10장. 선형회귀
-
회귀 : 데이터들을 2차원 공간에 찍은 후에 이들 데이터들을 가장 잘 설명하는 직선이나 곡선을 찾는 것.
-
선형회귀 : 입력 데이터를 가장 잘 설명하는 기울기와 절편값을 찾는 무제.
선형회귀 기본식 -> f(x) = Wx + b
여기에서 기울기 W는 가중치 (weight)
절편 b는 바이어스 (bias) -
단순선형회귀 : 입력 변수(x)가 하나일 때, 직선으로 데이터를 설명하는 회귀.
f(x) = Wx + b

위 이미지와 같이 공부시간(입력변수 x 하나)에 따라 일정하게 출력값(y) 가 달라지는 경우에 단순선형회귀를 사용하면 된다.
- 다중 선형 회귀 : 입력 변수(x, y, z, ...) 가 여러 개일 때, 직선(평면)으로 데이터를 설명하는 회귀.
쉽게 말해 입력 변수가 여러 개이고, 입력 변수마다 가중치를 다르게 주는 방법이다.

- 손실 함수 : 예측이 얼마나 틀렸는지를 수치화하여 나타낸 것.
필요한 이유 : 회귀의 목표는 데이터를 가장 잘 설명하는 직선을 찾는 것인데, 이 직선이 잘 맞는지를 판단할 기준이 손실 함수이다.
기본식 : (예측값 - 정답값)을 제곱해서 모두 더해서 평균을 낸다.
많이 사용하는 손실 함수 (MSE)

어떤 w와 b를 넣어봤을 때 손실값이 최대한 작은 것을 구하는 것이 우리의 목표.
그런데 w, b가 어떤 값이 최소 손실값이 나올지 한 번에 알 수 없다.
이때 사용하는 것이 경사하강법.
- 경사하강법 : 손실을 줄이는 방향으로 w와 b를 조금씩 고쳐가는 방법.
목표 : argmin Loss(W, b)
경사하강법은 손실 함수를 최소화하기 위해 손실이 감소하는 방향으로 가중치와 바이어스를 반복적으로 조금씩 업데이트 하는 방법.
11장. KNN
- KNN
개념 : 새로운 데이터가 주어지면 기존 데이터들과의 거리를 계산한 뒤에 가장 가까운 K개의 이웃을 선택하고, 분류 문제의 경우 다수결로, 회귀 문제의 경우 평균값으로 예측한다.
분류 : 신규 데이터를 기존 그룹 중 어디에 속할지 판단하는 것.
KNN 장단점
장점 : 구현이 간단하고 학습 과정이 없다.
단점 : 데이터가 많아지면 느리다. 거리 계산 비용이 크다.
- Decision Tree
개념 : 스무고개 게임 (계속 질문을 던져서 데이터를 분류(예측)하는 모델.
위에서 아래로 내려가면서 판단.
Root node : 처음 질문.
Leaf node : 최종 결정.
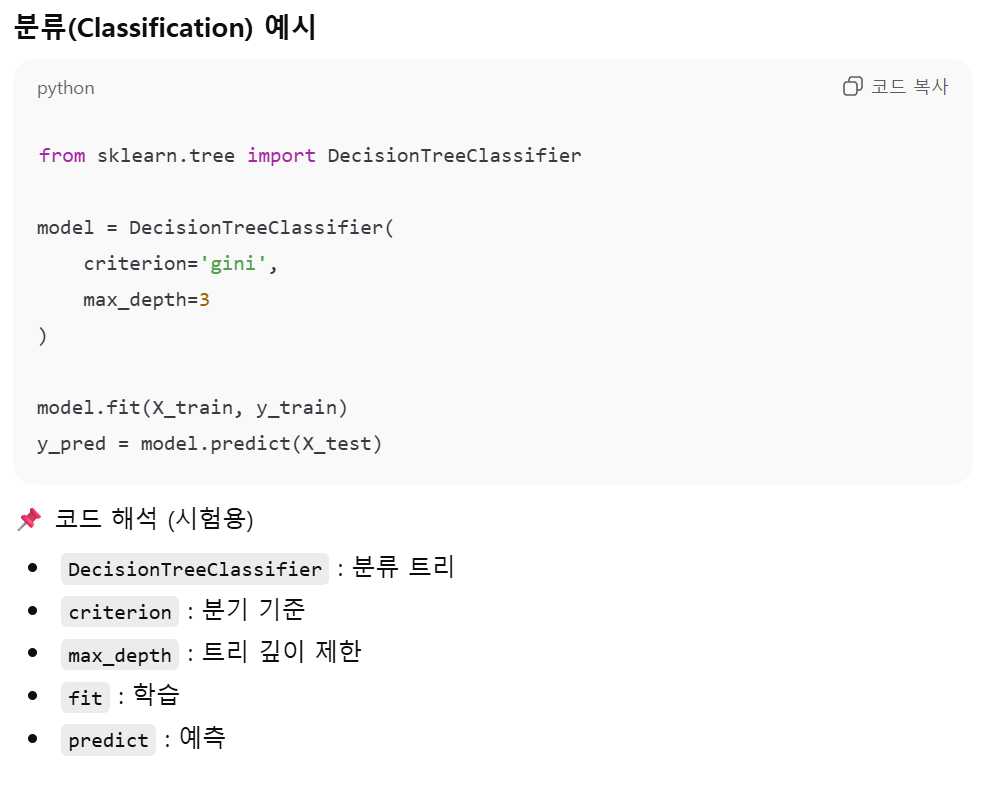
Decision Tree 기본 파라미터.
