📍 Prometheus란?
프로메테우스는 Soundcloud사에서 개발한 오픈소스 모니터링 툴로, vm이나 container node의 메트릭 정보를 시계열데이터로 저장하고 관리합니다. 2016년에 CNCF에 합류했으며, 서비스 운영을 위해 모니터링 시스템을 구축할 때 가장 널리 사용되는 툴이기도 합니다.
1. 특징
👍🏻 장점
(1) Pull-Based Monitoring
기존에 사용되던 모니터링 툴은 주로 대상서버에 직접 설치되어 사용되는 agent방식이 많았습니다. 이 agent가 수집서버에 메트릭 정보를 전송해주는 Push-Based Monitoring 방식이었던거죠.
프로메테우스에서는 Exporter라는 개념이 있습니다. Exporter는 대상서버에 설치되어서 메트릭을 수집합니다. 그렇게 쌓인 데이터를 수집서버가 가져가는 구조입니다.
(2) 시계열데이터베이스(TSDB)
RDB가 아닌 메트릭 이름 및 key-value 쌍으로 식별되는 시계열데이터가 있는 다차원 데이터 모델을 사용해거 많은 양의 정보를 빠르게 검색할 수 있습니다. Time-Stamped DataBase라고도 불리는 Time Seriese DataBase는 시간에 따라 저장된 데이터를 의미하며, 시간 경과에 따른 변화를 추적하는데 용이합니다.
(3) PromQL
PromQL은 다차원 데이터 모델에서 사용하는 쿼리언어로, 시계열 데이터를 실시간으로 조회하고 집계합니다. 자체 쿼리지만 사용 방법이 어렵지 않기 때문에 빠르게 익힐 수 있습니다.
(4) 시각화(w/ Grafana)
대부분 프로메테우스를 사용하는 사례에서 Grafana 라는 사용하는 걸 볼 수 있으실겁니다. Grafana는 오픈소스 메트릭 시각화 대시보드로, 시스템관점의 메트릭을 시각화하는데에 특화되어있습니다. 프로메테우스와의 호환성이 좋아 모니터링 툴 구축 시 우선적으로 고려되는 조합입니다.
(5) 다양한 Exporter
