
✏️ 오늘의 학습
DataBase Connection Pool (DBCP)
자바 어플리케이션에서 DataBase와 Connection을 맺고, 객체를 관리하기 위한 DataBase Pool이다.
- DataBase Pool은 DataBase Connection 객체를 미리 만들어놓고 저장 및 관리하는 역할을 한다. DBCP Connection Close 는 물리적인 Connection을 끊는게 아니라 Connection Pool에 Connection 객체를 반환하는 동작이 수행된다.
- javax.sql.DataSource 를 이용하여 Connection을 맺는다.
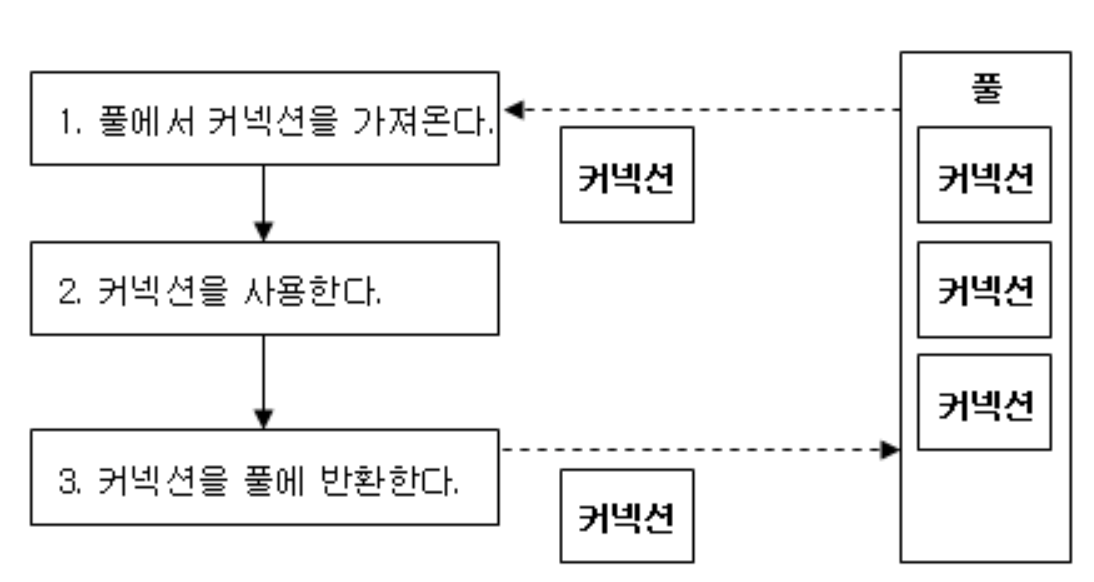
JDBC VS DBCP
-
JDBC(Java DataBase Connectivity) : 자바 어플리케이션과 DataBase를 연결하기 위한 인터페이스로 아래와 같은 프로세스를 실행한다.
1) DriverManager를 통한 DataBase Connection 객체 생성
2) Connection 객체에서 Statement 객체 생성 및 쿼리 실행
3) ResultSet 결과 처리
4) Connection Close
-
JDBC는 DataBase를 연결할때마다 1~4번 과정을 실행하는데, 1번과 4번 수행하는 것은 오랜 시간을 필요로 하게된다.
-> DBCP는 이러한 부분을 개선한것이라고 보면된다. 한번 DataBase Connection 객체를 생성했으면 DataBase Connection 객체를 Close 하지않고 DataBase Connection Pool에서 오픈된 상태의 Connection을 가지고 있다가, Connection이 필요할 때 할당을해주고, 작업이 끝나면 Connection을 반환받아서 Connection Pool에서 관리를한다.
HikariCP (JDBC Connection Pool Library)
스프링 부트 2.0 전에는 톰캣에서 제공해준 DBCP(아파치 DBCP랑 동일)를 사용했고, 스프링 부트 2.0 이후부터는 HikariCP 를 이용한다.
//jdbc dependency
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<scope>test</scope>
</dependency>Connection Pool 이 실제로 어떻게 사용되는지 확인해보자
DataSource를 통해 HikariConnectionPool을 연결하고, 실제로 필요할때만 Connection Pool에서 객체를 가져다 쓰는지 확인해보자.
show status like '%Threads%';다음 명령어를 통해서 DataBase Threads와 관련된 상태변수를 확인할 수 있다. 6번째줄을 보면 Threads_connected가 1개 연결된걸 확인할 수 있다.