criterion : 노드를 분기할 때 사용하는 기준.
max_depth : 트리의 최대 깊이.
min_samples_split : 노드를 나누기 위한 최소 데이터 개수. (데이터가 너무 적을 때 쪼개지 않도록 막는다. )
min_samples_leaf : 리프 노드에 남아야 하는 최소 데이터 수.
Decision Tree 장점 : 데이터를 분류하는 논리의 흐름을 시각적으로 볼 수 있다.
코드의 이해가 쉽다.
Decision Tree 단점 : 과적합에 빠지기 쉽다.
KNN : 거리 기반
Decision Tree : 질문 기반
12장. 퍼셉트론
- 퍼셉트론
개념 : 여러 입력을 받아 가중합을 계산한 뒤, 활성화 함수를 거쳐
출력을 내는 가장 기본적인 신경망.
퍼셉트론 구조 :
z = w1x1 + w2x2 + … + wnxn + b
가중합 ⇒ z
입력 ⇒ x1, x2, x3, …, xn
퍼셉트론은 하나의 뉴런만을 사용한다.
다수의 입력을 받아서 하나의 신호를 출력하는 장치이다.
13장. 다층 퍼셉트론
-
다층 퍼셉트론
개념 : 입력층과 출력층 사이에 은닉층을 가지고 있는 신경망.
퍼셉트론에서는 계단함수를 활성화 함수로 사용했지만,
다층 퍼셉트론 (MLP)에서는 다양한 비선형 함수들을 활성화 함수로 사용한다.
MLP에서 쓰는 활성화 함수 ⇒ Sigmoid, TanH, ReLU -
역전파 알고리즘
출력에서 생긴 오차를 뒤쪽에서 앞쪽으로 전달하면서,
각 가중치를 얼마나 고쳐야 하는지 계산하는 방법.
가중치를 조절하는 과정
가중치를 증가시켰을 때 오차 감소 → 가중치 증가.
가중치를 증가시켰을 때 오차 증가 → 가중치 감소.
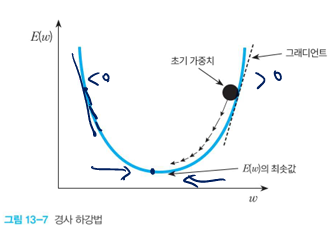
미분값 < 0 (미분값이 음수라면)
오른쪽으로 갈수록 계속 손실 감소.
w 증가시켜야 한다.
미분값 > 0 (미분값이 양수라면)
오른쪽으로 갈수록 계속 손실 증가.
w 감소시켜야 한다.
미분값이 음수라면, w 가중치를 증가시키고.
미분값이 양수라면, w 가중치를 감소시켜야.
손실값을 줄일 수 있다.
14장. 딥러닝
DNN (딥러닝)은 MLP(다층 퍼셉트론) 에서 은닉층의 개수를 증가시킨 것이다.
Gradient 소멸 문제
개념 : 은닉층이 많아질수록 역전파되는 기울기가 점점 작아져서
앞쪽 층의 가중치가 거의 학습되지 않는 현상.
Gradient 소멸 발생 이유 : 시그모이드, 탄젠트 함수와 같은 활성화 함수의 작은 미분값이
역전파 과정에서 반복적으로 곱해지기 때문이다.
Gradient 폭발 문제
개념 : 역전파 중 기울기가 너무 커져
가중치가 발산하는 현상.
역전파 과정에서 실제로 전달되는 것은 ‘기울기’
w ← w - 학습률 x 기울기
기울기가 클 경우 많이 고치고,
기울기가 작을 경우 거의 안 고치고,
기울기가 0 이면 학습을 멈춘다.
역전파는 뒤에서 앞으로 기울기를 전달한다.
그리고 전달할 때마다 곱해진다.
은닉층이 많아질 때, 은닉층마다 기울기를 곱하니까 기울기값이 작다면 0에 수렴해진다.
가중치 초기화의 필요성
역전파에서 오차는 가중치가 곱해져서 전달되는데,
모든 가중치가 0이면 오차 역전파가 제대로 되지 않는다.
그래서 가중치 초기화는 그래디언트 소멸과 폭발을 방지하고,
신경망의 안정적인 학습을 위해 필요하다.
Dropout (과적합 방지)의 효과랑 기능 파악하기.
Dropout은 일부 뉴런을 랜덤하게 비활성화하여, 과적합을 방지하고, 모델의 일반화 성능을 향상시킨다.
15장. CNN
CNN (컨벌루션 신경망) 개념 :
CNN은 이미지를 한 번에 보지 않고 작은 영역씩 보면서 특징을 뽑고,
중요한 정보만 남겨서 마지막에 분류하는 신경망이다.