1번에서 언급한 exporter에는 다양한 종류가 있는데요, node exporter, wmi exporter 등 다양한 형태의 메트릭을 수집하는 exporter들이 오픈소스로 공개되어있습니다. 공개된 exporter 외에 개인이 custom해서 사용할 수도 있답니다.
더 많은 종류는 아래 프로메테우스 공식 홈페이지에서 확인할 수 있습니다.
https://prometheus.io/docs/instrumenting/exporters/
👎🏻 단점
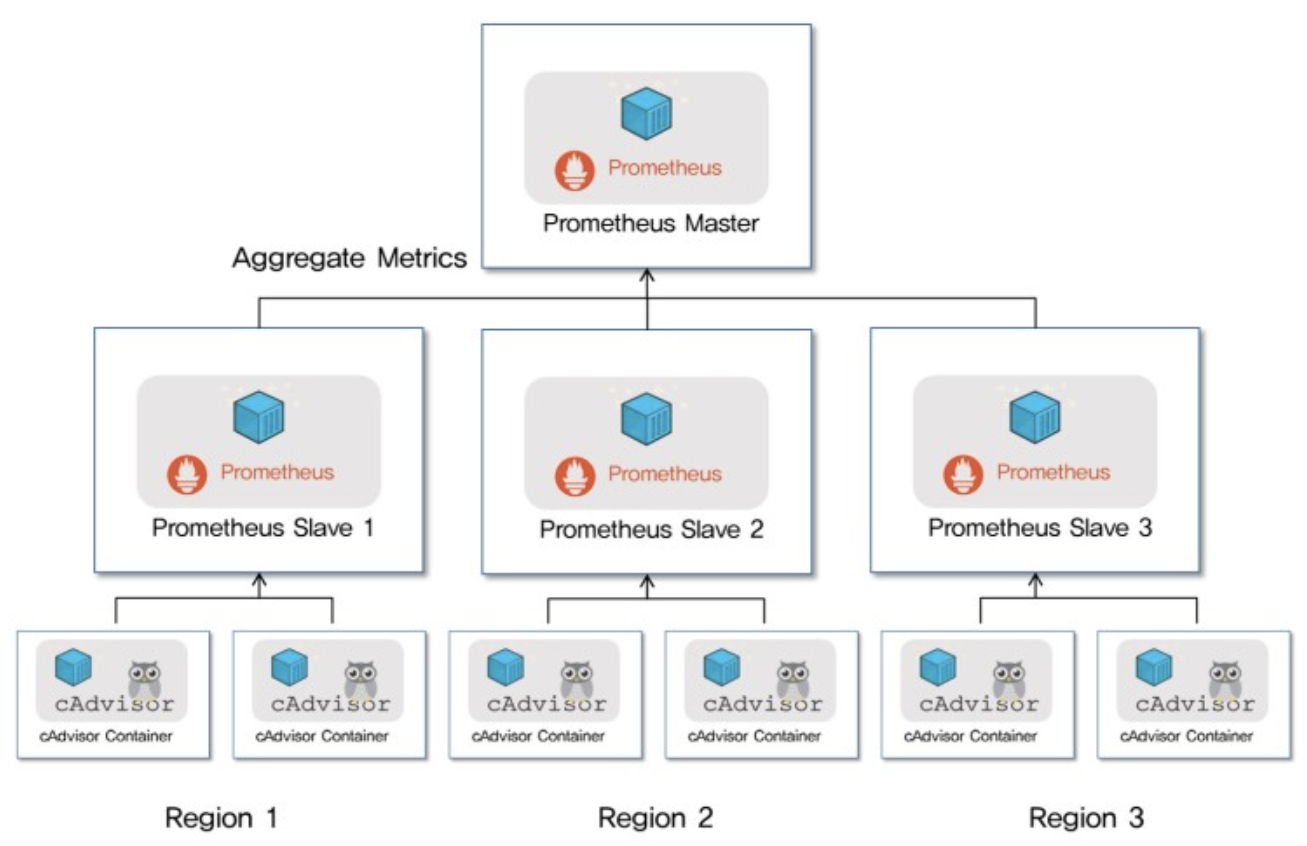
(1) Single-Host 구조의 한계
상단의 구조처럼 프로메테우스는 Single-Host 구조를 가지고 있습니다. 때문에 저장공간이 부족한 경우 서버의 디스크 용량을 늘려야 합니다.
Clustering은 유사한 성격을 가진 객체를 그륩으로 구성하는것을 의미하며, 클러스터링을 지원하는 구조는 확장성에 용이합니다. 하지만 프로메테우스는 클러스터링을 지원하지 않습니다. 그렇다면 어떻게 다중화 구조를 형성할 수 있을까요?
다중화를 위해서는 각 Region에 프로메테우스 서버를 배치 하고 이를 Master에 Aggregate하는 것이 프로메테우스가 공식적으로 권장하는 방식입니다. Replication 없이, 여러개의 Prometheus를 띄워 같은 목록을 풀링시키고 저장하는 방법을 사용하게 되는데, 이 때 Thanos라는 오픈소스 프로메테우스 스케일링 툴을 유용하게 활용할 수 있습니다. (Thanos는 추후에 따로 살펴보도록 하겠습니다.😎)
(2) 장애 대응 측면
프로메테우스는 일정 주기로 메트릭 정보를 조회해오는 pull-based 방식의 툴입니다. 이 점은 장점이기도 하지만 장애대응이라는 측면에서 보면 허점을 가지고 있습니다. 모든 메트릭을 수집하는 게 아니라 풀링하는 순간의 스냅샷 정보를 가지고 오는 것이기 때문에 근삿값을 알 수 있습니다. 따라서 모든 로그를 추적하거나 빠르게 장애를 감지하는데는 어려움이 있습니다.
