저장 프로시저 (Stored PROCEDURE)
정의
프로시저는 SQL Server에서 제공되는 프로그래밍 기능이며 SQL문을 저장해놓고 필요할때마다 호출해서 사용할 수 있도록 한다.
간단하게는 DML(SELECT, INSERT, UPDATE, DELETE)을 사용할 수 있으며, IF문이나 SET등의 프로그래밍 문법을 사용할 수도 있다.
저장프로시저 예시
- 일반적인 쿼리문
SELECT * FROM `user` WHERE name ='이승기';
SELECT * FROM `user` WHERE name ='성시경';
SELECT * FROM `user` WHERE name ='은지원';- 저장 프로시저
CREATE PROC select_by_name
@Name NVARCHAR(3)
AS
SELECT * FROM user WHERE name =@name;장점과 단점
장점
-
보안성 향상 : 프로시저 단위로 권한을 부여할 수있기 때문에 보안사고에 대한 대처가 유연하다.
-
네트워크 소요 시간 절감 : 쿼리를 다중으로 실행할 때, 한번의 호출을 통해 다중의 쿼리가 실행되므로 네트워크의 소요시간을 줄일 수 있다.
-
운영 배포 용이성 : 별도의 WAS 서버 재기동 없이 SP 수정으로 조회, 수정, 추가 등의 가벼운 소스 변경 등이 가능하여, 긴급 배포 등이 용이하다.
-
SQL Server의 성능 향상 : 저장 프로시저를 처음에 실행하면 최적화, 컴파일 단계를 거쳐 그 결과가 캐시(메모리)에 저장되게 되는데, 이 후에 해당 SP를 실행하게 되면 캐시(메모리)에 있는 것을 가져와서 사용하므로 실행속도가 빨라지게 된다.
-
유지보수 및 재활용 용이 : C#, Java등으로 만들어진 응용프로그램에서 직접 SQL문을 호출하지 않고 저장 프로시저의 이름을 호출하도록 설정하여 사용하는 경우가 많은데, 이때 개발자는 수정요건이 발생할때 코드 내 SQL문을 건드리는게 아니라 SP 파일만 수정하면 되기 때문에 유지보수 측면에서 유리해진다.
단점
-
낮은 처리 성능 : 프로시저의 경우 성능이나 최적화가 부족하여 수행 능력이 떨어지며, 특히 문자열이나 숫자 연산에 사용하면 JAVA, C 등에 비해서 효율이 좋지 않다.
-
디버깅의 어려움 : APP에서 SP를 호출하여 사용하는 경우 문제가 생겨도 해당 이슈에 대한 추적이 힘들다.
SQL문과 저장 프로시저 동작 비교
일반 SQL 동작방식
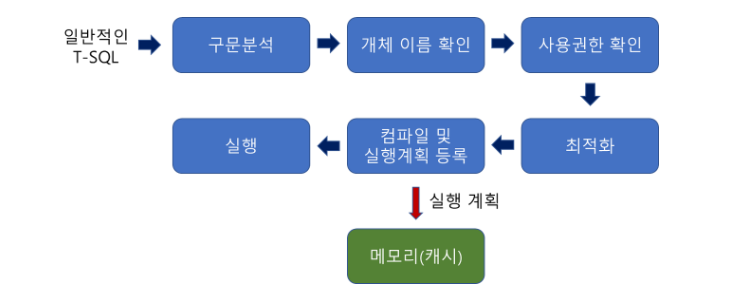
일반적인 SQL문을 처음으로 실행하면 위의 그림대로 동작한다.
SELECT `id` FROM `user`해당 쿼리를 실행한다고 가정했을때, 동작방식에 따르면
-
구문자체에 오류가 없는지 분석, 오타가 있다면 오류메시지 반환
-
개체 이름 확인은 user라는 이름의 테이블이 현재 DB에 있는지 확인을 하고, 있다면 그 안에 id라는 컬럼이 있는지 확인한다.
-
현재 접근한 사용자가 user테이블의 권한이 있는지 확인한다.
-
최적화 단계에서는 해당 쿼리가 가장 좋은 성능을 낼 수 있는 경로를 설정한다. 인덱스 사용여부에 따라 경로가 달라질 수 있기 때문에 테이블 스캔, 클러스터 인덱스 스캔이 진행된다.
-
최적화 결과를 바탕으로 실행계획 결과를 캐시에 저장한다.
-
저장한 컴파일 결과를 실행한다.
한 줄의 쿼리라도 6개의 단계를 거쳐서 실행되어지게 된다. 이런 단계를 거쳐서 한번 실행한 SQL문을 다시 실행하게 되면 아래와 같은 진행을 한다.
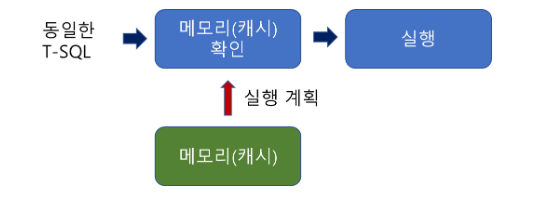
SQL문에서 한 글자라도 다른 SQL문을 실행하게 되면 위의 6단계를 다시 거치게 된다.
