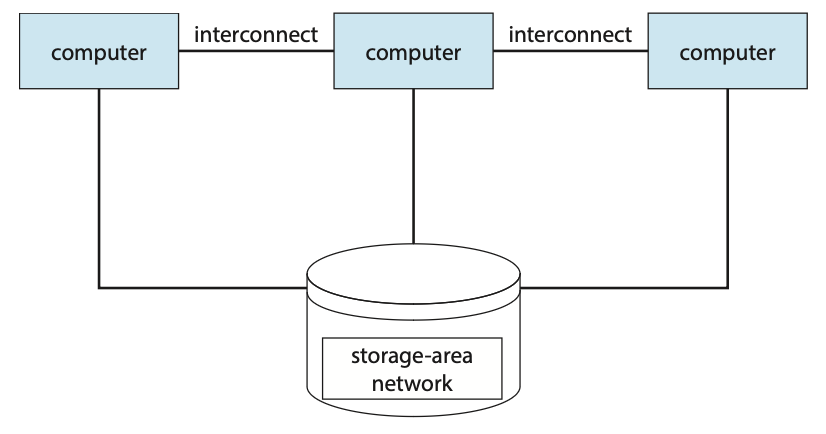
Figure 1.11 General structure of a clustered system.클러스터링은 일반적으로 고가용성 서비스, 즉 클러스터에 있는 하나 이상의 시스템에 장애가 발생하더라도 계속되는 서비스를 제공하는 데 사용된다. 일반적으로 시스템에 중복성 수준을 추가하여 고가용성을 얻는다. 각 노드는 (네트워크를 통해) 다른 노드 중 하나 이상을 모니터링하고, 오류가 발생한 시스템에서 실행 중이던 애플리케이션을 다시 시작할 수 있다.
운영체제의 작동 (Operating-System Operations)
Multiprogramming and Multiprocessing
Multiprogramming
멀티프로그래밍은 한 번에 두 개 이상의 프로그램을 동시에 실행하는 것이다.
- 여러 프로세스를 메모리에 동시에 유지함으로써 CPU 사용량을 높인다.
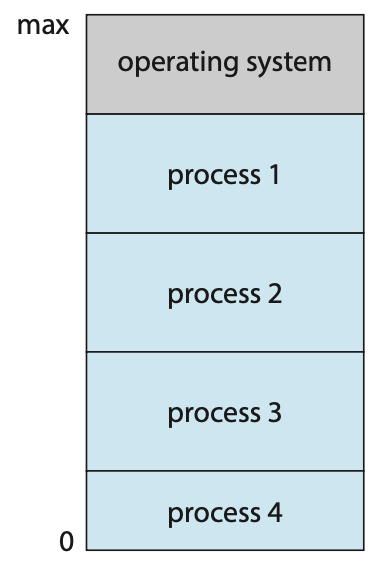
Figure 1.12 Memory layout for a multiprogramming system.Multitasking (= Multiprocessing)
멀티태스킹은 CPU 스케줄링 알고리즘이 프로세스 간에 빠르게 전환(switch)하여 사용자에게 빠른 응답 시간을 제공하는 멀티프로그래밍의 확장이다.
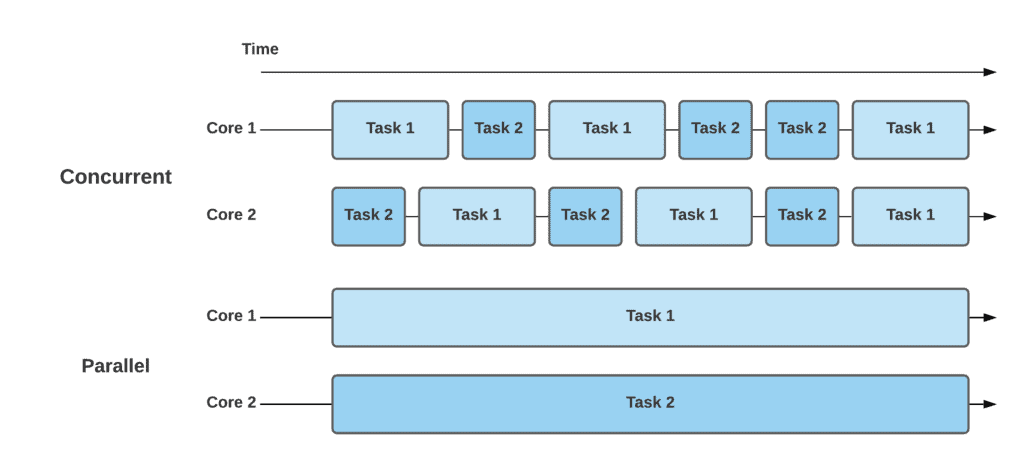
💡 Concurrency vs Parallelism
Concurrency(동시성)란 두 개 이상의 테스크를 동시에 지원함을 뜻한다.