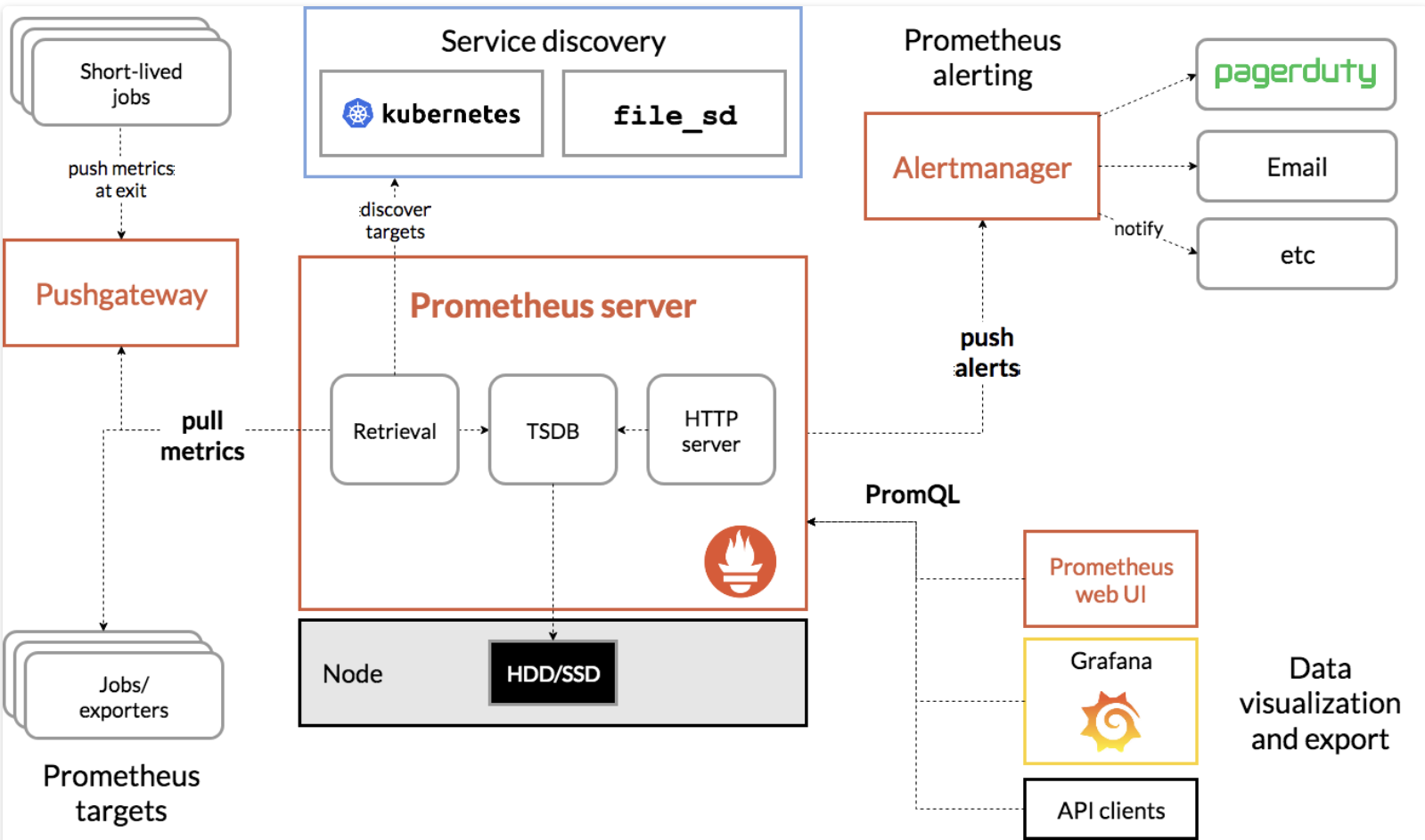
2. 기본 아키텍쳐
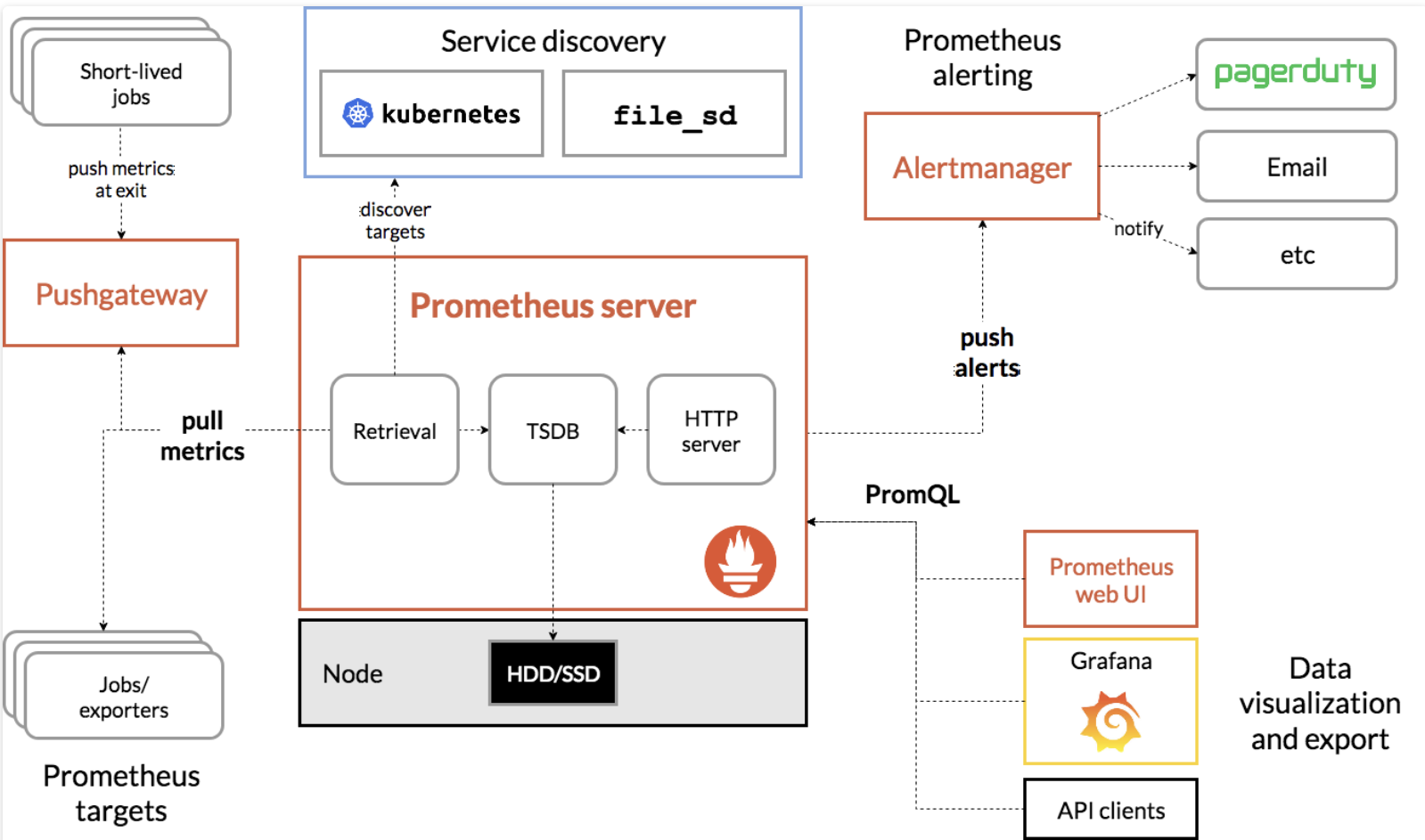
프로메테우스의 아키텍쳐는 크게 메트릭데이터를 (1)수집 (2)저장 (3)조회 하고, (4)알림을 처리하는 부분으로 나누어 볼 수 있습니다. 각 기능을 하는 부분에 대해 자세히 살펴보겠습니다 🤓
(1) 수집
-
Jobs/Exporters :
특징에서 언급했던 Exporter를 통해 메트릭 데이터를 수집합니다. 모니터링 대상에 설치되어서 프로메테우스가 메트릭 정보를 가져갈 수 있도록 HTTP GET방식의 API Endpoint를 제공하게 됩니다. 이 때 Response는 당시의 정보를 리턴할 뿐 따로 데이터를 저장하지는 않습니다. -
Service Discovery :
모니터링 대상을 유동적으로 관리하기 위해서는 Service Discovery 방식을 사용할 수 있습니다. 예를 들면 대상 서버들을 내부 DNS에 등록해놓고 새로운 서버가 생성되는 시점에 DNS에 등록하고, DNS에서 현재 기동중인 서버들의 IP들로 풀링을 하면 되는 구조를 사용할 수 있습니다. 이외에도 전용 솔루션인 Hashicorp사의 Consul 또는 쿠버네티스를 통해서, 모니터링 대상을 다이나믹하게 관리할 수 있습니다. -
Retrieval :
