SQL
1. coalesce : null 값 대체하기
select coalesce(column, replace_value)
from table2. 피봇 테이블 (pivot table) 만들기
예전에 업무할 때 SQL로 피봇 테이블 만든 적은 없는데...
그래도 언제 활용할지 모르니 기록!
select age
, max(if(gender='female', cnt_order, 0)) female
, max(if(gender='male', cnt_order, 0)) male
from
(
select gender
, cast(concat(substr(age, 1, 1), 0) as decimal) age
, count(1) cnt_order
from food_orders fo inner join customers c using (customer_id)
where age between 10 and 59
group by 1, 2
) a
group by 1
order by 1 desc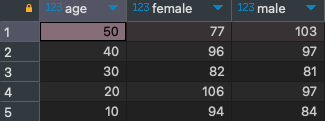
3. Window 함수 : RANK, SUM
이전 회사 SQL에서는 윈도우 함수를 지원하지 않아, 배워도 쓸모가 없었던 함수...
안 쓴지 오래되어 까먹었으니 한번 더 기록하자.
window_function(argument) over (partition by 그룹 기준 컬럼 order by 정렬 기준)window_function: 함수명 (예:sum,avg등)argument: 함수에 따라 작성하거나 생략partition by: 그룹을 나누기 위한 기준 (group by절과 유사함)order by: window function 적용 시 정렬할 기준 컬럼
RANK
select cuisine_type
, restaurant_name
, cnt_order
, ranking
from
(
select cuisine_type
, restaurant_name
, cnt_order
, rank() over (partition by cuisine_type order by cnt_order desc) ranking
from
(
select cuisine_type
, restaurant_name
, count(1) cnt_order
from food_orders fo
group by 1, 2
) a
) b
where ranking <= 3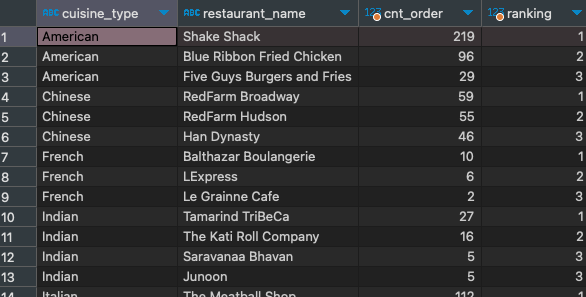
SUM (+ 누적합)
select *
from
(
select cuisine_type
, restaurant_name
, cnt_order
, cnt_order / sum(cnt_order) over (partition by cuisine_type) * 100 rate
, sum(cnt_order) over (partition by cuisine_type) sum_cuisine
, sum(cnt_order) over (partition by cuisine_type order by cnt_order) cum_cuisine
from
(
select cuisine_type
, restaurant_name
, count(1) cnt_order
from food_orders fo
group by 1, 2
) a
) b
order by 1, 3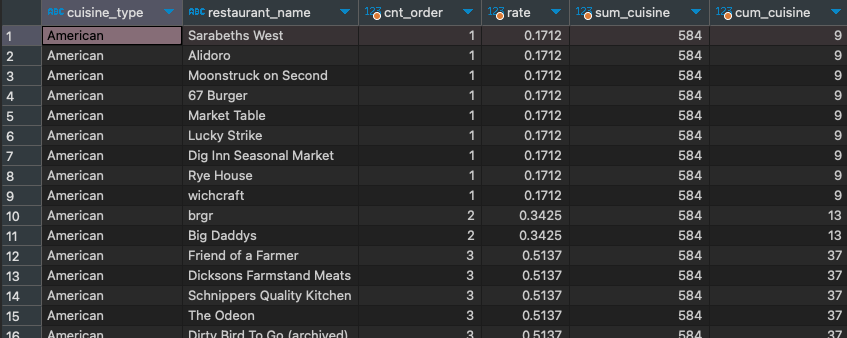
4. 날짜 포맷 (date_format)
# 문자열 컬럼을 날짜 형식(date_type)으로 변경
select date(column)
from table
# date_format
select date_col
date_format(date_col, '%Y') "년", # 연도 4자리
date_format(date_col, '%m') "월", # (01, 02, ...)
date_format(date_col, '%d') "일", # (01, 02, ...)
date_format(date_col, '%w') "요일" # 0 일요일, 1 월요일
from tablePython 심화 문법
1. 가상환경 설치
- 터미널을 연다.