Parallelism(병렬성)이란 두 개 이상의 테스크를 동시에 실행할 수 있음을 뜻한다.
출처: https://www.baeldung.com/cs/concurrency-vs-parallelism
Cf. JavaScript는 single-thread 환경이라 여러 개의 thread를 사용하는 Parallelism이 불가능하고, Concurrency를 지원한다.
Two separate mode of operations
시스템 하드웨어에는 user mode와 kernel mode(supervisor mode, system mode, privileged
mode라고도 불림)의 두 가지 모드가 있다.
operation의 dual mode는 잘못된 사용자로부터 운영 체제를 보호한다.
- 해를 끼칠 수 있는 일부 기계 명령어를 특권 명령어(privileged instructions)로 지정한다.
해당 명령어에는 권한이 부여되며 커널 모드에서만 실행될 수 있다. 예로는 커널 모드로 전환하라는 명령, I/O 제어, 타이머 관리, 인터럽트 관리 등이 있다.
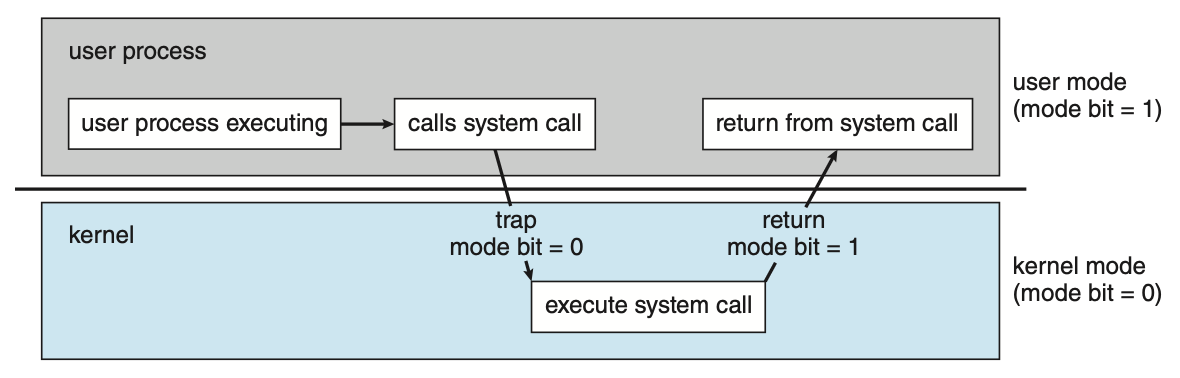
Figure 1.13 Transition from user to kernel mode.Timer
운영체제가 CPU에 대한 제어를 유지하도록 보장해야 한다. 사용자 프로그램이 무한 루프에 빠지거나 시스템 서비스 호출에 실패하고 운영 체제에 제어권을 반환하지 못하게 하면 안 된다. 이 목표를 달성하기 위해 타이머를 사용할 수 있다. 지정된 기간이 지나면 컴퓨터를 중단하도록 타이머(timer)를 설정할 수 있다. 주기는 고정(예: 1/60초)되거나 가변(예: 1밀리초 ~ 1초)될 수 있다. 가변 타이머(variable timer)는 일반적으로 고정 속도 클럭과 카운터로 구현된다. 운영 체제가 카운터를 설정하고, 시계가 똑딱거릴 때마다 카운터가 감소한다. 카운터가 0에 도달하면 인터럽트가 발생한다.
자원 관리 (Resource Management)
운영 체제는 자원 관리자(resource manager)다. 시스템의 CPU, 메모리 공간, 파일 저장 공간, I/O 장치는 운영 체제가 관리해야 하는 리소스 중 하나다.
