정규화 (Normalization)
불필요한 데이터(data redundancy)를 제거하여 중복 최소화
데이터베이스의 데이터들을 최대한 중복 제거하여 이상 현상 ( Anomaly ) 제거
- 갱신 이상 ( Modification Anomaly )
중복된 데이터 중 일부를 갱신할 때 의도치 않은 데이터가 갱신됨으로써 생기는 데이터의 불일치- 삽입 이상 ( Insertion Anomaly )
새 데이터를 삽입할 때 의도치 않은 데이터가 삽입됨으로써 생기는 데이터의 불일치- 삭제 이상 ( Deletion Anomaly )
데이터를 삭제할 때 의도치 않은 데이터까지 삭제됨으로써 생기는 데이터의 불일치
😃 제 1 정규화 (1NF)
- 도메인 원자값
- 반복 그룹은 존재 하지 않는다
- 모든행은 식별자로 완전하게 구분
🤔 Before
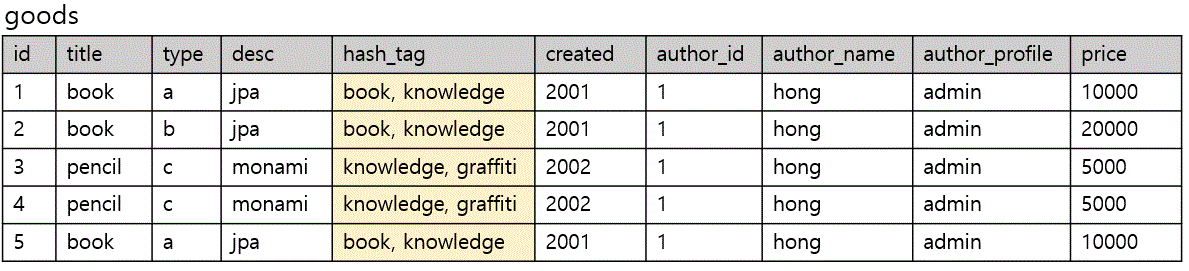
위의 테이블은 제 1정규화의 원자성을 만족하지 않는다.
컬럼 hash_tag에는 하나의 row 에 book, knowledge, graffiti 등 하나 이상의 값이 존재
select * from goods where hash_tag = 'free'
select * from goods order by hash_tag
위와 같은 쿼리를 사용할 경우 원하는 데이터를 조회불가
또한, 테이블과 join 할 경우 값이 하나의 컬럼 안에 여러 개의 값이 있다면, 조인하는 것이 어렵거나 불가능
😊 After
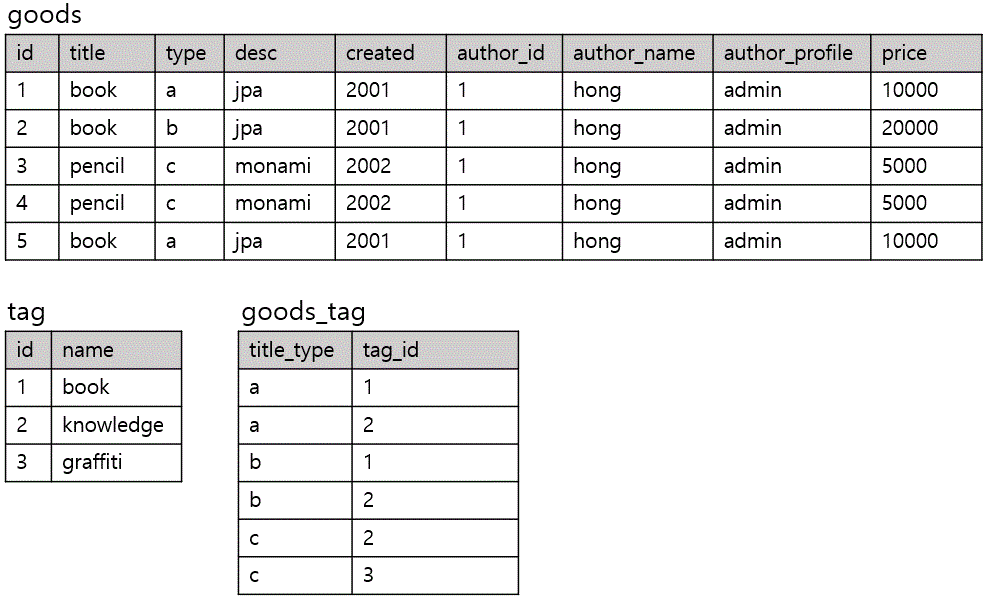
goods table, tag table 을 나눈 후 이 두 테이블을 연결하는 goods_tag 테이블 추가
hash_tag는 title이 무엇이느냐에 따라서 hash_tag가 book, knowledge, graffiti 인지 달라진다
😃 제 2 정규화 (2NF)
- 부분종속성이 없어야한다
- 중복키 여부 확인
🤔 Before
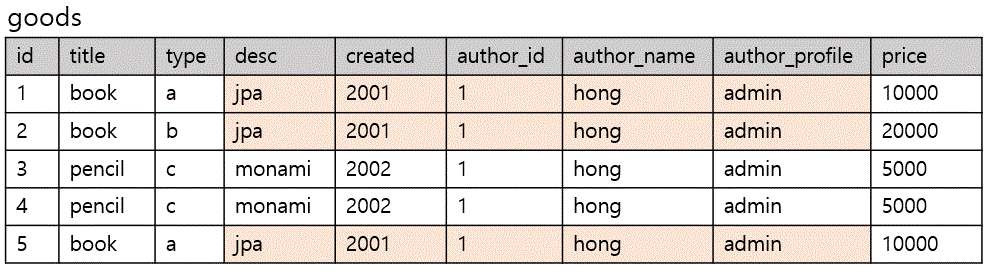
type 이라는 칼럼을 삭제하여 중복 데이터를 제거하여 테이블화를 한다.
