
이펙티브 코틀린(Effective Kotlin) 책 스터디를 진행하면서 내가 발표를 진행했던 아이템을 포스팅하려고 한다.
Chapter 7: Make it cheap
- 메모리는 싸고 개발자는 비싸다. 따라서 코드 비효율성은 어느정도는 합리적이다.
- 하지만 효율성은 장기간에 걸쳐 중요하다.
- but 최적화는 쉽지 않다.
- Chapter 7, 8은 performance에 대한 내용이다.
- 어떻게 성능을 최적화할지에 대한 코틀린 특화한 제안을 제공한다.
Readability와Performance와의 상충관계(tradeoff)를 명심해라- 개발하는 컴포넌트에 있어서 무엇이 더 중요한지 생각해라
- 제안은 하겠지만 universal answer은 없다.
Item 45: Avoid unnecessary object creation
[아이템 45: 불필요한 객체 생성을 피하라]
불필요한 객체 생성을 피하는 것이 최적화에서 중요하다.
- JVM에서는 하나의 가상머신에서 동일한 문자열을 처리하는 코드가 여러 개 있다면, 기존의 문자열을 재사용한다.
- Boxed primitives (Integer, Long)도 작은 수에 한해 재사용한다. (Integer의 경우 -128 ~ 127까지 캐싱)
- Int를 사용하면 일반적인 기본(원시) 자료형인 int로 컴파일된다.
- 하지만 nullable하거나 type argument로 사용할 경우 int 대신 Integer 자료형을 강제
(원시형은 null과 type argument가 될 수 없기 때문)
객체로 Wrapping하는 것은 3가지 비용이 발생한다.
- 객체가 더 많은 용량을 차지한다.
- 요소가 encapsulated(캡슐화)되어 있다면, 해당 요소에 대한 접근은 추가적인 함수 호출이 필요하다.
- 객체는 생성되고, 메모리에 할당되어야 하고, 이에 대한 reference를 만드는 등의 작업이 필요하다. (작은 비용이지만)
객체를 제거함으로써 3가지 비용을 피할 수 있고, 객체를 재사용함으로써 1, 3번째 비용을 제거할 수 있다.
Obeject declaration : Object 선언
객체를 재사용하는 간단한 방법은 Object 선언을 사용하는 것이다. (싱글톤)
예시를 들어보겠다.
 위 예제의 문제점은 매번 Empty 인스턴스를 새로 만들어야한다.
위 예제의 문제점은 매번 Empty 인스턴스를 새로 만들어야한다.
Empty 인스턴스를 미리 하나만 만들고, 다른 리스트에서 활용할 수 있게 한다하여도 제네릭 타입이 일치하지 않아서 문제가 발생할 수 있다.
다음 예제로 문제를 해결할 수 있다.
 (틀린그림찾기의 정답은 object와 out modifier다)
(틀린그림찾기의 정답은 object와 out modifier다)
Nothing 리스트의 Object를 만들어서 해결할 수 있다.
코틀린에서 Nothing은 모든 타입의 자식타입이다.
(Any는 모든 타입의 부모이듯이)
(Any -> Number -> Int -> Nothing)
또한, 리스트가 covariant(out 한정자로 인해)라면,
LinkedList<Nothing>은 모든 LinkedList의 서브타입이 된다.
앞서 들었던 예시는 LinkedList<T>로 invariance(불변성)에 해당하므로 T에 해당하는 자료형으로 맞춰서 할당해줘야한다.
하지만 covariant인 리스트에는 해당 리스트의 모든 서브타입을 할당할 수 있다.
따라서
val list: LinkedList<Int> = LinkedList<Nothing>()
과 같은 형태로 할당을 할 수 있으므로 Empty Object를 계속 재사용할 수 있다.
간단하게 변성에 대해 모르는 사람을 위해 설명하자면 기본적으로 모든 제네릭은 불변성이며 제네릭 타입 매개변수(ex T) 앞에 out 한정자가 붙으면 covariant(공변성) in 한정자가 붙으면 contravariant(반공변성)이다. covariant인 제네릭에는 해당 제네릭의 모든 서브타입을 할당할 수 있다. 대충 다형성의 느낌으로 이해하면 되는데 단순한 인터페이스, 클래스의 다형성을 제네릭의 다형성 느낌으로 보면 이해하기 쉬울 것 같다. 예시를 들자면 LinkedList<`out T`>는 out 한정자로 인해 covariant(공변성)이다. val list: LinkedList<Any> = LinkedList<Int>() LinkedList는 공변성을 가지면서 Int는 Any의 하위 클래스이므로 LinkedList<Int>도 LinkedList<Any>의 하위 타입이 된다. 그래서 Any형 제네릭에 Int형 제네릭 객체 할당이 가능하다. 공변성은 말 그대로 보존된 하위 타입 관계를 뜻한다. 따라서 val list1: LinkedList<Any> = LinkedList<Number>() val list2: LinkedList<Number> = LinkedList<Int>() val list3: LinkedList<Int> = LinkedList<Nothing>() 와 같은 형태로 할당할 수 있다. -------------------------------------------------- covariant의 반대는 contravariant(반공변성)이 있다. class ContraList<in T> 라는 클래스는 in 한정자로 인해 contravariant 성질을 가진다. 반공변성은 그야말로 반전된 하위 타입 관계이다. B가 A의 하위 타입인 경우, Class<A>는 Class<B>의 하위 타입이다. 따라서 val contraList: ContraList<Int> = ContraList<Any>() 와 같은 형태로 할당할 수 있다. 위의 예시를 설명하다보니 다소 본 주제와 동떨어진 이야기를 많이 하기도 했고 주절주절 설명하다보니 설명을 잘 못한 것 같다. 추후에 covariant(공변성)과 contravariant(반공변성)에 대해 더 자세하게 글을 작성하겠다.