CNN의 순서
(컨벌루션 → Pooling → 컨벌루션 → Pooling) → Flatten → Dense → 출력
컨벌루션
작은 필터(커널)가 이미지를 슬라이싱하면서 특정 패턴(엣지, 모서리 등)을 찾는다.
그러니까 작은 필터로 이미지 전체를 훑으면서 계산하는 연산이다.
필터 : 패턴을 검사하는 기준표. (패턴이 얼마나 강한지 계산)
필터가 많아질수록, 더 다양한 특징을 본다.
그 연산 결과를 특징맵이라고 한다.
필터가 1개라면 특징맵도 1개만 반환.
하지만 16개라면 특징맵도 16개 반환된다.
패턴을 검사하는 기준표이기 때문이다.
Feature Map ⇒ 컨벌루션 연산의 결과로 만들어진 ‘특징만 남은 이미지’
Pooling 연산
목적 : 특징맵의 크기를 줄여, 계산량과 과적합을 줄이기 위해서 사용.
폴링 종류 : Max Pooling, Average Pooling.
Max Pooling (영역에서 최댓값), Average Pooling (영역에서 평균값)
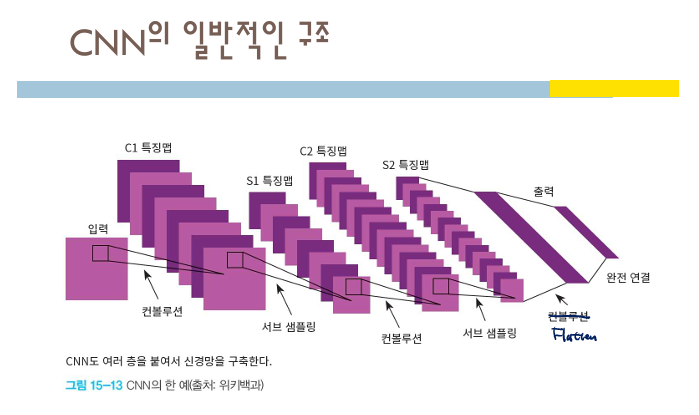
Flatten
컨벌루션 결과는 2D 아니면 3D 데이터이다.
하지만 Dense 는 1D 벡터 데이터만 입력 가능하다.
그래서 Flatten 과정을 거쳐서 펴줘야 한다.
한줄 정의 : 특징맵을 1차원 벡터로 변환하는 연산.
Dense 레이어는 최종 분류를 수행하는 층이다.
16장. 영상인식
왜 픽셀값을 255로 나눌까?
⇒ 픽셀값은 원래 0에서 255 사이의 값을 가진다.
그런데 이 값 그대로 가중치에 곱하면, 가중합 z 값의 숫자가 너무 커진다.
이 값이 그대로 활성화 함수로 들어가면 활성화 함수가 너무 커져 포화 구간에 들어가고,
이로 인해 미분값이 0에 가까워져 Gradient 소멸이 발생한다.
그래서 255로 나눠서 0~1 사이의 작은 값으로 바꿔준다.
데이터 증대
: 한정된 데이터에서 여러 가지로 변형된 데이터를 만들어내는 기법.
이미지를 회전, 이동, 반전하여 과적합을 방지하고 일반화 성능을 향상시킨다.
ImageDataGenerator
: 이미지 데이터를 자동으로 전처리 + 증강해주는 도구.
rescale=1./255 ⇒ 픽셀값 정규화.
rotation_range ⇒ 살짝 회전.
width_shift_range ⇒ 좌우 이동.
height_shift_range ⇒ 상하 이동.
zoom_range ⇒ 확대/축소.
horizontal_flip ⇒ 좌우 반전.
전이학습
: 이미 학습된 모델을 가져와 새 문제에 재사용하는 것.
장점 : 적은 데이터로도 가능하고 학습이 빠르고, 성능이 좋다.
단점 : 기존 데이터와 너무 다르면 성능 저하.
전이 3단계
1. 사전 학습된 모델 불러오기 (VGG, ResNet, MobileNet 등)
2. 기존 레이어 동결
3. 새로운 Dense 레이어 학습. (새 문제의 클래스에 맞게 새롭게 판단)
17장. 강화학습
-
강화학습
개념 : 정답을 주지 않고, 행동의 결과로 받은 ‘보상’을 기준으로
어떤 행동이 좋은지 스스로 배우는 학습 방법. -
강화학습 구성 요소
Agent → 강화 학습의 중심이 되는 객체
Environment → 에이전트가 작동하는 물리적 세계
State → 에이전트의 현재 상황 (미로 게임이라면 에이전트의 위치가 된다)
Action → 에이전트의 행동
Reward → 보상 (환경으로부터의 피드백)
Q테이블과 Q 함수
Q(s, a)는 상태 s에서 행동 a를 했을 때 앞으로 받을 ‘기대 보상’
Q테이블
행은 상태, 열은 행동, 값은 Q값.
처음에는 전부 값이 0이다. 우연히 목표에 도착하면 값이 채워지기 시작한다.