- 다음 명령어를 입력하여 가상환경을
venv라는 명칭으로 생성한다.python3 -m venv venv - VS Code 에서 확인창이 뜨면
Yes를 클릭한다.
클릭하면, 이후에 폴더 실행 시 가상환경이 자동으로 활성화된다. - 가상환경을 최초로 실행했을 때는 자동 활성화가 되지 않으므로, 아래 명령어를 터미널에 입력해 가상환경을 활성화 한다.
source venv/bin/activate - 활성화 하면 그 전과 다르게 앞에
(venv)가 붙은 것을 확인 가능하다.
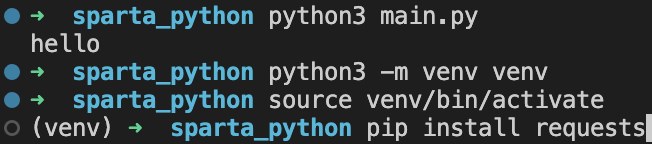
pip install명령어로 패키지를 설치하면 가상환경 내에 해당 패키지가 설치된다.pip install package_name- 가상환경 비활성화는 아래의 명령어로 실행한다.
deactivate
2. 코드 컨벤션 (Coding Convention)
- 개발자들이 서로 쉽게 알아볼 수 있도록 만든 스타일 규칙
- 파이썬에서는
PEP-8컨벤션 가이드를 제공함 - 파이썬의 네이밍 컨벤션
- 변수, 함수 : Snake 표기법 (ex:
function_name) - 클래스 : Pascal 표기법 (ex:
ClassName)
- 변수, 함수 : Snake 표기법 (ex:
- VS Code 에서 파일 저장 시 자동 Formatter 설정
command+,누르고 설정 진입format on save검색해서 아래 기능 체크
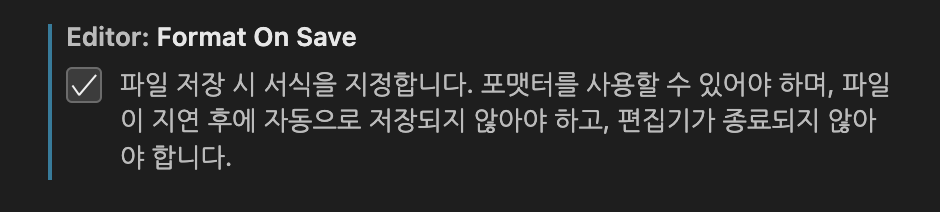
- VS Code 에서 default fommater 설정 (공식 문서 참고)
- 터미널로
autopep8패키지 설치pip install autopep8
3. 변수 유효 범위 (variable scope)
변수 유효 범위 (variable scope) 란 변수를 사용할 수 있는 범위를 말하는데, 변수가 선언된 위치나 키워드에 따라서 그 범위가 달라진다.
- 전역 변수 (global variable): 함수 밖에서 선언되는 변수로, 어디서든 접근 가능
- 지역 변수 (local variable): 함수 내부에서 선언되는 변수로, 해당 함수 내부에서만 접근 가능
- 지역 변수를 전역 변수로 재선언하고자 할 때:
global키워드 사용
전역 변수의 남용은 금물!!
값이 선언/변경된 위치를 추적하기 어렵고, 디버깅 하기 어렵다.