프로세스 관리 (Process Management)
실행 중인 프로그램은 프로세스다. 프로세스가 작업을 수행하려면 CPU 시간, 메모리, 파일, I/O 장치 등 특정 리소스가 필요하다. 이러한 리소스는 일반적으로 프로세스가 실행되는 동안 프로세스에 할당된다. 프로세스가 종료되면 운영체제는 재사용 가능한 리소스를 회수한다.
단일 스레드 프로세스에는 실행할 다음 명령을 지정하는 하나의 프로그램 카운터(program counter, PC)가 있다. CPU는 프로세스가 완료될 때까지 프로세스의 명령을 하나씩 차례로 실행한다. 다중 스레드 프로세스에는 여러 개의 프로그램 카운터가 있으며, 각각은 주어진 스레드에 대해 실행할 다음 명령을 가리킨다.
프로세스는 시스템의 작업 단위다. 시스템은 프로세스 모음으로 구성되며, 그 중 일부는 운영 체제 프로세스(시스템 코드를 실행하는 프로세스)이고 나머지는 사용자 프로세스(사용자 코드를 실행하는 프로세스)다. 이러한 모든 프로세스는 잠재적으로 단일 CPU 코어에서 다중화(multiplexing)하여 동시에 실행되거나 여러 CPU 코어에서 병렬로 실행될 수 있다.
운영 체제는 프로세스 관리와 관련하여 다음 활동을 담당한다.
- 사용자 및 시스템 프로세스의 생성 및 삭제
- CPU에서 프로세스 및 스레드 예약
- 프로세스 일시중단 및 재개
- 프로세스 동기화를 위한 메커니즘 제공
- 프로세스 통신을 위한 메커니즘 제공
메모리 관리 (Memory Management)
메인 메모리는 현대 컴퓨터 시스템 작동의 핵심이다. 메인 메모리는 크기가 수십만에서 수십억에 이르는 대규모 바이트 배열이고, 각 바이트에는 고유한 주소가 있다. 메인 메모리는 CPU 및 I/O 장치에서 공유하는 빠르게 액세스할 수 있는 데이터 저장소다. 메인 메모리는 일반적으로 CPU가 직접 주소를 지정하고 액세스할 수 있는 유일한 대형 저장 장치다. 프로그램이 실행될 때 절대 주소를 생성하여 메모리의 프로그램 명령과 데이터에 액세스한다.
CPU 활용률과 사용자에 대한 컴퓨터의 응답 속도를 모두 향상시키기 위해 범용 컴퓨터는 여러 프로그램을 메모리에 유지해야 하므로 메모리 관리가 필요하다.
운영 체제는 메모리 관리와 관련하여 다음 활동을 담당한다.
- 현재 메모리의 어느 부분이 사용되고 있는지, 어떤 프로세스가 이를 사용하고 있는지 추적
- 필요에 따라 메모리 공간 할당 및 할당 해제
- 메모리에 들어오고 나갈 프로세스(또는 프로세스의 일부)와 데이터 결정
파일 시스템 관리 (File-System Management)
컴퓨터 시스템을 사용자에게 편리하게 만들기 위해 운영체제는 정보 저장에 대한 통일되고 논리적인 보기를 제공한다. 운영체제는 저장 장치의 물리적 속성을 추상화하여 논리적 저장 단위인 파일(file)을 정의한다. 운영 체제는 파일을 물리적 미디어에 매핑하고 저장 장치를 통해 이러한 파일에 액세스한다.
파일 관리는 운영체제에서 가장 눈에 띄는 구성 요소 중 하나다. 컴퓨터는 다양한 유형의 물리적 매체에 정보를 저장할 수 있다. 보조기억장치가 가장 일반적이지만 3차 저장장치도 가능하다.
운영 체제는 대용량 저장 매체(mass storage media)와 이를 제어하는 장치를 관리하여 파일의 추상적인 개념을 구현한다. 또한 파일은 일반적으로 사용하기 쉽도록 디렉토리로 구성된다. 마지막으로, 여러 사용자가 파일에 액세스할 수 있는 경우 어떤 사용자가 파일에 액세스할 수 있는지, 해당 사용자가 파일에 액세스할 수 있는 방법(예: 읽기, 쓰기, 추가)을 제어하는 것이 바람직할 수 있다.
운영 체제는 파일 관리와 관련하여 다음 활동을 담당한다.