😊 After
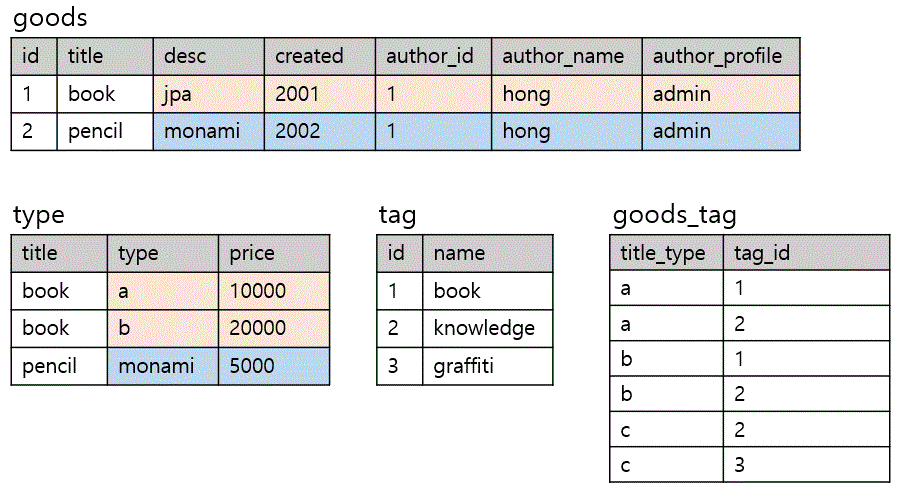
goods 테이블에는 더이상 중복되는 데이터가 존재하지 않는다.
title 과 type에 의존하는 type 테이블을 생성하여 관계를 형성한다.
😃 제 3 정규화 (3NF)
- 이행종속성을 제거
goods 테이블의 행은 title의 기본키에 종속되어있다. book 이나 pencil 이 행 전체를 대표하는 칼럼이다. 단, author_name 과 author_profile 칼럼은 author_id 에 의존하고 있는 관계도 존재한다. 이를 이행종속성 관계라고한다.
🤔 Before

😊 After
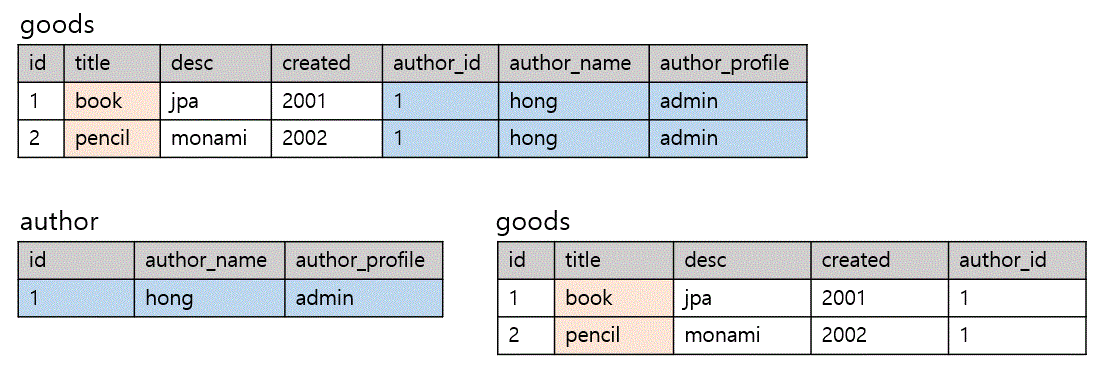
cf) 생활코딩 정규화 시리즈

반갑습니다. 개발자 변희준입니다.