그러므로, 다른 함수의 결과값을 사용하고자 할 때는 변수가 아닌,return을 사용하는 것이 권장된다.
val1 = 1
val2 = 2
def func1():
global val2 # not recommended
val1 = 3
val2 = 4
def func2():
print(val1)
print(val2)
func1()
func2() # 1, 4 출력
# recommended (instead of using 'global')
def func1_edit():
return 4
def func2_edit(value):
print(value)
result = func1_edit()
func2_edit(result) # 4 출력4. 주요 함수
-
type(): 자료형 확인num = 1 print(type(num)) # <class 'int'> -
split(): 문자열을 특정 값(구분자)를 기준으로 자르기 (리스트 형으로 나옴)string = "This is Heeky's Velog." string_list = string.split(" ") # 공백( ) 을 기준으로 문자를 나눔 print(string_list) # ['This', 'is', "Heeky's", 'Velog.'] -
join(): 리스트를 지정한 문자로 합쳐서 문자열로 만들어주는 함수string_list = ['This', 'is', "Heeky's", 'Velog.'] string = " ".join(string_list) print(string) # This is Heeky's Velog. -
replace(): 문자열 바꾸기before_string = "This is Heeky's Velog..." after_string = before_string.replace('.', '!') print(after_string) # This is Heeky's Velog!!! -
pprint(): 코드 예쁘게 출력하기 (pretty print)from pprint import pprint # 모듈 불러오기 ... pprint(data)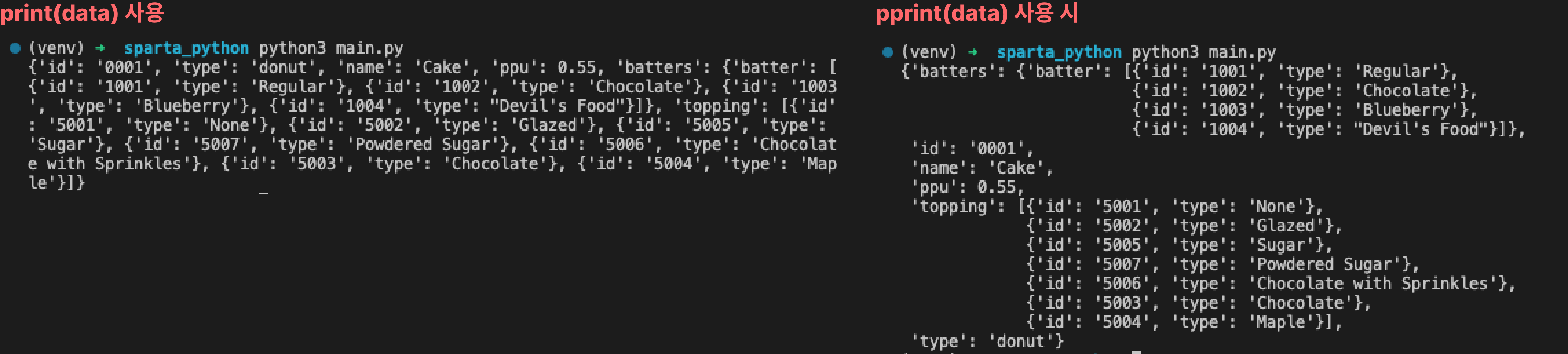
-
random: 랜덤한 값/동작 등이 필요할 때 사용되는 모듈import random numbers = [1, 2, 3, 4, 5, 6, 7, 8] random.shuffle(numbers) # 리스트 내의 요소를 섞기 print(numbers) # [7, 4, 5, 6, 1, 2, 8, 3] (순서는 실행 시마다 바뀜) random_number = random.randint(1, 10) # 1 ~ 10 사이의 번호를 랜덤하게 추출 print(random_number) # 6 (숫자는 실행 시마다 다르게 뽑힘) -
time: 시간을 다룰 때 사용되는 모듈 (코드 실행 속도 측정, 코드 일시 정지 등에 활용)import time start_time = time.time() # 코드 시작 시간 저장 time.sleep(1) # 1초 대기 end_time = time.time() # 코드 종료 시간 저장 print(f"코드 실행 시간 : {end_time-start_time:.5f}") # 코드 실행 시간 : 1.00506 -
datetime: 날짜를 다룰 때 사용되는 모듈from datetime import datetime, timedelta # 현재 날짜 및 시간 출력 print(datetime.now()) # 2024-02-21 16:42:35.087992 # datetime의 format code ''' %y : 두 자리 연도 / 20, 21, 22 %Y : 네 자리 연도 / 2020, 2021, 2022 %m : 두 자리 월 / 01, 02 ... 11 ,12 %d : 두 자리 일 / 01, 02 ... 30, 31 %I : 12시간제 시간 / 01, 02 ... 12 %H : 24시간제의 시간 / 00, 01 ... 23 %M : 두 자리 분 / 00, 01 ... 58, 59 %S : 두 자리 초 / 00, 01 ... 58, 59 ''' # string을 datetime 날짜로 변경하기 string_datetime = "24/02/21 16:42" datetime_ = datetime.strptime(string_datetime, "%y/%m/%d %H:%M") print(datetime_) # 2024-02-21 16:42:00 # datetime 날짜를 string으로 변환하기 now = datetime.now() string_datetime = datetime.strftime(now, "%y/%m/%d %H:%M:%S") print(string_datetime) # 24/02/21 16:42:35 # 3일 전 날짜 구하기 three_days_ago = datetime.now() - timedelta(days=3) print(three_days_ago) # 2024-02-18 16:42:35.097592