- 파일 생성 및 삭제
- 파일 정리를 위한 디렉토리 생성 및 삭제
- 파일 및 디렉터리 조작을 위한 기본 요소 지원
- 대용량 저장소에 파일 매핑
- 안정적인(비휘발성) 스토리지 미디어에 파일 백업
대용량 저장 장치 관리 (Mass-Storage Management)
컴퓨터 시스템은 메인 메모리를 백업하기 위한 보조저장장치를 제공해야 한다. 대부분의 최신 컴퓨터 시스템은 프로그램과 데이터에 대한 주요 온라인 저장 매체로 HDD와 NVM 장치를 사용한다. 컴파일러, 웹 브라우저, 워드 프로세서 및 게임을 포함한 대부분의 프로그램은 메모리에 로드될 때까지 이러한 장치에 저장된다. 따라서 보조저장장치를 적절하게 관리하는 것은 컴퓨터 시스템에서 매우 중요하다.
운영체제는 보조저장장치 관리와 관련하여 다음 활동을 담당한다.
- 장착 및 탈착 (Mounting and unmounting)
- 여유 공간 관리 (Free-space management)
- 스토리지 할당
- 디스크 스케줄링
- 파티셔닝
- 보호
캐시 관리 (Cache Management)
캐싱(Caching)은 컴퓨터 시스템의 중요한 원칙이다. 작동 방식은 다음과 같다. 정보는 일반적으로 일부 저장 시스템(예: 메인 메모리)에 보관된다. 사용되면서 일시적으로 더 빠른 저장 시스템인 캐시에 복사된다. 특정 정보가 필요할 때 먼저 해당 정보가 캐시에 있는지 확인한다. 그렇다면 캐시에서 직접 정보를 사용한다. 그렇지 않은 경우 소스의 정보를 사용하여 곧 다시 필요할 것이라는 가정하에 캐시에 복사본을 저장한다.
또한 내부 프로그래밍 가능 레지스터는 메인 메모리에 고속 캐시를 제공한다. 프로그래머(또는 컴파일러)는 레지스터에 보관할 정보와 메인 메모리에 보관할 정보를 결정하기 위해 레지스터 할당 및 레지스터 대체 알고리즘을 구현한다.
캐시는 크기가 제한되어 있으므로 캐시 관리(cache management)는 중요한 설계 문제다. 캐시 크기와 교체 정책을 신중하게 선택하면 성능이 크게 향상될 수 있다.
-
Cf. 캐시 일관성(cache cohrerency)
계층적 스토리지 구조에서는 동일한 데이터가 스토리지 시스템의 서로 다른 수준에 나타날 수 있다. 예를 들어, 1씩 증가할 정수 A가 파일 B에 있고 파일 B가 하드 디스크에 있다고 가정한다. 증분 연산은 먼저 I/O 연산을 실행하여 A가 있는 디스크 블록을 주 메모리에 복사함으로써 진행된다. 이 작업 후에는 A를 캐시와 내부 레지스터에 복사한다. 따라서 A의 복사본은 하드 디스크, 주 메모리, 캐시 및 내부 레지스터 등 여러 위치에 나타난다. 내부 레지스터에서 증가가 발생하면 A 값은 다양한 저장 시스템에서 다르다. A의 값은 A의 새로운 값이 내부 레지스터에서 하드 디스크로 다시 쓰여진 후에야 동일해진다.

Figure 1.15 Migration of integer A from disk to register.한 번에 하나의 프로세스만 실행되는 컴퓨팅 환경에서는 정수 A에 대한 액세스가 항상 계층 구조의 가장 높은 수준에 있는 복사본에 대한 것이기 때문에 어려움이 없다. 그러나 CPU가 다양한 프로세스 사이에서 앞뒤로 전환되는 멀티태스킹 환경에서는 여러 프로세스가 A에 액세스하려는 경우 각 프로세스가 가장 최근에 업데이트된 값을 얻도록 극도의 주의를 기울여야 한다.
각 CPU에 내부 레지스터와 로컬 캐시가 포함되어 있는 멀티프로세서 환경에서는 A의 복사본이 여러 캐시에 동시에 존재할 수 있다. 다양한 CPU가 모두 병렬로 실행될 수 있으므로 한 캐시의 A 값에 대한 업데이트가 A가 있는 다른 모든 캐시에 즉시 반영되도록 해야 한다. 이러한 상황을 캐시 일관성(cache cohrerency)이라고 하며 일반적으로 하드웨어 문제다(운영체제 수준 아래에서 처리됨).