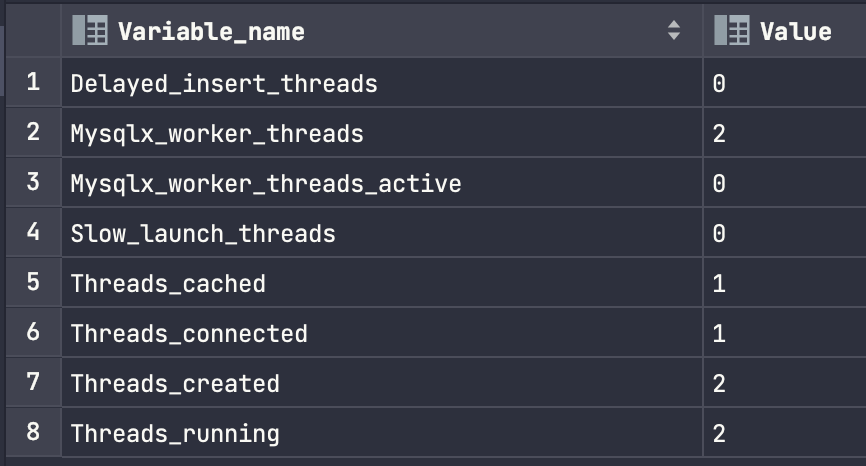
아래 테스트를 실행시키고 다시 show status like '%Threads%'; 를 실행시켜보면 Threads_connected 개수가 늘어났다가, 테스트가 끝나면 Threads_connected 개수가 1개로 바뀌는걸 확인할 수 있는데, 작업이 끝나서 Connection Pool에 반환했다고 볼 수 있다.
@SpringJUnitConfig
class CustomerRepositoryTest {
@Configuration
@ComponentScan(
basePackages = {"org.prgrms.kdt"}
)
static class Config {
@Bean
public DataSource dataSource() {
return DataSourceBuilder.create()
.url(dbInfo)
.username(userInfo)
.password(password)
.type(HikariDataSource.class)
.build();
}
}
@Autowired
CustomerRepository customerRepository;
@Autowired
DataSource dataSource;
@Test
public void testHikariConnectionPool() {
assertThat(dataSource.getClass().getName(), is("com.zaxxer.hikari.HikariDataSource"));
}
@Test
@DisplayName("전체 고객을 조회할 수 있다.")
public void testFindAll() {
var customers = regularCustomerRepository.findAll();
assertThat(customers.isEmpty(), is(false));
}
}- 커넥션 개수를 늘릴려면 dataSource 사이즈를 변경해주면 된다.
dataSource.setMaximumPoolSize(1000);
dataSource.setMinimumIdle(100);TestInstance Lifecycle
@BeforeAll
테스트가 실행되기전에 1번 실행할 수 있도록 하는 어노테이션으로 아래와 같이 static 메서드여야 한다.
@BeforeAll
static void clean() {
}그런데! clean() 메서드에서 non-static 메서드를 참조하려면 어떻게 해야할까?
Junit 에서 제공하는 @TestInstance() 어노테이션을 활용하면 된다.
@TestInstance
- @TestInstance(TestInstance.Lifecycle.PER_CLASS)
인스턴스의 라이프사이클을 CLASS 단위로 설정, 인스턴스가 클래스 단위로 1개만 존재하게 된다. - @TestInstance(TestInstance.Lifecycle.PER_METHOD)
인스턴스의 라이프사이클을 METHOD 단위로 설정, 인스턴스가 메서드 단위로 1개만 존재하게 된다.
테스트 순서 보장
테스트 메서드의 순서를 지정하고 싶으면 @TestMethodOrder(MethodOrderer.OrderAnnotation.class) 와 @Order(1)를 이용하면 된다.
@SpringJUnitConfig
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
class RegularCustomerRepositoryTest {
...
@BeforeAll
void setUp() {
...
}
@Test
@Order(1)
public void testHikariConnectionPool() {
...
}
@Test
@Order(2)
@DisplayName("고객을 추가할 수 있다.")
public void testInsert() {
...
}
}테스트할 때 메서드의 실행 순서를 정하고 싶으면 @Order(3) 과 같이 설정하면 된다.
JDBC Template
JDBC Template 은 전통방식으로 구현하는 JDBC로직을 간결하게 처리할 수 있는 Spring API이다. 반복되는 부분을 Template으로 만들고, 변경이 되는 코드를 Callback을 이용해서 JDBC Template으로 제공하고 있다.
아래 이미지는 JDBC Template 적용 전 예시 코드인데, 코드를 짜다보면 표시해놓은 부분이 중복되는 경우가 많다. 이를 JDBC Template을 이용하면 중복코드를 줄이고 간결하게 코드를 작성할 수 있다.