5. 조건문 심화
-
False로 판단되는 경우 : 빈 string(""), 숫자0, 빈 리스트([])print(bool("")) # False print(bool(0)) # False print(bool([])) # False print(bool(1)) # True print(bool([""])) # Truebool()함수로 값의True/False여부 판단 -
all(),any(): 리스트 내 요소에 대한 조건을 판단하는 함수# all() : 리스트 내 요소들이 모두 True 일 때, True 리턴 if all([True, True, True, False, True]): print("all 통과!") # False가 존재하므로 if문 통과 못함 # any() : 리스트 내 요소들 중 하나라도 True 일 경우, True 리턴 if any([False, False, False, True, False]): print("any 통과!") # True가 1개 이상 존재므로 if문 통과함
6. 에러 종류에 따른 에러 처리 (try ... except)
try:
...
except ErrorName1:
...
except ErrorName2:
...
except Exception as e: # 정의되지 않은 에러 발생 시 (not recommended)
...7. 패킹(packing) & 언패킹(unpacking)
- 요소들을 묶어주거나(
패킹) 풀어주는 것을 의미(언패킹) list혹은dictionary의 값을 함수에 입력할 때 주로 사용- 함수에서 받는 인자의 개수가 정해져있지 않을 때 사용
# 리스트의 패킹, 언패킹
def add(*args): # 인자를 모두 변수 args 안에 넣는다는 의미
result = 0
for i in args:
result += i
return result
numbers = [1, 2, 3, 4]
# *은 양쪽의 괄호를 풀어서 넣는 의미
# 아래 세 코드는 모두 동일한 의미를 가짐
print(add(*numbers)) # 10
print(add(*[1, 2, 3, 4])) # 10
print(add(1, 2, 3, 4)) # 10
# ------------------
# 딕셔너리의 패킹, 언패킹
def sample(**kwargs):
sample_dict = {}
sample_dict["key1"] = kwargs.get("key1", "-")
sample_dict["key2"] = kwargs.get("key2", "-")
sample_dict["key3"] = kwargs.get("key3", "-")
return sample_dict
sample_dict1 = {
"key1": "value1",
"key2": "value2"
}
# 아래 두 코드는 모두 동일한 의미를 가짐
print(sample(**sample_dict1)) # {'key1': 'value1', 'key2': 'value2', 'key3': '-'}
print(sample(key1="value1", key2="value2")) # {'key1': 'value1', 'key2': 'value2', 'key3': '-'}
# ------------------
# 리스트와 딕셔너리의 패킹, 언패킹
def sample(a, b, *args, **kwargs):
print(a)
print(b)
print(args)
print(kwargs)
sample(1, 2, 3, 4, test="a", key="abc", test_key="test_value")
''' 출력 결과
1
2
(3, 4)
{'test': 'a', 'key': 'abc', 'test_key': 'test_value'}
'''8. 클래스(class) - __init__ 함수
__init__ 함수 : 클래스의 인스턴스를 생성하는 과정에서 무조건 실행되는 함수(메소드)
class ClassName():
def __init__(self, instance_name):
print(f"The name of this istance is {instance_name}.")