분산 환경에서는 상황이 더욱 복잡해진다. 이 환경에서는 동일한 파일의 여러 복사본(또는 복제본)이 다른 컴퓨터에 보관될 수 있다. 다양한 복제본에 동시에 액세스하고 업데이트할 수 있으므로 일부 분산 시스템에서는 복제본이 한 곳에서 업데이트될 때 다른 모든 복제본도 최대한 빨리 최신 상태로 유지된다.
| Level | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Name | registers | cache | main memory | solid-state disk | magnetic disk |
| Typical size | < 1 KB | < 16MB | < 64GB | < 1 TB | < 10 TB |
| Implementation technology | custom memory with multiple ports CMOS | on-chip or off-chip CMOS SRAM | CMOS SRAM | flash memory | magnetic disk |
| Access time (ns) | 0.25-0.5 | 0.5-25 | 80-250 | 25,000-50,000 | 5,000,000 |
| Bandwidth (MB/sec) | 20,000-100,000 | 5,000-10,000 | 1,000-5,000 | 500 | 20-150 |
| Managed by | compiler | hardware | operating system | operating system | operating system |
| Backed by | cache | main memory | disk | disk | disk or tape |
Figure 1.14 Characteristics of various types of storage.입출력 시스템 관리 (I/O System Management)
운영체제의 목적 중 하나는 사용자로부터 특정 하드웨어 장치의 특성을 숨기는 것이다. 예를 들어, UNIX에서 I/O 장치의 특성은 I/O 하위 시스템(I/O subsystem)에 의해 운영체제 자체에서 숨겨진다. I/O 하위 시스템은 여러 구성 요소로 구성된다.
- 버퍼링, 캐싱, 스풀링(spooling)을 포함하는 메모리 관리 구성 요소
- 일반 장치 드라이버 인터페이스
- 특정 하드웨어 장치용 드라이버
가상화 (Virtualization)
가상화(Virtualization)는 단일 컴퓨터(CPU, 메모리, 디스크 드라이브, 네트워크 인터페이스 카드 등)의 하드웨어를 여러 다른 실행 환경으로 추상화하여 개별 환경이 별도의 컴퓨터에서 실행되고 있다는 환상을 만들 수 있는 기술이다.
- Virtual Machine Manager (VMM) e.g. VMware, XEN, WSL, …
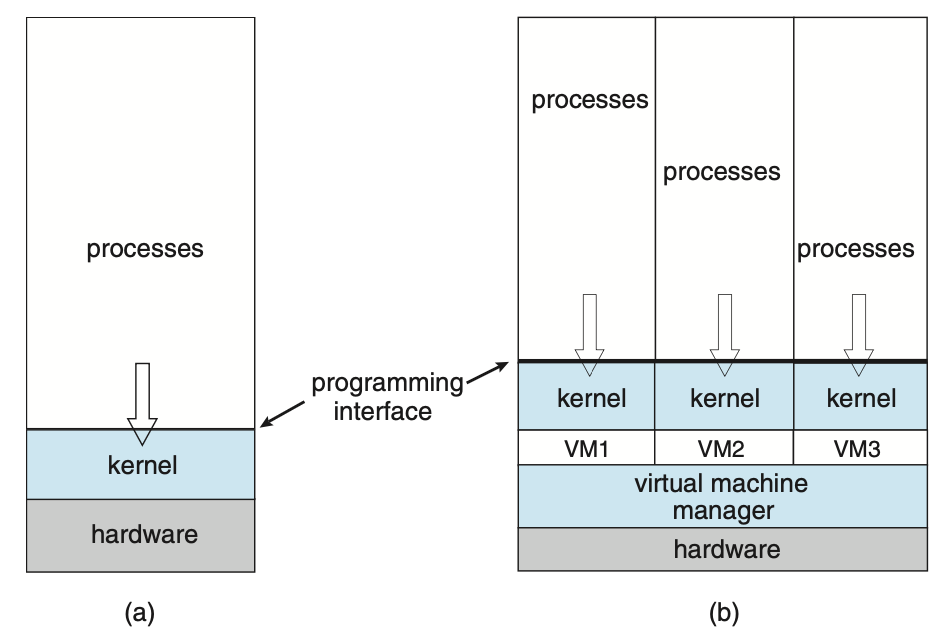
Figure 1.16 A computer running (a) a single operating system and (b) three virtual machines.컴퓨팅 환경 (Computing Environments)
-
전통적인 컴퓨팅
오늘날 웹 기술이 전통적인 컴퓨팅의 경계를 확장하고 있다. -
모바일 컴퓨팅
모바일 컴퓨팅은 휴대용 스마트폰과 태블릿 컴퓨터의 컴퓨팅 환경을 말한다.