.
Factory function with a cache : 캐시를 활용하는 팩토리 함수
팩토리 함수는 캐시를 가질 수 있다.
가장 간단한 케이스는 항상 같은 객체를 리턴하는 팩토리 함수다.
예를 들어
emptyList()평소에 스레드 풀을 가지고 있다가 스레드를 사용할 작업을 시작할 때, 스레드 풀에서 사용하고 있지 않는 스레드를 가져와 실행하는 코루틴의 default dispatcher데이터베이스 커넥션 풀
객체 생성이 무겁거나, 동시에 여러 mutable 객체를 사용해야하는 경우에 객체 풀 (objects pool)을 가지고 있는 것이 좋은 해결책이다.
모든 순수 함수는 캐싱을 활용할 수 있으며 이를 memoization이라 한다.
순수함수란 input값에만 의존하고 외부 상태를 변경하지 않는 함수를 말한다.
즉, 동일한 input에 대해 항상 동일한 결과를 반환한다.
또한 함수가 외부 상태를 변경하거나 I/O 작업을 수행하지 않아야 하기때문에 부작용(side effect)가 없다는 장점이 있다.
private val connections: MutalbeMap<String, Connection> =
mutableMapOf<String, Connection>()
fun getConnection(host: String) =
connections.getOrPut(host) { createConnection(host) }
private val FIB_CACHE: MutableMap<Int, BigInteger> =
mutableMapOf<Int, BigInteger>()
fun fib(n: Int): BigInteger = FIB_CACHE.getOrPut(n) {
if (n <= 1) BigInteger.ONE else fib(n-1) + fib(n-2)
}위와 같이 메모이제이션을 활용할 수 있지만 캐시를 위한 Map을 저장해야하므로 더 많은 메모리를 사용해야하는 단점이 있다.
메모리가 관리를 위해 사용할 수 있는 참조 타입은 WeakReference와 SoftReference가 있다.
WeakReference
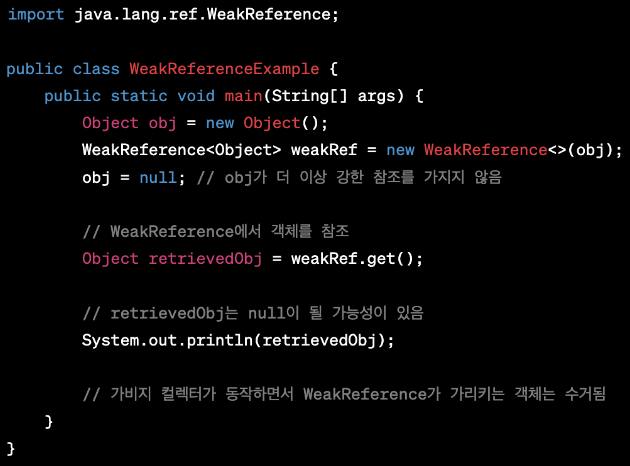
WeakReference는 약한 참조를 나타내며, 참조하는 객체가 다른 곳에서 참조하지 않을 때 가비지 컬렉터(Garbage Collector, GC)의 대상이 돤다.
따라서 다른 참조가 이를 사용하지 않으면 곧바로 제거한다.
SoftReference
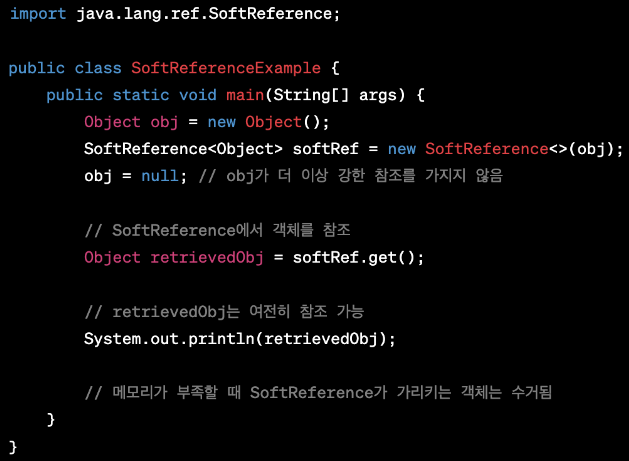
SoftReference는 소프트 참조를 나타내며 가비지 컬렉터가 값을 정리할 수도, 정리하지 않을 수도 있다.