self.instance_name = instance_name # 이렇게 저장해야 인수로 준 값을 instance1.instance_name 으로 호출할 수 있음 (아니면 호출 불가)
instance1 = ClassName("instance1") # The name of this istance is instance1.
instance2 = ClassName("instance2") # The name of this istance is instance2.9. 상속
상속 : 클래스를 생성할 때 다른 클래스에 선언된 변수, 메소드 등의 기능들을 가져와 사용할 수 있도록 해주는 기능
- 동일한 코드를 여러 클래스에서 조금씩 수정해 사용하거나 모듈에 내장되어 있는 클래스를 변경할 때 주로 사용
- 부모(parent) 클래스 / 슈퍼(super) 클래스 : 상속 해주는 클래스
- 자식(child) 클래스 / 서브(sub) 클래스 : 상속 받는 클래스
# 예시
class Monster():
def __init__(self, hp):
self.hp = hp
def attack(self, damage):
self.hp -= damage
def status_check(self):
print(f"monster's hp : {self.hp}")
class FireMonster(Monster):
def __init__(self, hp):
self.attribute = "fire"
# super()를 사용하면 부모 클래스의 코드를 그대로 사용할 수 있습니다.
# 해당 코드는 self.hp = hp 코드를 실행시키는 것과 동일합니다.
super().__init__(hp)
# 부모 클래스에 존재하는 status_check 메소드를 overriding 합니다.
def status_check(self):
print(f"fire monster's hp : {self.hp}")
class IceMonster(Monster):
def __init__(self, hp):
self.attribute = "ice"
super().__init__(hp)
def status_check(self):
print(f"ice monster's hp : {self.hp}")
fire_monster = FireMonster(hp=100)
# FireMonster 클래스에는 attack 메소드가 없지만
# 부모 클래스에서 상속받았기 때문에 별도의 선언 없이 사용 가능합니다.
fire_monster.attack(20)
fire_monster.status_check()
ice_monster = IceMonster(hp=200)
ice_monster.attack(50)
ice_monster.status_check()10. 정규표현식 (regex)
from pprint import pprint
import re
# rstring : backslash(\)를 문자 그대로 표현
# ^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$ : 이메일 검증을 위한 정규표현식 코드
email_regex = re.compile(r"^[\w\.-]+@([\w-]+\.)+[\w-]{2,4}$")
def verify_email(email):
return bool(email_regex.fullmatch(email))
test_case = [
"apple", # False
"account@mail.com", # True
]
result = [{x: verify_email(x)} for x in test_case]