저장 프로시저 동작방식
저장 프로시저를 정의 했을때의 동작방식이다.
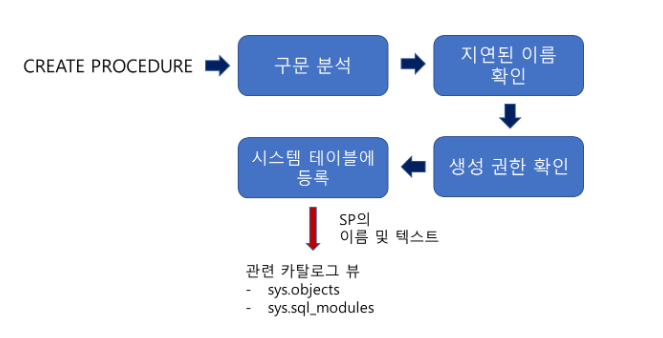
-
구문자체에 오류가 없는지 분석, 오타가 있다면 오류메시지 반환
-
지연된 이름 확인 과정은 저장 프로시저의 특징이다. 프로시저를 정의하는 시점에 테이블과 같은 해당 개체의 존재 여부와 상관없이 정의가 가능한데, 그 이유는
해당 테이블의 존재 여부를 프로시저의 실행 시점에 확인하기 때문이다.그렇기에 해당 테이블의 존재 여부와 상관없이 프로시저는 정의할 수 있지만 테이블의 컬럼 이름이 틀리면 오류가 발생된다. -
현재 접근한 사용자가 저장프로시저를 생성할 권한이 있는지 확인한다.
-
시스템 테이블 등록을 진행한다. 저장 프로시저의 이름과 코드가 관련 시스템 테이블에 등록되는 과정이다.
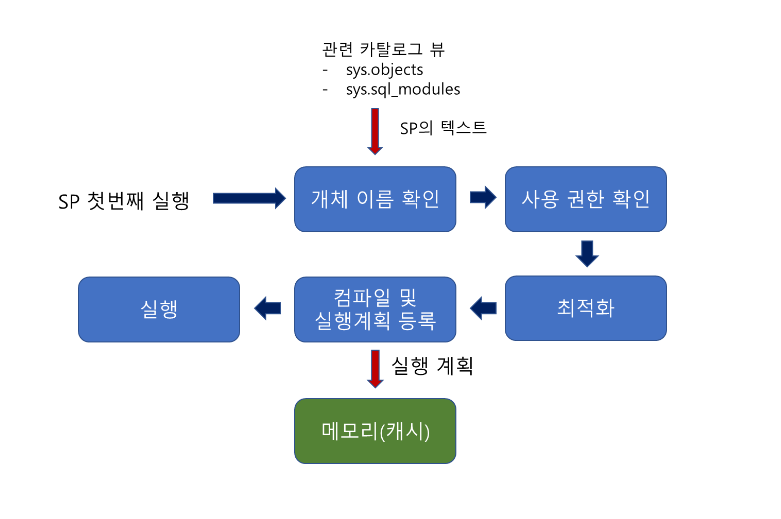
처음으로 저장 프로시저를 실행했을 때의 동작방식이다.
일반적인 쿼리의 동작방식과 비슷하다.
위에서 정의할 때 지연된 이름 확인을 개체이름 확인단계에서 진행한다.
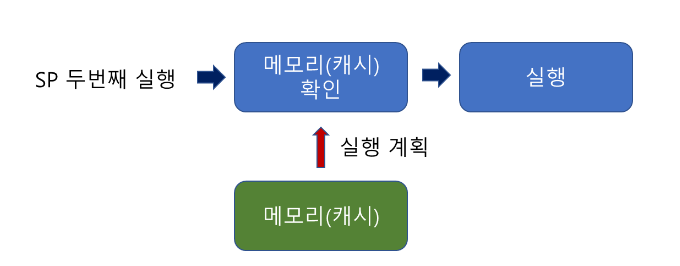
두번째 실행 단계부터는 일반적인 쿼리문의 동작과 수행시간이 많이 차이나게 된다.
위에서 들었던 예시 쿼리문을 보면
SELECT * FROM user WHERE name ='이승기';
SELECT * FROM user WHERE name ='성시경';
SELECT * FROM user WHERE name ='은지원';여기서 은지원을 김지원이라고만 바꿔도 위의 6단계의 과정을 다시 진행하게 된다.
하지만
CREATE PROC select_by_name
@Name NVARCHAR(3)
AS
SELECT * FROM user WHERE name =@name;위와 같이 저장 프로시저로 구성하게 되면 이승기를 검색하는 과정에서만 최적화와 컴파일을 수행하고 나머지는 캐시에 있는것을 사용한다.
자주 사용하는 쿼리라면 저장 프로시저가 성능적인 측면에서 효과적이다.




쿼리를 재사용하기 위해 저장프로시저라는 것도 있군요. 하나 배워갑니다.