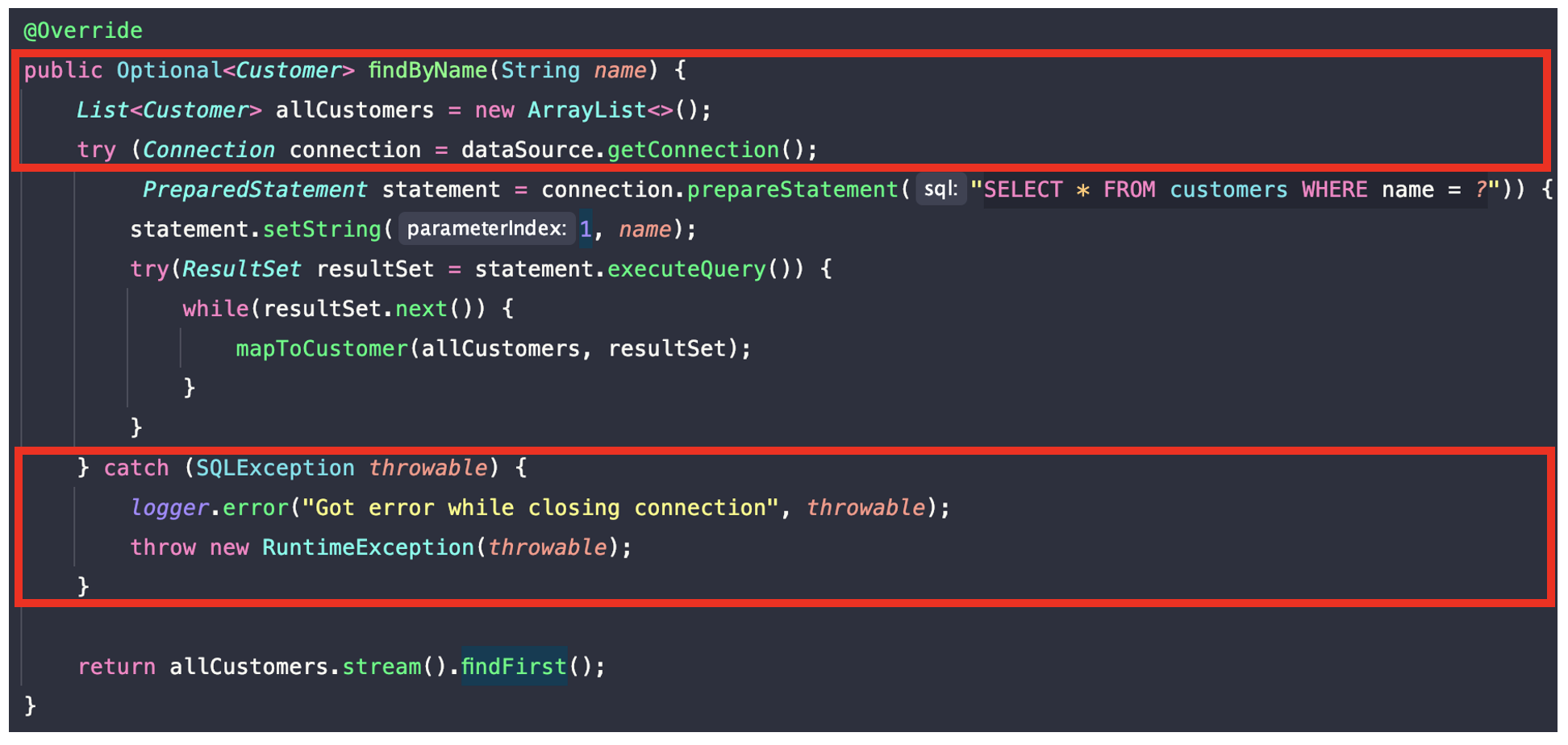
JDBC Template은 기본적으로 DataSource만 있으면 쓸 수 있고, jdbcTemplate.query(sql, rowMapper)로 사용할 수 있다.