pprint(result)11. rstring
backslash(\)를 문자 그대로 표현
print('\tHello') # Hello
print(r'\tHello') # \tHello12. glob : 파일 및 디렉토리 목록 확인
from pprint import pprint
import glob
# ./는 현재 python 파일이 위치한 경로를 의미합니다.
# *은 "모든 문자가 일치한다" 라는 의미를 가지고 있습니다.
# ./venv/*은 venv 폴더 내 모든 파일들을 의미합니다.
path = glob.glob("./venv/*")
pprint(path)
# result output
'''
['./venv/bin', './venv/include', './venv/pyvenv.cfg', './venv/lib']
'''
# **은 해당 경로 하위 모든 파일을 의미하며, recursive 플래그와 같이 사용합니다.
# recursive를 True로 설정하면 디렉토리 내부의 파일들을 재귀적으로 탐색합니다.
path = glob.glob("./venv/**", recursive=True)
pprint(path)
# result output
"""
['./venv/bin',
'./venv/include',
'./venv/pyvenv.cfg',
'./venv/lib',
'./venv/lib/python3.8',
'./venv/lib/python3.8/site-packages'.
...
]
"""
# *.py와 같이 작성 시 특정 확장자를 가진 파일들만 볼 수 있습니다.
# ./venv/**/*.py는 venv 하위 모든 폴더들을 재귀적으로 탐색하며 .py 확장자 파일을 탐색합니다.
path = glob.glob("./venv/**/*.py", recursive=True)
pprint(path)
# result output
"""
['./venv/lib/python3.8/site-packages/easy_install.py',
'./venv/lib/python3.8/site-packages/pycodestyle.py',
'./venv/lib/python3.8/site-packages/autopep8.py',
'./venv/lib/python3.8/site-packages/idna/intranges.py',
'./venv/lib/python3.8/site-packages/idna/package_data.py',
...
]
"""13. open : 파일을 편집하거나 생성하기
"file.txt": 사용할 파일 지정"w": 파일을 쓰기(write) 모드로 열기 (기존 내용을 유지하지 않고 내용을 새로 쓰며, 파일이 없다면 새로 생성)"a": 파일을 추가(append) 모드로 열기 (기존 내용을 유지한 상태로, 내용을 추가함)"r": 파일을 읽기(read) 모드로 열기
(그 외의 mode는 이 문서 에서 확인)encoding: 파일의 인코딩 형식 지정
-
파일을 쓰기 모드(
w)로 열기f = open("file.txt", "w", encoding="utf-8") -
파일에 내용을 작성하기
f.write("Today, Heeky learned Python.\n") -
파일 닫기 (
open으로 연 파일은 python 스크립트 종료 시까지 파일이 열려있게 되므로, 작업 종료 후 닫아줘야 함)f.close() -
파일을 열고 작업을 실행한 후 자동으로 닫기 (
with open)with open("file.txt", "a", encoding="utf-8") as w: w.write("Heeky also studied SQL, too.") with open("file.txt", "r", encoding="utf-8") as r: # readlines : 파일의 모든 내용을 list 자료형으로 한번에 읽음 print(r.readlines()) # result output ''' ['Today, Heeky learned Python.\n', 'Heeky also studied SQL, too.'] ''' with open("file.txt", "r", encoding="utf-8") as r: while True: # readline : 파일을 한 줄씩 읽음 line = r.readline() # 파일 끝까지 읽었으면 반복문을 중지함 if not line: break # 텍스트의 줄바꿈 문자 제거 line = line.strip() print(line) # result output ''' Today, Heeky learned Python. Heeky also studied SQL, too. '''
14. itertools : 배열을 효율적으로 다루기
효율적인 루핑을 위한 이터레이터 만들기
itertools로 가능한 작업
특정 패턴이 무한하게 반복되는 배열 만들기, 배열의 값을 일괄적으로 계산하기
-
데카르트곱