Service Discovery로 부터 모니터링 대상을, Exporter로 부터 메트릭을 수집하는 컴포넌트입니다.
(2) 저장
- TSDB(TimeSeriesDatabse) :
수집된 정보는 별도 DB가 아닌 프로메테우스 서버의 메모리와 로컬 디스크에 저장됩니다. 때문에 용량 증설 시 디스크를 늘릴 수 밖에 없다는 단점을 가지고 있다고 앞서 언급하기도 했죠! 필요에 따라 원격서버에 데이터를 저장할 수도 있습니다.
(3) 조회
- HTTP server :
프로메테우스에 저장된 데이터를 조회하기 위해 HTTP Rest API를 제공합니다. API를 사용하여 조회할 수 있고, Prometheus Web UI에서 확인할 수도 있습니다. - Grafana :
TSDB에 저장된 메트릭 데이터를 가장 효과적으로 시각화 할 수 있는 대시보드 입니다.
(4) 알림
- Alert Manager :
임계치 도달 등의 문제가 발생했다고 생각되는 시점에 다양한 채널을 통해 알림을 전송하는 모듈입니다. Alert rules와 manager 두 파트로 나뉘며, Alert rules가 Alert manager에게 alert 메시지를 전송하면 Alert manager는 사용자에게 알림을 보내줍니다. 기 설정된 Rule을 기반으로 동작하며 mail, slack, hipchat 등을 통해 알림을 전송할 수 있습니다.
