이미지 분류 모델에서의 혼동행렬 (Confusion Matirx)
분류 모델의 성능을 평가할 때, 4가지의 값을 사용한다.
TP, FP, FN, TN
TP => True + Positive
FP => False + Positive
FN => False + Negative
TN => True + Negative
먼저 뒷부분(Positive, Negative)은 모델의 예상값 을 의미한다.
Positive라면, '맞다' 혹은 '있다' 와 같은 긍정의 의미를 지닌다.
반면 Negative라면 '틀리다', '없다'의 의미가 된다.
반면 앞부분(True, False)은 모델 예상값의 정답 여부 를 의미한다.
True라면 모델 예상값이 맞다는 것을,
False라면 모델 예상값이 틀렸다는 것을 의미한다.
예를 들어, 이미지에서 사람이 있는지 없는지 찾는 모델이 있다고 가정해보자.
사람이 있는 곳을 찾고 실제로 해당 이미지에 사람이 있다면,
P (모델의 예상 : 있다. 즉, Positive)
T (모델 예상 값 정답 여부 : True / 실제로 있기 때문)
=> 합쳐서 TP
이런 식으로 분류 모델의 성능을 평가하게 된다.
모델이 예상값을 틀리는 FP와 FN의 경우 헷갈렸다.
너무 헷갈려서 그림으로 정리해 보았다.
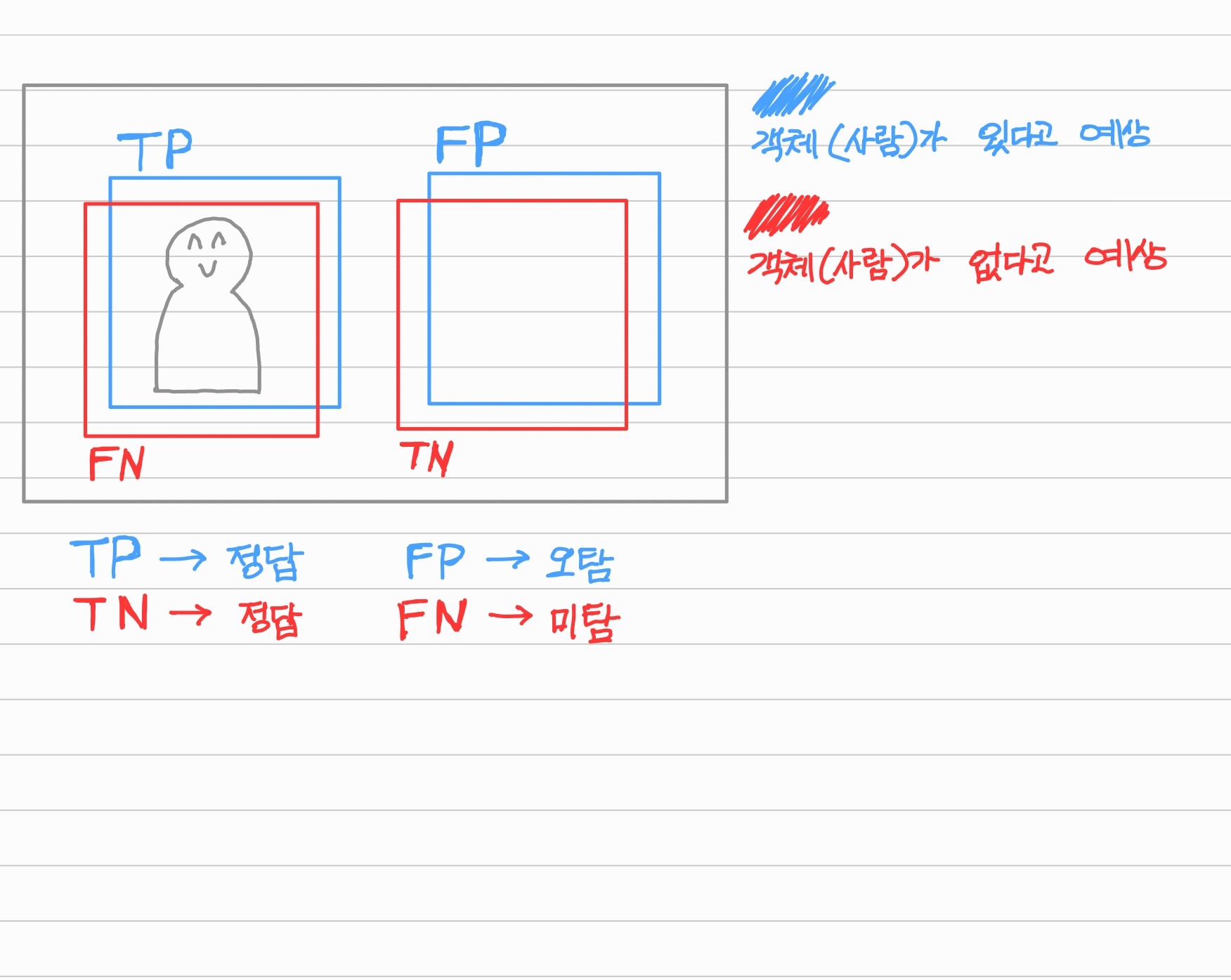
따라서
FP는 모델이 이미지에 사람이 있다(Positive)고 예측했는데, False(오답)이기 때문에 실제 이미지에는 사람이 없는 것이다.
없는데 있다고 예측을 했기 때문에 '오탐'이 된다.
FN는 모델이 이미지에 사람이 없다(Negative)고 예측했는데, False(오답)이기 때문에 실제 이미지에는 사람이 있는 것이다.
있는데 없다고 예측을 했기 때문에 '미탐'이 된다.
Precision
모델이 '있다' 라고 예측한 것 중에서 실제로 맞은 비율이다.
즉, _P 들 중에서 TP 의 비율을 의미한다.
당연히 수식 또한 Precision = TP / TP + FP 가 된다.
위 이미지에서 파란색 네모들 중에서 TP 네모의 비율을 생각하면 이해가 쉽다.
Recall
실제 객체 중 모델이 찾아낸 비율을 의미한다.
위 이미지에서 사람이 있는 부분에 쳐진 두 개의 네모 (TP, FN) 중에서 TP 네모의 비율을 생각하면 된다.
