11725. 트리의 부모 찾기
👌 문제 이해
- 부모노드를 1로 설정했을 때, 나머지 노드의 부모노드를 순서대로 출력
💡 문제 해결 방법
알고리즘 : DFS,BFS 모두 가능, but 나는 dfs 사용
이유 : 부모노드를 찾는 것이라 깊게 찾아야 한다고 생각했기 때문
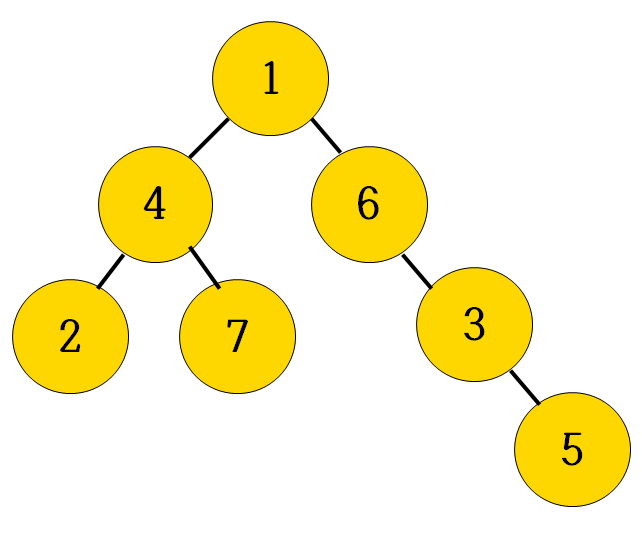
- 파이썬에서 기본으로 지원하는 최대 재귀 깊이는 1000인데 노드의 개수가 최대 100,000개 이므로 setrecursionlimit() 함수를 사용해서 최대 재귀 깊이를 늘려주어야 한다.
💻 코드 (다른 코드 참고함)
from sys import stdin as s
from collections import deque
import sys
sys.setrecursionlimit(10**6)
# SETRECURSIONLIMIT사용
#방문 리스트에 부모 노드 값을 저장하도록 설정
s=open("input.txt","rt")
n=int(s.readline())
graph=[[] for i in range(n+1)]
visited= [0]*(n+1) # 방문 리스트 자체에 값을 저장할 것이므로 0으로 초기화
def dfs(start):
for i in graph[start]:
if visited[i]==0: #방문하지 않은 노드일때
visited[i]=start # 현재 확인중인 노드의 값을 저장해줌
dfs(i) # 현재 노드에 대해 재귀 호출
for i in range(n-1):
a,b=map(int,s.readline().split())
graph[a].append(b)
graph[b].append(a)
#정렬 해도 되는데 방문 순서를 확인할 필요가 없고 부모 노드만 확인하면 되므로 생략해도 무관
dfs(1) # 시작노드가 1이므로 dfs(1)
for i in visited[2:]: #2번 노드부터 출력한다고 했으므로 2부터 출력
print(i)

블로그 이전합니다 -> https://heekyoung2000.tistory.com/