from itertools import product sample1 = ["A", "B", "C", "D", "E"] sample2 = [1, 2, 3, 4] # 행 / 열을 구분하여 프린트 하기 위해 enumerate 사용 for i, v in enumerate(product(sample1, sample2), 1): print(v, end=" ") if i % len(sample2) == 0: print("") # result output """ ('A', 1) ('A', 2) ('A', 3) ('A', 4) ('B', 1) ('B', 2) ('B', 3) ('B', 4) ('C', 1) ('C', 2) ('C', 3) ('C', 4) ('D', 1) ('D', 2) ('D', 3) ('D', 4) ('E', 1) ('E', 2) ('E', 3) ('E', 4) """ -
원소의 개수가 n개인 순열
from itertools import permutations sample = ["A", "B", "C"] # 원소의 개수가 3개인 순열 출력 for i in permutations(sample, 3): print(i) # result output """ ('A', 'B', 'C') ('A', 'C', 'B') ('B', 'A', 'C') ('B', 'C', 'A') ('C', 'A', 'B') ('C', 'B', 'A') """ -
원소의 개수가 n개인 조합
from itertools import combinations sample = ["A", "B", "C"] # 원소의 개수가 2개인 조합 출력 for i in combinations(sample, 2): print(i) # result output """ ('A', 'B') ('A', 'C') ('B', 'C') """ -
원소의 개수가 n개인 조합 (중복 허용)
from itertools import combinations_with_replacement sample = ["A", "B", "C"] # 중복을 포함한 원소의 개수가 2개인 조합 출력 for i in combinations_with_replacement(sample, 2): print(i) # result output """ ('A', 'A') ('A', 'B') ('A', 'C') ('B', 'B') ('B', 'C') ('C', 'C') """
15. requests : 파이썬에서 HTTP 통신하기
GET: 데이터 정보 요청POST: 데이터 생성 요청PUT: 데이터 수정 요청DELETE: 데이터 삭제 요청
[ GET 요청 테스트 코드 ]
import requests
from pprint import pprint
# 통신할 URL 지정
url = "https://jsonplaceholder.typicode.com/"
# 정보를 받아오는 get 요청 : 1번 사용자 정보 경로(users/get)
r = requests.get(f"{url}users/1")
pprint({
"contents": r.text,
"status_code": r.status_code,
})
# result output
"""
{'contents': '{\n'
' "id": 1,\n'
' "name": "Leanne Graham",\n'
' "username": "Bret",\n'
...
'}',
'status_code': 200}
"""[ POST 요청 테스트 코드 ]
import requests
from pprint import pprint
# 통신할 URL 지정
url = "https://jsonplaceholder.typicode.com/"
# 데이터 생성에 사용될 값 지정
data = {
"name": "heeky",
"email": "heeky@velog.com",
"phone": "010-0000-0000",
}
# 정보(사용자)를 생성하는 post 요청 : 경로는 users, 데이터는 data
r = requests.post(f"{url}users", data=data)
pprint({
"contents": r.text,
"status_code": r.status_code,
})
# result output
"""
{'contents': '{\n'
' "name": "heeky",\n'
' "email": "heeky@velog.com",\n'
' "phone": "010-0000-0000",\n'
' "id": 11\n'
'}',
'status_code': 201}
"""16. json (javascript Object Notation)
- 데이터를 저장하거나 데이터 통신을 할 때 주로 사용 (예: 다른 서버와의 API 연동 등)
- json을 파일로 다룰 때는
.json확장자를 사용 key: value쌍으로 이루어져 있으며, 파이썬의 딕셔너리와 유사함 (상호 변경이 가능)json.loads(): 문자열 형태의 json을 dictionary 자료형으로 변경
import json
import requests
# 해당 사이트는 요청에 대한 응답을 json 형태의 문자열로 내려줌
url = "https://jsonplaceholder.typicode.com/"
r = requests.get(f"{url}users/1")
print(type(r.text)) # <class 'str'>
# json.loads() : 문자열 형태의 json을 dictionary 자료형으로 변경
response_content = json.loads(r.text)
print(type(response_content)) # <class 'dict'>