현재 휴대 컴퓨팅에서 두 개의 지배적인 운영체제는 Apple iOS와 Google Android다.
-
client-server 컴퓨팅

현대 네트워크 구조는 서버 시스템이 클라이언트 시스템이 생성한 요청을 만족시키는 배치를 특징으로 하며, 클라이언트-서버 시스템이라 불린다.
-
peer-to-peer(p2p) 컴퓨팅

분산 시스템의 다른 구조는 피어 간 시스템이다. 이 모델에서는 클라이언트와 서버가 서로 구별되지 않으며, 시스템상의 모든 노드가 피어로 간주되고 각 피어는 서비스를 요청하느냐 제공하느냐에 따라 클라이언트 및 서버로 동작한다. 서비스가 네트워크에 분산된 여러 노드에 의해 제공될 수 있으므로, 서버가 병목으로 작용하는 클라이언트-서버 시스템에 비해 장점을 제공한다. -
클라우드 컴퓨팅
클라우드 컴퓨팅은 계산, 저장장치는 물론 응용조차도 네트워크를 통한 서비스로 제공하는 계산 유형이다. 어떤 면에서 클라우드 컴퓨팅은 가상화를 그 기능의 기반으로 사용하기 때문에 가상화의 논리적 확장이다.클라우드 컴퓨팅의 유형
- Public cloud — 서비스를 위해 지불 가능한 사람은 누구나 인터넷을 통해 사용 가능한 클라우드
- Private cloud — 한 회사가 사용하기 위해 운영하는 클라우드
- Hybrid cloud — 공공(public)과 사유(private) 부분을 모두 포함하는 혼합형 클라우드
- Software as a service (SaaS) — 인터넷을 통해 사용 가능한 하나 이상의 응용 프로그램 (e.g. spreadsheet)
- Platform as a service (PaaS) — 인터넷을 통해 사용하도록 응용 프로그램에 맞게 준비된 소프트웨어 (e.g. database server)
- Infrastructrue as a service (IaaS) — 인터넷을 통해 사용 가능한 서버나 저장장치 (e.g. 생산 데이터의 백업 복사본을 만들기 위한 저장장치)
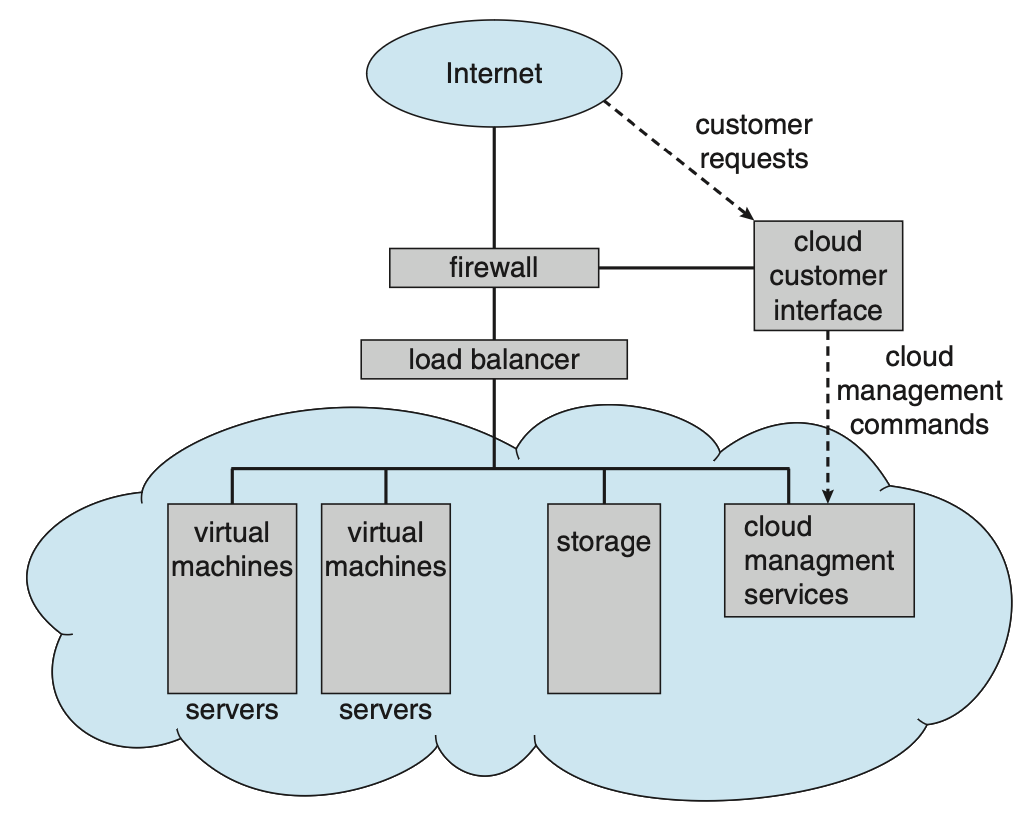
Figure 1.24 Cloud computing.