JDBC Template을 사용하려면 아래와 같이 빈으로 등록해주고, DataSourece를 주입받아야 한다.
public class RegularCustomerRepository implements CustomerRepository{
private final DataSource dataSource;
private final JdbcTemplate jdbcTemplate;
private static final RowMapper<Customer> customerRowMapper = (resultSet, i) -> {
String customerName = resultSet.getString("name");
String email = resultSet.getString("email");
UUID customerId = toUUID(resultSet);
LocalDateTime lastLoginAt = resultSet.getTimestamp("last_login_at") != null ?
resultSet.getTimestamp("last_login_at").toLocalDateTime() : null;
LocalDateTime createdAt = resultSet.getTimestamp("created_at").toLocalDateTime();
return new RegularCustomer(customerId, customerName, email, lastLoginAt, createdAt);
};
public RegularCustomerRepository(DataSource dataSource, JdbcTemplate jdbcTemplate) {
this.dataSource = dataSource;
this.jdbcTemplate = jdbcTemplate;
}
@Override
public Optional<Customer> findByName(String name) {
try {
return Optional.ofNullable(jdbcTemplate.queryForObject("SELECT * FROM customers WHERE name = ?",
customerRowMapper,
name));
} catch (EmptyResultDataAccessException e) {
logger.error("Got empty result", e);
return Optional.empty();
}
}
}
class RegularCustomerRepositoryTest {
@Configuration
@ComponentScan(
basePackages = {"org.prgrms.kdt"}
)
static class Config {
@Bean
public DataSource dataSource() {
return DataSourceBuilder.create()
.url(dbInfo)
.username(user)
.password(password)
.type(HikariDataSource.class)
.build();
}
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource;
}
}
- jdbcTemplate.query : list가 반환된다.
- jdbcTemplate.queryForObject : 1개의 값만 반환된다.
🔗 오늘의 알고리즘
leetcode complex-number-multiplication
class Solution {
public String complexNumberMultiply(String num1, String num2) {
// (a+bi)(c+di) => ac + adi + bci +(-bd) => ac + (ad + bc)i +(-bd)
String[] s1 = num1.split("\\+");
String[] s2 = num2.split("\\+");
int a = Integer.parseInt(s1[0]);
int b = Integer.parseInt(s1[1].replace("i", ""));
int c = Integer.parseInt(s2[0]);
int d = Integer.parseInt(s2[1].replace("i", ""));
String real = Integer.toString(a*c+(-1*b*d));
String imaginary = Integer.toString(a*d+b*c);
StringBuilder sb = new StringBuilder();
sb.append(real);
sb.append("+");
sb.append(imaginary);
sb.append("i");
return sb.toString();
}
}알고리즘 자체는 논의할 내용이 없었는데, 출력 결과를 어떻게 하냐에 따라서 실행속도 차이가 많이났다.
String + 연산자를 쓰는건 새로운 String 인스턴스를 만들어 내기때문에 느린걸 알고있었는데, String.format(), String split() 이 느린건 처음알게 됐다. 이 친구들은 regex를 이용하는데 regex가 느리다고 한다.
regex가 느린 이유
동섭님이 공유해주신 String Performance
재원님이 공유해주신 split vs StringTokenizer
연수님이 공유해주신 각종 String 비교 자료
🎤 데일리 스터디 발표
08.25.(수) W4D1, W4D2 학습 내용 발표 범위
- 소프트웨어 테스팅 - 효희님
- 단위테스트 - 효희님
- 통합테스트 - 효희님
- JUnit - 재원님
- JUnit 실습 - 재원님
- Mock Object - 나
- 유닛테스트 실습 - 나
- Spring Test - 연수님
- Spring Test 실습 - 연수님
- JDBC 알아보기 - 동섭님
- JDBC 준비하기 - 동섭님
✏️ 오늘의 궁금증
- 도메인 객체에서 비즈니스 룰을 작성한다고 하는데, 도메인 객체의 역할은 어디까지일까?
- 테스트코드 엣지케이스를 유연하게 생각하려면 많은 경험과 노력이 필요할 것 같다. 노련한(?) 테스트 코드를 작성하려면 얼마나 많은 시간이 필요할까?
🎊 오늘의 느낀점
- 시간이 미친듯이 빨리간다. 시간을 붙잡아둘 수 있으면 얼마나 좋을까?
- 강의 내용 정말 좋다. 핵심적인 내용만 콕콕찝어서 알려주시는 느낌. 자바 / 스프링 생태계를 많이 알고있는 상태에서 들었으면 더 좋았을 것 같다. 급하게 소화하려다보면 마음만 조급해지고 효율만 떨어진다는걸 명심해야지! 조급하게하지말고 느리더라도 차근차근 소화해서 내것으로 만들자.
- 알고리즘 문제가 쉬워서 공유할 내용이 많지않을거라 생각했는데 생각과 다르게 스트링관련해서 많은걸 공유했다. 스트링 관련해서 아는건 확실하게 알게됐고(안까먹고 입으로 말할 수 있게 됐다), 혼자공부했더라면 몰랐을 부분까지 알게됐다!