print(f"사용자 이름은 {response_content['name']} 입니다.") # 사용자 이름은 Leanne Graham 입니다.17. csv (comma-separated values)
- 텍스트에 쉼표(
,)를 사용해 필드를 구분하며.csv확장자를 사용 - 텍스트 편집기를 사용해 간단하게 만들 수 있음
- 단순 텍스트이므로, 읽고 쓰는 속도가 빠름
17-1. csv 파일 읽기
# 파이썬에서 csv 파일을 다루기 위해 모듈 import
import csv
csv_path = "sample.csv"
# csv를 list 자료형으로 읽기
csv_file = open(csv_path, "r", encoding="utf-8") # 텍스트 파일을 읽기
csv_data = csv.reader(csv_file) # csv를 리스트 형태로 읽기
for i in csv_data:
print(i)
# 작업이 끝난 csv 파일을 닫기
csv_file.close()
# result output
"""
['email', 'birthyear', 'name', 'Location']
['jisoo@example.com', '1995', 'Jisoo Kim', 'Gunpo']
['jennie@example.com', '1996', 'Jennie Kim', 'Seoul']
['rose@example.com', '1997', 'Roseanne Park', 'Auckland']
['lisa@example.com', '1997', 'Lalisa Manobal', 'Buriram']
"""
# csv를 dict 자료형으로 읽기
csv_file = open(csv_path, "r", encoding="utf-8") # 텍스트 파일을 읽기
csv_data = csv.DictReader(csv_file) # csv를 딕셔너리 형태로 읽기
for i in csv_data:
print(i)
csv_file.close()
# result output
"""
{'email': 'jisoo@example.com', 'birthyear': '1995', 'name': 'Jisoo Kim', 'Location': 'Gunpo'}
{'email': 'jennie@example.com', 'birthyear': '1996', 'name': 'Jennie Kim', 'Location': 'Seoul'}
{'email': 'rose@example.com', 'birthyear': '1997', 'name': 'Roseanne Park', 'Location': 'Auckland'}
{'email': 'lisa@example.com', 'birthyear': '1997', 'name': 'Lalisa Manobal', 'Location': 'Buriram'}
"""17-2. csv 파일에 데이터 쓰기
# 파이썬에서 csv 파일을 다루기 위해 모듈 import
import csv
csv_path = "sample.csv"
# csv 파일을 쓸 때는 newline='' 옵션을 줘서 중간에 공백 라인이 생기는 것을 방지합니다.
csv_file = open(csv_path, "a", encoding="utf-8", newline='')
csv_writer = csv.writer(csv_file)
# csv에 데이터를 추가합니다.
csv_writer.writerow(["heeky@example.com", '1996', "heeky", "Seoul"])
csv_file.close()18. 데코레이터(decorator)로 파이썬 함수 장식하기
선언되는 함수 위에 골벵이를 사용해
@decorator형태로 작성하며, 해당 함수가 실행될 때 데코레이터에서 선언된 코드가 같이 실행됨
# 데코레이터는 호출 할 함수를 인자로 받도록 선언합니다.
def decorator(func):
# 호출 할 함수를 감싸는 wrapper 함수를 선언합니다.
def wrapper():
# func.__name__에는 데코레이터를 호출 한 함수의 이름이 들어갑니다.
print(f"{func.__name__} 함수에서 데코레이터 호출")
func()
print(f"{func.__name__} 함수에서 데코레이터 끝")
# wrapper 함수를 리턴합니다.
return wrapper
@decorator
def decorator_func():
print("decorator_func 함수 호출")
decorator_func()
# result output
"""
decorator_func 함수에서 데코레이터 호출
decorator_func 함수 호출
decorator_func 함수에서 데코레이터 끝
"""예시 (인자가 있는 경우)
# 입력받은 인자에 2를 곱해주기
def double_number(func):
def wrapper(a, b):
# 함수에서 받은 인자에 2를 곱해줍니다.
double_a = a * 2
double_b = b * 2
return func(double_a, double_b)
return wrapper
@double_number
def double_number_add(a, b):
return a + b
def add(a, b):
return a + b
print(double_number_add(5, 10))
print(add(5, 10))
# result output
"""
30
15
"""