대부분의 JVM에서 추가적인 메모리가 필요한 게 아니라면 정리되지 않는다.
따라서 캐시를 만들 때는 SoftReference를 사용하는 것이 좋다.
캐시는 언제나 메모리와 성능의 tradeoff(상충관계)가 발생하므로 여러 상황을 잘 고려해 사용해야한다.
Heavy object lifting : 무거운 객체를 외부 스코프로 보내기
컬렉션 처리에서 이루어지는 무거운 연산은 컬렉션 처리 함수 내부에서 외부로 빼는 것이 좋다.
- Iterable안의 모든 요소에서 최대 요소를 찾는 함수 최적화
[as is] fun <T: Comparable<T>> Iterable<T>.countMax(): Int = count { it == this.max() }maxiaml element를 count함수 내부보다 외부에서 실행하자.
[to be] fun <T: Comparable<T>> Iterable<T>.countMax(): Int { val max = this.max() return count { it == max } }매번 iteration마다 maximal 요소를 찾을 필요가 없어졌기 때문에 performance가 향상되었다.
- 정규직 top-level로 올려 향상시키기
[as is] fun String.isValidIpAddress(): Boolean { return this.matches("\\A(?:(?:25[0-5]|2[0-4][0-9]...\\z".toRegex()) }문제는 matches 반복마다 매번 새로 Regex 객체를 만드는 것이다.
regex 패턴 컴파일은 복잡한 연산이므로 반복적으로 만드는 것은 심각한 disadvantage이다.[to be] private val IS_VALID_EMAIL_REGEX = "\\A(?:(?:25[0-5]|2[0-4][0-9]...\\z".toRegex() fun String.isValidIpAddress(): Boolean = matches(IS_VALID_EMAIL_REGEX)이 함수가 한파일에 다른 함수들과 함께있지만, 이것이 사용되지 않는 다면 이 객체를 생성하지 않길 원할때 지연 초기화를 할 수 있다.
[to be + lazy init] private val IS_VALID_EMAIL_REGEX by lazy { "\\A(?:(?:25[0-5]|2[0-4][0-9]...\\z".toRegex() } fun String.isValidIpAddress(): Boolean = matches(IS_VALID_EMAIL_REGEX)
Lazy initialization : 지연 초기화
무거운 클래스를 생성할 때 lazy하게 만드는 것이 더 좋을 때가 있다.
class A {
val b = B()
val c = C()
val d = D()
}무거운 객체들을 lazy하게 초기화할 수 있다.
class A {
val b by lazy { B() }
val c by lazy { C() }
val d by lazy { D() }
}만약 A 클래스에 B, C, D라는 무거운 인스턴스가 필요하다고 가정하면, A를 생성하는 과정이 굉장히 무거워질 것이다.
내부에 있는 인스턴스들을 지연 초기화하면, A객체를 생성하는 과정을 가볍게 만들 수 있다.
-> 하지만 지연 초기화는
양날의 검(double-edged sword)이다.객체 생성은 무겁지만 메서드는 가능한 빨랐으면 하는 상황을 가정한다.
이때 객체 생성을 lazy하게 한다면, http call 요청을 받고 응답을 내리기 위한 연산을 거치는 과정에서 모든 무거운 객체 초기화를 할 것이다.
이렇게 되면 api 통신과정에서 응답을 내리기까지 많은 시간이 소요될 것이고 이는 결국 사용자 경험 저하로 이어질 수 있다.
(물론 첫 사용자가 한번 초기화를 거쳤으면 다음 사용자부터는 초기화 과정을 겪지 않겠지만..)
Using primitives : 기본 자료형 사용하기
JVM은 숫자와 문자와 같은 기본적인 요소를 나타내기 위한 기본 자료형(primitives)를 가지고 있다.
Kotlin/JVM 컴파일러는 가능하면 내부적으로 기본 자료형을 사용하지만
Wrapped class를 대신 사용해야하는 상황이 있다.
- nullable 타입을 연산할 때 (primitives는 null이 될 수 없음)
- 타입을 제네릭으로서 사용할 때
매우 큰 컬렉션을 처리할 때 기본 자료형과 wrap한 자료형의 성능 차이는 매우 크다.
Summary
불필요하게 객체 생성을 피하는 다양한 방법을 알아보았다.
Obeject declaration
Factory function with a cache
Heavy object lifting
Lazy initialization
Using primitives
가독성(readability) 측면에서 쉽거나 오히려 더 좋은 방식도 있다.
예를 들어 Heavy object lifting의 경우처럼 성능도 향상시킬 뿐더러 함수를 읽기 더 쉽게 만들 수도 있다.
하지만 최적화가 어렵거나 더 큰 변경을 요구하는 최적화라면 최적화를 미룰 수도 있다.
프로젝트에서 가이드라인을 아직 가지고 있지 않다면 시기 상조의 최적화를 피하는 게 좋으니 상황에 맞게 사용하자.
책 내용뿐만 아니라 개인적인 의견도 내포되어있으므로 참고부탁드립니다.
참고: 책 Effective Kotlin - Marcin Moskala