-
실시간 임베디드 시스템
내장형 시스템은 현재 가장 유행하는 컴퓨터의 형태다. 이 장치들은 자동차 엔진, 공장용 로봇, 광학 드라이브, 전자파 오븐 등 어느 곳에서나 볼 수 있으며, 아주 특정한 작업만을 수행하는 경향이 있다. 일반적으로 사용자 인터페이스가 거의 없으며, 주로 자동차 엔진이나 로봇 팔과 같은 하드웨어 장치들을 모니터링하고 관리한다.
Open-Source Operating System

GNU/Linux
소프트웨어 사용 및 재배포를 제한하려는 움직임에 대응하기 위해 1984년 Richard Stallman은 GNU라는 무료 UNIX 호환 운영체제(”GNU’s Not Unix!”의 약어)를 개발하기 시작했다. 자유 소프트웨어는 다음과 같은 네 가지 자유가 보장되어야 한다고 주장한다. (1) 자유롭게 소프트웨어를 실행시킬 권리, (2) 소스 코드를 분석하고 수정할 권리, (3) 코드 수정 없이 배포하거나 판매할 권리 또는 (4) 코드를 수정하여 배포하거나 판매할 권리. 1985년에 Stallman은 모든 소프트웨어가 자유로워야 한다고 주장하는 GNU 선언문을 발표하였다. 또한 자유 소프트웨어의 사용 및 개발을 장려하기 위해 자유 소프트웨어 재단(FSF)을 설립하였다.
1991년 핀란드의 Linus Torvalds 학생은 GNU 컴파일러와 도구를 사용하여 초보적인 UNIX 유사 커널을 출시했으며 전 세계에 공동 개발을 요청하였다. 1992년에 GLP에 따라 Linux를 무료 소프트웨어로 릴리스했다.
그 결과로 만들어진 GNU/Linux 운영체제(커널만 말할 때는 Linux라고 하지만 GNU 도구를 포함한 전체 운영체제는 GNU/Linux라고 부름)는 시스템의 수백 가지의 고유한 배포판 또는 사용자 맞춤 빌드를 생성하였다. 주요 배포판에는 Red Hat, Fedora, Debian, Slackware 및 Ubuntu가 있다. 배포판은 기능, 유틸리티, 설치된 응용 프로그램, 하드웨어 지원, 사용자 인터페이스 및 목적에 따라 다르다. 예를 들어, Red Hat Enterprise Linux는 대규모 상업적 용도로 사용된다.
시스템에서 Linux를 수행할 수 있는 간단하고 무료인 방법은 다음과 같다.
- Virtualbox VMM 도구를 다운로드 받아 시스템에 설치한다.
https://www.virtualbox.org/- CD와 같은 설치 이미지를 기반으로 운영체제를 처음부터 새로 설치하거나, 더 빠르게 설치하고 실행할 수 있는 미리 설치된 운영체제 이미지를 선택할 수 있는 사이트를 이용한다.
http://virtualboxes.org/images/- Virtualbox 내에서 가상 머신을 부팅한다.
References
- Operating System Concepts 10th
- PART ONE OVERVIEW
- Chapter 1 Introduction
- PART ONE OVERVIEW
- 운영체제 공룡책 전공강의 | 주니온 - 인프런
- 섹션 1. Chapter 1-2. Introduction & O/S Structures
